基于层次信息粒表示的属性图链接预测模型
2019-03-22苗夺谦张志飞张远健胡声丹
罗 晟 苗夺谦 张志飞 张远健 胡声丹
1(同济大学计算机科学与技术系 上海 201804)2(嵌入式系统与服务计算教育部重点实验室(同济大学) 上海 201804)3 (计算机软件新技术国家重点实验室(南京大学) 南京 210023) (tjluosheng@gmail.com)
随着信息技术的快速发展,越来越多的网络应用将人们紧密地联系在一起,形成了人与人之间的一个链接网络.现有大量的复杂网络分析相关的研究工作发表在统计物理、统计学、计算机科学和应用数学等领域[1-2].复杂网络分析早已成为国内外学者研究的热点问题.链接预测正是复杂网络分析的一个基础性工作,具有重要的地位.早期的链接预测[3]分析方法的出发点是建立在数据的网络拓扑图之上,这类方法较为直观,易于解释.除了网络拓扑结构数据之外,结点还具有属性信息,这类复杂网络一般称之为属性图[4].一个常见的链接网络如图1所示:

Fig. 1 A toy example of the link network图1 一个示例链接网络
然而,伴随着计算机的存储能力和计算能力的快速增长,以及进入Web 2.0时代之后,人们参与数据发布的积极性高涨,以至于现在的复杂网络数据的规模越来越庞大.同时,网络结点属性的丰富程度也越来越高.复杂网络数据的来源及质量得到了巨大的提升.数据的快速增长导致人们获取的数据亦呈现大数据特点,即体量巨大(volume)、类型多样(variety)、产生速度快(velocity)、易变性(variability)以及真实性(veracity)①https://en.wikipedia.org/wiki/Big_data等特征.这些数据特性对现有智能学习系统带来了巨大的挑战,特别是数据的易变性,也就是数据的不一致性,对现有数据挖掘与分析工作提出了新的要求.
本文从数据的不一致性出发,分析现有多源异构的复杂网络不同数据,以及由此引发的信息过载所带来的数据差异性问题;同时采用粒计算范式,克服原有计算模式的单一粒度视角,建立异构多源数据的层次粒度表示.不一致问题带来的挑战,其背后的主要原因是异构数据之间存在的信息间隔(infor-mation gap).为此,本文提出数据的层次粒度表示用于处理信息间隔问题.数据的层次粒度表示的主要工作是设计一个基于拓扑结构图的统计模型;同时,以结点属性表为基础构建统计模型的先验知识.最后将这些异构的浅层模型表示的数据提升至更为抽象的高层信息粒,以期望在高层信息粒层,加以一定的约束条件,多源数据能够达到数据一致.该链接预测模型的动机在于,试图在多层粒度空间上寻找链接预测问题的最优解.
1 相关工作
本节主要介绍与链接预测主题相关的研究背景以及研究现状.
现有大量链接预测相关的研究,其中最简单和直观的方法以结点的相似性为基础.这类方法通过计算结点之间的相似性的评分来构造结点之间存在链接关系的可能性.常见的相似性计算方法有公共邻居(common neighbors, CN)[5]、杰卡得系数(Jaccard index, JI)[6]、索尔顿系数(Salton index, SI)[7]、资源分配系数(resource allocation index, RAI)[8]和adamic-adar系数(adamic-adar index, AAI)[9]等.这类方法主要使用拓扑结构上的邻居或路径等特征来计算结点对之间的相似程度.很明显,这类方法的主要缺陷是缺乏考虑结点属性以及扩展性不足.
