基于大数据的货物运输责任时间划分方法研究
2019-04-19侯吉宋瑞何世伟殷玮川
侯吉,宋瑞,何世伟,殷玮川
(北京交通大学综合交通运输大数据应用技术交通运输行业重点实验室,北京 100044)
随着我国铁路货运改革的不断推进和铁路基础设施建设的发展,铁路运输部门在货物运输方面大力发展“前店后厂”模式,精简货物承运办理程序,加强与客户的信息沟通,努力提高货物运输的服务质量。另一方面,随着经济的快速发展和人民生活水准的提高,高附加值货物及零散白货的货运需求不断增加,对时效性的要求更加严格[1]。然而铁路货物运输过程中,铁路运输部门的时间指标和要求灵活性不足,缺乏对货物运输全程中各车站和区段作业时间的动态考核和评价,货物逾期到达的问题依然存在,成为制约铁路提升货运服务质量的关键“痛点”。
目前,关于货物运输时间的研究多为对现有指标和作业流程的优化。罗小明等[2-3]提出在新的运输条件和铁路普遍提速的前提下,制定新的货物运到期限计算方法。韩雪松等[4]分析得出货车在货运站的集散时间和技术站之间的运送时间对全程货物运输时间影响较大,并提出一系列流程优化建议。程文毅[5]分析了货物运到期限的保障对货主选择货运方式造成的影响。贾玉卫[6]主要从可靠性方面分析评价货物送达时间。张戎等[7]等分析了时间可靠性对铁路集装箱运输的影响。而关于铁路大数据应用的研究[8-11],大多为系统框架构建和需求功能分析等,也有如Yin 等[12]提出基于云计算的铁路“门到门”货物运输产品设计方法,但是在货物运输责任划分方面的研究较少。
综上所述,本文针对目前在铁路货物运输责任划分和考核评价方面研究的不足,结合云计算和大数据处理方法,通过对铁路货运大数据的分析,提出了一种基于大数据的货物运输责任时间划分方法(division method of railway freight transport responsibility time based on big data,DMRFTRT),以实现对铁路货运全程中各环节作业时间的动态考核评价,促进提高铁路货物运输效率和保障铁路货物运输的时效性。
1 货物运输过程分析
根据铁路货物运输组织方法[13],货物运输过程可以划分为3个阶段:始发站的发送作业阶段、途中技术站和区段的运输阶段、到达作业阶段,如图1所示。

