基于关联规则的协同过滤改进算法
2019-04-16张小川周泽红桑瑞婷
张小川,周泽红,向 南,桑瑞婷
(1.重庆理工大学 计算机科学与工程学院, 重庆 400054;2.重庆理工大学 两江国际学院, 重庆 401135)
从网易云音乐的歌单、亚马逊的商品到抖音的短视频,推荐系统已经改变了用户的浏览习惯。推荐系统由于具有帮用户做出合适选择的能力在网络技术发展的时代下越来越有意义。
目前,推荐系统中主流的推荐算法有基于内容的推荐、矩阵分解推荐、基于知识的推荐、协同过滤推荐、混合推荐等算法,其中协同过滤算法是基于用户对商品的评分或其他行为(如购买)来为用户提供个性化的推荐,不需要了解用户或商品的大量信息,不必进行内容分析,可较好地实现跨类别项目的推荐[1-2]。该算法根据目标用户的近邻用户(具有相似兴趣的用户)对物品的用户偏好预测(推测)目标用户对物品的偏好从而进行推荐。因此,协同过滤算法被广泛应用于推荐系统中。协同过滤算法有CF based user (基于用户的协同过滤)和CF based item(基于项目于的协同过滤) 两种。由于本文所研究的算法场景是项目增长量大于用户增长量的电影等场景,计算项目相似度比用户相似度复杂,故本文选择在基于用户的协同过滤算法基础上进行研究。
在日常生活中,朋友经常一起购物,是因为朋友对商品有相似的喜好。协同过滤也是在这类场景下产生的一种算法。它可以根据目标用户的朋友(近邻)购买的商品,对目标用户实现较为准确的推荐。协同过滤算法主要根据历史评分数据进行推荐,而随着用户和项目的急速增长,用户只能对有限的项目进行评分,项目也只能得到有限用户的评分,评分数据变得越来越稀疏[3],严重影响了推荐算法的准确性。在数据稀疏的情形下真正具有相似兴趣的用户也不能被有效提取出来。
针对上述问题,专家学者提出了一系列的解决办法。李文海等[4]提出了用默认值填充缺失数据的矩阵填充技术。韩亚楠等[5]提出采用用户平均评分填充评分矩阵缺失值。李远博等[6]提出用PCA对评分矩阵降维,保留信息量最大的几个特征,在保证不影响结果的提前下缓解数据稀疏性带来的影响。邓爱林等[7]通过基于项目的协同过滤算法对用户未评分项目进行评分预测,将评分预测值填充到评分稀疏矩阵中。陈宗言等[8]通过引入项目的特征,计算项目间特征的相似度,预测用户对未评分项目的评分,填充稀疏矩阵。Elahi M等[9]提出了主动学习,有选择地选择要呈现给用户的项目以获得其评分并最终提高推荐准确性。Najafabadi M K等[10]引入用户与项目的隐式交互记录,计算基于特征的项目相似度实现推荐。王潘潘等[11]提出了一种改进的加权 Slope one 协同过滤推荐算法,计算相似度选择最近邻,用Slope one算法预测值填充用户未评分项。Kim K等[12]通过社交网络分析(SNA)和聚类技术来提高准确性。Tong C等[13]结合时间对用户和项目的影响,提出了TimeTrustSVD,一种集成时间信息、信任关系和评价得分的协同过滤模型。肖文强等[14]引入用户共同评分权重、物品时间差因素以及流行物品权重,将兴趣相似的用户聚成一类,在类内应用推荐算法分别为用户进行推荐。孟桓羽等[15]通过建立基于图的评分数据模型,将传统的协同过滤算法与图计算及改进的KNN算法相结合来提高推荐准确度。张海霞等[16]引入加权异构信息来缓解数据稀疏性造成的推荐不准确问题。
