基于分数阶累加的灰色GM(1,1|sin)模型及其应用
2019-04-13李亚男
李亚男
(广东理工学院基础教学部,广东肇庆526100)
1 引言
针对“小样本、贫信息”的系统序列的预测问题,邓聚龙教授提出了灰色系统理论[1],其中灰色预测是该理论中的核心体系.GM(1,1)模型作为灰色预测模型中的典型代表,已被广泛应用于众多领域[2−4].研究表明,该模型对近似齐次指数律的数据序列的模拟预测具有较高的精度,而对其他一般序列尤其是振荡序列的模拟预测效果并不理想.为拓广灰色预测模型的适用范围,许多学者针对不同类型的序列进行了深入研究,提出了一系列的灰色预测模型.针对非齐次指数律特征的数据序列的预测问题,战立青等[5]提出了NHGM(1,1,k)模型,并将其应用于北京地铁客流量和江苏省财政科技投入预测中;针对部分指数特征并含时间幂次项的数据序列的预测问题,钱吴永等[6]提出了GM(1,1,tα)模型,并将其应用于某省沿海高速公路软土地基沉降预测中;为更好地描述系统的非线性的本质,王正新等[7]提出了GM(1,1)幂模型,并将其应用于南京市水路货运量预测中;为减少以离散形式估计参数且用连续函数模拟预测过程中产生的误差,谢乃明等[8,9]提出了离散灰色预测模型,并将其应用于纯指数序列模拟中;针对振荡序列的预测问题,毛树华等[10]构建了GM(1,1|sin)模型,并将其应用于城市交通流的模拟预测中.相比于传统GM(1,1)模型,以上拓展模型在各自应用中都取得了更好的模拟预测效果,具有一定的实用性.
为充分利用系统的新信息,本文结合分数阶累加思想[11,12],将文献[10]的GM(1,1|sin)模型中对原始序列的一阶累加方式转变为分数阶累加.由于GM(1,1|sin)模型是利用离散方程估计参数,而预测时采用的是连续函数,所以在从离散到连续的转换过程中不可避免地会产生误差.为尽量减少转换误差,本文在分数阶累加的基础上,对GM(1,1|sin)模型的白化微分方程进行推导,构建了分数阶累加GM(1,1|sin)模型.由于模型参数的不同,模拟预测精度也有所不同,本文采用粒子群算法对模型参数进行优化,使模型具有最高的模拟精度,且更加有效应用于振荡序列的模拟预测.最后以城市交通流预测为例,证实了与GM(1,1|sin)模型相比,本文提出的分数阶累加GM(1,1|sin)模型显著提高了预测精度.
2 GM(1,1|sin)模型简介
定义 1 设非负序列X(0)={x(0)(1),x(0)(2),···,x(0)(n)},称X(1)={x(1)(1),x(1)(2),···,x(1)(n)}为X(0)的一阶累加生成序列,其中

Z(1)={z(1)(1),z(1)(2),···,z(1)(n)}为X(1)的紧邻均值生成序列,其中

定义2 方程
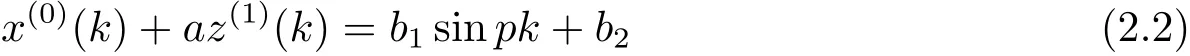
称为GM(1,1|sin)模型.将一阶微分方程

称为GM(1,1|sin)模型的白化方程.
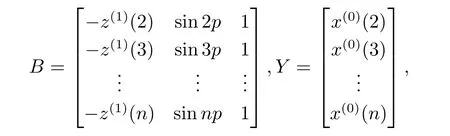
则GM(1,1|sin)模型参数列的最小二乘估计满足

