位场数据处理算法的数据挖掘试验与应用
2019-04-08魏华敬尹宏伟姜素华赵斐宇
魏华敬, 尹宏伟, 姜素华, 汪 刚, 赵斐宇
(1. 南京大学 地球科学与工程学院;能源科学研究院,南京 210023;2. 中国海洋大学 海洋地球科学学院; 海底科学与探测技术教育部重点实验室,山东 青岛 266100)
0 引 言
数据挖掘是从海量数据中挖掘知识的技术,随着大数据时代的到来,数据挖掘发展迅猛。作为一种通用的技术,数据挖掘在各行业都扮演着举足轻重的作用[1]。地球物理学是通过定量的物理方法研究地球以及寻找地球内部矿产资源的学科,重力勘探是地球物理的方法之一,通过地表测得的重力异常确定地表以下的构造或地质体位置的方法[2]。地球物理数据作为一种可挖掘的数据,让地质与地球物理学界的专家学者获益匪浅。
位场是一种场的大小与位置有关的场,重力场是位场的一种,通过对位场的变换和处理可以挖掘出场源相关的信息。然而位场数据直接反映场源的能力较差,需要对位场数据进行适当的变换。国内外学者对位场数据的处理方法有一定的研究,Cooper等[3]提出的THDR、Theta Map、HTA等算法提高了边界增强后图像识别的效果;张超等[4]提出的Sigmoid算法实现异常值网格数据的拉升和灰度级像素的压低,凸显了地质体的边界;张冲等[5]提出向下延拓3阶Adams-Bashforth公式法,相比起传统的延拓方法更稳定,不容易产生边界效应,使延拓结果更准确。
本文设计了位场数据处理的Matlab算法[6]:梯度算法,解析延拓算法,边界提取算法,并对规则形体的重力异常使用上述3种方法进行处理,讨论了它们各自的特点。
1 位场数据处理算法
在重力位场中,引力位V的1阶垂向导数为重力异常,则不同的位场数据处理算法。
梯度算法
VZ垂向导数:

(1)
VZ水平0°导数:
(2)
VZ水平45°导数:
Vz45(x,y)≈
(3)
VZ水平90°导数:
(4)
VZ水平135°导数:
Vz135(x,y)≈
(5)
解析延拓算法
向上延拓:
(6)
向下延拓:
(7)
边界提取算法
ReLU:
max(Vzz(x,y),0)
(8)
Leaky ReLU:
max(Vzz(x,y),0.01Vzz(x,y))
(9)
tanh:
tanh(Vzz(x,y)/n)
(10)
sign:
sign(Vzz(x,y))
(11)

2 模型试算
为了验证算法较位场原始数据的优越性以及对场源体的识别效果,建立了若干模型进行计算分析。本文选定地面观测数据区域为51×51点距的平面网格面积,并通过规则形体的重力异常正演公式计算得到重力异常数据[7]。对模型进行以下几种算法的处理,探讨算法各自的特点(见图1)。图中:Vz表示重力异常;Vzz表示重力异常的1阶垂向导数;Vzzz表示重力异常的2阶垂向导数;Vz0,Vz45,Vz90,Vz135分别表示重力异常方位角为0°,45°,90°,135°的水平导数;VzUP和VzDOWN分别表示重力异常向上延拓和向下延拓的计算结果。图中比例尺中的单位:Vz,VzUP,VzDOWN的单位为mGal (1 mGal=10-5m/s2);Vz0,Vz45,Vz90,Vz135和Vzz的单位为E(1E=10-9/s2);Vzzz的单位为nMKS (1nMKS=10-12/(m·s2))
2.1 梯度算法
模型1和2形状如图1(a)、(b)所示,几何形态截然不同的两个模型具有相似的重力异常特征(图1(c)、(d)),模型的垂向1阶和2阶梯度 (图1(e)~(h))表现出了明显的差异,梯度阶次的增加使异常平面图表现出更明显的低频特性,异常的平面特征与场源体的几何形态趋于吻合。模型1和2在0°、45°、90°、135°4个方向的水平1阶梯度如图2所示。场源体处水平梯度产生明显异常条带(图2(a)、(c)、(e)、(g))。
模型3(图3(a))是两个水平位置靠近的条带状场源体,其重力异常(图3(c))和单个条带状场源体模型4(图3(b))产生的异常(图3(d))的平面特征相近,基本不可直接区分。垂向1阶梯度和2阶梯度(图3(e)、(g))能将模型3的相互靠近的两个异常场分离,且2阶分离效果好于1阶。