上述学者提出的方法都可以在一定程度上缓解数据稀疏性问题,但都没有考虑到项目间存在的相关性,或者仅考虑到两个项目之间的关联关系[17]。为了缓解稀疏性问题,本文提出了基于关联规则的协同过滤改进算法。即设置相似度阈值,选定目标用户的k个近邻用户,若选择的k个近邻与目标用户的相似度不小于阈值,则按协同过滤算法推荐,否则应用关联规则技术进行推荐。协同过滤算法按照传统的基于用户的协同过滤算法进行推荐,而用关联规则技术进行推荐则先应用Apriori算法,挖掘出强关联规则,从而发现项目间的关联关系,以支持度和置信度的乘积作为推荐度进行推荐。
1 基于用户的协同过滤
基于用户的协同过滤算法的推荐思想是:如果某些用户评分高的项目重合度高,那么这些用户是兴趣度相似的用户,对其他项目的评分也相似。该算法首先建立用户项目评分矩阵,然后根据目标用户与其他用户的共同评分项计算出目标用户与其他用户之间的相似度,用相似度选取目标用户的近邻,目标用户对未评分项目的评分依据近邻用户对该项目的评分进行预测,最后选取评分高的项目进行推荐。
1.1 相似度计算
评估相似度的方法有多种,如余弦相似度及调整的余弦相似度、皮尔逊相关系数(Pearson相关系数)、Jaccard相似系数、Tanimoto系数(广义Jaccard相似系数)、对数似然相似度等。其中常用的3种相似度度量方法是:余弦相似度,修正的余弦相似度,Pearson相关系数。
要对目标用户进行推荐首先要建立用户评分矩阵,假设数据中有m个用户n个项目,数据转化的m行n列的评分矩阵见式(1)。其中:i行j列的元素Rij代表的是用户i对项目j的评分;?代表的未评分或缺失值。
(1)
用户i和j相似度的计算方法是:首先得到用户i和用户j共同评分的所有项目,然后通过相似度计算方法计算用户i和j的相似度,记为sim(i,j)。
余弦相似度:用两个向量的余弦值作为衡量相似度的标准,两个向量夹角越小,相似度越强。设Iij是用户i和j共同评分的项目集合,Ric是用户i对项目c的评分,Rjc是用户j对项目c的评分,则
(2)

(3)
(4)
考虑到用户之间评分尺度不同这个重要因素,选择修正余弦相似度和Pearson相似度。经实验证明:Pearson相似度效果最好,本文选择Pearson相似度计算方法。
1.2 邻居集的选择
根据上述选出的相似度计算方法计算目标用户与其他用户的相似度,将相似度降序排序,选择前k个作为该目标用户的邻居集。
1.3 预测评分
选择好目标用户i的最近邻居集合为NBSi,根据邻居集中邻居对目标用户未评分项目的评分预测目标用户的评分。目标用户i对未评分项目c的预测评分计算公式为
(5)
1.4 传统基于协同过滤算法不足分析
由于互联网推动的电子商务的发展,用户数目和项目数目呈指数级增长,而一个用户对项目的购买能力有限,只会购买庞大项目中的少数项目而且用户不一定对购买过的项目都进行评分,因而造成用户评分数据极度稀疏,某一个用户的评分项目不及总项目的1%。相似度计算依靠的是用户间的共同评分,数据稀疏情况下,相似度计算方法不能准确计算用户间的相似度,从而无法选择和目标用户兴趣品味相似的邻居集,导致目标用户对未评分项目评分预测不准确,影响推荐质量。
