MongoDB负载均衡算法优化研究
2020-04-09陈敬静马明栋王得玉
陈敬静,马明栋,王得玉
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 地理与生物信息学院,江苏 南京 210003)
0 引 言
随着通信技术、互联网、云计算的飞速发展,互联网浪潮已经到达,接入到互联网中的设备呈指数增长,越来越多的数据以不同内容和形式涌现出来,大数据时代正式到来。大数据时代最主要的特征就是数据种类与数量的繁多,除了结构化数据还有半结构化数据以及非结构化数据,这要求数据存储系统必须能够处理高并发问题,同时还要易于扩展[1]。尽管在主流应用场景中仍然使用传统关系型数据库,但面对海量的数据,它很难满足海量数据的存储需求,已经无法满足人们日益增长的需求。为了解决如何存储和处理海量数据的问题,非关系型数据库(NoSQL)应运而生[2]。MongoDB也是NoSQL的一种,因其非常适合处理海量数据和高并发而得到大量应用。文中通过研究MongoDB的自动分片原理,提出一种改进的基于节点实时负载的负载均衡算法[3],以有效解决其自身算法存在的部分问题。
1 MongoDB的自动分片
1.1 MongoDB简介
MongoDB是10gen公司使用C++编写开发的基于分布式文件存储的开源NoSQL数据库系统,由于其性能高效、功能丰富,在生产中得到了广泛应用。MongoDB除了具有NoSQL 数据库的相关特性外,还具有自动分片、集群扩展、单点故障自动恢复、复杂查询等优点,非常符合存储海量的半结构化或非结构化数据[4]。MongoDB将数据存储为一个文档,数据结构由键值对组成,其文档的数据结构非常松散,是类似于JSON的BSON格式[5],存储效率高。它是一个面向集合的,模式自由的文档型数据库,相较于传统的关系型数据库,在面对海量数据的挑战时更加有优势,其主要功能特性有:面向集合存储、模式自由、容易扩展、支持复制和数据恢复、支持动态查询、支持完全索引以及自动处理分片等[6]。
1.2 分片介绍
分片(Sharding)是指将内存中的数据拆分成不同的块,分别存储到不同机器上的过程。通过分割数据到不同的服务器,让数据集的不同部分分别由不同的服务器负责,使得单个机器上的请求数得到减少,系统总负载得到提高,总存储空间也得到提高[7]。分片是数据库系统扩展的必然产物,而不是某个特定数据库软件附属的功能,分片能在一定程度上决定系统性能的优劣。MongoDB采用自动分片(Auto-Sharding)机制,如图1所示。
自动分片技术一般用于自动配置、监控和数据转移,当数据量大到服务器的磁盘、内存难以负担时,自动分片技术可以自动平衡负载和数据分布的变化,提升系统的扩展性能。此外,它还提供无单点故障自动恢复、自动故障转移以及动态添加额外服务器等技术,为提升系统性能提供了很大帮助。

图1 分片原理
1.3 自动分片集群架构