图1 模型1

图2 模型2

图3 模型3
(a)及其Vz(c),Vzz(e),Vzzz(g);(b)及其Vz(d),Vzz(f),Vzzz(h)
模型5(图4)由3个埋深互不相同的条带状场源体组成,模型的垂向1阶梯度和2阶梯度 (图6(b),(c))随着阶次的增加,异常的低频成分愈发明显,这一规律有利于分离不同埋深的异常体。

图4 模型5平面图和立体图
从梯度算法模型试算的结果可以看出,不同形态的场源体的梯度具有不同的平面特征。梯度算法不仅能将相互靠近的场源产生的叠加异常分离,还能突出浅部场源压制深部,且梯度阶次越高效果越明显。实测重力异常往往是多场源叠加的结果,梯度算法能够分离不同性质的场源产生的异常,有利于分类和解释。

(a) Vz(b) Vzz

(c) Vzzz
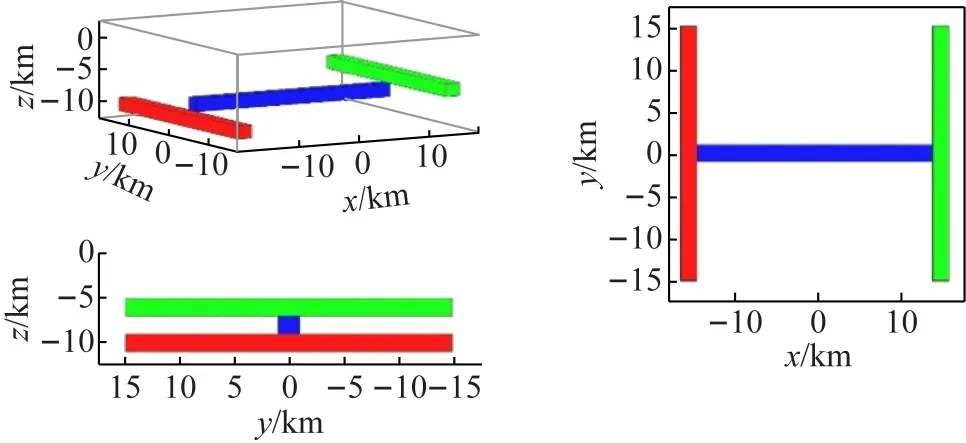
图6 模型6平面图和立体图
2.2 解析延拓算法
模型4由4个不同埋深的条带状场源组成(见图6),模型的重力异常(图7(b))表现出与埋深呈现负相关的态势:由浅到深的场源产生由大到小的异常,对应云图上的颜色为由深到浅。云图7(a)由异常值引起的颜色差异较云图7(b)不明显,模型重力异常的向上延拓结果(图7(a))表现出异常值随深度的差异较延拓前(图7(b))不明显,相对地突出了深部场源的产生的异常,浅部异常受压制。反之,图7(c)中深浅场源引起的颜色差异显著,表示浅部场被突出,深部场被压制。
