基于改进YOLOv3网络的无人车夜间环境感知
2019-05-24裴嘉欣孙韶媛王宇岚李大威
裴嘉欣,孙韶媛,王宇岚,李大威,黄 荣
(1.东华大学 信息科学与技术学院,上海 201620;2.东华大学 数字化纺织服装技术教育部工程研究中心,上海 201620)
引言
近年来,无人驾驶技术在理论方法与关键技术方面都取得了重大突破[1]。在无人驾驶技术中,环境感知是最为关键的一环,无人车的环境感知研究目前多见于可见光领域,夜视领域研究较少。在夜间条件下,有效的环境感知技术可以保障无人车夜间行驶的安全性[2]。夜间获取图像需借助红外摄像机[3],获取的是场景的温度分布,红外图像纹理信息少,图像较模糊[4],因此夜间的无人车环境感知相比可见光条件下的无人车环境感知难度更大。夜间无人车环境感知中的核心问题之一是行人及车辆检测,由于夜间道路能见度低,利用车载红外对夜间行人,车辆进行目标检测,能够扩展无人车在夜间的识别能力,有效帮助无人车对障碍物及时做出避让决策。
基于视觉的目标检测算法[5]可以让无人车在不使用昂贵的雷达传感器情况下获取实时的场景信息,帮助无人车快速做出相应决策。整体而言,目前处于技术前沿的目标检测算法主要分为两类:一类例如Faster R-CNN(快速区域卷积神经网络)[6],采用两级式的检测框架;另一类例如YOLO(you only lock once)网络[7],采用单级式的检测框架。YOLO网络改进了Faster R-CNN使用区域建议网络(region proposal network,RPN)生成候选区域,再用分类算法对候选区域分类后得到目标边界的方法,改用整张图像作为网络的输入,直接在输出层回归边界框的位置和边界框所属的类别。YOLO网络遵循端到端训练和实时检测,检测速度较Faster R-CNN大幅提升,解决了目前基于深度学习目标检测中的速度问题,真正实现实时性。
周边车辆的行驶方向对帮助无人车感知周边环境变化具有重要意义。如果将目标检测、周边车辆行驶方向信息以及车辆的距离和速度信息相结合,可以帮助无人车根据周边车辆行驶信息判断车辆的行驶意图。如何获取周边车辆的方向信息并结合目标的深度信息得到速度信息,从而判断车辆行驶意图,帮助无人车对目标车辆及时做出反应是难点。
本文提出一种改进的YOLOv3网络对无人车夜间获取的红外图像进行目标检测,并将红外图像中车辆角度信息加入到YOLOv3网络[8]边界框位置信息中,实现周边车辆角度预测,同时结合目标的深度信息得到周边车辆的速度预测,从而对周边车辆行驶意图作出判断,该网络具有端到端的特点,保证实时性的同时准确性性能良好。
1 网络结构
本文对YOLOv3网络结构进行改进,实现目标检测和周边车辆角度预测,并引入深度估计网络[9],与目标检测的结果结合,得到周边车辆的距离和速度信息。
1.1 YOLOv3网络结构
YOLO网络整个系列都采用一步式(one stage)的检测方法[10],整体实现框架如图1所示。YOLO网络结构简单,速度非常快,改进了Faster R-CNN将错误背景作为感兴趣区域的情况。但网络对小物体检测准确性有待提高,定位精度不高。从原理上看,小物体的像素较小,卷积操作后,特征经过最后一层卷积后输出层很难识别。YOLOv3网络针对这个问题,结合YOLOv2网络[11]进行改进,加入了特征金字塔网络[12](feature pyramid network, FPN),使网络在小物体的识别上性能大幅提升。
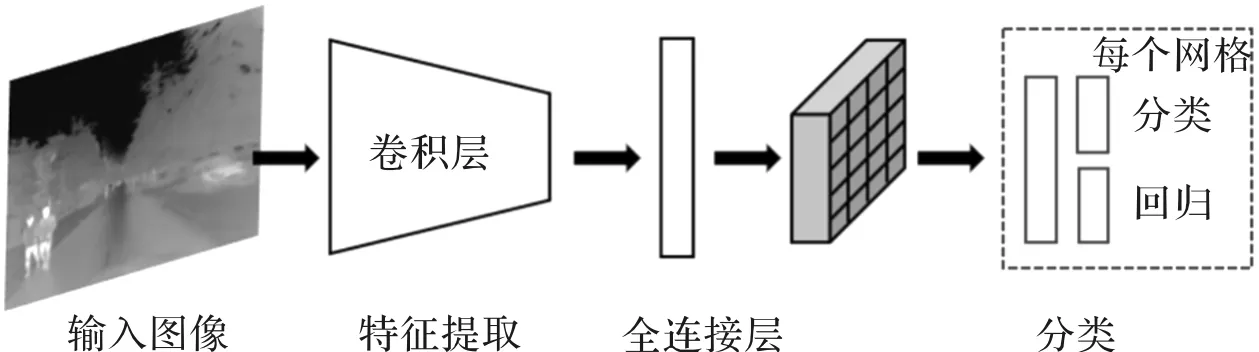
图1 YOLO框架示意图Fig.1 YOLO network structure