在已知p值的前提下,利用方程(2.4)可求解得到模型的各个参数,再将这些参数代入到白化方程(2.3)中,则可求出微分方程的数值解即模型的预测函数.从预测系统的角度出发,模型的预测函数即为模型的时间响应函数,对其离散化可得到时间响应序列(k=1,2,···).根据一阶累加生成公式(2.1),对做一阶累减还原可以得到原始序列的模拟值(k=1,2,···).
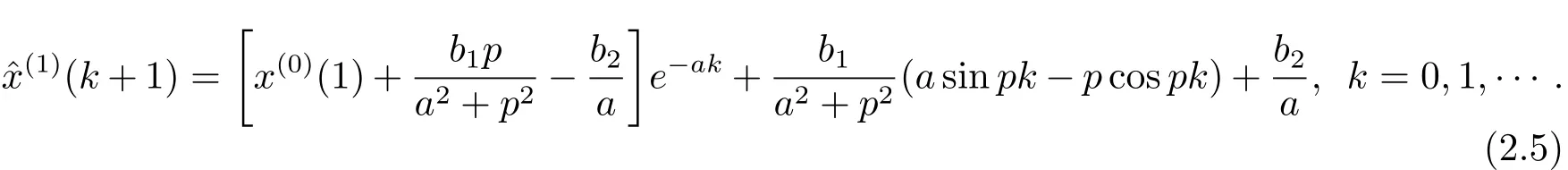
一阶累减还原值为
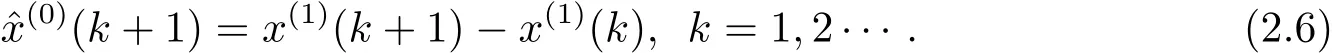
3 基于分数阶累加的GM(1,1|sin)模型的构建
定义 3 设非负序列X(0)={x(0)(1),x(0)(2),···,x(0)(n)},称X(r)={x(r)(1),x(r)(2),···,x(r)(n)}为X(0)的r(r≥0)阶累加生成序列,其中
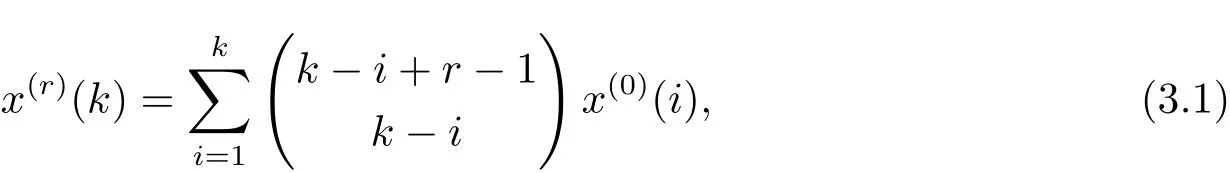
且规定
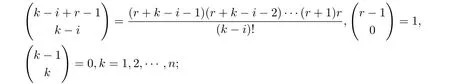
称矩阵
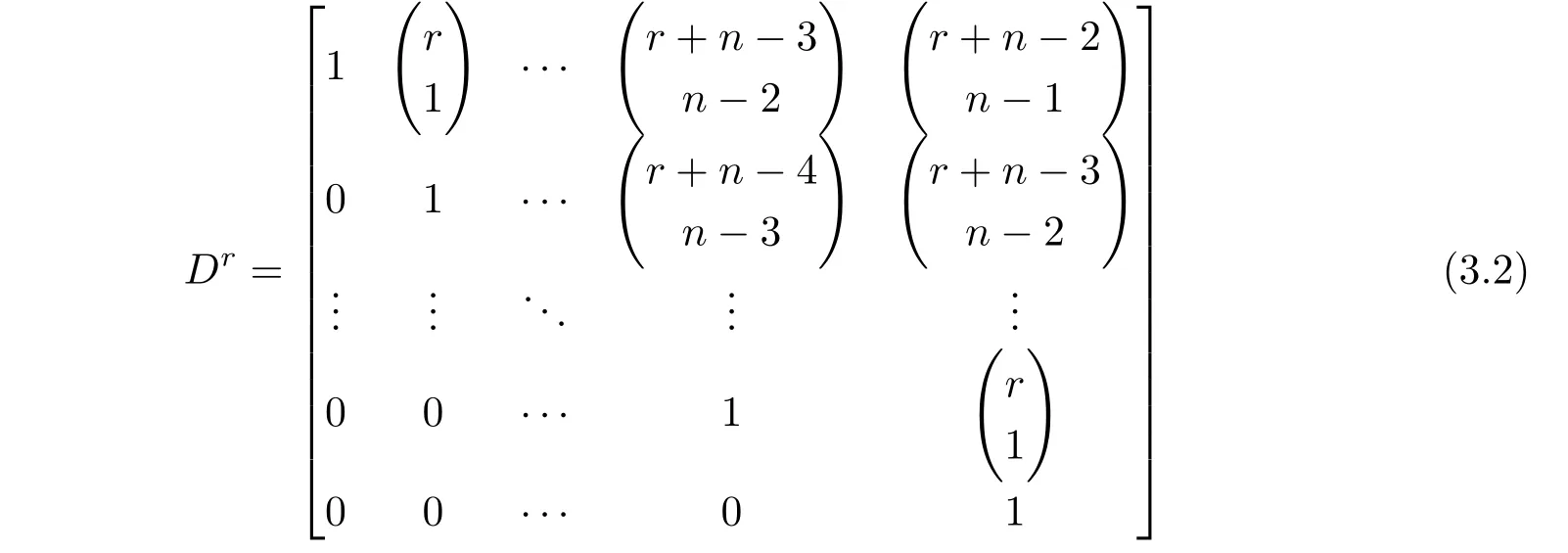
为r阶累加生成矩阵,X(r)可表示为