MongoDB的自动分片集群架构如图2所示,主要包括分片服务器、路由服务器以及配置服务器,这三种服务器负责的功能如下:
(1)Mongos:路由服务器,负责将读取和写入的请求从应用程序路由到分片。集群通过Mongos连接客户端和服务器,当客户端向数据库发送更新或查询操作请求,Mongos接收请求并聚合,然后发送给分片服务器,它并不存储数据,只传递请求[8]。
(2)Config Server:配置服务器,存储集群的配置信息以及分片与数据的对应关系,运行集群时向路由服务器提供配置信息和对应关系。一般MongoDB自动分片集群中配有多个配置服务器,每个配置服务器中都保存了所有信息,防止信息丢失。
(3)Shard:分片节点,用于存储数据。在架构中,一个片内可以有多个Mongos服务器,每个服务器中存放的数据都相同,主服务器只有一个,其他均为从服务器。存储数据的部件是分片节点,为了获得高扩展性和数据一致性,分片常与副本集(Replica Set)同时使用,防止该数据片单点故障[9]。
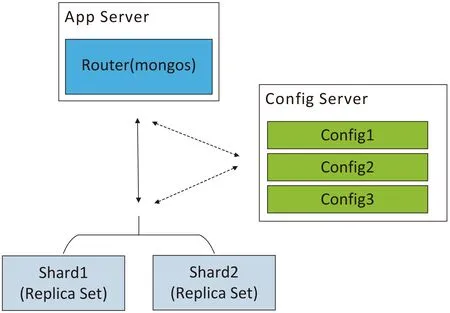
图2 自动分片集群架构
一般情况下,当用户向数据库发送操作请求时,Mongos会解析数据库的分片shard key(片键)规则,在存储元数据的配置节点配置服务器中查找相关信息,找到对应的分片后将请求转发到正确的片上,对客户端发送来的请求进行响应,最后Mongos将获取到的结果发送给应用程序[10]。将数据片段与应用程序分离是MongoDB分片技术中最独特的地方,使用这种分片机制,用户可以在不更改程序的前提下,实现对数据库系统的扩展。
2 MongoDB负载均衡算法
2.1 Chunk块拆分
MongoDB将分片服务器内部数据分为chunks,不同chunk块代表这个分片服务器内部的部分数据,由指定片键的某一连续范围内的文档组成。当chunk块过大时,MongoDB后台进程会计算每个chunk块的大小并选择拆分点,根据拆分点将该chunk块切分成更小的chunk块,避免chunk块过大的情况[11]。在MongoDB中,负责数据迁移的工具就是均衡器(balancer),balancer是一个后台进程,负责chunk块的迁移,从而均衡各个shard server的负载。拆分chunk块最重要的两点是选择合适的拆分点和不同chunk块所占用的空间基本相等。
2.2 负载均衡算法分析
随着MongoDB中的数据越来越多,分片中chunk块的数量也越来越多,每个分片服务器上chunk块的个数也不相同,且差异越来越大。在MongoDB中,默认的负载均衡算法认为chunk块数量相当即负载均衡。负载均衡的实现主要来自于其内部负载均衡器(balancer)进程的运行,均衡器周期性地检查各分片,当分片间chunk块的数量差到达迁移阈值(默认为8),均衡器启动自动数据迁移,将数据从包含最多chunk块的片上迁移到chunk块最少的片上,直到chunk块的数量差不大于2为止[12]。数据迁移以chunk块为单位进行迁移,最初默认大小为64 M,但随着数据量的逐渐增大,最终每个块的数据量会达到200 M[13]。