另一类方法聚焦在最大化观测结构的似然,建构图的生成模型.然后,使用数据学习后的最优模型预测未知结点对之间的链接概率.Clauset等人[10]提出了一种从拓扑网络结构推断潜在层次组织结构的生成技术,并将该模型用于缺失链接的预测.也有一些研究工作,使用概率相关模型(probabilstic relational models, PRM)[11]描述关系数据集(rela-tional dataset, RD)的属性联合分布、优化分布,并将其用于结点对的链接关系预测.相似的工作还有Relational Markov Networks[12], Relational Depen-dency Networks[13], Local Naïve Bayes Model[14]等.还有一类链接预测方法则是基于机器学习技术[15-18].
此外,对于链接预测问题,每个社区对于结点的链接关系建立过程同样具有重要作用[19].例如对于一个中国的社交网络链接预测问题来说,大部分结点都属于中国这个社区;同时这些结点属于或不属于网球、游泳、足球等社区.很明显,中国社区对于建立结点链接关系问题而言,影响程度小于网球社区、游泳社区、足球社区等社区.也就是说社区在结点对建立链接关系的过程中所处的地位及作用是不同的.相关的工作还有:王鑫等人[20]研究了交互意见和地位理论与链接关系的强相关性,提出了一种基于符号网络的链接预测模型;刘冶等人[21]研究了主数据源与附加数据源的特性,并提出了一种基于低秩和稀疏分解的多源融合链接预测算法;张泽华等人[22]将粗糙集理论引入图挖掘领域,提出了网络社区的领域粗糙化扩张方法等等.值得注意的是,现有的这些方法,要么忽略了结点属性,要么拓扑网络数据与结点属性之间存在的潜在交互性,要么忽略了社区在结点对建立链接关系过程中的不同作用.
为了处理以上问题,本文首先对于各个来源的数据进行粒度表示学习.具体来说,对于拓扑结点图数据,使用一种概率生成模型对图数据进行抽象表示(作用相当于提升数据信息粒层);对于结点属性表,使用聚类方法对数据进行抽象表示(提升数据信息粒层).同时,对数据抽象后产生的高层数据信息粒加以一定条件的约束,以期在粒度表示的条件下,达到数据的一致,从而优化层次粒度表示模型,最终优化结点对链接关系预测的效果.
本文的贡献可以概括为3点:
1) 提出了一种关于拓扑结构图数据的概率生成模型.这个模型充分考虑潜在社区贡献度因子,又考虑结点与社区之间的结点-隶属关系.
2) 提出了一种基于数据层次信息粒表示的问题求解方法.该方法将原始多源异构数据抽象为不同层次结构下的信息粒,并考虑将不一致问题消除在这种层次信息粒表示的数据结构中.
3) 提出了基于粒度视角的链接预测方法,根据粒度计算范式,学习最优的层次粒表示模型,并将此模型用于表示缺失及观测链接关系的生成概率.实验表明这一方法相较现有方法,有较为显著的性能提升.
2 基本知识
本节主要介绍数据的粒度表示以及信息粒在复杂网络链接预测模型中降低数据不一致性的重要作用.粒计算是人们处理日常事务的一般性思维模式.人们在计算现实世界问题时,通常是从多个角度,多个层次的观点看待问题,而不会局限于某一些局部特征,这一方法论也被称之为粒计算[23-24].
2.1 基本定义
在处理复杂网络数据时,根据粒计算理论,本文将网络结构中观测到的网络拓扑结构数据与结点的属性数据(特征、标签等)归结为原始信息粒.在原始信息粒的基础上,又可以构造当前信息粒的一种抽象表示(如图像处理过程中边缘是像素的一种抽象表示),形成高层信息粒,假如当前信息粒层不适合问题求解,可以在此基础上,继续构造上一层信息粒,直至当前信息粒有利于问题求得最优解.由此,便形成了数据的层次粒度结构表示.
下面给出相关的定义.

Fig. 2 The framework of the HGRLPM图2 层次粒度表示的属性图链接预测模型框架图
定义1. 属性图.任意给定一个网络拓扑图G(V,E),其中网络拓扑图结点集V={vi},i=1,2,…,N,N为网络拓扑图的结点总数,链接边集E={ei j|∀i,j≤N}为V上的一个二元关系,且有
(1)
一般地,若网络拓扑图G(V,E)的结点具有属性信息,则这一类型的网络拓扑图也称之为属性图,记为G(V,E,F),其中F为结点属性表.


