指示变量随机缺失下变系数模型的分位数回归
2019-05-18宁黎明何晓霞王志明
宁黎明,何晓霞,王志明
(武汉科技大学理学院,湖北 武汉,430065)
删失数据广泛存在于金融、生物、医学、工程等研究领域。为了更好地对删失数据进行分析,各种统计模型相继出现,较早的有Cox提出的比例风险模型[1],但其中一些假设在现实中是不成立的。随后Cox等[2]又提出了加速失效时间(accelerated failure time, AFT)模型:logT=XTβ+ε,将失效时间的对数表示为协变量的线性组合。AFT模型很显然是有意义的,但在实际应用中,不可能保证所有协变量对生存时间都有线性影响,因此研究人员又提出了部分线性变系数模型,它在线性回归模型的基础上增加了非线性部分,使得整个模型具有更强的可塑性,通常采用局部多项式和光滑样条来估计其非参数部分。基于局部多项式方法,Zhang等[3]研究了半变系数模型,而Fan等[4]研究了协变量带测量误差情况下的惩罚经验似然估计。Zhao等[5]基于B样条估计,得到半参数部分线性变系数模型的模态回归。
分位数回归较普通的均值回归更加灵活,其应用也得到了迅速发展。何晓霞等[6]针对右删失数据,得到光滑回归函数的组合分位数回归估计。Wang等[7]对非参数部分采用B样条近似,得到部分线性变系数模型在纵向数据情形下的分位数回归。Shen等[8]运用局部多项式方法,在指示变量缺失的条件下得到部分线性变系数模型的分位数回归估计。由于局部多项式的计算速度较慢,因此本文采用B样条估计,研究删失指示变量缺失情形下部分线性变系数模型的分位数回归。
1 模型描述
本文考虑右删失数据情形下的部分线性模型
(1)
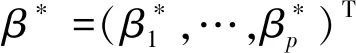
由于数据右删失,故只能观察到(Xi,Ui,Zi,Yi),其中Yi=min(Ti,Ci),Ci是随机删失时间。定义删失指示量δi=I(Ti≤Ci)以及缺失指示量ξi,其中I为示性函数,如果δi被观测到存在缺失时ξi=1,否则ξi=0。另外,记Hi=(Xi,Zi,Ui)。
2 估计方法和主要结论
2.1 样条近似和估计

(1)s限制在任何区间IMi(0≤i≤M)上是r次多项式;
(2)对r≥2,s在区间[a,b]上是r次连续可微的。
由文献[10],对Sn存在标准化的B样条基{Bω,1≤ω≤mn},其中mn=M+r是Sn的维数。因此对于任意函数αn(t)∈Sn,能够得到
(2)
在合理的平滑假设条件下,可以通过Sn中的基函数来逼近任意平滑函数。因此模型(1)中对α*的估计就可以转化为估计αω。
(3)
进一步地,式(3)又可以写为
(4)
其中Wi=Ip⊗B(Ui)·Xi且γ=(α1,α2,…,αmn)T,cτk是误差ε的τk分位数。

(5)

(6)
在删失指示量随机缺失的情况下,对于G(·)的估计不能再使用较为常见的Kaplan-Meier估计。参照文献[11],这里给出G(·)的估计:
(7)
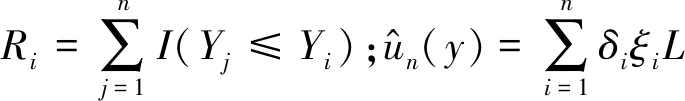
(8)
2.2 估计量的理论性质