YOLOv2网络用Darknet-19网络代替YOLO网络中的VGG-16网络[13]。VGG-16是常用的特征提取网络,作为分类网络,它准确率高,但十分复杂,计算量非常庞大。Darknet-19网络下采样后将卷积的通道数翻倍,提取特征后再使用1×1和3×3的卷积和交替操作,最后使用平均-池化进行预测,有效减少计算次数。YOLO网络将整幅图像划分成S×S个网格,每个网格预测一个类别,虽然减少了计算量提升了速度,但这并不合理,YOLOv2网络使每个边界框都预测一个类别,实现解耦。YOLOv2网络采用Faster R-CNN中目标Anchor boxes的思想,Faster R-CNN是在每个位置上手动选取9个不同比例的Anchor boxes的方法,而YOLOv2网络通过K-Means聚类方法得出Anchor模板,确定Anchor boxes的个数和比例,最后在网格的周围生成几个一定比例的边框,网络输出边界框的计算公式为
bx=σ(x)+cx
(1)
by=σ(y)+cy
(2)
bw=pwew
(3)
bh=pheh
(4)
式中:bx为边界框中的偏移量;σ(x)、σ(y)为某个网格左上角的偏移量经过σ函数转化为[0,1]区间的值;cx、cy为网格左上角的坐标,均是单位为1的值;by为边界框中的偏移量;bw为边界框的宽度;pw、ph分别为Anchor boxes的宽和高;ew为网络输出值w的指数运算;bh为边界框的高度;eh为网络输出值h的指数运算。最终使目标检测在保持速度的同时精度与Faster R-CNN持平。
针对小物体的识别问题,YOLOv3网络采用FPN方法,将图片经过第K次卷积操作后得到的特征图复制1份,第1份特征图接着进行M次卷积操作,得到第1个输出层,用来检测大物体。将第1份特征图进行M次卷积操作得到的特征图上采样操作后,与复制的第2份特征图合并为另一组特征图,再进行N次卷积操作后,得到第2个输出层,用来检测中等大小物体。最后将第2份特征图进行M次卷积操作得到的特征图上采样操作后,与复制的第3份特征图合并为第3组特征图,再进行L次卷积操作后,得到第3个输出层用来检测小物体。
1.2 改进的YOLOv3网络结构
本文提出一种改进YOLOv3网络,采用端到端的检测方法,在检测网络的基础上增加多尺度预测,采用3个尺度分别负责预测不同大小的物体,并将车辆角度信息加入到YOLOv3网络边界框位置信息中,整体网络结构如图2所示(彩图见电子版)。
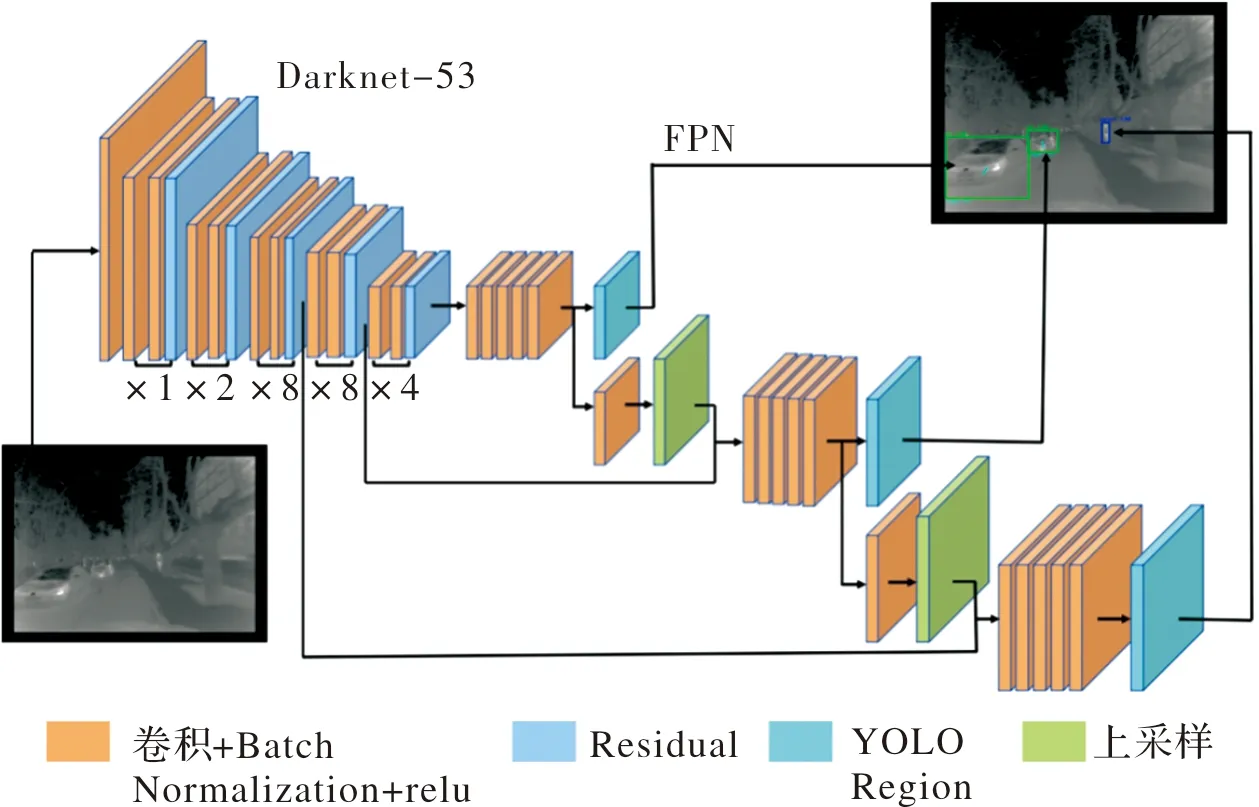
图2 改进的YOLOv3网络结构图Fig.2 Improved YOLOv3network structure
整幅图像划分成S×S个网格,将红外图像中车辆角度信息加入到YOLOv3网络边界框位置信息中,使用Anchor预测类别和坐标,每个网格使用K-Means聚类得出Anchor boxes的比例,得到9个聚类中心,将其按照大小均分给3种尺度。不同尺度的大小负责不同尺度物体的检测,通过将不同尺度的特征图进行融合,可以使得网络学习更有意义的语义信息,并添加一些卷积层提取图像的深层特征。用大尺度负责检测小物体,小尺度负责检测大物体,可以有效解决网络中小目标检测不好的问题,同时提升速度。
每个网格生成B个边界框,每个边界框的预测值增加角度信息,变为位置信息(x,y,w,h)、角度α和置信度(confidence)。(x,y)表示边界框相对于网格中心的的坐标,(w,h)是相对于整张图像的高度和宽度。角度α代表周边车辆的角度,是以车辆边界框中心水平向右为零度,逆时针角度变大,旋转一圈为360°。角度α定义如图3所示。