为了降低数据稀疏性造成的推荐效果不佳的影响,本文在计算相似度时先统计用户与邻居的共同评分项目数,设置计算相似度的最小共同项目数,当共同评分的项目数小于设置值时则将相似度设置为0。然后设置相似度阈值,若选择的邻居集中的用户与目标用户的相似度都不小于阈值,则按协同过滤算法推荐,否则应用关联规则技术进行推荐。
2 基于关联规则的协同过滤改进算法
关联规则是数据挖掘技术中挖掘项目相关性的一类规则,最早由Agrawal等于1993年提出[18],能够揭示项集之间的关联。关联规则技术最初应用在零售业中,把具有相关性的商品进行打包销售。基于关联规则的推荐算法利用关联规则挖掘出项目间的相关性,将用户未购买但与已购买项目相关性大的项目推荐给用户。其中Apriori算法[19]是最经典的关联规则挖掘算法。
2.1 关联规则概述
关联规则挖掘已经被广泛采用来提升推荐质量,挖掘用户的兴趣度模式。关联规则形如X={x1,x2,…,xm}⟹Y={y1,y2,…,yn},意味着用户购买了X则很大程度上可能会购买Y。其中,X和Y分别称为关联规则的前项和后项。常用的关联规则挖掘算法有Apriori算法和FP-Growth算法两种。本文选择最为经典的Apriori算法。以下是关联规则相关概念。
定义1 项集: 项集是项的集合。一条购买记录中每一个item为一个项,包含k个项的项集称为k项集。
定义2 支持度(support):假设规则X⟹Y,支持度表示X作为前项Y作为后项在所有事务中同时出现的概率。最小支持度是X、Y同时出现的最小概率,是评估支持度的一个阈值。

(6)
定义3 置信度(confidence):假设规则X⟹Y,置信度表示在购买X的情况下购买Y的概率。最小置信度是评估置信度可靠性的一个阈值,表示关联规则的最低可靠性。
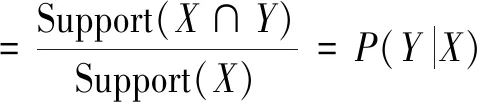
(7)
定义4 频繁项:经常出现在一块的物品的集合。也就是关联规则的支持度不低于最小支持度的前后项组成的项集称为频繁项,否则为非频繁项。
定义5 强关联规则:支持度不小于最小支持度且置信度不小于最小置信度的规则。
Apriori算法主要包含两个步骤:首先找出事务数据库中所有不小于用户指定的最小支持度的数据项集(频繁项集);然后利用频繁项集结合最小置信度生成强关联规则。此算法基于性质:若一个项集是非频繁项集,则它的所有超集也是非频繁项集。该算法有两个关键步骤分别为连接步和剪枝步。
关联规则挖掘所需的数据为事务型数据,一条事务型记录代表一次交易(购买),所以需将数据转化为事务型数据。
采用Apriori算法进行数据挖掘,其输入为:处理成事务型的数据集,最小支持度minSupport,最小置信度minConfidence;其输出为:强关联规则。具体步骤如下:
1) 扫描全部数据集,产生候选1-项集C1;
2) 根据最小支持度,由候选1-项集C1产生频繁1-项集L1;
3) 对k>1,重复执行步骤4)、5)、6);
4)由Lk执行连接和剪枝操作,产生候选(k+1)-项集C(k+1);
5) 根据最小支持度,由候选(k+1)-项集C(k+1),产生频繁(k+1)-项集L(k+1);
6) 若L不空,则k=k+1,转步骤4);否则,转步骤7);
7) 根据最小置信度,由频繁项集过滤掉低于最小置信度的规则产生强关联规则。
2.2 基于关联规则的评分预测
