基于区块链的智能合约压缩存储方法
2019-05-17王守道蒋玉明胡大裟
王守道,蒋玉明,胡大裟
(四川大学计算机学院,成都610065)
0 引言
区块链(Blockchain)最早出现在中本聪发表的论文《比特币:一种点对点的电子现金系统》中[1],它是一种基于加密算法、时间戳、梅克尔树(Merkle tree)和共识机制实现的分布式数据管理技术,主要特点有去中心化、数据可追溯、不可篡改,并在以比特币(Bitcoin)和以太坊(Ethereum)为代表的区块链平台上得到了应用[2]。
智能合约(Smart Contract)的概念由尼克·萨博在1994年提出,由于智能合约在提出的初期缺少特定的编程脚本和可信的运行环境,因此并未受到广泛关注,区块链技术的横空出世与其天然适用于智能合约的特性重新定义了智能合约。以太坊是一个基于公有链的区块链平台,除了拥有类似于比特币等数字加密货币的转账功能外,还提供了图灵完备的编程语言并为智能合约的编写、编译、部署与运行提供了良好的条件[3]。
通过以太坊提供的编程语Solidity(https://solidity.readthedocs.io/)编写的智能合约经过编译后以字节码的形式存储在区块链平台上,字节码可以被以太坊虚拟机(Ethereum Virtual Machine,EVM)解释后执行。用户在执行智能合约时需要向区块链网络中负责处理交易的节点支付一定数量gas作为手续费,收取费用是为了防止恶意节点生成大量无效的交易对区块链网络发起 DDoS(Distributed Denial of Service)攻击。
比特币中每个区块的大小为1M,而以太坊中区块的大小由区块中可供消耗的gas数量决定,因此以太坊中每个区块的大小是不固定的。智能合约的可重用性是初期提出的设想,通过在区块链上部署特定功能的合约,并将其作为一个子模块提供给其他合约使用,从而实现功能更多样化的智能合约,目前以太坊区块链平台上已经部署了超过60万个智能合约[4]。本文提出了一种对部署在区块链上的智能合约的压缩存储方法,通过将智能合约间相同的字节码片段进行重复利用,达到减小区块链数据量的目的。
1 相关研究
为了减少以太坊平台上存储的数据总量,加快节点加入区块链网络的速度,以太坊社区的研究者从不同的角度提出了一些用于减少区块链上的数据的方法。其中节点同步是基于节点的功能定位,为节点设置不同的同步数据量,让轻节点可以快速加入区块链网络并参与交易;而节点分片是基于分治的思想,将区块链的节点划分到不同的分片中,每个分片中的节点只需要参与分片内的交易,减轻了节点的负担,同时提升了整个区块链上的交易处理速能力。
1. 1 节点同步
以太坊平台上的节点可以自由的加入或退出区块链网络,在同步完区块链上所有的数据之后才可以发起交易,以太坊平台运行初期区块链上的数据量很少,节点可以在短时间内完成数据同步。随着区块链技术关注热度的提升,以太坊平台上的智能合约与关联的交易数量也在快速增长,区块链上存储的数据急剧增加,导致新节点同步数据需要的存储空间越来越多,消耗在同步数据上的时间越来越长。为了使新节点可以快速加入区块链网络,以太坊中定义了多种类型的节点,这些节点采用不同的同步策略来同步区块链上的数据[5]。节点按同步模式可归纳为以下三种类型:
●全同步模式:节点需从创世区块开始同步所有区块中的数据,并对区块中的所有交易进行执行与验证。
●快同步模式:节点以快照的形式同步历史数据,在同步到当前区块之前不处理任何交易,之后像全同步节点一样运行。
●轻同步模式:节点只获取当前区块的状态,如要执行交易则需要与网络中的全同步节点进行交互。
1. 2 节点分片
以太坊中节点分片[6]源于数据库中的分片技术,数据库中将数据表进行水平切分后存储在不同的数据库服务器上,可以加快数据的存取速度。以太坊中则是将整个网络状态分为进行分片,分片系统由校验器(Validator Manager Contract,VMC)合约负责维护。每个分片都是一个单独的区域,分片中的交易处理能力与原区块链中的处理能力相同,因此区块链的交易处理速度会线性增长。分片内的节点可以作为全节点和轻节点运行,轻节点在执行交易的时候需要通过RPC(Remote Procedure Call)在全节点获取必要的数据信息。分片虽然可以加快区块链的交易速度减轻节点的负担,但是处理跨分片的交易能力较差,安全方面也有潜在的风险。