(2)
其中,vfi为结点v在特征fi映射值域Vfi的一个具体属性值.具有属性值的网络图结点可以表示为属性值向量vf=(vf1,vf2,…,vfm),所有结点属性向量集合为结点属性表,记为F.
定义3. 网络社区.任意给定一个网络拓扑图G(V,E),其中的网络结点根据一定的划分规则潜在地属于某个类簇中心,即v∈Ci,i∈{1,2,…,k}(k为类簇总数).在复杂网络分析上下文环境中,类簇中心也称之为网络社区.
特别地,由网络拓扑数据得到的网络社区也称之为拓扑网络社区,记为{Ci},i∈{1,2,…,k}.
同理,给定结点的属性表,那么根据结点的属性相似度,潜在的存在着一个由所有结点组成的聚类族(属性表诱导的网络社区),记为{Qi},i∈{1,2,…,k},这类网络社区称之为属性网络社区.若结点可以同时属于多个网络社区,那么由这些结点所形成的社区之间,会存在结点的重叠,即2个或以上社区存在公共结点,这种类型的社区也称之为重叠社区.
3 层次粒度表示的属性图链接预测模型
3.1 问题描述
在介绍模型之前,首先将所研究的问题做个简单的描述.一般地,假设给定属性图G(V,E,F),则链接预测问题的主要任务是根据观测到的现有结点间的链接关系集{ei j|∀ei j∈E∧ei j>0}与结点属性表F,试图建立任意结点对之间链接关系的似然估计.
如图2所示,在系统处理的原始数据中,拓扑结构图观测到的链接边与结点属性相似度诱导的潜在链接边存在不一致的情况,即:
1) 拓扑结构图中结点对没有观测到链接关系,而属性表提供的结点相似度暗示着这对结点存在一条隐式链接;
2) 根据结点属性表计算出结点对相似度较低,表示存在链接关系的可能性较低,而拓扑结构图却观测到了结点对之间存在链接.
如果将所有对象映射至高层信息粒,即拓扑网络社区与属性网络社区,则可以在这种层次粒度结构的表示下,通过粒度转换融合异构数据,最大化地消除低层信息粒的不一致.信息粒度表示的粒层数量依赖于问题的规模及领域特点.
现有的属性图链接预测模型都忽略了这种潜在的数据不一致导致的冲突问题.基于此,不同于现有链接预测模型,本文提出层次粒度表示链接预测模型(hierarchical granular representation link prediction model, HGRLPM)将从数据的层次粒度表示出发,通过提升数据的粒度层次,消除低层次粒度的不一致性,最大化地融合异构的数据源,降低链接预测的不确定性,提升链接预测的准确性与精确性.下面引入基于层次信息粒表示的属性图链接预测模型.
3.2 层次粒度表示的属性图链接预测模型
本文的模型主要基于Breiger等人[25]与Jaewon等人[26]的工作,即每个结点依据不同的隶属度包含在不同的网络社区(每个结点与每个社区潜在地都具有包含关系,区别在于隶属度不同).如果任意2个结点所属的公共社区越多,那么它们将会以更高的概率建立链接关系.
同时,我们也注意到每一个网络社区在结点对建立链接关系中的重要程度是不同的.换句话说,每个社区对每个结点对建立链接的贡献度是不一致的.
最后,由于结点的属性表获取代价昂贵,所以研究数据对象以网络拓扑结构图为主体,而属性表诱导的结点社区隶属关系作为拓扑网络结构统计模型对应随机变量的先验分布.