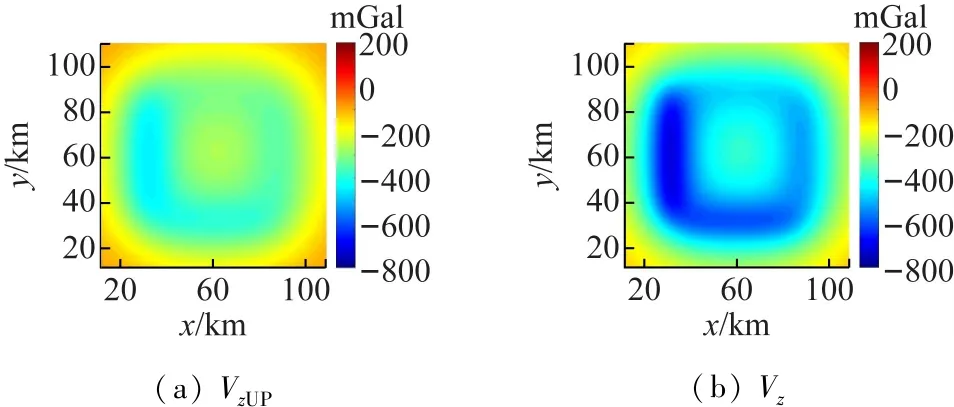
(a) VzUP(b) Vz
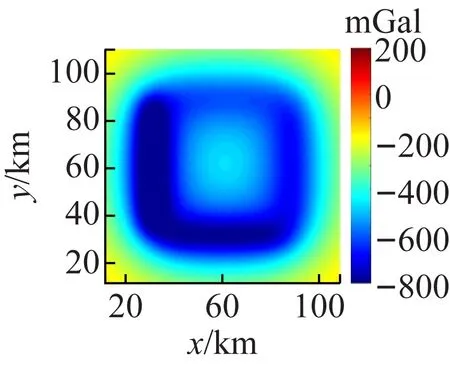
(c) VzDOWN
从解析延拓算法模型试算结果可以得到结论:向下延拓突出浅部异常体,向上延拓突出深部异常体。
2.3 边界提取算法
边界提取算法是增强位场边界识别和检测效果的一种方法[8]。位场垂向梯度在场源边界处发生急剧变化,通过tanh、sign、ReLU、Leaky ReLU等激活函数(见图8)的作用能够一定程度反映场源体的边界。激活函数在深度学习与神经网络当中十分常见,能够一定程度地将线性模型转化为非线性,丰富模型内容[9]。
对于tanh函数,若自变量值绝对值过大,则函数变换后的值通常为1或-1,tanh函数边界提取的效果与sign函数近似,需要通过引入合适的参数n使自变量绝对值缩小。自变量落在0附近函数变化率大的范围内能够更好地由线性信息得到非线性信息,从而使算法更加实用。引入参数后的改良tanh函数为:
tanh(Vzz(x,y)/n)
对模型5的重力异常作边界提取处理,从图9对比可以看出,激活函数对边界的提取效果各有千秋。改良tanh函数用梯度带来反映边界,sign函数在边界附近表现出符号阶跃,ReLU和Laeky ReLU用接近0的极值条带反映了场源覆盖的范围,0值与正值的交界能一定程度反映边界。4种激活函数提取出的模型边界略大于实际边界,边界的宽度能反映场源的深浅。