2 压缩存储方法
2. 1 操作码定义
在以太坊中定义了多种操作码用于表示智能合约在EVM中的运行流程[3],文中模仿CALLCODE定义了一个新的操作码COMPRESS。COMPRESS的功能定义为:在一个新合约的字节码即将部署在区块链上时,通过对比它和已经部署在区块链上的旧合约字节码寻找它们的公共连续子串,并用旧合约上的子串作为指针来代替新合约中的子串。在智能合约执行时,当EVM检测到操作码COMPRESS后会将指针还原为具体的字节码然后继续向下执行。为了使COMPRESS操作有意义,指针的长度必须小于子串的长度,这样才能对智能合约进行有效压缩。为此对COMPRESS的结构定义如表1。

表1
opcode:为了和EVM中已经存在的操作码进行区分,将COMPRESS的值设置为“0xf5”;
block height:作为指针的智能合约在区块链中的位置,当前区块链的区块为6502231;
tx index:智能合约在创建时生成的交易处于区块中的位置;
string start:作为指针的子串在字节码中的起始下标,自从EIP150[7]中规定了智能合约的长度不超过0x6000或24576 bytes,这意味着2 bytes足够表示智能合约字节码中所有位置的起始下标;
string size:作为指针的子串长度;
在上述的结构中,使用9 bytes的长度的指针用于替换智能合约中的字节码,被替换的字节码的长度应大于指针的长度。
2. 2 智能合约分类
以太坊区块链提供了公开智能合约源代码的功能,在以太坊平台上有部分智能合约的源代码可供查看。对于从Ethereum Blockchain Explorer(https://etherscan.io/)爬取的智能合约源代码与字节码构建的数据集,源代码比编译后的字节码有更好的可读性、易于对智能合约分出类别,因此使用智能合约的源代码对其进行分类处理。

图1 智能合约的分类流程
为了对智能合约分类,设计了如图1所示的分类流程,用于快速地对智能合约进行标记。首先爬取了文献[8]中指明的GitHub上以太坊智能合约的公共代码库;然后将从etherscan.io上爬取的智能合约与公共代码库进行相似度分析,如果合约间的字符串相似度较高则通过人工阅读README等信息为智能合约添加类标签,否则通过直接阅读源代码的方式为智能合约添加类标签;最后根据智能合约的类标签,将对应的字节码进行分类处理。
2. 3 相同片段计算
在对智能合约中的字节码进行替换时只能在先部署的智能合约中选取合适长度的字节码片段去取代后部署的智能合约中相同的字节码片段,因此需要对获取的智能合约的字节码按其部署在区块链上的时间进行排序。计算智能合约序列中临近合约间相同字节码片段的问题可以认为是求字符串的最长公共子串(Longest Common Substring,LCS)的简单扩展。这个问题可以定义如下:
给定一个智能合约序列{C0,C1,…,Cn-1,Cn},为了对其中的智能合约Ci进行压缩,需要计算Ci与{Ci-k,…,Ci-2,Ci-1}i-k≥0}中每个智能合约字节码的公共连续子串LCS。
给定∑表示字符串的集合,给定两个字符串s1,s2∈∑,它们的公共连续子串集合 ω1,ω2可以定义为:
计算LCS的算法主要有动态规划(Dynamic Programming)、广义后缀树(General Suffix Tree)和后缀数组(Suffix Array)。动态规划算法实现简单但是计算效率低,适用于短串;广义后缀树算法虽然计算复杂度是线性的,但是原理比较复杂,代码实现困难;后缀数组算法的计算复杂度略高于后缀树算法,但它占用的内存空间会小很多,而且实现起来也更为容易。使用基于后缀数组的最长公共前缀(Longest Common Prefix,LCP)[9]来计算智能合约相同字节码片段的具体步骤如下:
(1)将字符串 s1和 s2拼接为一个新的字符串“ s1#s2”,其中“#”是在 s1和 s2中均未出现过的一个字符;
(2)对合成的字符串构造后缀数SA和名次数Rank,SA与Rank[10]为互逆运算,使SA和Rank将后缀数组按字典序进行排列;