协同过滤算法中计算相似度的方法是Pearson相关系数度量方法,依据的是用户对项目的显式评分,而在数据稀疏性的情况下,评分数很少会导致相似度计算不准确影响推荐精度。因此,对于由于共同评分数目稀少而不能用传统协同过滤算法准确推荐的则用关联规则进行推荐,缓解数据稀疏造成的负面影响。
由上述Apriori算法得出的强关联规则组成集合Rrules,本文对Rrules里的关联规则进行拆分,拆分为关联规则后表示为只有一个项目的形式,即将关联规则拆分成多对一或一对一的形式,拆分形式如下:

(8)
令S为规则的支持度,C为规则的置信度,recom为规则的推荐度,可得:
recom(X⟹Y)=S(X⟹Y)·C(X⟹Y)
(9)
本文结合项目间的关联关系,利用数据挖掘中的关联规则技术缓解数据稀疏性对推荐质量的影响。基于关联规则计算用户对项目预测评分的公式为
(10)

MAI的形成:首先,找出后项为目标项目的关联规则;其次,将找到的关联规则按推荐度值降序进行排列;最后,设置推荐度阈值,提取不小于推荐度阈值的关联规则,这些关联规则的前项组成MAI。
2.3 基于关联规则的改进推荐算法
设置用户间的相似度阈值为α,利用Pearson相关性度量方法计算目标用户i和其他用户间的相似度,然后对相似度进行降序排序,选择前k个用户作为目标用户的最近邻,m为第k个用户,则用户i对项目c的预测评分值计算公式如下:
(11)
3 实验分析
首先介绍实验环境和所选用的数据集,然后介绍实验内容,最后根据选用的数据集将本文算法与传统算法相比较得出实验结果。
3.1 实验环境和实验数据集
实验环境如下:笔记本,CPU为 @1.60 GHz 1.80 GHz,内存8 GB,编程环境Anaconda-Spyder(python 3.6)。
实验数据集:美国明尼苏达大学GroupLens小组给出的100k的movieLens 数据集。采用该数据集中的u.data,包含完整的用户数据集,有943个用户对1 682个项目的100 000个评分。每位用户至少有20个评分数据。用户和项目从1开始连续编号,数据是随机排列的。这个列表是以用户id|项目id|时间戳分割的一个列表。评分集合为{1,2,3,4,5},评分越大证明用户对所评电影越满意。实验中将数据随机分成10份,一份作为测试集,其余作为训练集。
3.2 评价指标
评估推荐系统性能的指标有很多,如平均绝对误差、均方根误差、召回率、准确率、覆盖率、多样性、流行度、F1指标和AUC等。本文采用平均绝对误差MAE(mean absolute error)和均方根误差RMSE(root mean squared error)来评估推荐系统的性能。MAE、RMSE主要计算预测评分值与用户真正评分值之间的误差程度,MAE、RMSE值越小,推荐系统的推荐性能就越好。
(12)
(13)
其中:u为用户;i为项目;T为测试集;rui为用户u对用户i的真实评分;为用户u对用户i的预测评分。
3.3 实验内容与实验结果
本文将实验分为两部分,首先是对影响关联规则质量的指标最小支度、最小置信度进行比较,选择最佳值作为接下来实验的基础;然后将本文提出的算法与传统算法相比较,证明本文算法的有效性。
3.3.1选择关联规则最优支持度、置信度的实验
在进行关联规则实验前,要对数据进行处理。由于关联规则挖掘输入的是事务型数据,因此要将数据集的数据处理成事务型数据,再进行实验。将评分不小于3的视为购买,加入事务项,否则视为不购买。