称Z(r)={z(r)(1),z(r)(2),···,z(r)(n)}为X(r)的紧邻均值生成序列,其中
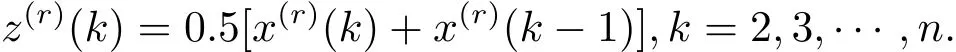
由于GM(1,1|sin)模型利用离散方程(2.2)估计参数,且通过由微分方程(2.3)求解得到的时间响应序列进行模拟预测,所以在从离散到连续的转换过程中不可避免地产生误差,此误差将直接影响到模型的模拟预测精度.为尽量减少此误差,以提高模型的模拟预测精度,本文利用积分运算对白化方程进行推导,得到近似程度较高的离散方程.
现对序列X(r)建立结构形式同方程(2.3)的一阶线性微分方程
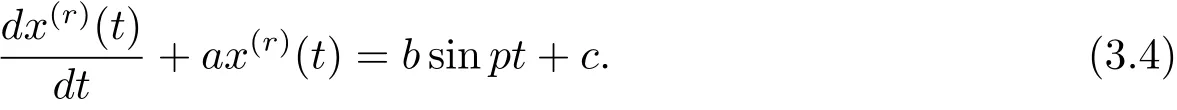
在区间[k−1,k]上对式(3.4)两边同时积分,得
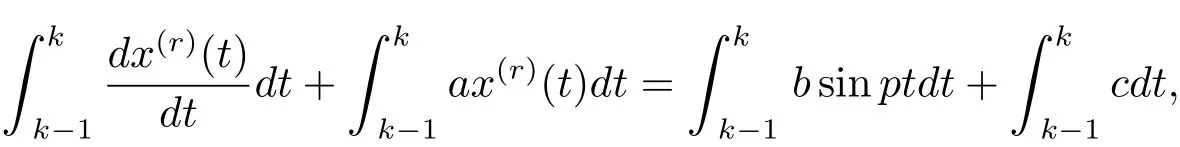
则
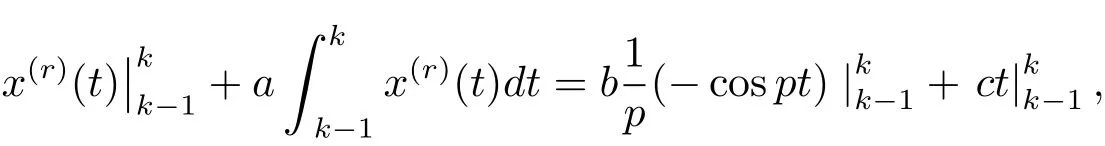
即

利用三角函数和差化积公式,可得

用背景值z(r)(k)近似代替,并作如下定义.
定义4 称方程
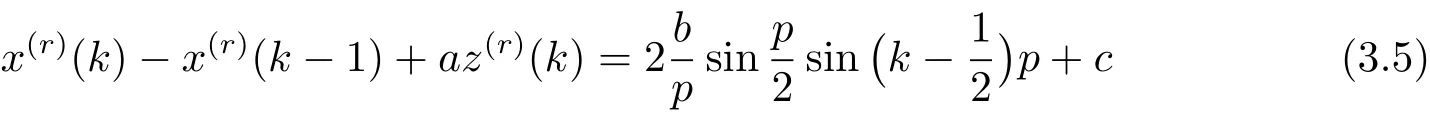
为基于r阶累加的GM(1,1|sin)模型(简称r阶GM(1,1|sin)模型).方程(3.4)为模型的白化方程.
令
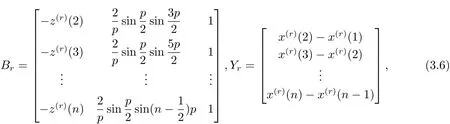
由最小二乘估计可得模型参数列