引理1. 层次粒度表示链接预测模型(HGRLPM)通过相应的产生概率p(u,v) 建立任意结点链接边 (u,v),∀u,v∈V,生成拓扑结构图G(V,E),且
p(u,v)=1-exp(-sT(Bu⊙Bv)),
(3)
其中,sc是一个表示网络社区c的贡献度的随机变量,向量s=(s1,s2,…,sk);Bu,Bv分别是结点u,v的结点-隶属向量,代表结点-隶属矩阵的一列;“⊙”为逐元素乘法.

(4)
其中,Poi(·)为泊松分布.根据泊松分布的性质,可知,网络社区对结点对(u,v)的相互作用总量Tu v为
(5)
可以得到链接概率p(u,v)=P(Tu v>0),即
P(Tu v>0)=1-P(Tu v=0)=
1-exp(-sT(Bu⊙Bv)).
(6)
证毕.
3.2.1 拓扑结构图对数似然
假设给定潜在因子矩阵,即结点-隶属关系矩阵B与网络社区贡献度因子向量s,拓扑结构图G生成模型的似然概率记为L(B,s),那么有:
L(B,s)=lnP(G|B,s)=
(7)
在没有考虑结点属性表的情况下,通过求解以下问题就可以得到最优模型,即
(8)
然而,在这种情况下,模型没有考虑结点属性以及拓结构图数据与属性数据之间潜在的不一致性.一般地,在建构一个全面、鲁棒的链接预测模型时,不仅需要考虑集成异构数据,同时也需要考虑消除异构数据的不一致性.
3.2.2 结点-隶属关系先验
当我们考虑结点的属性信息时,这表示根据某种相似度测度可以将所有的结点按照它们之间的亲疏程度,划分为k个聚类簇.这里为了保持数据整体上是一致的,假设拓扑结构以及属性信息各自产生的数据概括是相同的,即拓扑图产生的类簇与属性图产生的类簇个数是相等的.在本文中,属性表产生的结点与聚类簇的隶属程度记为

并将此信息作为拓扑结构图的结点-隶属关系矩阵的一个先验信息.


((9)
M(·,·)一般使用欧氏距离,也可以根据数据特点选择余弦距离、马氏距离等.
3.2.3 社区贡献度先验
我们假设每一个网络社区在结点对建立链接的过程中的贡献度是不同的.例如当我们在分析中国的社交网络链接问题时,如果所有结点所属的社区都为中国,那么这个社区对于链接预测任务而言,贡献度是可以忽略的;而根据某种爱好划分的社区,如音乐、体操、乒乓球等社区对于结点间的链接关系建立具有很强的驱动力.
显然,网络社区的重要性可以从当前社区的链接数在全体网络链接所占的比例观察出来.这也是为什么使用拓扑结构图的链接密度作为社区贡献度的先验,即

(10)
其中,函数φ(·)用于计算结点集所具有的链接边的个数.
3.2.4 结点-隶属关系重要度
由于社区的贡献度不一样,所以结点-隶属关系成员的重要程度也不一样.在系统建模时,应当考虑结点-隶属关系成员的重要度.在本文中,结点-隶属关系重要度为
Wi j=πμj,
(11)
其中,i∈{1,2,…,|V|},j∈{1,2,…,k},π为自定义常数.Wi j表示当前结点与社区中心的隶属关系的重要度与社区在结点建立链接关系时的重要度成正比关系.
3.2.5 层次粒度表示
定义5. 原始信息粒、高层信息粒.一般地,信息系统所采集的经过简单数据清洗后得到的数据被认为是信息系统输入的原始数据.原始数据称之为原始信息粒,记为IGL.对原始数据依据某种规则抽象之后形成原有数据的一个概括描述,即高层信息粒,记为IGH.