图1 铁路货物运输全程示意图Fig.1 Diagram of railway freight transportation
影响货物运输过程的因素众多,主要有货物因素、车站设备条件、区间设备条件、人为因素和其他因素等5个方面,如图2所示。
由于货物运输过程中会经过多个车站和区段,影响因素众多,不同地区铁路建设水平、运输组织工作水平并不均衡,同时随着近年来我国铁路基础设施不断建设改造,车站区间能力得到释放和改善,现行的货物运到期限计算方法作为时间指标来组织和评价货物运输状况难以符合实际现场情况,需对货物运输的各环节加强监督与责任划分。
传统货物运输过程各环节时间的分配方法包括剩余时间平均分配法、均值比例分配法、蒙特卡洛仿真法[14-15]。剩余时间平均分配法,即将货物实际送达时间与货物运到期限的差值平均分配到各作业环节上;均值比例分配法直接以各环节作业的均值占货物实际送达时间均值的比例来分配货物运到期限;而蒙特卡洛方法则是通过查询各作业环节的历史数据,利用符合各作业环节时间服从的分布规律产生随机数,再从其中随机抽取样本,最后算出各作业环节所占比例均值,以此来进行运到期限时间的分配。上述的几种货物运到期限时间的分配方法,主要不足有:(1)对货物运输各环节作业的时间波动性和不同环节作业时间的差异性缺乏体现;(2)对于铁路部门产生的大量记录数据利用不充分,其时间分配结果适用性不高;(3)传统的方法分配的时间标准并不是动态的,而是一个通过计算得到的固定值,对于影响因素众多的铁路货物运输不一定始终适用。
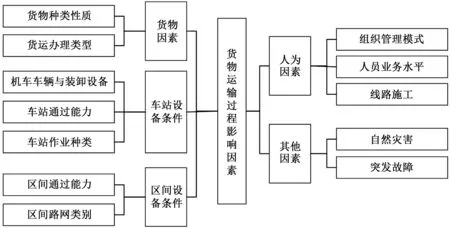
图2 铁路货物运输过程影响因素Fig. 2 Influence factors of railway freight transport process
2 基于大数据的货物运输责任时间划分方法
2.1 货车运行轨迹大数据处理方法
据初步数据统计,中国铁路总公司及各铁路局存储的数据总量已经达到10 PB的数量级[16],铁路货物运输大数据特点:数据量大(volume)、数据类型和来源多(variety)、数据实时采集(velocity)、价值密度低,但通过有效利用可获得很高的价值(value),即具有4V特性。传统的本地数据处理方法受限于数据量和计算速度,而大数据分析和云计算的发展,为铁路利用货运大数据实现精准营销和提升工作水平都提供了更好的技术保证。
本文的货车运行轨迹大数据的处理方法基于云计算平台。数据来源于铁路信息系统中普通货车的装卸作业和到发运行等记录数据,以及路局、站名等基础数据字典。货车运行轨迹大数据处理方法主要包括数据结构读取、数据上传存储、数据清洗、数据筛选匹配4个步骤,其中数据结构读取利用本地编程软件如Java工具实现,数据上传存储、数据清洗、数据筛选匹配在云计算平台实现。本文中云计算平台均使用阿里云计算服务大数据平台[17],而将来的实际应用中可以使用铁路相关部门的自建云平台。大数据处理流程见图3,具体步骤如下:
(1)数据结构读取。即利用Java工具对原始数据文件的数据结构进行读取。获得数据文件中行分隔符、列分隔符和数值类型等信息,以保证数据上传时符合云端数据库规范。
(2)数据上传存储。在云端数据库新建与(1)中读取出数据结构符合的表格,然后利用云客户端的MapReduce分布式上传功能,完成原始数据上传和存储在云端数据库中。
(3)数据清洗。由于数据在统计、导入导出等格式转换时,不可避免会出现数据部分缺失、重复等问题,以及存在隐藏符号、空格等,会影响数据分析,所以需要对数据进行清洗,并将格式统一,以方便计算分析。
(4)数据筛选匹配。去除无效数据,筛选有效信息,并通过货物运输不同环节产生的数据之间的相互匹配,得到需要分析的目标数据和结果。
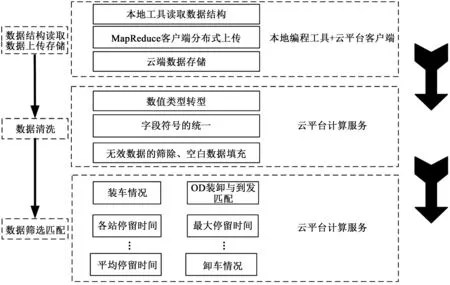
图3 基于云计算的货车运行轨迹大数据处理流程Fig. 3 Big data processing flow of freight transit track based on cloud computing
利用云计算平台处理货车运行轨迹大数据,其计算效率有明显优势。在相同硬件环境条件下,阿里云MaxCompute和本地SQL Server2008数据库处理大数据的SQL运算效率对比结果如表1所示,可见SQL语句越复杂或者运算数据量越大,云计算相对于传统SQL Server数据库的运算速率优势越能体现出来。