同GM(1,1|sin)模型的预测原理,将求解得出的参数代入方程(3.4)可得到模型的时间响应函数(t).对其离散化可得模型的时间响应序列(k)(k=1,2,···),再经r阶累减还原可得原始序列的模拟值(k)(k=1,2,···).
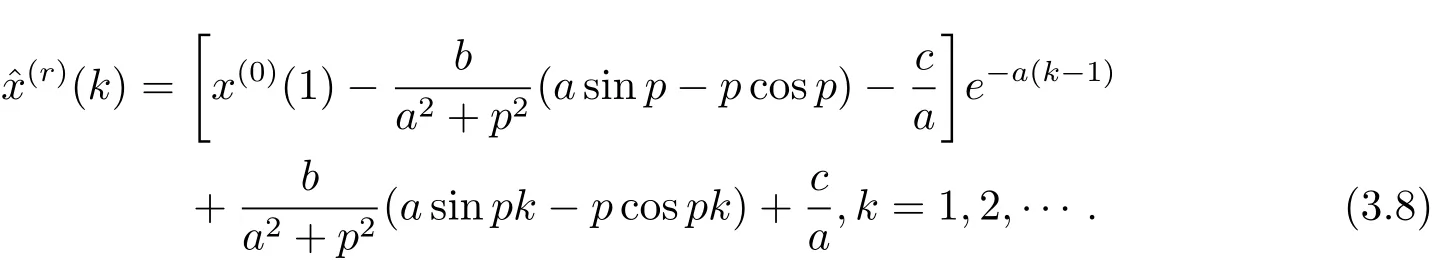
r阶累减还原值为

证 由于r阶GM(1,1|sin)模型的白化方程(3.4)为非齐次的一阶线性微分方程,若令P(t)=a,Q(t)=bsinpt+c,则由非齐次的一阶线性微分方程的通解公式可得
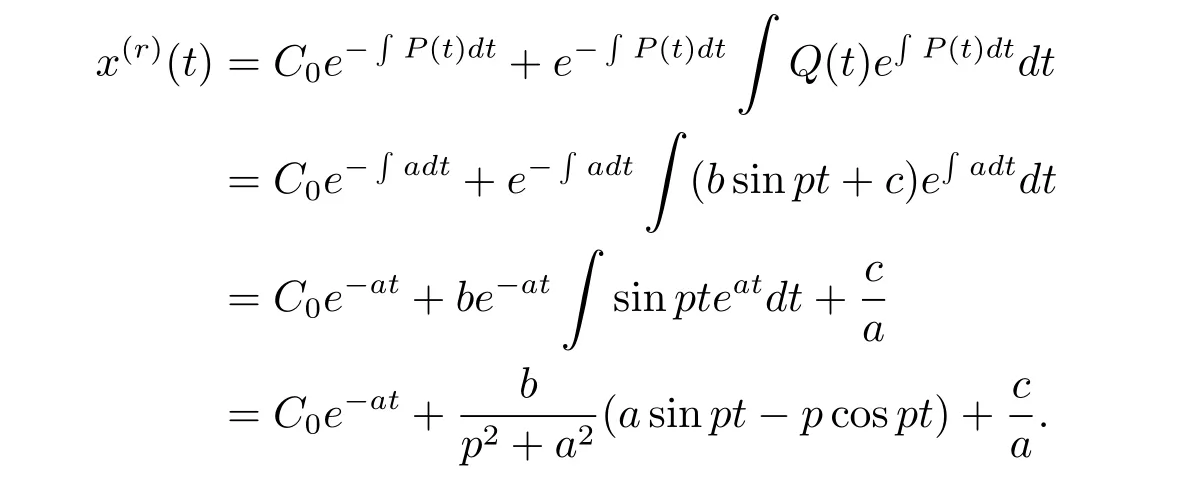
令t=k,则x(r)(t)=x(r)(k).于是可得r阶GM(1,1|sin)模型的时间响应序列为

令k=1,得
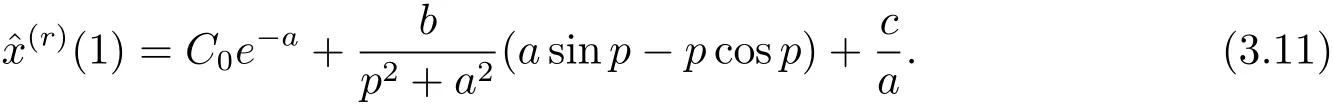

将C0代入式(3.10),得

由于X(r)=X(0)Dr(其中Dr为定义3中r阶累加生成矩阵),则与原始序列X(0)的模拟值之间满足.又矩阵Dr的行列式,则矩阵Dr可逆.故.于是r阶累减还原值为