为了分析估计量的理论性质,首先给出以下假设条件:
(C1) 对于任意α*∈Ψ,有E[α*(Ui)]=0。
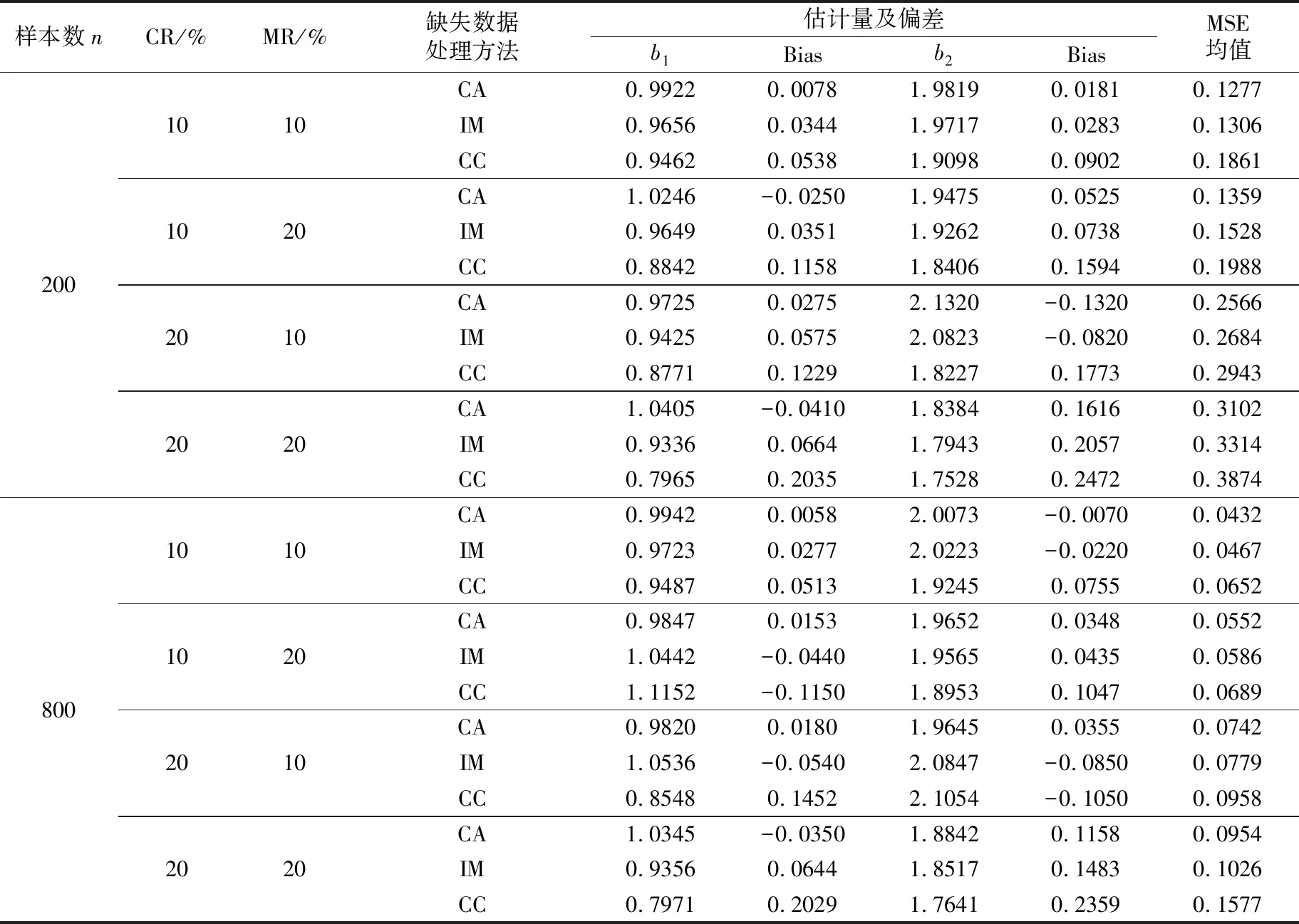
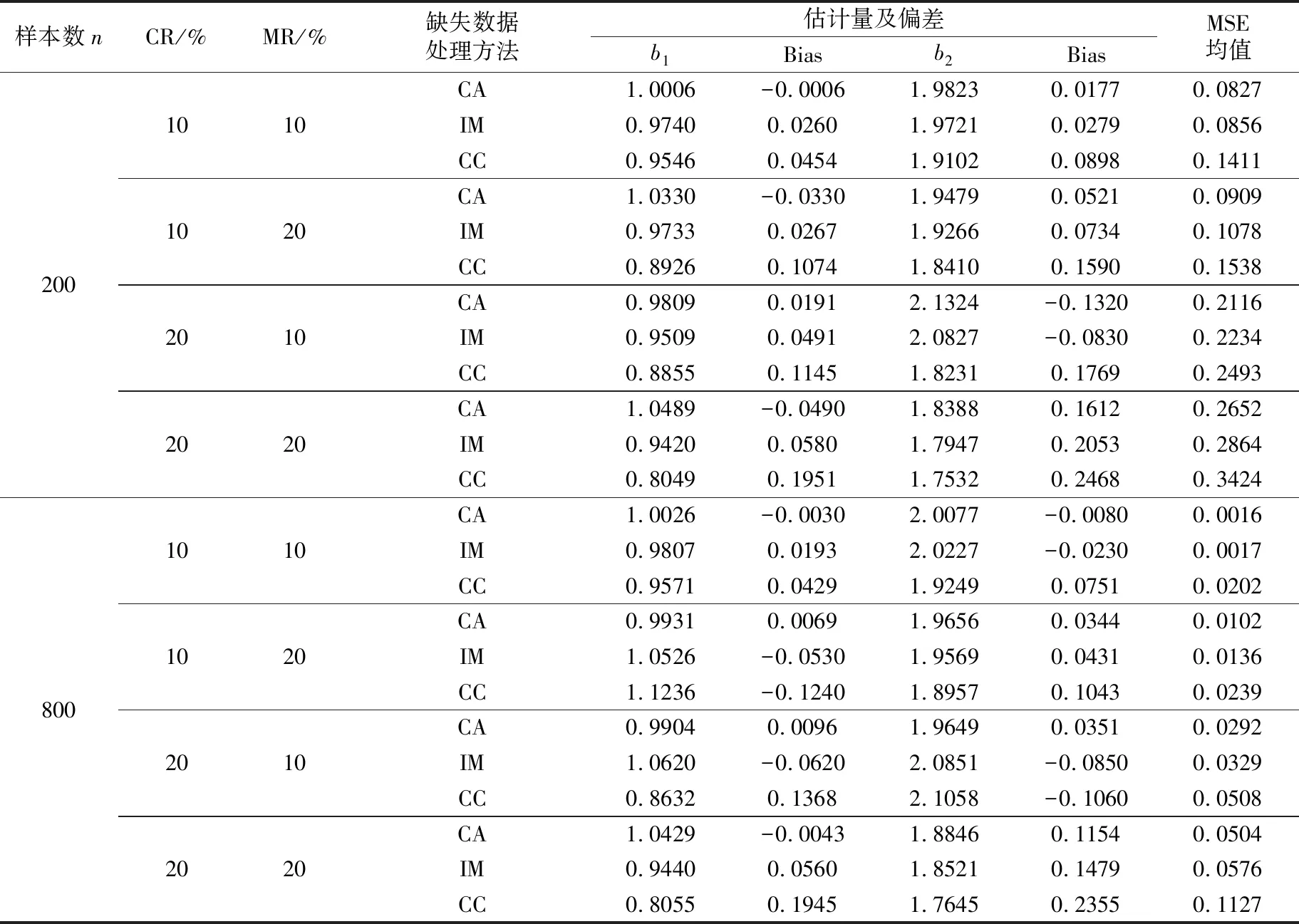
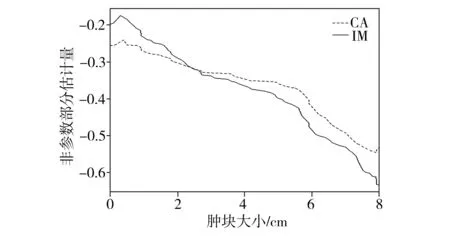
(C2) 协变量U有密度函数fU(u)且存在两个常数c1和c2,使得在[a,b]区间上,有0 (C3)Ci独立于(Zi,Ui)和Ti。 (C4) 对于任何t∈[0,τ],P(t≤T≤C)≥ζ0,其中ζ0是正常数。 (C5)ε1,ε2,…,εn有共同的连续可微的概率密度函数f(·),满足0 (C7) 定义aH=inf{t∶H(t)=1},aG=inf{t∶G(t)=1},令aH 条件(C1~C2)是一般性假定,条件(C3~C5)是生存分析背景下的常规设定,条件(C6)保证定理1的证明中所定义矩阵D的特征值是有界的并且远离零,条件(C7)表示G(Yi)远离零。 关于估计量的性质,本文有下述结论。 定理1假设条件(C1~C7)成立,可以得到 其中,D1和Σ的定义在定理1的证明中给出。假设mn=O(n1/(2p+1)),定理1的结论(II)也可写为 引理2假设条件(C1~C7)成立,最小化式(8)等同于最小化下式: (9) 同时,可以得到 因此A2=op(1),A3=op(1)。 基于以上结论,可以得到 (10) (11) 而 =op(1) (12) (13) 根据引理1和引理2,可以得到 (14) 结合式 (13) 和式(14) 就可以得到式(11)。 定义如下矩阵: D-1= 令 =op(1)。 下面证明定理1的结论(II)。由式(11)也可得到: 则可以得到 因此, (15) 根据I2的定义与如下等式: 有 (16) 结合式 (15)~式(16),有 因此 本文采用R软件中的lpsolve包解决此线性规划问题。 样本数据由以下模型产生: Ti=b1zi1+b2zi2+α(Ui)Xi+εi,i=1,…,n (17) 评价非参数部分估计效果采用均方误差指标: (18) 本文应用3种方法处理缺失数据:校准方法(Calibration Method, CA)和插补方法 (Imputation Method, IM)以及完全记录分析(Complete Case Analysis, CC)方法。CC方法的基本思路就是直接忽略那些有缺失记录的个体,再用传统的统计分析方法去处理剩下的数据集,该方法的缺点是,当缺失数据太多时得不到有效的估计。IM方法是对缺失的数据进行填补,然后再用传统的统计分析方法去处理整个数据集,其缺点也很明显,对缺失的数据进行填补亦要选择合适的方法,否则不会得到较好的估计。CA方法是用当前的可观测数据来估计参数,通过给定参数的形式产生模拟数据,即对包含缺失在内的整个数据集进行估计。 设置模拟次数为200、q=5,误差服从N(0,1)和t(5)分布的计算结果分别见表1和表2,其中MSE为200次模拟均值。另外,在表1中,CR为10%和20%时所对应的删失时间指数分布参数分别为0.1和0.19;在表2中,CR为10%和20%所对应的删失时间指数分布参数分别为0.08和0.16。 从表1和表2的结果可以看出:①对比不同的处理缺失数据方法,CA方法最好,IM方法其次,CC方法最差,表明本案例选用数据校准方法比较合适,而CC方法在不是完全随机缺失的假设下只能得到有偏的估计,所以在本案例中的估计效果是最差的。②随着样本数量的增多,估计结果的偏差也逐渐变小,这与估计的大样本性相符。