通过阅读源码并对源码进行分析,MongoDB负载均衡算法的流程如图3所示。
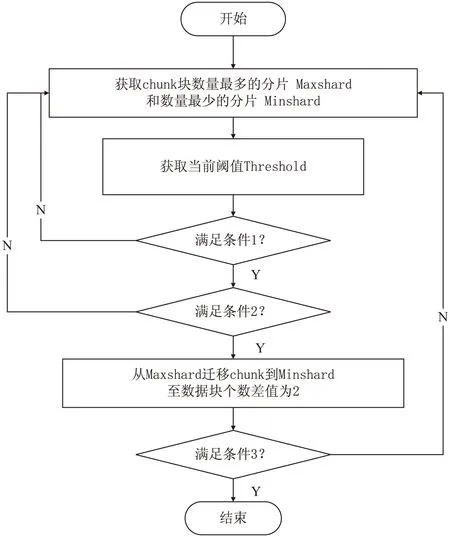
图3 负载均衡算法流程
条件1:Minshard未达存储上限且不存在写回队列;
条件2:Maxshard-Minshard>=Threshold;
条件3:负载均衡器仍然开启。
2.3 负载均衡算法的争议
一直以来,MongoDB的负载均衡算法在实际应用中仍然存在许多问题。这个均衡器只考虑了数据的存储平衡,而没有考虑负载平衡[14]。节点的负载取决于其配置及接受任务的轻重,尽管分片节点上的chunk块数量相同,但在选择目标分片时,没有考虑分片节点上的负载不相同这一问题,因此得到的结果也可能不是最好的,所以很有必要对MongoDB的负载均衡算法进行改进。
3 基于节点实时负载的负载均衡算法
3.1 基于节点的均衡算法思想
通过前面的分析了解到MongoDB的负载均衡算法并不是十分完善,因此文中在原始算法的基础上提出一种基于节点实时负载的负载均衡算法。改进的算法将节点的实时负载情况作为判断条件,在节点上增加负载代理,在负载均衡器上增加负载监视器,通过负载代理监测各节点的负载情况并将数据发送给负载监视器,均衡器将节点负载指数作为确定源分片和目的分片的一个指标。
将节点i的负载代理检测到的CPU占有率、内存使用率以及网络带宽占有率分别记为Ci、Mi以及Ni,CPU、内存和网络带宽的权值分别设为i1、i2和i3,则节点i的负载指数Iload可表示为:
Iload=i1×Ci+i2×Mi+i3×Ni
(1)
i1+i2+i3=1
(2)
假设自动分片集群架构中有n个分片,则平均负载Aveload为:
(3)
最大的节点负载为Maxload,设定阈值γ(一般默认为8),若
Maxload-Aveload≥γ
(4)
则此节点过载。改进的基于节点的均衡算法在均衡chunk块数量的同时,还均衡了分片节点上的负载,可以有效提升原算法的性能,解决数据分布不均的问题[15]。
3.2 基于节点的均衡算法设计
基于节点实时负载的负载均衡算法具体设计如下:
(1)负载代理周期性地遍历各分片,获取节点负载信息并发送给负载监视器。
(2)负载监视器计算出平均负载,确定负载最大的分片、chunk块数最多的分片和存储即将超过上限的待移除分片,将既不是待移除分片且chunk块数也不是最多的分片列入最小分片的候选列表。
(3)若分片块数差超过设定阈值,则确定源分片为chunk块数最多的分片;若分片块数差满足条件,但存在待移除分片,则确定源分片为待移除分片;若前两个条件都不满足但根据式(4)计算得出存在过载分片,则源分片为负载最大的分片;若以上条件都不满足,则不需要迁移。
算法流程如图4所示。
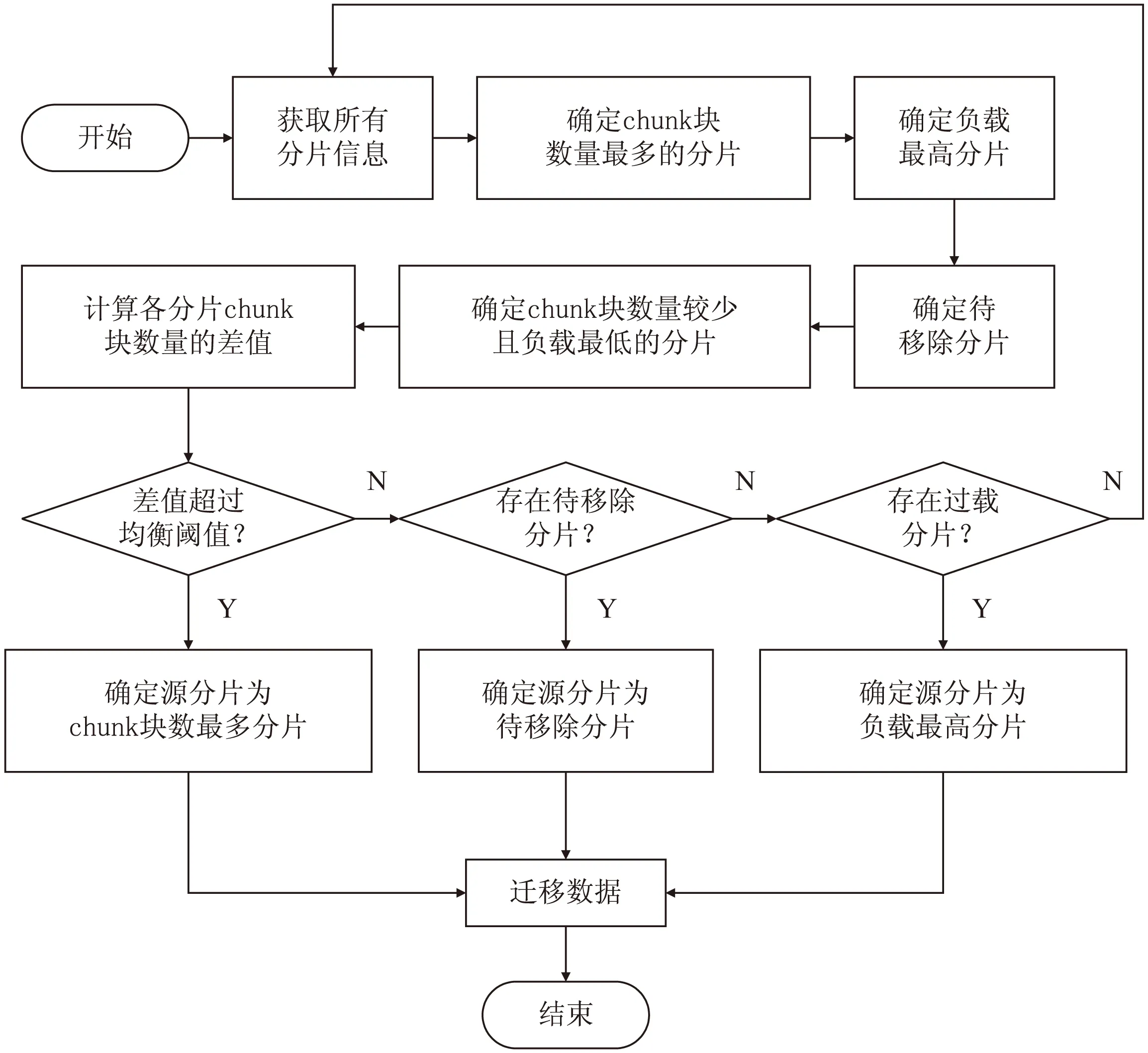