表1 云计算与传统数据库计算效率对比
2.2 货物运送责任时间划分方法步骤
2.2.1 符号与参数说明
本文以货车为直接研究对象,货物运输责任时间为铁路运输全程中货车在各环节应该完成运输作业的最大时间。其中,始发站的站内作业时间为货车装车入线开始,至从车站开出时止的总时间;终到站的站内作业时间为货车到达车站开始,至卸车结束时止的总时间;对于货运OD的货车途经车站,站内作业时间为出发时间与到达时间之差;区段运行的作业时间为前一车站出发时间与后一车站到达时间之差;仅用于会车、越行的中间站和线路所,其作业时间均计入区段运行作业时间内。
责任保障率就是能够在货物运输责任时间范围内完成作业的货车数占总数的百分比。相关符号和参数规定见表2。

表2 符号与参数说明
2.2.2 货物运输责任时间划分和责任保障率计算方法
货物运输责任时间划分和责任保障率计算方法总体步骤如图4所示。
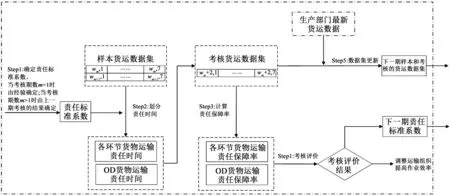
图4 货物运输责任时间划分和责任保障率计算总体步骤Fig. 4 The overall steps of freight transport responsibility time division and responsibility guarantee rate calculation
Step 1:确定各环节责任标准系数
Step 2:划分各环节运输责任时间和OD运输责任时间
(1)
Step3:计算各环节责任保障率
第i车站作业的运输责任保障率为:
(2)
第j区段的责任保障率为:
(3)
货运OD责任保障率为:
(4)
Step4:考核评价
综合考虑运输各环节的责任保障率与责任标准系数的关系,评价每个环节的作业效率变化,并且根据各环节的责任保障率与货运OD责任保障率之间的关系,确定对下一期数据考核的责任标准系数。以车站为例,考核评价方法如下:
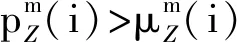
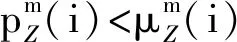
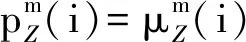
区段的考核评价方法与车站的考核评价方法同理。
Step5:数据更新和动态考核
重复上述Step1~Step5,根据最新的货运记录数据不断更新数据集,及时动态地考核评价货物运输过程中各环节作业时间和效率的变化情况,研究变化原因和对应改善措施,提高货物运输组织生产效率。
3 算例分析
3.1 货车运行轨迹大数据处理
基于2017年5月1日—21日共21 d的铁路货车到发和装卸车记录数据,其中样本货运数据集包括27 173 283条记录,考核货运数据集包括14 029 506条记录。
首先通过Java平台编程读取数据的结构,表3和表4分别为整车货物的货运装卸记录和货运到发记录数据表结构,行分隔符为“/n”,列分隔符为“,”。之后在云平台建立符合该数据表结构的表格,上传并存储数据。

表3 货运装卸记录数据表结构

表4 货运到发记录数据表结构
数据清洗主要包括3个方面:第一,处理不规则字符,排除字符干扰,例如数据文件中String类型的数据含有双引号和未显示的空格,则需用split_part函数和trim函数进行数据清洗;第二,转换数据类型以方便计算,例如货运原始数据中数据类型均为String类型,而时间计算需要用到Datetime类型,故需将进行时间数值运算的数据由String类型转换为Datetime类型;第三,清理无效数据,由于原始数据中可能存在记录不全、缺失、错误或者重复的无效数据,需设置限制条件,以保证数据的可靠性。
数据筛选匹配,即是根据分析的OD不同,在数据库中筛选目标数据,并匹配计算时间分布特征:第一,在云平台上对装卸数据和到发数据的匹配和筛选,主要利用mapjoin等函数,选取目标数据,得到每辆货车在各车站、区段的到发时间、停留状态、装车卸车等情况;第二,对筛选出的目标数据,计算其数学特征,如在车站和区段的停留时间、装卸作业时间等,并统计经过某一车站或区段的所有货车作业时间分布,如平均值、标准差、中位数等。
货车运行轨迹大数据经过上述云计算处理后,根据货车数据筛选分析,发现仅在京广线上样本货运数据集中装卸货车的OD有195对,表5中列出了部分装卸货车的OD,并计算出了其中同一OD间按照相同停站方案运送的货车数。