图8 激活函数
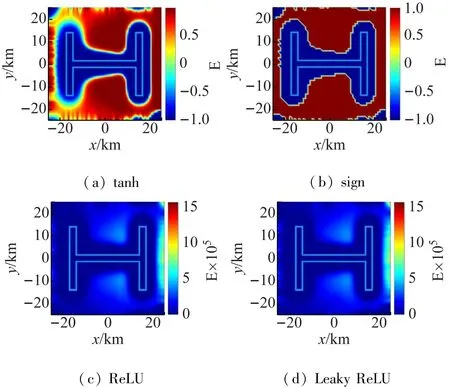
图9 模型5边界提取
3 位场数据挖掘实例
位于我国西北部新疆的塔里木盆地蕴藏着丰厚的石油及天然气资源[10]。塔里木盆地经纬度范围为75°E~9E°,36°E~42°,盆地断裂系统发育十分良好(图10),且大多数油气藏均与断裂系统有着密不可分的关联。本文结合数据挖掘的基本思路将位场处理算法应用于塔里木盆地的布格重力异常数据,得到塔里木盆地断裂系统的相关信息。实验数据来源于BGI(Bureau Gravimetric International)[11],数据精度为2′,数据经纬度为72°E~92°E,34°E~44°。
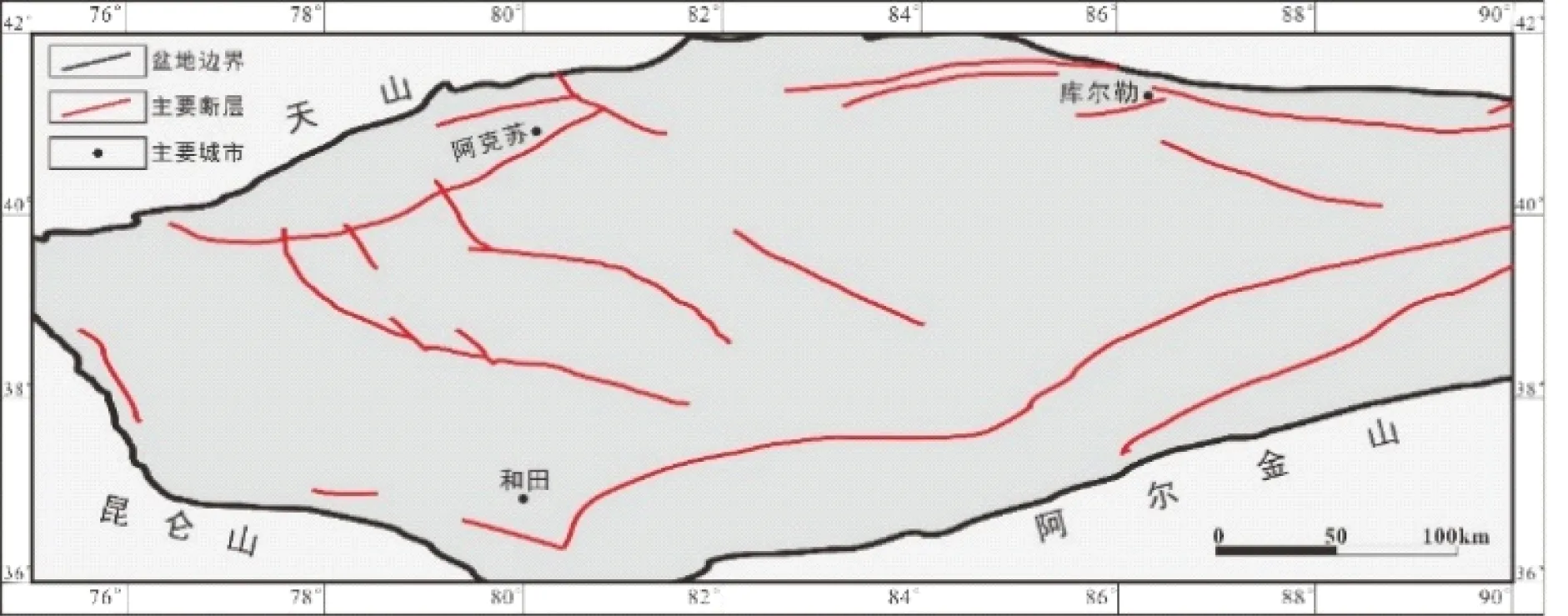
图10 塔里木盆地主要断裂示意图(据文献[13]修改)
3.1 数据清理、集成与选择
BGI将实测重力数据通过基点联测或平滑处理消除地表附近密度不均因素引起的异常。BGI将不同来源的重力数据(如地面重力测量,航空重力测量等)组合形成数据库。实测重力数据经过地形校正、中间层校正、自由空气校正、均衡校正等得到布格异常、自由空气异常、均衡异常,均存放在数据库中,学者根据研究目的选出相应的数据。本文选择能够反映地球内部剩余密度分布的布格重力异常。考虑到对位场数据做处理时的边界效应,通常使用数据的经纬度范围比研究区域大2°。