(3)定义一个元组( )s1,s2,p1,p2,size 来表示后缀数组中相邻子串的LCP,其中 p1,p2分别为LCP在s1,s2中起始处的下标,size表示LCP的长度;
(4)对LCP数组进行剪枝操作,首先将LCP数组按size从小到大排序,然后对数组进行遍历,对于子串ωi如果数组中存在相应的元素(s1,s2,p1+1,p2+1,size-1),则将当前元素从数组中移除。
2. 4 字节码替换
计算出智能合约字节码之间存在的公共连续子串后,需要恰当的选取部分子串对智能合约进行压缩。为了确定哪些子串可以作为指针替换对应合约的字节码,定义了一些参数用于筛选这些子串:
临近合约数量k:用于与目标合约计算公共字节码片段的智能合约数量,即在目标合约以前的部署的k个合约才会作为候选合约。
替换指针数量p:每个智能合约可以被替换的子串数量的上限,p并不是越大越好,p值过大智能合约还原需要的时间也会变长;
公共子串长度t:作为被自定义的操作码替换的子串的最小长度,如果用16 bytes的操作码去替换17 bytes的字符串显然是不值得的,t的大小会影响替换合约的数量和智能合约的压缩率。
为了确保作为指针的子串在原字符串中存在且处于连续的位置,如果字符串s1中的子串ω1作为指针去替换字符串s2中的子串ω2,那么字符串s2中的子串ω2就不会作为指针去替换字符串s3中的子串ω3,这样就不会出现指针替换指针的情况,智能合约的还原时间也可以得到保证。
在智能合约执行的时候,EVM会如同处理操作码CALLCODE一样对指针进行处理,即把指针还原成对应的字节码。由于指针代表的字节码存储在其他智能合约中,因此需要提前将部署在它前面的k个合约的字节码读取出来,然后目标合约中的所有指针进行转换,最后拼接成完整的可执行的智能合约。
在一个子串作为指针替换了其他合约中的子串后,与这两个合约相关的子串的可用性会受到影响,部分子串会变得不可用,导致智能合约的压缩效果会变差。以合理的顺序选取子串进行替换有利于提升智能合约字节码的压缩率,本文以长度优先的规则去将子串作为指针去进行替换,因此在替换开始需要将子串按照长度进行排序。
3 实验与结果分析
本次实验环境为:CPU为Intel Core i5 6300HQ,主频为2.30GHz,内存为8GB,操作系统为Windows 10。
实验数据是从etherscan.io上下载的1210个有开源的代码信息的智能合约,经过分类处理后,各种类别的智能合约比例如图2所示。
在将智能合约分类后,按照图2中的类别顺序将智能合约进行排序。使用基于后缀数组的最长前缀算法计算智能合约字节码间的相同子串,在向前查找智能合约数量为10的平均查找时间为1.7s,当查找数量增加到50时平均查找时间为5.8s。图3和图4分别是向前查找智能合约数量为10和50的分类前后的压缩率对比。由图中可知,最早部署的智能合约字节码是不会被替换的,随着区块链上智能合约的增加,可作为指针进行字节码替换的字符串数量也在变多,智能合约的压缩率就逐渐增高并在一定数量之后趋于平稳。在向前查找智能合约数量为10和50时,分类后智能合约压缩率分别为28%和47%,比起分类前的压缩率分别高出6%和11%。随着向前查找合约数量的增加,智能合约的压缩效果在逐渐变好,从而字节码在区块链上存储需要的空间会减少,同时分类后与分类前的智能合约压缩效果差距也在变大。
在字节码替换时对每个智能合约可被替换的指针数量无限制的情况下,字节码替换完后每个智能合约被替换的字节码片段数量分布如图5所示,大多数合约被替换的字节码片段数量在0到40之间。

图3 临近合约数量为10的压缩率
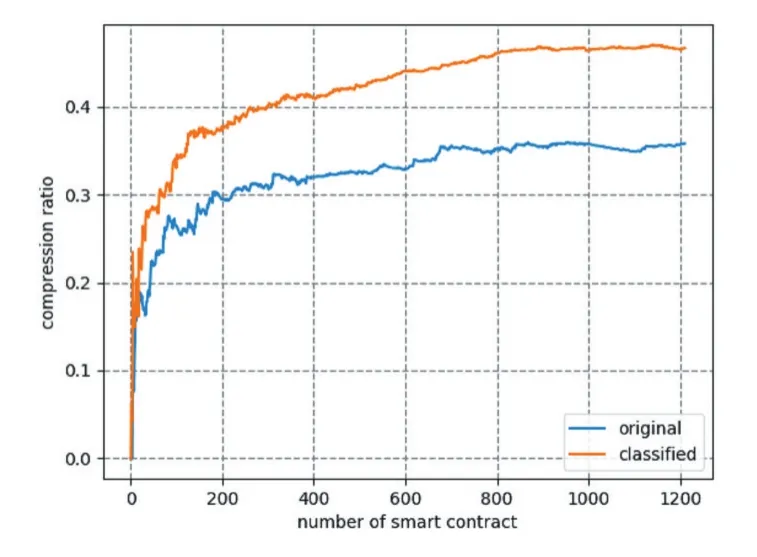
图4 临近合约数量为50的压缩率

图5 智能合约压缩后的替换指针数量
4 结语
本文提出的对智能合约压缩存储方法,通过对存储在以太坊区块链上的智能合约字节码进行重用,使智能合约的存储空间可以节省近47%,对智能合约分类后的压缩效果明显优于分类前的压缩效果。智能合约在经过压缩存储后,不仅可以减少区块链上存储的数据,还可以减轻节点同步数据的负担,使节点可以更快地加入区块链网络。