图4 基于节点实时负载的负载均衡算法流程
4 算法性能评估
4.1 测试环境
测试环境基于MongoDB的自动分片集群,由3台机器构成,每台机器内存都为4 GB,操作系统为Linux Redhat,MongoDB版本为3.4.0。集群包含3个分片,每个分片由一个副本集组成,每个副本集包含1个primary节点,2个secondary节点和1个arbiter节点。结合实际运行情况,设置CPU占有率和内存使用率权重占比较大,网络带宽占有率权重较小,i1、i2和i3分别为0.2、0.7和0.1,阈值γ设置为13%。
4.2 平台搭建
(1)配置副本集。
> cfg={_id:“shard1”,members:[{_id:0,host:“192.168.169.128:40007”},
{_id:0,host:“192.168.169.128:40007”},
{_id:0,host:“192.168.169.128:40007”}]}
> rs.initiate(cfg);
(2)配置Config Server。
mongod --configsvr --dbpath=/home/mongod/data/mongo.conf
(3)配置Mongos。
mongos -f /home/mongod/mongos/mongo.conf
(4)配置Shard。
>db.runCommand({addshard“shard1/192.168.148.61:40007,192.168.148.63:40007,192.168.148.65:40007”})
4.3 算法测试结果
首先,测试集群的并发写入功能。为了保证数据总量相等,均插入一百万条数据,在不同并发数下,新旧算法每秒可写入的数据记录如表1所示。
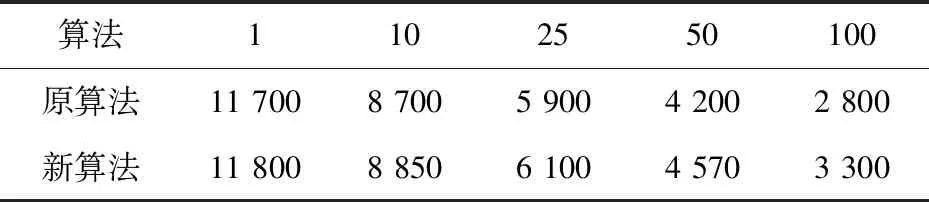
表1 新旧算法并发写入性能数据统计
在并发数和记录不变的情况下,测试集群的并发读取性能,新旧算法每秒读取的数据记录如表2所示。
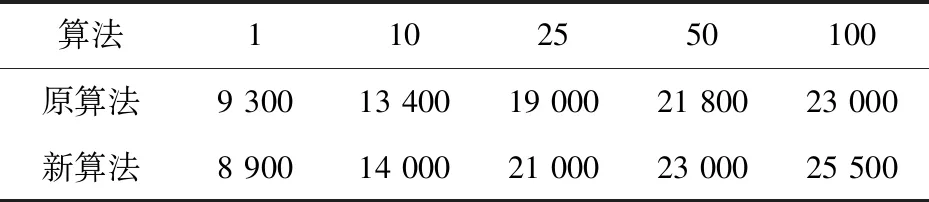
表2 新旧算法并发读取性能数据统计
从实验数据结果可以看出,在并发数较小的时候,新算法的读写性能并没有明显优于原算法,甚至可能会低于原算法,但随着并发数的增加,新算法明显优于原算法。这是因为改进的基于节点实时负载的负载均衡算法将节点负载作为一个考虑条件,当数据量不够大时,计算节点的负载情况资源利用率低,影响了系统性能,而在大数据及大并发的情况下,应用新算法之后的读写性能明显优于原算法,提高了集群的并发读写能力。
5 结束语
首先介绍了MongoDB自动分片的原理,然后分析了其负载均衡算法的缺点,针对分片间分配数据不均匀的问题,提出了一种基于节点实时负载的负载均衡算法。接着搭建了测试环境,针对数据的并发读写性能与原算法做一个对比实验,通过实验得出,该算法在数据的读写均衡上得到了明显优化,提高了集群的并发读写性能,证明了算法的有效性。
