基于Solr的电子病历全文检索系统的设计与实现
2019-03-15彭红波韩晟王婷婷
彭红波,韩晟,王婷婷
空军军医大学第三附属医院 信息科,陕西 西安 710032
引言
以电子病历(Electronic Medical Records,EMR)为医疗信息载体的智慧医疗体系正在蓬勃发展[1]。初期,由于缺乏临床信息系统支持,电子病历首先是从病程记录编辑器开始发展的,期间经历了Word、半结构化或结构化等编辑器的过程演变[2],其存储形式也丰富多样,总体来说可分为两类:结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)和非结构化数据(指所有格式的XML、办公文档、HTML、文本、图片、各类报表、视频、音频信息等,包含完全无结构化数据及半结构化数据)[3]。
两者并存的病历存储形式给医生的检索带来了不便。首先,没有统一的搜索入口,需要各自提供检索操作。其次,检索效率不高,特别是在数据量巨大且需要全文检索时,大量的全表扫描操作将严重影响数据库的性能,检索速度势必下降。最后,传统关系型数据库很难检索处理非结构化数据,查准率可想而知。针对上述问题,我们提出了构建一个简单、高效和异构的电子病历全文检索平台,以高性能的Solr全文搜索引擎为基础,通过对电子病历存储格式的异构处理,完成电子病历内容的索引化,从而实现电子病历的全文检索。
1 Solr全文搜索引擎
1.1 Solr简介
Solr是目前非常受欢迎的基于Apache开源组织下Lucene开发的一个开源高性能的企业级搜索平台。Solr具有高度可靠性、可扩展性、可容错性的特点,提供了分布式索引、索引备份、查询负载均衡、自动故障转移和恢复以及集中配置等功能[4]。它能作为一个独立完整的检索服务器,提供基于REST的XML和JSON的索引和检索API,以Web Service的形式集成到任意编程语言中使用[5]。
1.2 Solr与电子病历
尽管电子病历有着各种各样的存储形式,但是它存储的内容却始终不会脱离文本的范围[6]。而Solr最擅长处理的就是以文本为中心的数据类型,因为搜索引擎是专门用于将文本的隐含结构抽取到索引中,从而改善搜索的。以文本为中心的数据意味着,文档中的文本包含用户在找寻时感兴趣的信息[7]。病历文本中包含的内容恰恰就是医生搜索时感兴趣的信息,Solr作为一个非常成熟的全文检索平台,能够非常轻松地帮助医生找到它。
2 系统的设计与实现
2.1 系统设计
2.1.1 系统架构
电子病历全文检索系统主要实现对电子病历的提取、索引和检索,即根据用户的查询要求,从索引库中检索出相关信息资料[8]。它包含3个功能模块:病历提取模块、索引创建模块和用户检索模块。各功能模块之间的关系如图1所示。

图1 电子病历全文检索流程图图
2.1.2 功能模块说明
(1)病历提取模块。从电子病历数据库和电子病历文件中提取患者基本信息、就诊信息及病历信息生成电子病历JavaBean(一种JAVA语言写成的可重用组件)对象,然后再将电子病历JavaBean对象转化为统一格式的XML(可扩展的标识语言)病历文档[9]。其中电子病历文件中的病历信息是通过Apache Tika(一个通用的内容分析工具)解析获得的。
(2)索引创建模块。将病历提取模块中生成的电子病历JavaBean对象,通过SolrJ(一个使Java应用程序可以轻松与Solr对话的API)提交到Solr服务器,再利用IKAnalyzer中文分词器[10]切分病历信息中词语,从而转化为索引,形成索引文件。
(3)用户检索模块。根据用户提交的查询请求,利用Solr提供的查询解析器(默认为Lucene查询解析器[11])将其转化为查询对象,最后查询索引并返回满足条件的结果列表。用户可以点击病历编号查看完整的XML病历文档内容。
2.2 系统实现
2.2.1 系统平台和开发环境
本系统的平台和开发环境介绍如下[12]。操作系统:Centos7 x86_64;开发语言:Java;Solr版本:Solr 7.2.1;Web服务器:Apache Tomcat 8.5.28;开发工具:MyEclipse 2015。
2.2.2 代码设计
从功能模块设计中可以看出,XML病历文档的生成和病历索引库的建立是整个系统的核心,其部分源代码设计,见图2。