(12)
由此,RHI={IGL,IGH|B,D,W,s,μ}为原始数据的层次粒度表示,其中,{B,D,W,s,μ}为层次粒度表示的参数集.
2) 属性表诱导的社区重要度与拓扑结构图生成过程中的社区的重要度的差异也应最小化.
3) 根据最大似然估计法,我们需要最大化拓扑结构图的对数似然.
因此,本文提出层次粒度表示链接预测模型,即

(13)
其中,ψ(·,·)为高层信息粒IGH成员粒之间距离度量函数,η(·,·)为s与μ的距离度量,用于测量2个输入变量的相似程度.矩阵B和D为构建高层信息粒层的参数.
(14)
根据拉格朗日乘子法,可以将式(14)转化为以下优化问题:
(15)
4 模型参数学习
模型所有需要学习的参数为矩阵B与向量s,记为Θ={B,s}.对于式(15)这个优化问题,当固定参数s与其他的Bv(∀v∈V∧v≠u)时,我们发现(B,s)是Bu(∀u∈V)的凸函数(convex function).同理,(B,s)是s的凸函数.因此,选择块座标梯度下降算法[27](block coordinate gradient descent algorithm, BCGDA) 来得到模型参数的最优解.
原式(13)可以分解为

(16)
与

(17)

式(16)的目标函数为
(18)

式(17)的目标函数为
(19)
BCGDA将迭代地按某一个顺序,循环地优化式(14)和式(15).BCGDA的一个最基本的要求是必须计算式(16)和式(17)的梯度.
下面,给出每个目标函数各自相对应的梯度,它们分别为
(20)
与
(21)
下面给出本文提出的层次粒度表示链接预测模型(HGRLPM)的参数学习算法.
算法1. HGRLPM参数学习算法.
输入:精度εtol、属性图G(V,E,F)、社区数k、学习率γ、重要度系数π、最大迭代次数MAXITER;
输出:结点-隶属关系矩阵B、社区贡献度s.

② foru=1,2,…,|V| do
③ forc=1,2,…,kdo
④Dc u←式(9);
⑤ end for
⑥ end for
⑦ forc=1,2,…,kdo
⑧μc←式(10);
⑨ end for
⑩ foru=1,2,…,|V| do
5 层次粒度表示模型的链接预测
经过数据训练后,获得当前数据的一个层次粒度表示RHI={IGL,IGH|B*,D*,s*,μ*},其中B*,D*,s*,μ*是从数据中学习的参数最优值.模型HGRLPM将在学习好的层次粒表示RHI基础上,执行链接预测任务.为此我们设计了以下预测模型.
5.1 协同预测


(22)
其中,nnb(u)为结点u最相似的n个结点集合.若v也是信息缺失,那么执行与结点u相同的处理过程.
在此基础上,结点对(u,v)建立链接关系的协同预测概率p(u,v),即
(23)
特别地,当n=1时,这种协同预测策略称之为基础预测.
5.2 预测算法
下面给出基于层次粒度表示协同链接预测算法的详细步骤:
算法2. 协同链接预测算法.
输入:层次粒度表示RHI、预测结点对(u,v)、协同数n;
输出:结点对链接概率p(u,v).

② 计算链接概率:p(u,v)← 式(23);
③ 输出p(u,v).
6 实验与结果
在本节中,我们设计了关于引言部分介绍的示例数据集,以及2个真实数据数据集AmazonFail[28]和Lazega[29]的实验.同时,我们对比了HGRLPM与其他的算法的预测性能,实验结果显示HGRLPM模型相对于其他的方法具有较强的优越性.
6.1 数据集
示例数据集的拓扑结构图已在引言部分介绍过了,表1给出了示例数据的结点属性值,表2给出了所有数据集的一些基本统计信息.
AmazonFail数据集是从Amazon网站所收集的.该数据集总共有1 418个结点,每一个都代表Amazon网站出售的一件产品.3 695条链接边建立了这些结点之间的相关关系.此外,这个数据集还提供了产品的属性以及标签信息.标签信息用于标记用户对该产品的不满意度.
Lazega数据集是一个公司法律事务所关于公司法合伙关系的属性图.它包括该公司的71名律师(合伙人和同事)之间的网络关系.这个数据集常用于社区网络分析,例如有限团结、横向控制、质量控制、知识共享、权力平衡、监管等等.