3.2 数据变换
数据变换是为了让数据变换成适合挖掘的形式,本例中使用梯度算法、解析延拓算法、边界提取算法将布格重力异常变换成适合解释的形式。
通常,在重力异常和垂向梯度平面图中梯级带、不同特征异常区的分界线、线性分布的高低异常过渡带能反映深大断裂,有时也可以反映大范围不同岩性的接触带[12]。在水平梯度平面图中,异常条带能够反映深大断裂的位置。向上和向下解析延拓的方法可以分别突出浅部或深部的异常特征。进行延拓处理后再根据断裂构造在重力异常平面等值线图上的特征对断裂构造加以识别。
3.3 数据挖掘
本例中数据挖掘步骤是对算法处理过的数据进行相应的解释。删除盆地边界以外的数据点,仅留下与盆地形状大小相近的区域作为处理结果并可视化。根据3.2中提到判别标准可以确定出断层的平面展布的情况。
垂向1阶(图11(a))和2阶梯度(图11(b))与研究区域的布格重力异常场(图12)相比,高频成分丰富,表现出的断裂的数量多且细致,突出了埋深较浅的断裂。水平梯度 (图13)以极值条带的方式体现了断裂的展布,图中只确定了条带较宽在图中较为明显的异常条带,它们和深且大的断裂相对应。研究区域中不同断裂的走向和规模不同,不同方向的水平梯度突出的深大断裂也不相同,因此重力异常数据处理当中常对多个方向进行水平梯度计算,综合考虑各方向处理结果才能得到合适的解释。

