多模态卷积神经网络的物体抓取检测
2019-09-13魏英姿曹雪萍
魏英姿,曹雪萍
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
近年来,机器人自主抓取研究受到人们的密切关注,主要是因为机器人缺乏理解感知信息的能力。即使给机器人提供与人类相同的视觉信息,机器人也并不知道怎么抓住物体。其次,由于待抓取物体的外形各种各样,即使同一种类别的物体在外形上也可能有较大的差异,因此视觉感知成为现实机器人系统的一大瓶颈。
传统的机器学习主要根据物体模型进行抓取姿态估计[1-3]。随着深度学习的快速发展,有学者提出两点抓取表示法,选择最优抓取点位置,提高机器人抓取的成功率。Tanner等[4]通过外形结构以及形态学处理的方法提取物体的特征点,从而确定物体的中心定位,但该方法并不适用于形状和结构复杂的物体。Maitin-Shepard等[5]利用手工标记特征的方法来选择最优抓取点,虽然在一定程度上提高了准确率,但手工标记既耗时,通用性也不强。卷积神经网络的出现,弥补了上述的不足,其结构类似生物神经网络,能够自主获取物品的特征。2012年AlexNet卷积神经网络[6]在ImageNet比赛中脱颖而出,随后,利用卷积神经网络进行物体识别[7]及物体抓取检测等研究迅速发展起来。2015年康奈尔大学的Ian Lenz等[8]利用一个深度网络检测机器人抓取矩形框并将矩形框中的三维点云映射到抓取参数。Redom等[9]将一个卷积神经网络与Jiang等[10]提出的抓取矩形框结合起来,实现物体抓取框的获取,但该方法的成功率并不高,还需要进一步完善。
本文提出一种基于多模态卷积神经网络模型的最优抓取位姿检测的方法。由于单独使用RGB图像作为神经网络输入时,物体抓取框预测结果易被图像的背景颜色和图案干扰,针对这个问题,本文对AlexNet卷积神经网络进行了改进,增加专门处理Depth图像的神经网络,并将其与处理RGB图像的神经网络合并。由于预测结果中评判值排名第一的抓取框未必是最利于机械手抓取操作的,所以还对最佳抓取框的选择进行了优化,增加了比较重心的算法。第一阶段采用背景减除法,得到物体的掩膜,通过等间距采样规则,获取这个物体所有可能的候选抓取矩形框;第二阶段将两个独立的AlexNet卷积神经网络融合作为一个整体进行训练,物体的RGB图像和Depth图像分别作为两个网络的输入,然后将所有候选抓取框送入神经网络打分,找到评判值排名前三的抓取框;第三阶段通过比较重心的算法找到中心最接近物体重心的抓取框,从而得到最优抓取框。
1 抓取矩形框的定义
机器人在抓取物品时要预先获取物品被抓取部位的位姿,并将位姿映射到末端执行器进行抓取。本文用一个旋转的矩形框表示物品的抓取位姿,采用文献[10]的方法来定义矩形框。进行物体抓取位姿检测时,输入到神经网络的数据是包含目标物体的RGB-D图像,输出的是抓取矩形的四个顶点坐标和抓取矩形框的旋转角度。矩形框的定义如图1所示,用五维向量表示抓取位姿。
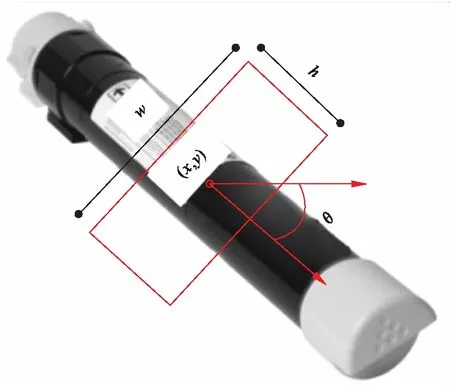
图1 抓取框在图像中的定义
若将抓取矩形框表示为G,则矩形框的定义式为
G={x,y,h,w,θ}
(1)
式中:(x,y)表示抓取矩形框的中心位置;h为机器人夹持器的宽度;w为夹持器张开的大小;θ为h与水平轴的夹角,表示抓取位置的姿态。
2 候选抓取框的确定
根据抓取框G={x,y,h,w,θ}可知,一个抓取框由中心点、长、宽、角度决定。抓取框中心点的确定,如图2所示,先通过背景减除,得到物体掩膜,然后以一定的等间距在横向和纵向上标记直线,找到既在直线交点上又在物体掩膜上的点,该点即为抓取框的中心点。采样的间距根据物体整体在图像上的像素面积确定,如面积较大,则可适当地增加采样间距;反之,则适当地减小采样间距。

图2 抓取框中心点获取示意图
根据康奈尔数据集中的物体大小,可大致确定抓取框16组长(w)和宽(h)的组合。
[w,h]=[40,20;50,20;60,20;40,30;50,30;60,30;70,30;50,40;60,40;70,40;80,40;60,50;70,50;80,50;70,60;80,60]
当实际值h比夹持器的宽度小时,或实际值w比夹持器张开的最大值大时,该抓取框则被判定为无效。
θ的取值范围为0°~180°,每改变15°取一个值,这样既能很大程度上减少抓取框的搜索时间又不会影响抓取框检测的效果。
通过上述步骤可以确定一个物体上的所有候选抓取框。
3 神经网络模型设计及训练
3.1 数据集选择
采用美国康奈尔大学提供的抓取数据集[11],该数据集由240个不同物品的885幅图像数据和点云数据组成,图片和点云数据相对应。在这些数据中,每幅图像均有多个被标记为成功(正)或失败(负)的抓取矩形框,共标注了8019个抓取矩形框,去掉点云缺失严重的数据后,共提取出7365个抓取框,其中正样本数为4673,负样本数为2692。图3所示为可抓取框RGB图像,图4所示为可抓取框Depth图像。本文将数据集上标注的所有可用的抓取框全部提取出来,将RGB图像和Depth图像分开作为训练抓取分类器的两个数据集,在进行卷积神经网络训练时,用提取出来经过处理的数据,将可抓取的矩形框标记为1,不可抓取的标记为0。