Table 1 The Attribute Information of the Toy Dataset表1 示例数据集结点的属性信息

Table 2 Basic Statistics of Datasets表2 数据集基本统计信息
6.2 对比标准
对于模型输出的链接概率,设置一个阈值ε,如果p(u,v)>ε,那么认为结点对(u,v)存在一条边,即E(u,v)=1,反之为0.那么,使用3个指标来对比算法的性能:
(24)
其中,TP(true positive)为正确正例,TN(true negative)为正确负例,FP(false positive)为错误正例,FN(false negative)为错误负例.
6.3 案例分析
在本节将详细分析算法在示例数据集上的性能,以及与其他算法的对比.对比的算法为第1部分介绍的杰卡得系数(JI)和资源分配系数(resource allocation index, RA)和LHNI (Leicht Holme Newman index)系数.
由上述示例数据集的背景知识,假设社区数量k=3,学习率γ=0.001,正则项系数α=0.03,β=0.005,在这些参数设定条件下,算法经过50次迭代后目标函数逐渐稳定,最终在第59次迭代后收敛于6 020.49.具体的收敛过程如图3所示:
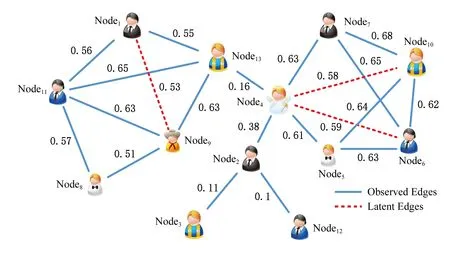
Fig. 5 The link prediction result of the HGRLPM model图5 HGRLPM模型链接预测结果

Fig. 3 The convergence of the HGRLPM model training processes with the Toy dataset图3 HGRLPM模型在示例数据集上的训练收敛过程
训练过程结束后,我们得到了用于表示模型HGRLPM的最优参数值B*,s*.图4给出了B*和s*的参数值分布.从图4我们可以发现每个社区参与建立结点对之间的链接关系的贡献度s*是不同的,社区1的贡献度最小,社区2的贡献度最大,社区3的贡献介于社区1和社区2之间.同时,社区贡献度s*还影响着结点与社区之间的隶属关系B*.模型HGRLPM的最优参数值也代表着:属性表导出的结点与类簇的隶属关系D与拓扑结构图产生的B在B*时差异最小.这也表明通过最优化技术,低层信息粒的不一致性在高层信息粒得到了最大化的消除.

Fig. 4 The community weights and node-community affiliation relations learnt by the HGRLPM图4 HGRLPM得到的社区重要度与结点-社区关系
通过数据训练得到最优模型HGRLPM后,我们根据链接预测算法,对属性图的所有结点,预测其链接的生成概率.图5显示了模型HGRLPM预测的属性图中的示例训练集观测到的所有链接生成概率,以及潜在链接(生成概率大于50%的边)的生成概率.在图5中,虚线代表为错误正例,实线为正确正例,链接边的数字为建立链接的概率.
另外,表3给出了所有的结点对的链接边(观测到的以及未观测到的结点链接关系)预测概率.