③当删失率和丢失率增大时,估计偏差随之变大,这也从侧面说明了估计的大样本性,在足够的样本容量下,配合适当的估计方法才能得到好的估计结果。④在样本量一定的情况下,相较于丢失率的变化,删失率的变化对最后的估计结果影响更大。 实例分析数据来源于文献[15]。该数据是基于“东部肿瘤合作组织”(Eastern Cooperative Oncology Group)进行的一次临床试验,其对象是II 期女性乳腺癌患者,目的是比较三苯氧胺(tamoxifen)和安慰剂对于该病的疗效。在参与试验的170 名对象中,只关注其中79 个在试验结束前死亡的病患。根据报告可知,这个试验的死亡原因数据并不完全。在这79 个死亡对象中, 44人死于乳腺癌,17 人死于已知的其他原因,剩下的18 名死于未知原因。为了适用于本文模型,在下面的数据分析中,采用的都是生存时间(单位:d)的对数值,记作Y。设指标δ显示死亡是否由乳腺癌引起,指标ξ显示死因是否已知。另外,变量Z1表示病人服用药物情况(1,三苯氧胺;0,安慰剂);变量Z2表示病人雌激素受体蛋白状态(1,阳性;0,阴性);X为病人腋淋巴结个数;U为肿块的大小。模型如下: 表1 误差服从N(0,1)分布的模拟结果 表2 误差服从t(5)分布的模拟结果 Y=b1Z1+b2Z2+α(U)X+ε (19) 实例分析时采用的缺失数据处理方法为CA和IM,参数估计结果见表3,非参数部分的估计结果见图1。由表3可见,所有的系数估计值都是正值,但是变量Z1的系数估计值比较小,也就是说,乳腺癌患者的生存时间虽然没有受到“是否接受药物治疗”这个因素的显著性影响,但若服用三苯氧胺,病人存活的时间还是可以延长;另外雌激素受体蛋白状态为阳性也能增加生存时间,变量Z2的系数相对比较大,可见该因素对乳腺癌患者生存时间的影响更显著一些。上述计算结果与文献[11]的结论基本一致。根据图1,非参数部分估计值意味着肿块的增大会导致生存时间的减少,这与文献[15]中的试验结果是一致的。 表3 参数估计结果 图1 非参数部分估计结果 [1] Cox D R. Regression models and life-tables[J]. Journal of the Royal Statistical Society: Series B, 1972,34(2):187-220. [2] Cox D R, Oakes D. Analysis of survival data[M]. London: Chapman and Hall, 1984:593. [3] Zhang W Y, Lee S-Y, Song X Y. Local polynomial fitting in semivarying coefficient model[J]. Journal of Multivariate Analysis, 2002,82:166-188. [4] Fan G L, Liang H Y, Shen Y. Penalized empirical likelihood for high-dimensional partially linear varying coefficient model with measurement errors[J]. Journal of Multivariate Analysis, 2016,147:183-201 [5] Zhao W H, Zhang R Q, Liu J C, et al. Robust and efficient variable selection for semiparametric partially linear varying coefficient model based on modal regression[J]. Annals of the Institute of Statistical Mathematics,2014,66(1):165-191. [6] 何晓霞,刘熙,王志明.