Oracle数据库全文检索性能研究
2016-10-29龚建华
龚建华
(国防信息学院,武汉 430010)
Oracle数据库全文检索性能研究
龚建华
(国防信息学院,武汉430010)
随着全文检索应用场景越来越多,更加需要了解数据库全文检索的性能。介绍Oracle数据库全文检索的设置方法,然后加载测试数据,对全文检索和模糊查询的性能进行比对测试,最后对全文检索的查全能力和查询速度进行详细分析。
数据库;全文检索;模糊查询
0 引言
随着信息社会的不断发展,获取信息比过去任何时候都变得更加容易,人们在碰到疑难问题时会主动查询信息,查询信息的频率比过去高出了很多倍。生产生活中涌现的大量信息通常以文本形式呈现,很多信息还没有来得及结构化,或者这些根本没有必要进行结构化,导致目前从文本中查找信息是信息查询的主流形式。由于文本难以量化比对大小,因此与数量、日期类型的数据查询相比,文本的比对更复杂、更费时。
数据库全文检索是在数据表文本字段上建立全文索引,文本查询完全在索引上进行,毋庸置疑,建立全文索引可以提高文本数据查询的效率,但是查询效率到底能够提高多少,查询效率与哪些因素有关,这些都是需要深入研究的问题。本文以Oracle10g企业版10.2.0.1.0版为研究对象,对比研究Oracle数据库全文检索性能。
1 全文检索设置
1.1解锁CTXSYS用户
Oracle数据库建立全文检索在的工具包在CTXSYS模式中,安装数据库时,默认情况下CTXSYS用户是锁定的,在使用CTXSYS工具包之前,必须解锁CTXSYS用户,具体操作如下:
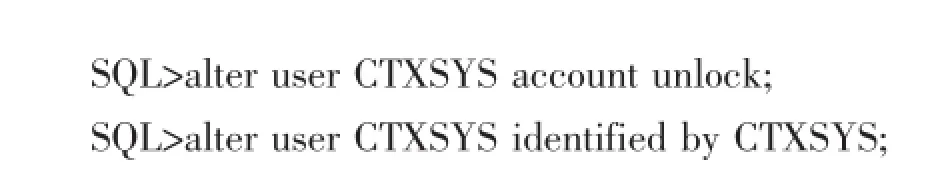
1.2CTX_DDL包授权
CTX_DDL包是设置全文索引的工具,因此在创建全文索引之前需要获得该包的执行权限,例如把该包的执行权限授予SCOTT用户,具体操作如下:
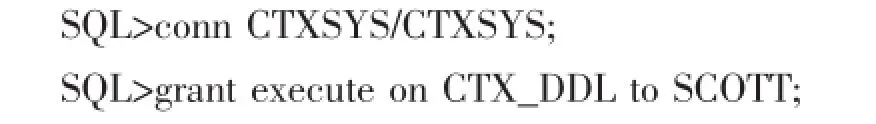
1.3创建中文分词名称
在Oracle数据库中,针对不同国家的语言提供了不同的分词器,常用的中文分词器主要有CHINESE_VGRAM_LEXER和 CHINESE_LEXER,其中CHINESE_LEXER是新的汉语分词器,支持中文和U-nicode字符集,该分词器最大的改进是能够认识大部分常用汉语词汇,因此能够更有效地分离词汇。这里选用CHINESE_LEXER分词器,使用该分词器之前,需要建一个分词器实体名,操作如下:

其中,CHINESE_LEXER是分词器,MY_CHI-NESE_LEXER是分词器实体名。
1.4创建全文索引
(1)创建数据表
在SCOTT模式下,创建一张用于存储大量文本的数据表,操作如下:
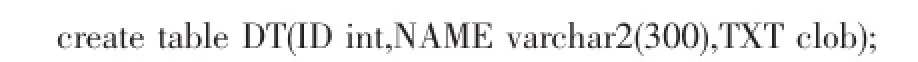
其中,TXT字段是clob类型,可以存储大量文本,单条记录可以高达4G容量,NAME用于文本来源的文件名称,ID只是一个编号。
(2)创建全文索引
Oracle数据的全文索引有 CONTEXT、CTXCAT、CTXRULE、CTXXPATH等四种类型,对DT表的TXT字段创建CONTEXT类型全文索引,操作如下:
create index IDX_DTTXT on SCOTT.DT(TXT)indextype is ctxsys.context parameters('LEXER MY_CHINESE_LEXER');
