基于循环神经网络的股指价格预测研究
2019-03-19,,,
,,,
(浙江工业大学 理学院,浙江 杭州 310023)
随着中国金融市场的逐步发展,以股票为代表的蕴含经济利益的众多金融产品越来越被人关注。以往对时间序列研究的领域多涉及股市波动性[1]和金融风险管理[2]等,由于现在股票投资者在进行投资活动时,也越来越关注股票价格的准确预测,从而最大程度地降低投资亏损,增加其投资回报率,所以对股票价格的准确建模分析成为了投资者进行投资决策时最重要的研究内容之一。以往的研究者们虽然主要是将各种统计学和概率论的方法应用于时间序列的预测模型,例如:ARMA(自回归滑动平均模型)、ARCH[3](自回归条件异方差模型)和多元线性回归模型等,但是这些传统模型往往假设条件较多,而且一般只能找出股价与其相关的影响因子之间的线性关系,不能很好地反映股票非线性变化规律,预测精度较低,应用也很受限。
近年来,随着人工智能领域的快速发展,越来越多的投资者开始尝试利用改进的机器学习方法对股价进行建模分析和预测,例如:用改进的支持向量机回归法[4]、改进的神经网络法[5]和改进的聚类算法[6]等,同时也都得到了良好的预测结果。而对于时间序列这种序列数据来说,采用最广泛的模型为RNN(循环神经网络)模型[7]。RNN作为一种专门处理序列数据的模型,可以通过网络结构提取出数据更深层次的特征,从而能够获取时间序列之间的高度非线性关系。又因为传统的RNN结构容易面临梯度消失或梯度爆炸的问题[8],所以就很难获取时间序列的较长时期的依赖关系。Hochreiter等提出的LSTM(长短时记忆网络)结构[9]克服了传统RNN网络的梯度消失和梯度爆炸的问题,使得循环神经网络结构不仅能够提取出时间序列的深层特征,还能考虑到时间序列的长时依赖,也使得模型获得了更好的预测结果[10]。此外,编码-解码循环神经网络近年来在机器翻译上取得了很大的成功。受到这一结构的启发,以下将针对上证50股指的每分钟数据做预测实验,对影响股指价格的各个因子进行编码,再利用编码后的向量作为网络的输入向量,然后结合LSTM结构作股指价格的预测,最终再与其他模型对比,验证模型的有效性。
1 循环神经网络
1.1 传统循环神经网络结构
循环神经网络是专门用于研究类似于时间序列数据等序列型数据的神经网络,并且大多数的循环神经网络也能够处理不同长度的时间序列数据。与循环神经网络相关的一个想法是:在一维时间序列上做卷积,即可以将循环神经网络看作是对一个包含时间索引t的向量x(t)的操作。此外,需要注意,在循环神经网络中,时间索引t仅指序列数据的前后位置而已,而不一定指现实世界中的时间先后。除了时间序列数据,循环神经网络还可以应用于二维空间数据,如图形数据。甚至当二维图形数据涉及时间时,网络也会学习到图形数据时间上的特殊关系。在过去几年中,应用循环神经网络在模式识别[11]、语言建模、机器翻译和图片描述等问题上已经取得一定成功。传统的循环神经网络包括输入层、隐藏层和输出层3层。一般输入层由时间序列x(t)构成,向量x(t)中每个元素代表与目标序列y(t)有关的t时刻的时间序列的特征;隐藏层h(t)则相当于对t时刻之前的输入序列x(t′) (t′从0取到t)的一个归纳提取。一个经典的3层循环神经网络如图1所示。