(a) 垂向1阶梯度Vzz

(c) 向上延拓14.8 kmVzUP

(d) 向下延拓14.8 kmVzZOWN
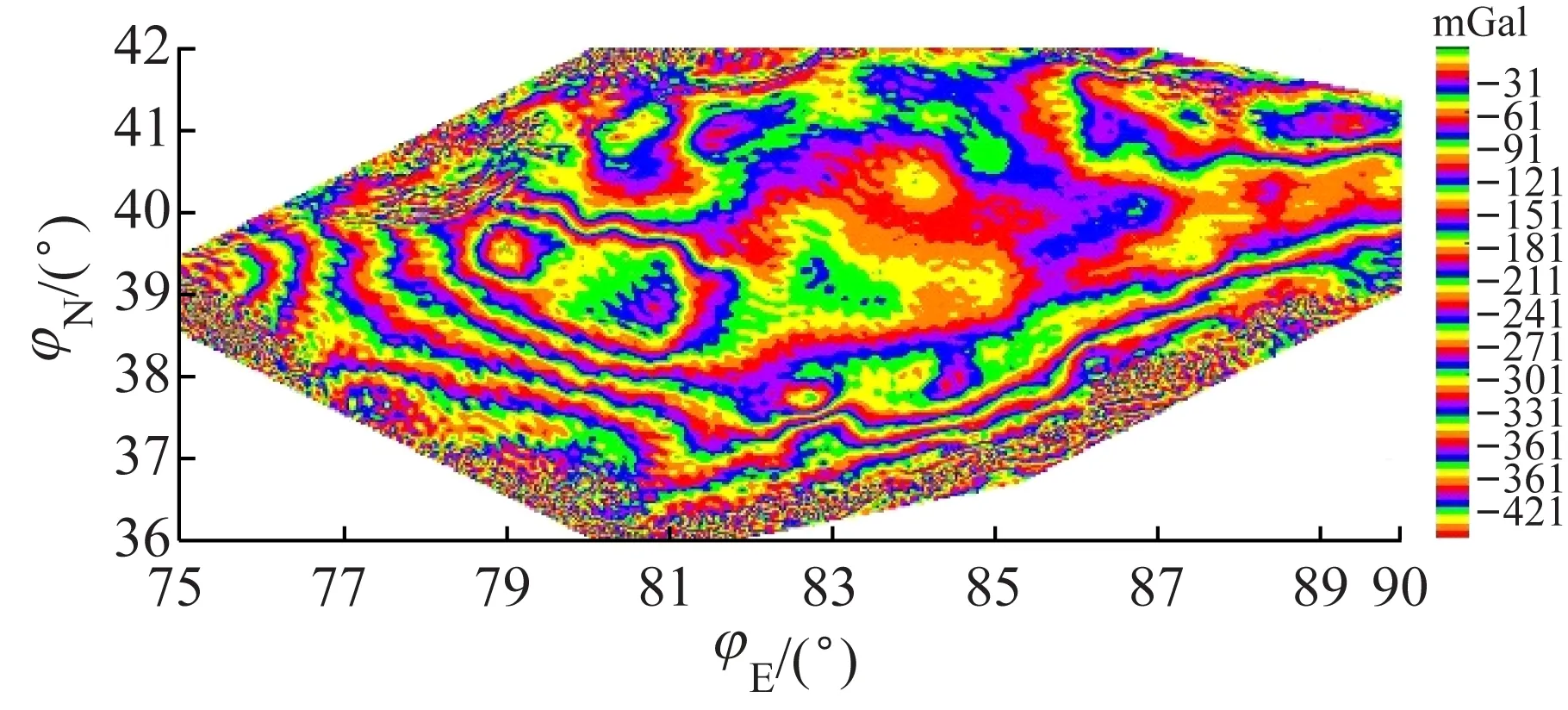
图12 塔里木盆地布格重力异常
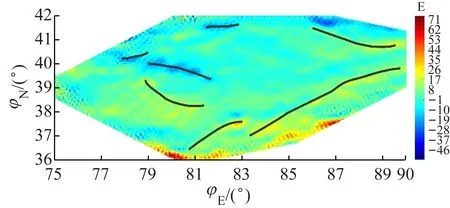
(a) 水平梯度Vz0