执行这条命令即可创建全文索引,其中ctxsys.context是全文索引类型,'LEXER MY_CHINESE_LEXER'表示使用名称为MY_CHINESE_LEXER的分词器。
2 全文检索测试
由于全文检索是在全文索引的基础上做检索,从理论上讲应该比模糊查询直接针对文本做查询要快一些,下面通过对比分析研究全文检索的检索速度。
2.1给DT表加载测试数据
为了能够重现测试结论,这里选用中文版HTML格式JAVADOC系列文档作为测试数据,该JAVADOC文档集共有8964篇、约198M字节,是Java语言的编程指南,每篇文档包含中英文字符,可作为测试数据。
向Oracle数据库加载CLOB字段内容时,通常不能直接插入,而应该采用流的方式加入,所以这些测试数据需要编写程序加载到DT表中,具体操作略,数据加载完毕后,DT表所占表空间大小约550M字节。
2.2维护全文索引
每次更新DT表TXT字段的数据后,应当及时进行全文索引维护,即同步和优化,使全文索引与TXT字段的内容吻合,具体操作如下:
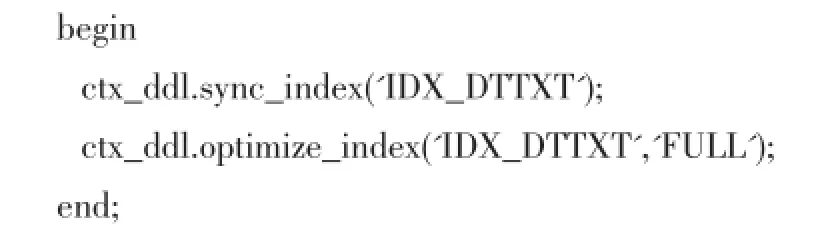
2.3全文检索与模糊查询对比测试
(1)查询工具与查询命令
使用PL/SQL Developer 9.0中文版为查询工具,使用下列语句来对比测试结果
模糊查询的语句为:
(2)查询方法
为提高对比分析的精确性,每次查询尽可能采用一致的环境,使用相同的查询工具,在相同的查询窗口,每次查询前等待CPU空闲。PL/SQL Developer 9.0设置为一次显示全部查询结果,操作系统中不额外运行其他应用程序,避免对系统资源的干扰。选用了“合成”、“网络”、“链接”等检索词。
(3)查询结果
全文检索和模糊查询对比测试的结果如表1所示。

表1 全文检索与模糊查询对比测试结果
表中:
记录数占比=查询结果记录数/DT 表总记录数(式1)
记录数互比=全文检索的结果记录数/模糊查询的结果记录数(式2)
查询速度互比=模糊查询的耗时/全文检索的耗时(式3)
耗时是查询过程所使用的时间,以秒为单位,来自PL/SQL Developer 9.0 给出的结果。
3 全文检索性能分析
(1)对测试数据本身的分析
测试选用JAVADOC文档集属于一个单一的专业领域,共有8964篇,占用550M左右表空间,有一定的规模,数据量对全文检索性能分析有意义。
测试中选择了7个检索词,这7个检索词的查询结果的记录数占比从0.007变化到0.975,覆盖范围比较广,检索词选取对全文检索分析有意义。
(2)查全能力分析
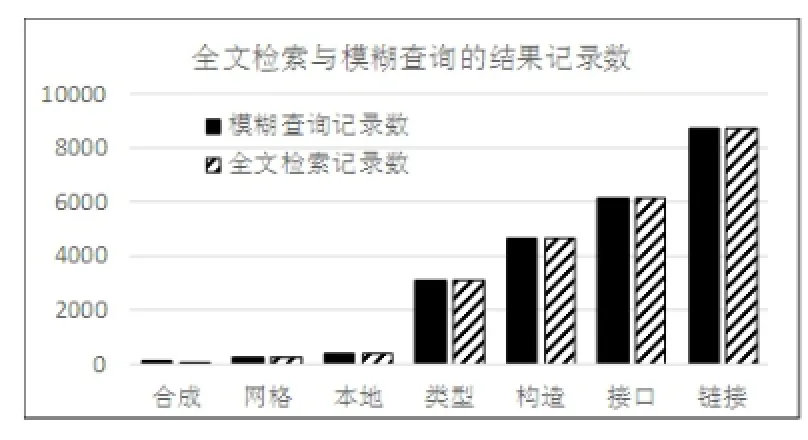
图1 全文检索记录数与模糊查询记录数
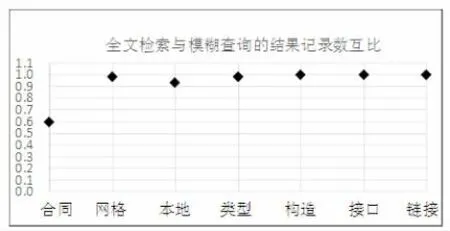
图2 全文检索记录数与模糊查询记录数互比
模糊是查询能够把满足条件的所有数据都查询出来,而全文检索由于可能存在分词不正确的原因,可能有少数满足条件的记录查询不到。从图1和图2可以看出,对相同表和相同的检索词,全文检索和模糊检索的结果基本相差很小,记录数互比最高到0.9998856,笔者推断,记录数互比很高的原因是我们使用专业文献作为测试数据集,并且使用专业词汇作为检索词。基本可以认为在专业领域全文检索可以查全所有结果。
(3)查询速度分析
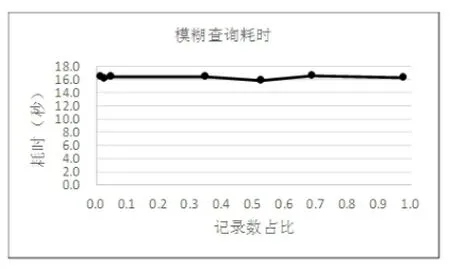
图3 模糊查询耗时