Table 3 All of the Link Probability Predicted by the HGRLPM for the Node Pairs表3 HGRLPM预测的所有结点对链接概率
从表3可以看出,图5中有4条边划分为错误的负例,即{(Node4,Node13):0.16, (Node2,Node4):0.38,(Node2,Node3):0.11,(Node2,Node12):0.10};同时,有3条未能观测到的边划分为正例,即错误的正例{(Node1,Node9):0.53,(Node4,Node6):0.59,(Node4,Node10):0.58}.可以得到以下评价分:
为了验证算法的性能,我们将原有的拓扑相似索引JI[6],RA[8],LHNI[8]进行扩展,使之能够同时利用拓扑和属性表信息.然后与HGRLPM进行对比.具体扩展如下:
1) 计算JI,RA,LHNI的相似度;
2) 计算属性表中结点对的修正余弦相似度(adjust cosine similarity, ACOS), 即
(25)
3) 融合2个相似度,以JI索引为例, 融合ACOS与JI,即
δJIA(xi,xj)=θ×δJI(xi,xj)+
(1-θ)×δACOS(xi,xj),
(26)
其中,xi,xj为属性表中的任意结点的特征向量,θ为权值参数,可以设置属性表与拓扑结构图的重要性.扩展后的3个算法分别记为JIA,RAA,LHNIA.
我们使用3个扩展算法和相同的对比标准,在示例数据集上可以得到表4的实验结果:

Table 4 Performance Comparison of Toy表4 示例数据集的性能对比
表4的3个方法(JIA,RAA,LHNIA)的结果为θ取值0.3:0.05:0.7的9次计算结果的均值.这3个方法的Precision,Recall,Accuracy的方差分别为(JIA:0.224 3,0.092 4,0.026 3),(RAA:0.115 2,0.194 6,0.012 8)和(LHNIA:0.295 5,0.227 4,0.019 0).实验结果表明:无论是Accuracy还是Precision以及Recall指标,HGRLPM模型预测的结果对比JIA,RAA,LHNIA有着显著的提升.而且,当θ的值发生变化时,算法的性能波动较大,这主要体现在方差的变化.原因在于JIA,RAA,LHNIA等算法是建立在原始信息上的单粒度表示之上,拓扑结构图与属性表的原始信息融合容易出现偏差,异构数据源的冲突较为明显.这也证明了在原始信息粒上直接处理信息融合是具有挑战性的问题.HGRLPM充分挖掘了潜在社区变量的分布,以及社区作用的不平衡,在多层信息粒的表示下,将数据的不一致性上升到高层信息粒,可以最大化地消除原始信息粒上较难处理的融合问题.这一对比结果映证了我们的假设,也显示了HGRLPM的优越性.
6.4 其他数据集上的结果
采取与示例数据一致的评价标准,表5和表6分别显示了在数据集AmazonFail和Lazega数据集上的算法性能.

Table 5 Performance Comparison of AmazonFail表5 AmazonFail的性能对比

Table 6 Performance Comparison of Lazega表6 Lazega的性能对比
虽然HGRLPM能够取得比JIA,RAA,LHNIA要好的Precison和Recall成绩,但Accuracy却提升不是很显著,甚至在AmazonFail数据集上,Accuracy指标在还有较大的差距离,主要原因在于拓扑图数据的结点链接的稀疏性.当数据集规模不大时稀疏性不会对算法性能产生很严重的影响,然而当数据集规模扩大到一定程度时,稀疏性将严重影响预测的准确性.这一现象也称之为类别不平衡问题[30].最直观的影响在于正例淹没在负例的海洋.对于Precision和Recall为0,这说明RAA和LHNIA在数据集AmazonFail和Lazega上所有的判例都为负,不能识别正例,这也证实了底层原始数据源的不一致性.同时,这也说明了当数据规模扩大时,HGRLPM应该在建模时对数据的稀疏性这一数据因子加以考虑.
7 结 论
本文提出了一种融合异构数据(网络拓扑图与结点属性表)的层次粒度表示模型,根据粒计算理论,对于低层信息粒中的数据不一致性,通过提升粒层的方法,在高层信息粒最大化的消除异构数据的不一致性.该方法的最大优势在于它能捕捉数据潜在的层次粒度结构,同时也最大化的捕捉了数据的语义.实验结果表明,层次信息粒表示的链模型是有效的,对比其他方法有较大优势.