右删失数据下回归函数的局部组合分位数回归估计[J].武汉科技大学学报,2016,39(4):309-316. [7] Wang H J, Zhu Z Y, Zhou J H. Quantile regression in partially linear varying coefficient models[J]. The Annals of Statistics, 2009,37(6B):3841-3866. [8] Shen Y, Liang H Y. Quantile regression for partially linear varying-coefficient model with censoring indicators missing at random[J]. Computational Statistics and Data Analysis, 2018,117:1-18. [9] Huang J, Horowitz J L, Wei F R. Variable selection in nonparametric additive models[J]. The Annals of Statistics, 2010,38(4):2282-2313. [10] Schumaker L L. Spline functions: basic theory[M]. New Jersey: John Wiley & Sons, Inc.,1981. [11] 李夏炎.删失指示量随机缺失情况下回归模型统计推断[D].合肥:中国科学技术大学, 2011. [12] Wang Q H, Dinse G E. Linear regression analysis of survival data with missing censoring indicators[J]. Lifetime Data Analysis, 2011,17(2):256-279. [13] Hjort N L, Pollard D. Asymptotics for minimisers of convex processes[R/OL]. (2011-07-19)[2018-12-13]. https://arxiv.org/abs/1107.3806. [14] Knight K. Limiting distributions for L1regression estimators under general conditions[J]. The Annals of Statistics, 1998,26(2):755-770. [15] Cummings F J, Gray R, Davis T E, et al. Tamoxifen versus placebo: double-blind adjuvant trial in elderly women with stage II breast cancer[J]. NCI Monographs: a Publication of the National Cancer Institute, 1986 (1):119-123.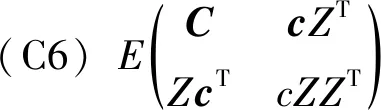
3 定理的证明
3.1 三条引理