图1 3层循环神经网络结构Fig.1 Three-layer RNN structure
1.2 LSTM结构(长短时记忆网络)
上述介绍的循环神经网络的关键点是可以将先前的信息连接到当前的预测任务上,例如使用过去的时间序列来预测未来的时间序列走势,或者使用过去的视频段来推测对当前段视频的理解。然而在传统的循环神经网络中,当模型想要学习变量的长时依赖时,总会面临网络深层上传播的梯度消失或爆炸的问题,在梯度的这两种问题中,梯度消失问题往往是很常见的,虽然梯度爆炸问题不太常见,但是一旦出现梯度爆炸问题,就会对模型的优化产生很大的不良影响,当然也可以通过精心的设计或者调节循环网络的参数来避免这一问题。事实证明,即使在参数稳定的情况下,与只学习较短期影响的网络结构相比,想要学习长期影响的网络结构所面临的梯度指数衰减或爆炸的问题,依然是难以解决的[12]。
1997年,由Hochreiter和Schmidhube提出的LSTM结构在很多问题上都取得相当巨大的成功,并得到了广泛的使用。LSTM结构是在RNN发展过程中获得的重要成功,LSTM通过刻意设计RNN中的隐藏层结构,使得循环神经网络结构能学到序列数据之间的长期依赖关系,并同时成功地避免了传统RNN结构面临的梯度问题。实际上,LSTM结构相当于在传统RNN的隐藏层上进行了更为复杂的非线性变换。近期,类似于LSTM的各种其他门控RNN上的研究成果有2015年Cho和Chung提出的GRUs[13]等。一般的LSTM的结构如图2所示。
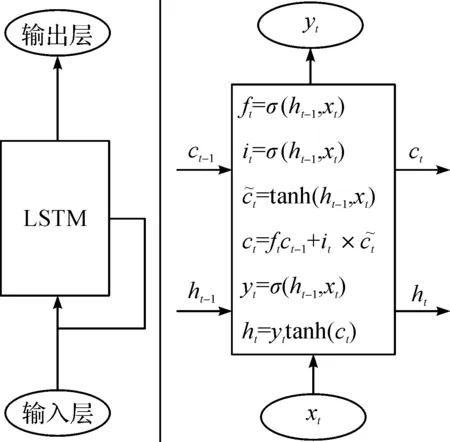
图2 长短时记忆网络的隐藏层结构Fig.2 The hidden layer structure of LSTM
对于上证50股指的每分钟数据而言,其输入层可以是固定长度的历史价格序列,也可以是影响价格序列的其他各类因子。当输入层是一个固定长度为D的股指历史收盘价向量时,即采用单因子RNN模型来对股指价格建模时,模型在最后60 min的股指收盘价预测效果如图3(a)所示。而当输入层是上证50股指所包含的N个成分股的固定长度为D的历史收盘价数据时,就可以用传统多因子RNN模型来对股指价格建模,此时输入层是一个维数为D×N的成分股历史价格矩阵,模型在最后60 min的股指收盘价预测效果如图3(b)所示。
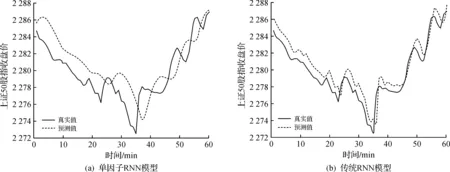
图3 传统模型的预测结果Fig.3 The prediction results of traditional model
1.3 基于注意力机制的LSTM结构
受启发于解决机器翻译问题中所采用的编码-解码循环神经网络的结构,下面将对输入的时间序列x(t)引进注意力机制[14-15]。首先,先介绍实验中会用到的数学符号和一些具体的实验设置等。

再给定目标序列的历史数据,例如(y1,y2,…,yD),其中yi∈R,i∈1,2,…,D,和输入层的历史数据(x1,x2,…,xD),其中xi∈RN,i∈1,2,…,D。基于注意力机制的循环网络模型的目的是,给定时间窗口D,根据这些输入层和目标层数据,学习一个从输入层到目标值yD+1的非线性映射,即
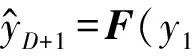
(1)