4 r阶GM(1,1|sin)模型参数p和累加阶数r的确定
上述r阶GM(1,1|sin)模型是基于参数p和累加阶数r确定的前提下建立的.一般情况下,p和r的取值不同,模型的模拟精度也会相应不同.平均相对误差是判别灰色预测模型的模拟效果优劣的常用准则,因此,为达到最优的模拟效果,本文以平均相对误差最小化为目标,模型参数之间的关系以及p和r自身的取值范围为约束,建立如下非线性优化模型
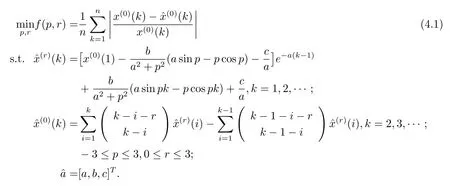
为得出p和r的最优值,本文采用粒子群优化算法(简记为PSO)对该优化模型进行求解.PSO是由Eberhart博士和Kennedy博士于1995年提出的一种新的进化算法[13],其源于对鸟群捕食的行为研究.由于PSO具有概念简单、参数少和易于计算与编程等优点,所以在函数优化和神经网络训练等领域得到了广泛的应用[14].
PSO的基本思路是:首先对优化问题初始化一组随机解,每个随机解都视为搜索空间中的“粒子”,然后通过迭代找到最优解.在每一次迭代中,所有粒子都有一个由被优化的函数决定的适应值.基于适应值,粒子本身所找到的最优解称为个体极值(pBest),整个种群目前找到的最优解称为全局极值(gBest).当找到这两个极值时,粒子根据以下公式来更新自己的速度v和位置x:

其中ω是惯性权重,它决定了粒子先前速度对当前速度的影响程度,起到平衡算法全局搜索和局部搜索能力的作用[15].当取值范围在0.9和1.2之间时,优化效果较好;c1和c2是学习因子,这两个常数使粒子具有自我总结和向群体中优秀个体学习的能力,从而向最优点靠近.c1和c2通常都取等于2,并且范围在0和4之间;rand()为在[0,1]之间的随机数.粒子当前的速度决定了粒子下一步搜索的距离和方向,且有一个最大速度Vmax,最大速度决定粒子在每一次迭代中最大的移动距离,通常设定为粒子的范围宽度.整个算法停止准则是达到最大迭代次数或获得可以接受的满意解.
基于粒子群算法的r阶GM(1,1|sin)模型的建模求解步骤如下:
步骤1取粒子数为30,在问题可行域中初始化所有粒子的位置和速度.
步骤2取平均相对误差即目标函数(4.1)作为适应度函数,计算出每个粒子的适应值.分别比较每个粒子的适应值与个体极值pBest和全局极值gBest之间的关系,如果前者优于后者,则将当前粒子位置设置为pBest位置和gBest位置.
步骤3按照式(4.2)和(4.3)更新粒子的速度和位置.
步骤4循环回到步骤2.终止条件设置为达到最大迭代次数2000或所有个体极值的最大值与全局极值之间的误差小于10−25.若满足终止条件,则转到步骤5.
步骤5输出全局极值以及相应的原始序列的模拟值ˆx(0)(k),算法结束.
5 应用实例
为了验证本文提出的分数阶累加GM(1,1|sin)模型的模拟预测效果,以文献[10]中的数据为例,原始数据为纽约市某天6时至18时的交通流量(以1小时为间隔),即
易见,该序列为振荡序列.为体现本文提出的新模型的优化效果,对序列X(0)分别建立文献[10]中GM(1,1|sin)模型x(0)(k)+az(1)(k)=b1sinpk+b2,累加阶数r=1时的r阶GM(1,1|sin)模型和r阶GM(1,1|sin)模型得到的模拟值及平均相对误差结果见表1和图1.