(b) Vz45

(c) Vz90
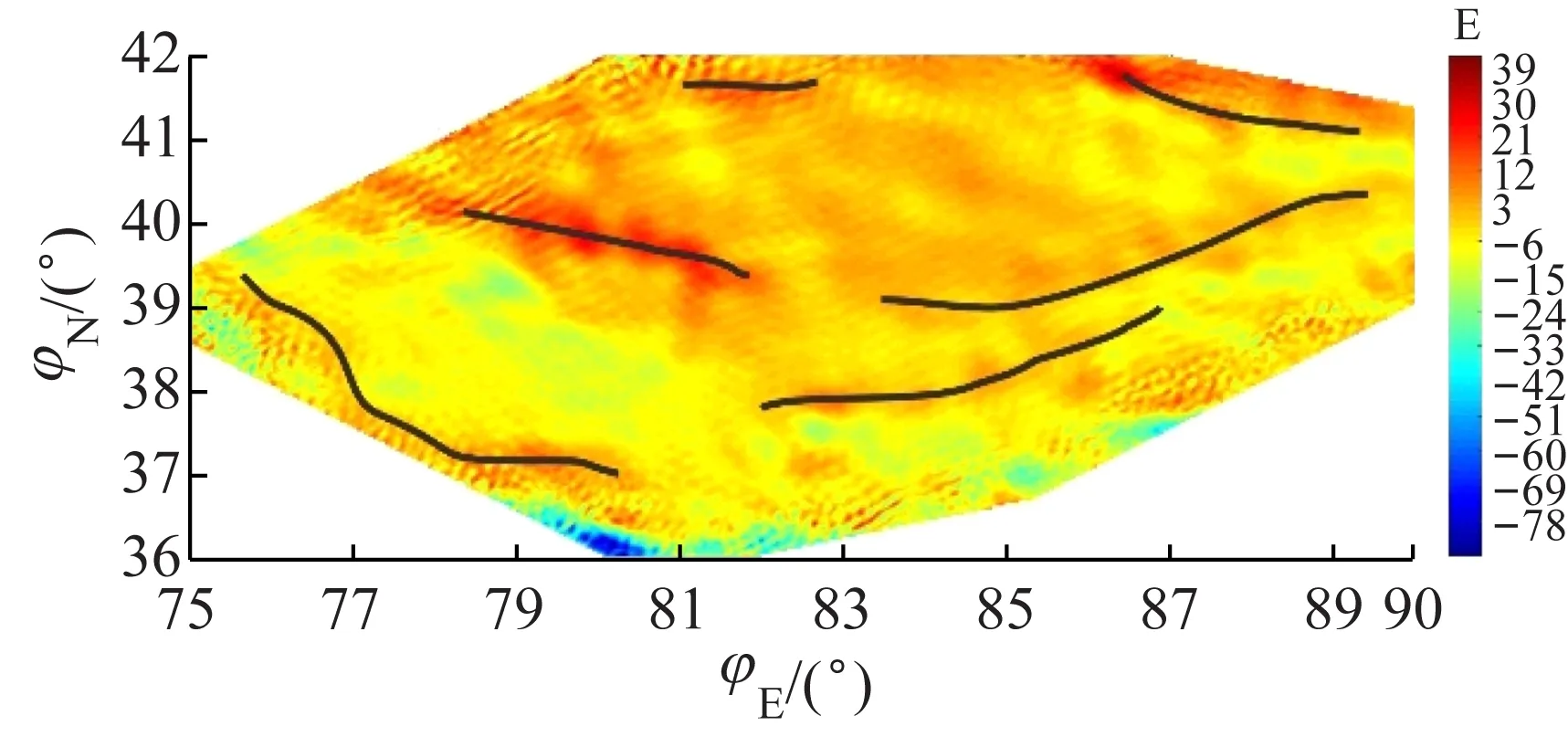
(d) Vz135
解析延拓中的单位长度就是原始数据的精度,本文使用的原始数据的精度是2′,对应的长度为3.7 km。分别对研究区域布格重力异常场(图12)向上延拓4个单位长度(14.8 km)(图11(c))和向下延拓4个单位长度(14.8 km)(图11(d))。向上延拓所得结果中长波段信号丰富,反映大型断裂的展布。向下延拓极大程度地突出了高频成分,它们是由浅部小规模的异常源引起,浅部断裂数量多展布方式复杂,图中没有一一描绘出断裂形态。
用tanh, sign, ReLU, Leaky ReLU 4种激活函数处理研究区域的布格重力异常数据。由边界提取算法模型试算的结果可知,tanh函数(图14(a))梯度带能表征断裂边界,边界在sign函数(图14(b))表现为阶跃,ReLU(图14(c))和Leaky ReLU(图14(d))0值附近的极小值条带即图中黄色的条带是深大断裂存在的区域。