图3 周边车辆角度定义图Fig.3 Angle definition of surrounding vehicles
根据特征提取网络Darknet-53得到类别信息,当类别为车时,给出预测车辆的角度信息和车辆边界框,当类别为行人时,给出目标行人边界框。具体表示如(5)~(6)式所示:
C=car, angle=[0,1]
(5)
C=person, angle=-1
(6)
当类别C判定为车(car)时,(5)式中的角度值(angle)根据车辆角度预测的定义,将预测得到的0~1之间的值转换为角度值α,计算公式如(7)式所示:
α=angle×360°
(7)
当类别C判定为行人(person)时,角度值(angle)预测值为-1。
1.3 深度估计网络
本文利用基于卷积-反卷积神经网络[14]的深度估计算法对红外图像进行深度估计,其网络结构如图4所示(彩图见电子版)。
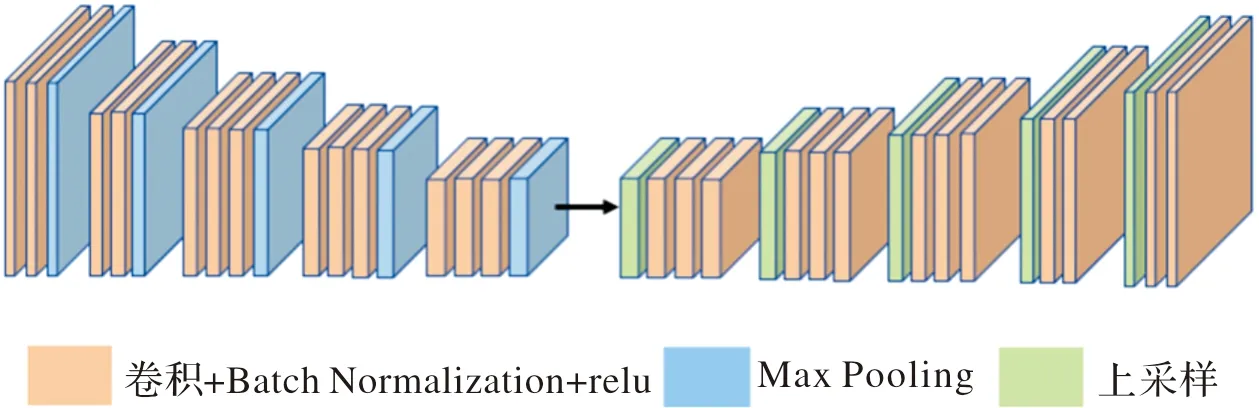
图4 卷积-反卷积神经网络结构图Fig.4 Convolution-deconvolution neural network structure
该网络结构采用去掉全连接层的VGG-16卷积网络作为特征提取网路,提取红外图像的深层特征,并采用反卷积网络将得到的特征还原到原图相同的大小,在卷积-反卷积网络后加上一层分类层从而得到每个像素点所属类别的概率,概率特征图中概率最大值所属的类别即为像素点所属类别。该网络具有端到端的优点,能够实时估计出红外图像的深度信息,并且根据(8)式将像素的分类结果转化成深度数据,从而得到深度估计结果。
dp=exp(Xi·k+lndmin)
(8)
式中:Xi表示红外图像X中第i个像素点的标签:k表示类别数量:dmin表示最小的深度:dp表示深度值。
本文将深度估计结果与目标检测的结果进行结合,根据深度估计图像中像素点的明暗变化判断目标的远近。无人车前方的物体距离越远,深度估计图像中物体对应的像素点越暗。将目标检测得到的物体边界框坐标与深度估计图像中相应像素点坐标对应,得到相应目标的距离。
2 实验过程及结果分析
2.1 实验配置与数据
本文算法使用Caffe框架[15],实验的软硬件配置详见表1。