式中F(·)为最终想要得到的非线性映射函数。
而关于编码-解码循环神经网络的思想,具体地说,就是对于给定的输入矩阵X=(x1,x2,…,xD),首先在时刻t,学习一个从原始输入序列xt到隐藏层ht的映射,即
ht=f1(xt,ht-1)
(2)
式中:ht∈Rm表示网络在时刻t处的隐藏层节点,m为隐藏层节点的个数;f1(·)为任意一个非线性激活函数,对于时间序列,一般采用LSTM结构。
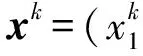
(3)
(4)


(5)
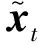
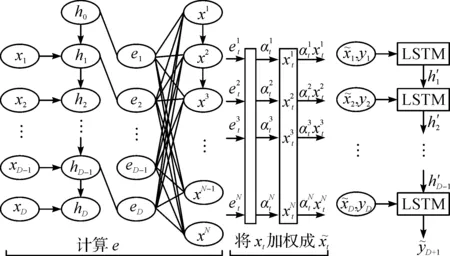
图4 基于注意力机制的 RNN结构图Fig.4 The structure of attention-based recurrent neural network
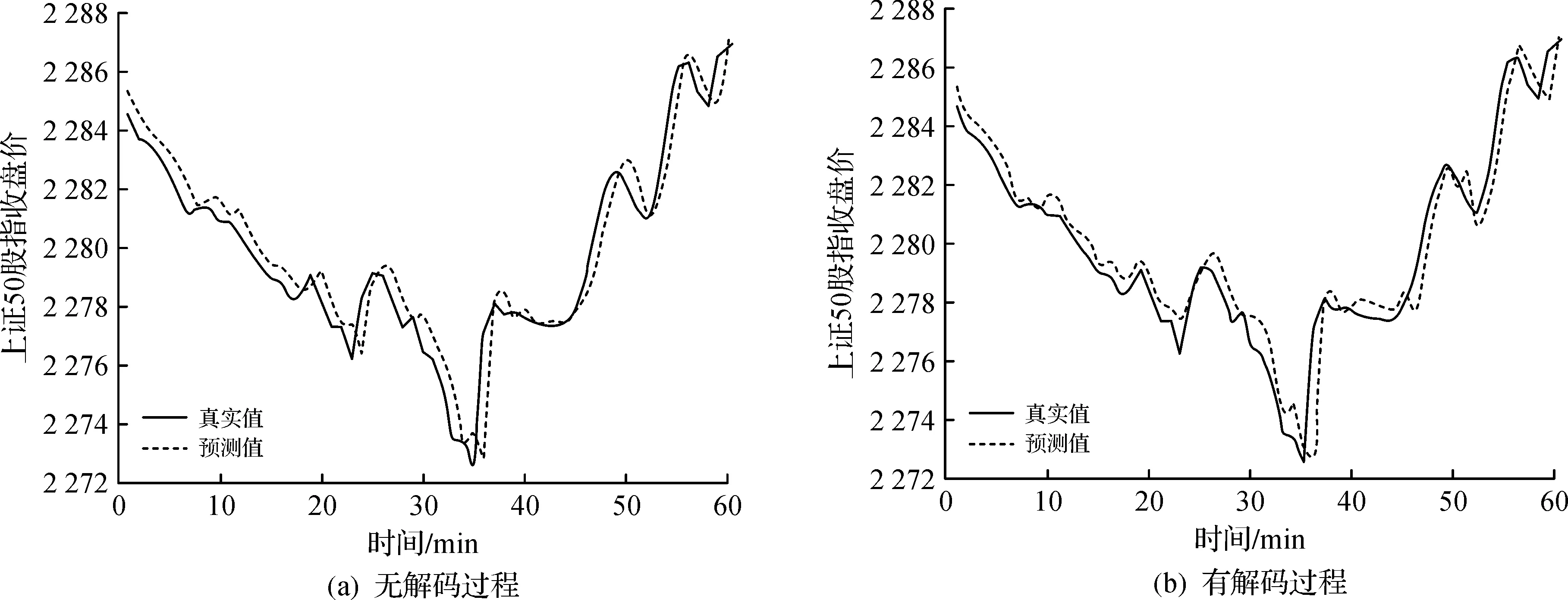
图5 带注意力权重的RNN模型的预测结果Fig.5 The prediction results of attention-based RNN
2 实验分析
2.1 数据来源
模型的代码实现是基于Keras和TensorFlow框架,数据来源是基于开源的Python数据接口Tushare。利用该数据接口,可以方便地获取2016年05月01日至2016年12月30日的上证50股指及其成分股的每分钟收盘价数据。共获得165 d的数据记录。其中,每天又分别包含240个每分钟收盘价数据。此外,由于节假日、停牌和退市等不可避免的因素,会导致数据有部分缺失,所以在正式建模之前需要先对有缺失的数据进行填充。具体选择的方法是:对于有缺失数据的股票数据,以上1个1 min的收盘价对其进行补齐,对于在2016年05月01日至2016年12月30日内停盘的股票,将该股从研究对象中剔除。经过处理后,最终得39支符合要求的个股完整数据。部分数据见表1。该数据共有41列,表1中第1列表示时刻,第2~40列分别代表每支成分股所对应的收盘价数据,第41列代表上证50股指的每分钟收盘价数据。在接下来的模型中,均采用前143 d作为训练集,用以训练模型。接下来的11 d作为验证集,用以选择模型参数。最后11 d作为测试集来评估模型的具体表现。为了避免原始输入变量由于量纲与数量级的不同对模型的训练过程造成影响,在正式开始训练前,对原始数据的每一列分别进行去量纲处理,标准化公式为
(6)
式中xk表示第k列数据。

表1 上证50股指及其成分股的收盘价表Table 1 The close price of SZ50 index and its constituent stocks
2.2 参数设置与结果分析
首先,单因子模型的整体思想是只利用上证50股指的历史收盘价数据作为输入值,构建只包含一层隐藏层的简单循环神经网络,对股指价格做预测,以求映射关系,即
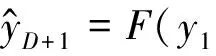
(7)