(a) tanh

(b) sign
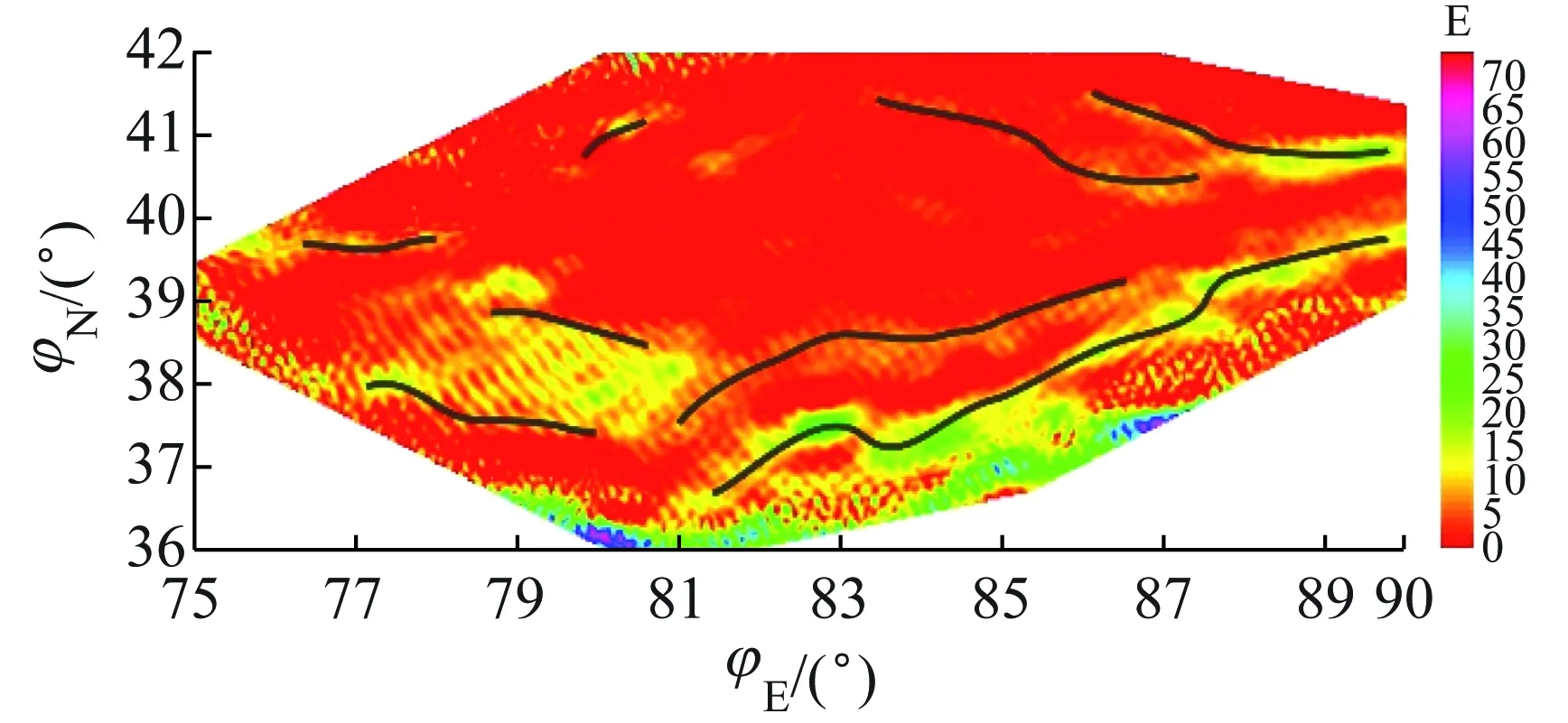
(c) ReLU

(d) Leaky ReLU
3.4 模式评估
区域主要断裂示意图(图10)可识别挖掘所得结论的可靠性:盆地主要由五大断裂系统组成,它们分别是天山山前断裂系统、库鲁克塔格断裂系统、阿尔金山前断裂系统、昆山山前断裂系统和巴楚凸起断裂系统。其中巴楚凸起断裂系统位于盆地内部,另外4个断裂系统位于盆地的边缘,走向为NE、NEE和NW,且基本与盆地边缘平行。本例挖掘出的断裂系统的分布模式与地质事实吻合度高。
运用不同的挖掘方式挖掘同样的数据能挖掘出不同的知识[14],使用不同的算法处理区域异常数据既能得到构造水平方向的位置信息也能得到垂向的深度信息。对不同的数据用同样的挖掘方式也能得到不同结论。除本文介绍的应用之外,位场数据处理技术还广泛应用于磁力探测、遥感、计算机视觉、特征学习等领域当中[15]。
4 结 语
本文通过模型试算比较了几种位场数据处理算法的特点:梯度算法能够区别不同形状的场源,突出浅部短波段信号,并分离靠近的场源异常,且梯度阶数越高效果越明显;解析延拓算法能够突出不同深度的场源异常,向上延拓能突出深部场源,向下则突出浅部;边界提取算法以梯度带,阶跃等形式刻画出场源边界。通过挖掘地球物理数据可得到地表以下的情况,塔里木盆地断裂系统尤其是盆地边缘的深大断裂在梯度算法的作用下主要表现为梯度带和条带状异常,断裂的深浅不一在解析延拓算法处理结果中表现为长短波段,深大断裂在向上延拓图中表现为低频信号,向下延拓能够识别和圈定一些细小的异常特征。塔里木盆地的主要断裂系统走向为NE, NEE, NW且基本与盆地边缘平行分布,与研究区域实际情况相符。