表1:三种模型的模拟结果比较
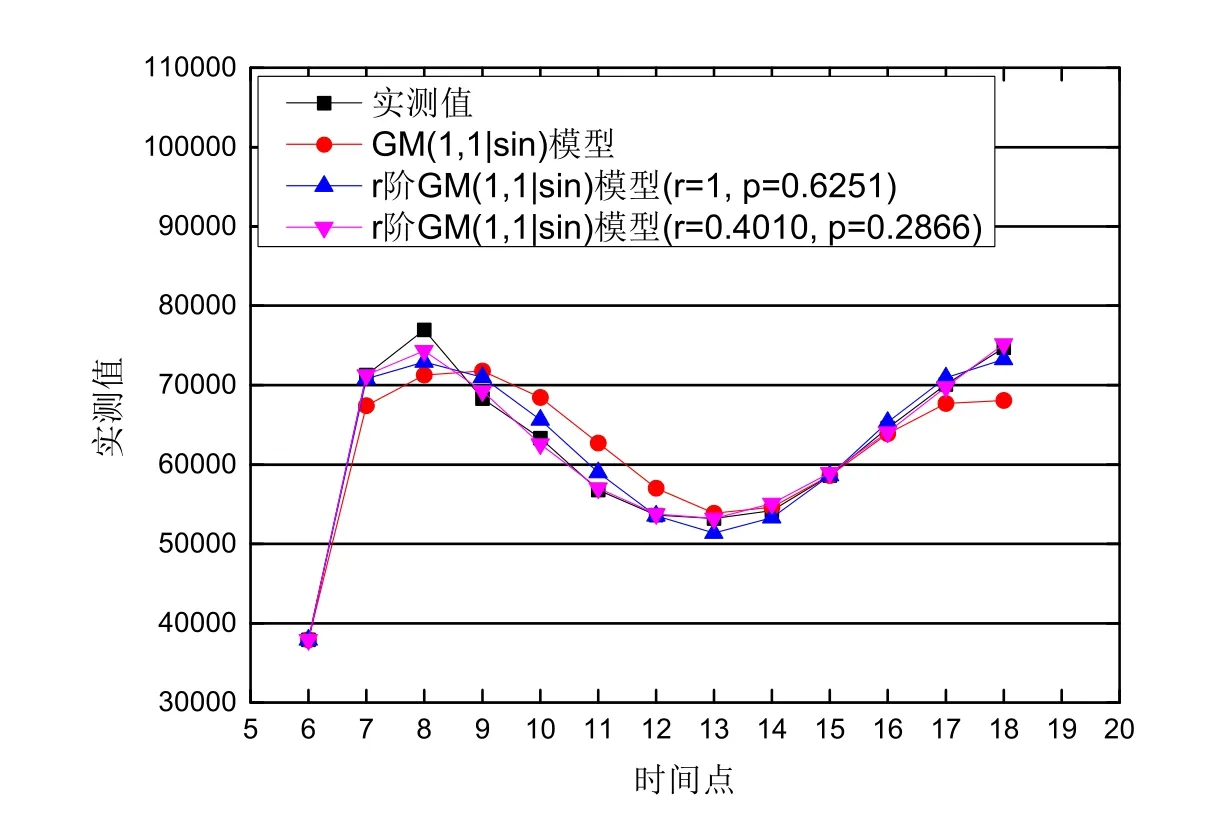
图1:三种模型对交通流的模拟预测曲线
由表1可以看出,累加阶数为1时的r阶GM(1,1|sin)模型的平均相对误差为2.0760%,显著小于GM(1,1|sin)模型的4.4651%,说明新模型能有效较少离散到连续的转换误差.同时,r阶GM(1,1|sin)模型的平均相对误差仅为0.8280%,进一步提高了模拟精度.从图1同样可看出,r阶GM(1,1|sin)模型的预测效果要显著优于GM(1,1|sin)模型.综合分析说明,与GM(1,1|sin)模型相比,本文提出的r阶GM(1,1|sin)模型能更准确地反映交通流的变化规律,能更好地适应振荡序列的模拟预测.
6 结语
由于振荡序列具有随机性和不稳定性的特点,所以利用传统灰色模型难以得到满意的预测效果.为此,本文提出了基于分数阶累加的GM(1,1|sin)模型,一方面利用了分数阶蕴含着的“in between”思想,能充分利用系统的新信息;另一方面利用了对白化方程推导的方式构建模型,能有效减少模型从离散到连续的转换中所带来的误差.实例表明,采用粒子群算法找到最优参数,可使新模型对振荡序列的预测效果好于现有的GM(1,1|sin)模型,并且达到较高的精度.