从图3中可以看出,无论查询结果记录占比为多少,模糊查询的时间基本上是一个常数,在16秒左右。反过来说明,模糊查询的耗时与查询结果的数量没有关系。这个测试结论印证了模糊查询机制,模糊查询要将检索词与所有记录的TXT字段内容进行比对,对同一个表每个检索词比对记录数是相同的,在一篇文档内比对的方法也是相同的,所以每个检索词的查询耗时基本相同。

图4 全文检索耗时
从图4中可以看出,全文检索的耗时随着检索结果的增加线性增加,这与全文索引的存储机制有密切关系。如果有多篇文档包含同一个索引词,那么就会对这个索引词建立起这些文档的编号链表,包含同一个索引词的文档越多,链表就越长。全文检索就是找到索引词的链表,并解析链表把文档编号分析出来。因此当索引词的记录数越多时,链表就越长,耗时就越多,基本是一个线性递增的关系。
从图5中可以看出,查询结果记录数占比小于0.1时,全文检索与模糊查询的速度互比有几十倍甚至上百倍,全文检索的优势非常明显。当查询结果记录数占比大于0.4时,全文检索与模糊查询的速度互比小于5,最小只有2.426,全文检索的优势减弱。综合图3和图4可以看出,模糊查询的耗时与查询结果多少无关,基本是一个常数,而全文检索查询的结果记录越多耗时越长,这是查询结果越多时全文检索优势迅速下降的根本原因。虽然全文检索的优势已经不是十分明显,但是全文检索两倍以上的速度优势仍然有应用价值。
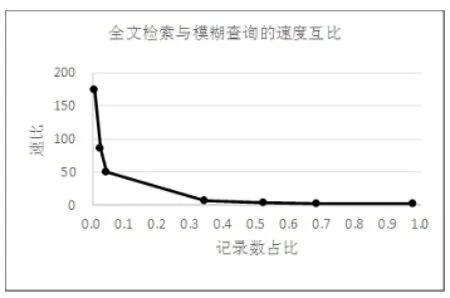
图5 全文检索与模糊查询的速度互比
[1]蒙辉,陈燕.Oracle Text技术在复杂结构数据库中的应用[J].计算机技术与发展,2007,17(4):38-44.
[2]葛振国,李建,何林糠等.基于Lucene的Oracle数据库全文检索.信息技术,2010(3):156-158.
[3]杨宝峰.数据库全文检索技术.黑龙江科学信息,2007(5)45-45.
Research on the Performance of Oracle Full Text Retrieval
GONG Jian-hua
(PLA Academy of National Defense Information,Wuhan 430010)
With more and more applications in full text retrieval,understanding of the performance of database full-text retrieval is needed.Introduces the method of setting Oracle text,and then the loads test data,tests the performance of full-text retrieval and fuzzy query,analyses the search ability and speed of the full-text retrieval in details.
Database;Full Text Retrieval;Fuzzy Query
1007-1423(2016)27-0036-04DOI:10.3969/j.issn.1007-1423.2016.27.010
龚建华(1973-),男,湖北麻城人,副教授,硕士研究生,研究方向为信息系统设计与数据工程
2016-06-21
2016-09-20