图2 源代码节选
2.2.3 用户检索界面
由于Solr搜索引擎自带的检索界面相对复杂,且需要一定的专业知识才能进行操作,结果显示也不太友好。因此,为了简化用户的搜索操作,方便用户直观地看到搜索结果,我们将搜索界面设计如图3所示。用户只需要在搜索框内输入感兴趣的词语,然后点击搜索按钮即可查看到返回的结果列表。
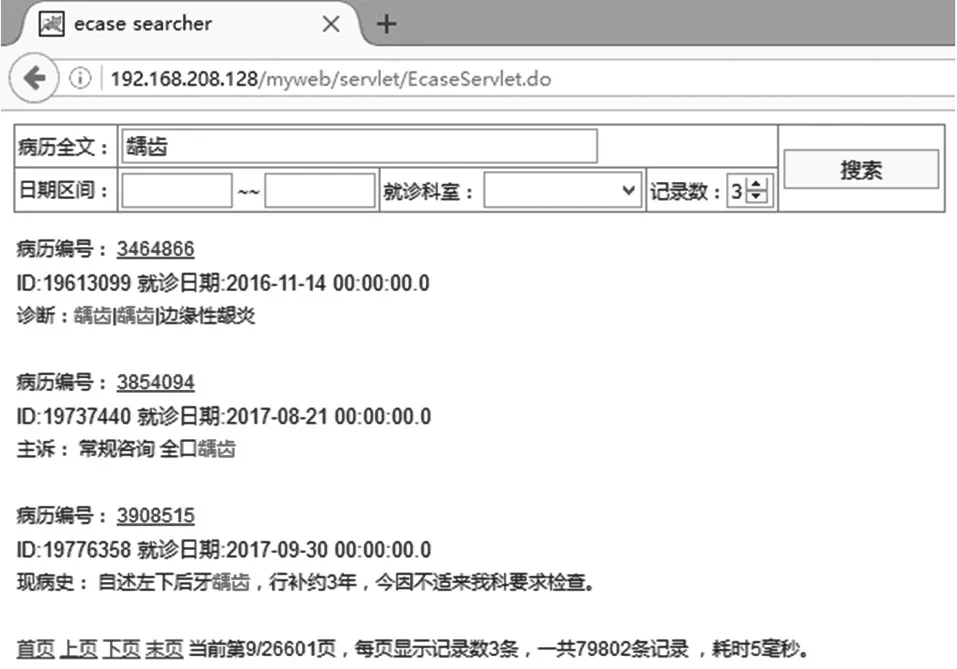
图3 用户检索界面
3 应用效果
本系统采用的是B/S架构模式,这样便省去了客户端应用程序安装的烦恼,用户只需要打开浏览器输入病历检索服务器的地址,完成权限验证后就可以轻松地进行病历的检索操作。然而,操作的简单易行是否就满足了医生的应用需求呢?为此,我们从3个方面进行了评价。
(1)查询效率[14]。对上述系统的性能与传统关系型数据库进行对比,测试用数据量400万条。经过100次统计测试,传统的电子病历检索系统平均查询时间为6376.7 ms,基于Solr的电子病历全文检索系统平均查询时间为5.36 ms。可以看出,查询效率的提升还是非常显著的[5]。
(2)查准率。查准率在试图回答这样一个问题:返回的这些文档是不是我想要寻找的[7]?由于医生病历书写习惯的不同,在传统的电子病历检索系统中搜索得到的病历文档常常并不是我们想要寻找的。如搜索病历中包含有“龋齿”的患者,我们得到的病历常常就会出现以下类似的信息:“龋齿”“未见明显龋齿”“无龋齿”“其他龋齿”“继发龋齿”等[15]。这样的结果显然不是医生所需要的,因为这些病历中包含的干扰信息太多。而基于Solr的电子病历全文检索系统却可以排除这些干扰因素,它只需要医生在检索关键词前加上一个“-”号就能轻松地实现病历的过滤,且不受检索词语数量的限制,相信这样返回的病历文档一定是医生想要寻找的。病历文档数过滤前后对比如表1所示。
(3) 可扩展性。由于本系统屏蔽了病历存储格式的差异,无论是结构化的还是非结构化的电子病历[13],只要是它可以转化为文本内容,系统都能够把它无缝接入,生成统一的XML病历文档,写入病历索引库,进而实现病历的全文检索。

表1 基于Solr的全文检索平台搜索龋齿患者的记录数(条)
4 结论
通过在医院的应用实践,本系统达到了预期设计的目标。它屏蔽了原有电子病历的存储格式[14],无论是新产生的或是旧的病历数据,系统都会定时自动将其转化为索引内容,并写入病历索引库。它不仅简化了用户的检索操作,改善了病历的检索效率,而且还提高了病历的查准率,从而提升了用户的检索满意度。同时,也可以将检索得到的结果数据导出,然后再通过专业的统计分析软件做进一步的科学研究。这不仅提高了电子病历的利用率,也为医生的科研统计工作带来了极大的便利。在医院管理方面,管理人员也可以利用本系统更加精准地找到某类病种的患者信息,为临床路径提供决策支持[16]。当然,本系统也存在着一些不足:① 除了电子病历包含的数据外,缺少其他系统的数据,如LIS(医院检验系统)、PACS(医学影像信息系统)等;② 缺乏一些基本的统计分析功能,如性别比例、身份构成比等;③ 某些病种的检索条件都是固定不变的,然而在每次检索的时候,这些条件却需要重复录入。在今后的应用升级中,我们会逐步改进。