在关联规则挖掘算法中,最小支持度和最小置信度是影响关联规则的两个主要因素。为了获取关联规则的最优最小支持度、置信度,设计如下实验:通过设置一系列关联规则推荐算法的最小支持度和最小置信度,观察关联规则数目随最小支持度和最小置信度的变化规律。实验结果如图1所示。考虑到数据量较大,设置的支持度范围为15%~40%。实验首先将最小支持度设为15%,观察最小置信度在20%~70%的MAE和RMSE的变化,找出最佳最小置信度。然后,设置最小置信度为找出的最佳最小置信度,观察最小支持度在15%~40%的MAE和RMSE的变化,找出最佳最小支持度。实验结果如图2、3所示。

图1 最小支持度在不同置信度下与规则数目的关系
由图1可以看出:在最小置信度一定的情况下,关联规则推荐算法的规则数随着最小支持度的增加不断下降直至规则数为0,而在最小支持度一定的情况下,置信度越大,规则数目越少。由此可知,最小支持度、置信度太小,规则数太多,关联规则质量比较低;最小支持度、置信度太大,则会把有效规则过滤掉。因而,在合适的最小支持度、置信度时关联规则质量较高。

图3 最小置信度为0.5,最小支持度与MAE、RMSE的关系
由图2可知:在最小支持度设置为0.15,最小置信度在0.5时MAE、RSME最小,算法获得最优推荐质量,最佳最小置信度为0.5。由图3可知:在最佳最小置信度下,最小支持度为0.2时,MAE、RSME最小,算法获得最优推荐质量。因此,当最小支持度为0.2,最小置信度为0.5时,关联规则推荐算法取得最优推荐质量。
3.3.2 本文算法有效性实验
为了验证本文提出的基于关联规则的协同过滤改进算法的有效性,在上述最佳最小支持度、置信度条件下,将基于关联规则的协同过滤算法(ARCF)与传统基于用户的协同过滤算法(UCF)、基于用户平均值填充的协同过滤算法(UACF)进行对比实验。在测试数据集上,这些算法在不同最近邻上的性能表现见图4、5。
由图4、5可以发现:本文提出的算法的MAE、RMSE平均都比传统协同过滤算法小,即本文算法推荐的准确度更高。可以得出,关联规则技术的引入可以提高推荐准确性,一定程度缓解数据稀疏性问题。当近邻数目为90时,基于关联规则的协同过滤推荐算法推荐质量最优。

图4 三种算法在不同邻居数目下MAE的比较
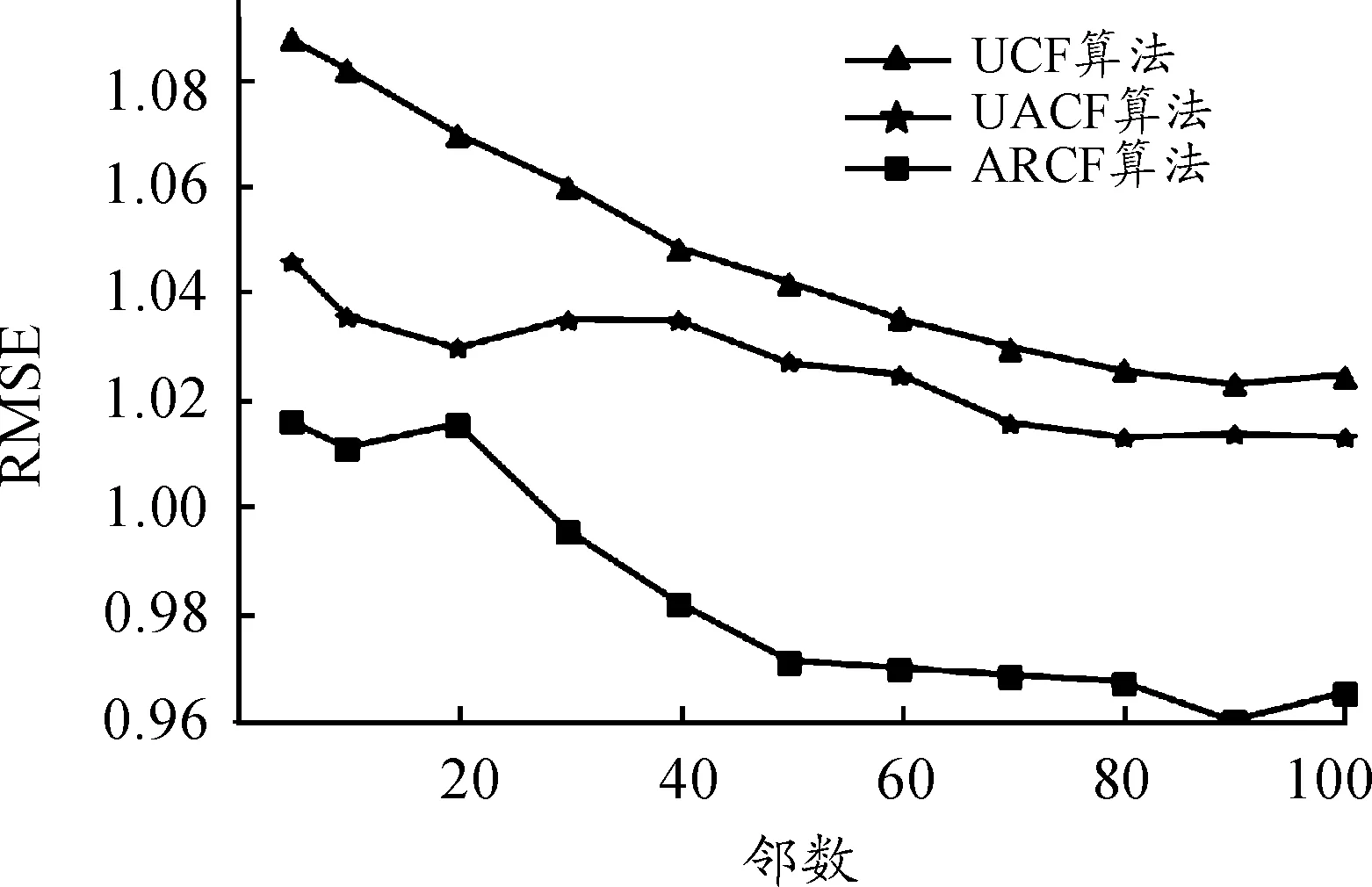
图5 三种算法在不同邻居数目下RMSE的比较
4 结束语
协同过滤算法由于其简单、可实现跨项目推荐等优点成为目前在推荐系统中应用最广泛、最成功的推荐算法,但是该算法的实现依赖用户项目的显式评分数据。当今互联网行业蓬勃发展,各种线上网站发展迅速,用户量和数据量急速上升,由于用户购买能力有限造成的评分数据稀疏性越来越严重,因而协同过滤算法推荐效果不佳。针对数据稀疏性问题,本文考虑到项目间存在的关联关系,提出了基于关联规则的协同过滤改进算法。设置相似度阈值,若选择的邻居集中的近邻用户与目标用户的相似度都不小于阈值,按协同过滤算法推荐,否则应用关联规则技术进行推荐。经过实验证明:基于关联规则的协同过滤改进算法在一定程度上缓解了数据稀疏性,提高了推荐精度。在基于关联规则的推荐算法中,如果数据中具有关联关系的项目较少,提取出来的强关联规则就较少,关联规则起不到应有的推荐作用。解决此问题是下一步的研究工作。