表1 实验配置
本实验图像由实验室载有红外摄像头和毫米波雷达的无人车在夜晚拍摄所得,包括红外图像和对应的雷达数据,其中训练集为8 000张红外图像及其对应的由雷达数据转换的真实深度图像。红外图像测试集1 500张。
2.2 实验步骤
通过标记工具LabelImg将训练集中的红外图像中包含的行人及车辆进行真实目标位置标注,并使用Python脚本进行车辆的角度标定,得到样本文件后将其输入改进的YOLOv3网络进行迭代训练,模型收敛后输入测试图像得到目标检测与周边车辆角度预测的结果。将训练图像与对应真实的深度信息输入深度估计模型,进行迭代训练,输入测试图像得到深度估计图像,之后将目标检测的结果与深度估计结果结合,得到周边车辆的距离和速度信息。实验流程如图5所示。在训练过程中,设置基本学习率为0.000 1,迭代次数为60 000,耗时约5 h。

图5 实验流程图Fig.5 Flow chart of experiment
2.3 实验结果及分析
将测试集输入到训练好的模型中,得到目标检测与周边车辆角度预测的结果,如图6所示(彩图见电子版)。可以看出本文的算法能够准确检测出目标和车辆的角度。
使用传统的HOG+AdaBoost算法(方向梯度直方图)[16]、Fast R-CNN算法、Faster R-CNN算法、YOLOv1、YOLOv2以及本文算法在测试集中进行测试,并对不同算法结果进行了对比,结果如表2所示。从表2的对比结果来看,由于传统机器学习算法的特征表示能力不强,其在检测速度和正确率上都远低于深度学习算法。而两级检测算法如Fast R-CNN、Faster R-CNN算法采用候选区域提取算法生成大量潜在边界框,后采用分类算法对候选区域分类后得到目标边界。该类算法的准确率较高,但是速度较慢。YOLO系列算法通过直接在输出层回归边界框的位置和边界框所属的类别,在保证准确性的同时,极大地提高了目标检测的速度。本文改进的YOLOv3网络能够进一步提升目标检测的准确率,同时预测目标车辆的方向信息。