表5 样本货运数据集京广线部分装卸货车的OD及货车数
3.2 货物运输责任时间划分方法分析
3.2.1 货物运输责任时间划分和责任保障率计算
基于云计算平台的数据筛选匹配结果,考虑到论文篇幅有限,所以选择京广线上衡阳北—大朗运输区段停站方案相同的货车记录为例,验证本文提出的货物运输责任时间和责任保障率计算方法。

表6 衡阳北—大朗运输区段各站段样本货运数据集的数据分析
Step2:根据划分各环节运输责任时间和OD运输责任时间的方法,可以求得运输中各环节货物运输责任时间和货运OD的货物运输责任时间,如表7所示;
Step3:根据公式(2)~(4),求得各环节的责任保障率和货运OD运输责任保障率,如表7所示;

表7 运输责任时间划分和责任保障率计算结果
Step4:根据责任保障率与责任标准系数的关系,对作业效率进行评价,并确定下一考核周期的责任标准系数,如表8所示。
Step 5:数据更新。样本货运数据集更新为2017年5月8日—21日的货运数据,考核货运数据集更新为2017年5月22日—28日的货运数据。不断根据最新的货物运输记录数据进行运输各环节的责任时间划分和评价,可以反映作业效率的波动,以及时调整运输组织方式,保障作业效率。
3.2.2 与传统时间分配方法的对比分析
根据铁路总公司货物承运办法计算,衡阳北—大朗普通整车货物的运到期限为3 d,即4320 min,基于m=1考核周期时的样本货运数据集和考核货运数据集,分别用剩余时间分配法和均值比例分配法计算各环节的分配时间和保障率,结果如表9所示,不同时间分配方法各环节的保障率对比如图5所示。
可以看出,这两种时间分配方法的缺点是由于不考虑站段之间作业的差异性和作业时间的波动性,不符合实际作业规律,所以不同环节的保障率差异较大。如剩余时间分配法中,马坝站内作业时间、江村—大朗的区段作业时间分配时间大于该环节的最大时间,保障率都等于100.00%,说明分配时间偏大,而在始发站衡阳北、终到站大朗和途中编组站江村保障率明显偏小,说明分配时间偏小;同理均值比例法中衡阳北—郴州区段、江村站内保障率偏小,说明分配时间偏小。而货物运输责任时间划分方法的保障率则能够保持在90.00%左右,说明不存在作业时间划分明显偏大或者偏小的情况,更适合作为考核评价的指标。

表9 传统时间分配法的责任保障率

图5 不同时间分配方法各环节保障率对比Fig. 5 Comparison of responsibility guarantee rate in different time distribution methods
4 结论
本文对铁路货物运输责任时间计算方法进行研究,设计了基于大数据的货物运输责任时间划分方法,提出了货物运输全程责任时间和责任保障率的概念,并通过算例验证了该方法的有效性和可适性,得到以下结论:
(1)利用云计算平台,对海量铁路货车运行轨迹大数据进行存储、清洗、筛选分析等操作,能够节省本地空间,大大提高数据管理和处理效率及准确性,降低铁路企业的工作成本和提升工作效率。
(2)通过货物运输责任时间划分和责任保障率的计算,能够给对铁路货运全程各环节划分责任时间,并评价各环节作业效率,且能够根据货车运行轨迹大数据反映的实际情况,实时动态地排除不同作业条件下历史数据对现在运输状态评价的干扰,动态调整考核标准系数,有利于改进货物运输组织工作保障水平。
(3)不同于传统的货物运到期限时间分配方法,本文提出的方法能够体现各环节作业时间的差异性和波动性,考核方法具有更好的可适性和应用前景,为铁路货运责任划分提供了很好的研究新思路。
针对货物运输责任时间划分的研究,根据不同列车、不同货物种类,在铁路运输全程中对作业时间要求存在的差异性进行精细分析,是未来的研究和应用的方向之一。