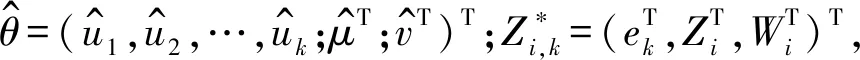



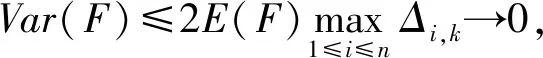

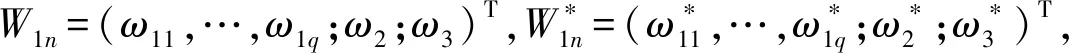
3.2 定理1的证明
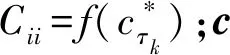

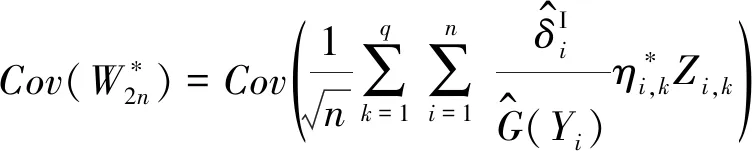
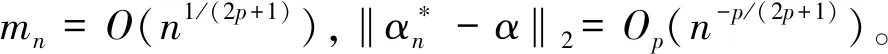

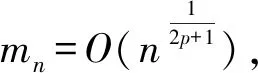
4 数值模拟与实例验证
4.1 蒙特卡洛模拟

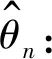

4.2 实例分析