表2 不同算法结果对比
将相同的测试集输入到训练好的深度估计模型参数中,得到深度估计的结果,如图7所示。

图6 目标检测与周边车辆角度预测结果Fig.6 Prediction results target detection and surrounding vehicle angle

图7 深度估计结果Fig.7 Depth estimation results
将图6目标检测结果和图7深度估计结果融合,对于目标检测中的车辆位置,找到其在深度图像中对应的位置,平均深度计算公式如(9)式所示。
(9)
其中:di表示第i个车辆的深度值;xi、yi分别是边界框左上角的坐标;wi、hi分别表示边界框的宽和高;dp表示深度图像中边界框的深度值。
利用(9)式计算的目标车辆的深度值,即可计算目标车辆的实时速度,(10)式给出了计算方法:
(10)

本文通过回归模型得到目标车辆的方向和速度,使用平均误差指标作为主要衡量指标。车辆方向误差如(11)式所示:
(11)

(12)

针对测试集中的红外图像,本文计算出测试集的车辆角度和速度误差,如表3所示。

表3 不同算法的车辆角度和速度误差
从表3以及表2中的数据可以看出,由于本文所提出的改进的YOLOv3网络具有更强的特征表示能力,能够更好地反映红外图像的特性,因此取得了更好的目标检测效果、车辆角度以及速度预测效果。
3 结论
本文将改进了的YOLOv3网络应用于无人车夜间环境感知,将夜间红外图像中周边车辆角度信息加入到YOLOv3网络边界框位置信息中,并将深度估计网络与改进的YOLOv3网络相结合,对周边车辆行驶意图做出判断,实现周边车辆角度、距离和速度信息预测。该改进YOLOv3网络具有端到端的特点,输入一张图像直接预测出目标信息耗时0.04 s,帮助无人车感知周边环境,大幅提升速度的同时加强了对小目标物体的检测,能够有效保证了预测的正确性和实时性。