图3 可抓取框RGB图像

图4 可抓取框Depth图像
3.2 多模态神经网络结构
以抓取矩形框为学习特征,用8层的AlexNet卷积神经网络,建立多模态神经网络模型,将整个网络作为一个整体来进行训练,输入数据是抓取矩形框的RGB数据集和Depth数据集。多模态神经网络结构如图5所示。

图5 多模态神经网络结构
整个神经网络共有8层,前5层是卷积层,完成图形特征的提取;后3层是全连通层,实现图像分类。其中,第1层和第2层包括卷积层、标准化操作和最大池化层;第1层输出96个特征图;第2层输出256个特征图;第3、4层只有一个卷积层,输出384个特征图;第5层包含了一个卷积层和一个池化层,输出256个特征图;第6、7层为全连接层,均有4096个隐层;第8层将两个网络进行融合;最终输出层soft-max输出分类结果。
3.3 模型训练
实验平台采用Anaconda的tensorflow平台,主要使用GPU型号为GTX 1080Ti、操作系统为Windows10的计算机进行训练;训练数据集是从康奈尔抓取数据集中提取出来的抓取矩形框RGB-D样本集。训练参数如表1所示。

表1 训练参数
3.4 检测评估
神经网络模型训练完成后,在样本数据集上的识别成功率只反映模型对样本特征的学习能力,还需要将所有候选抓取框送入神经网络中评判,检测top3的抓取框。
若预测的抓取框为Rect,数据集中标注的抓取框为Rect*,判断一个预测抓取框是否成功有两个条件:
(1)预测的抓取框Rect和标注的抓取框Rect*之间的夹角小于30°;
(2)预测的抓取框Rect和标注的抓取框Rect*之间的重叠率score大于25%,定义式为
(2)
4 最优抓取框的选择
通过多模态卷积神经网络对所有可能候选抓取框进行评判打分后,得到评判值排名前三的候选抓取矩形框。为方便对物体进行抓取操作,通过比较重心的算法找到中心最接近物体重心的抓取框,即为最优抓取框。本文采用以下算法找到最优抓取矩形框,如图6所示。

图6 算法的流程图
首先找到评分排名前3名且不同中心位置的矩形框,记为Gt1、Gt2、Gt3,初始化Gt1、Gt2、Gt3后,输入候选矩形框Gi和该矩形框的评分Ji,然后将矩形框的评分Ji与第1个矩形框的评分Jt1进行比较,若Ji>Jt1,则比较其中心值;若中心值相等,则将该候选矩形框Gi赋值给Gt1;若中心值不相等,则依次进行以下操作:Gt2赋值给Gt3,Gt1赋值给Gt2,Gi赋值给Gt1,执行结束后进入下一循环。若Ji≤Jt1,则进入下一个判断,依次执行下去,直到获得评分在前3名且不同中心位置的矩形框Gt1、Gt2、Gt3。提取Gt1、Gt2、Gt3,求得中心平均值(x,y),再求出每个矩形框的均方差,则均方差最小的值既为最优矩形框。
5 实验结果及分析
5.1 网络测试结果
利用康奈尔大学的抓取数据集对整体网络进行测试。测试主要从以下两方面进行:①从康奈尔抓取数据集中随机抽取30种物体的图像进行测试,共抽取10次,求10次抽取结果的平均值作为最终正确率;②从数据集中随机抽取100张图片,同样抽取10次,求10次抽取结果的平均值作为最终正确率。图7为测试得到的正确抓取矩形框,图8为错误抓取矩形框。

图7 正确抓取矩形框

图8 错误抓取矩形框
将多模态卷积神经网络测试结果同其他方法进行对比。结果表明,使用多模态卷积神经网络可使抓取矩形框的正确率提高到90%以上,如表2所示。

表2 测试结果 %
5.2 实验验证结果
将多模态卷积神经网络应用到现实中常见物品上进行实验验证。实验共选择8种非数据集中的物体,这些物体均以不同的位置和姿态进行摆放,对每种物体进行10次top1抓取框预测,图9所示为部分物体top1抓取框预测。表3为8种物体top1抓取框预测成功率。结果显示,该实验预测成功率比较理想,除了在水杯、剪刀、鼠标、苹果上预测的抓取框比较不稳定外,在其它四个物体上预测的top1抓取框的中心大致在物体的中心处,成功率达到100%,验证了多模态卷积神经网络能够实现对未知物体的抓取框检测。

图9 部分物品top1抓取框预测

表3 top1抓取框预测成功率% %
6 结论
采用多模态卷积神经网络实现对物品的抓取矩形框检测,提高了抓取矩形框检测的成功率,在测试集上抓取框的正确率提高到90%以上,在验证集上对8种物体分别进行10次top1抓取框预测,其成功率都高达80%,其中有四种物体的预测成功率达到了100%。经验证,不需要对物品进行三维建模,也能实现对未知物体的抓取。未来将进一步优化本文的方法,将两个网络更有效地结合在一起,更快更准确地实现最优抓取位置的检测。