在具体试验中,单因子模型中的隐藏层采用了LSTM结构。为了得到单因子RNN模型最优的超参值,对时间跨度D1和隐藏层节点个数m1采用网格搜索法,找到模型验证集在D1∈10,20,30,40,50和m1∈25,50,100上的最好表现对应的超参值,最后确定时间D1=50,隐藏层节点m1=50为最优的超参值。模型的预测结果在图3(a)中展示,由于单因子RNN模型只选用了目标序列的历史时间序列作为网络的输入值,所以模型在测试集上的预测效果很差,基本上只能抓住目标变量的大致走势,而不能很好地跟踪目标变量的变化,并且在数值上明显滞后于目标变量,预测效果很不理想。
其次,上述提到传统RNN模型的整体思想是利用上证50股指的历史收盘价数据和其成分股的历史收盘价数据,构建一个只包含一层隐藏层的循环神经网络模型,对股指价格作预测,以求得类似于式(1)中的映射关系。而引进注意力权重的RNN模型则是构建如图4所示的网络结构,来对股指价格作预测。对于这两种网络模型,均需要确定的超参有:输入序列的时间跨度D2,隐藏层节点m2。此外,对于加了注意力权重的RNN模型来说,还需要确定编码层的节点个数m3和解码层的节点个数m4。结合网格搜索方法和处理时间序列数据的实际经验,最终设定超参D2=9,m2=m3=m4=128 。
图3(b)刻画了传统循环神经网络在上证50股指测试集中最后一个小时内的预测表现,可以看出,与图3(a)中的单因子RNN模型相比,由于在网络的输入层加入了成分股的历史数据,增加了目标变量的影响因子,故该模型能够较为准确地跟踪股指价格走势,但是预测结果还是明显滞后于真实值。图5(a)是对输入序列进行注意力加权的模型在测试集最后1 h内的预测表现,与图3(a,b)相比,明显可以看出加了注意力权重后的模型预测效果更好,预测价格与真实价格走势基本一致,虽然与真实股指价格走势还是有一定的延迟,但是延迟程度与图3(a,b)相比较小,最后还可以看出图5(a)中去除了解码过程的模型与图5(b)中不去除解码过程的模型预测结果相比,无明显差距。
2.3 误差比较
为了更好地比较和分析各个模型之间的预测效果,可以根据模型的预测值和真实值,进一步计算模型的MAE(均方绝对误差)、RMSE(均方根误差)、MAPE(平均绝对百分比误差) 3 种误差评价指标,这3 种方法的定义分别为
(8)
(9)
(10)
上述3种模型的评价指标的计算结果如表2所示,表2中数值均取自模型最后1次迭代所得到的结果。由表2可以看出:采用注意力加权模型的评价指标明显优于单因子RNN模型和传统RNN模型,且无解码过程的RNN模型与有解码过程的RNN模型的评价指标相差不大,再次证明了注意力权重在时间序列预测中的显著有效性。
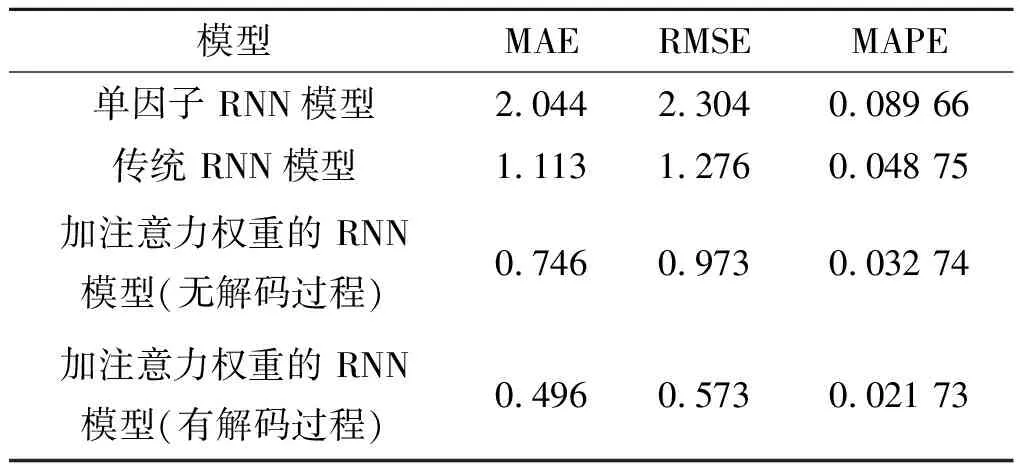
表2 上证50股价预测结果比较Table 2 The prediction results over the shangzheng50 dataset %
3 结 论
利用上证50股指及其成分股在2016年05月01日至2016年12月30日的每分钟收盘价数据建立改进后的基于注意力机制的循环神经网络,虽然与单因子模型和传统RNN模型相比,股指价格的预测精度更高,并且与原始的编码-解码循环网络相比,该模型进一步简化了网络结构,加快了模型的训练速度,但是上述模型均只利用股指及其成分股的历史价格数据对股指未来价格进行预测,利用可能的其他影响因子对股指价格作预测还需要进一步研究。
