基于包成批特性的OpenFlow流表高效区分存储算法
2019-03-13史长琼胡龙平
史长琼,胡龙平,熊 兵
(长沙理工大学 计算机与通信工程学院,长沙 410114)
1 引 言
软件定义网络(Software-Defined Networking,SDN)作为一种创新型网络架构,将数据转发和逻辑控制功能相分离,并为网络应用提供灵活的编程接口,显著提升了网络的灵活性和开放性,被认为是未来网络领域最有前景的发展方向之一.OpenFlow协议是SDN架构中最为成熟的南向接口协议之一,实现了控制平面与数据平面之间的信息交互和配置管理功能,提升了网络的可编程性和可管控性.然而,OpenFlow也给SDN数据平面的交换机带来了新的问题和挑战,其中一个突出的问题就是流表存储空间有限问题[1].
OpenFlow将网络协议栈扁平化,借助丰富的协议首部字段,并引入通配符支持任意字段的组合,实现网络流的灵活定义与管理,但也带来了流表存储空间需求显著上升的问题.随着OpenFlow协议版本的持续演进,流表匹配域数量不断增加,从1.0版本的12个已增加至1.5版本的44个,导致OpenFlow流表极其庞大.TCAM由于支持通配符查找方式,且能在一个时钟周期内输出查找结果,因而常用于OpenFlow流表的存储与查找.然而,TCAM成本高、能耗大、集成度低,导致容量有限,难以满足OpenFlow大规模流表的存储需求.因此,如何高效存储OpenFlow大规模流表,成为SDN数据平面亟待解决的一个关键问题.目前主要有两类方法解决该问题,一类采用压缩流表,另一类采用优化存储结构.
采用压缩流表的方法来减少OpenFlow流表存储空间.Kannan等人引入流标识符替代流表项15元组以减少流标识位,压缩OpenFlow流表项[2].Banerjee等人采用标签嵌套方法(Tag-in-Tag),将流表项替换成两层简短标签,使TCAM能容纳更多流表项[3].罗寿西等人应用流表快速聚合(FFTA)和增量流表快速聚合(iFFTA)方法,结合基于前缀的聚合技术,实现流表快速更新,以减小流表规模,提高流表匹配速度[4].葛敬国等人通过分析流表字段之间的共存和冲突关系,划分流表与切分子流表以压缩流表存储空间[5,6].Bo Yan等人提出一种桶中缓存规则方案(CAB),将匹配域划分为与所请求的桶相关的桶和缓存规则来减轻依赖性问题[7].上述算法在一定程度上能节省流表存储空间,但无法满足SDN大规模部署时的流表存储空间需求.
采用优化设计存储架构来解决OpenFlow流表存储问题.徐明伟等人基于现有商业交换机的各类硬件存储表,采用软件方式统一管理存储资源,进而建立多流表串行查找模型[8].Ferkouss等人采用SRAM和TCAM存储流水线查找表,并应用递归流分类算法提高OpenFlow包分类性能[8].吴国新等人在SRAM中采用散列表存储精确流表项,并将哈希冲突的流表项存储到TCAM中,以避免多次读取SRAM,加快流表查找速度[10].然而,该方法不适用于存储带通配符的OpenFlow流表项,且其散列冲突率将随着流表项的增多而快速上升.张志勇、贾智平等人提出了一种混合TCAM存储架构,采用基于NVM的TCAM缓存活跃流规则以提高缓存命中率,采用基于SRAM的小容量TCAM处理缓存失配包流以降低更新时延,并设计高效的规则迁移替换策略以充分利用TCAM资源[11].江勇、徐明伟等人提出一种流量感知的混合规则分配方案BALANCER,从逻辑上将TCAM划为主动部分和被动部分,并根据网络流量行为进行动态调整.同时,提出一种主动部分的高熵主动规则生成算法,为被动部分提供规则缓存方法和规则替换算法,提高OpenFlow交换机的TCAM利用率[12].Naous等人设计并开发了一个OpenFlow交换机,在NetFPGA芯片上采用TCAM与SRAM区分存储通配流表项和精确流表项[13,14],但是由于TCAM容量有限,无法满足大量通配流表项的存储需求.本文利用OpenFlow流的包成批特性,建立一种OpenFlow流表区分性存储架构,采用TCAM与SRAM区分存储包成批流和包稀疏流,以期望在一定程度上解决OpenFlow大规模流表的存储空间问题,从而提高流表查找性能.
2 OpenFlow流表存储
由于TCAM容量有限,难以满足OpenFlow大规模流表的存储空间需求,因此,现有OpenFlow交换机往往采用TCAM和SRAM相结合存储流表[10].图1给出了对应的OpenFlow流表存储与查找架构.当某个数据包p到达OpenFlow交换机时,首先提取其流关键字fid,然后在TCAM与SRAM中并行查找,若成功匹配到SRAM或TCAM中的某条流表项,则执行相应的动作集;否则,将数据包封装成流安装请求发送给控制器,待控制器生成并下发对应的流规则,再转发处理数据包,同时将流规则添加到流表.
在上述OpenFlow流表存储与查找架构中,一个关键问题是如何将所有流表项区分存储在TCAM和SRAM中,以加快网络包流的流表查找速度,提升OpenFlow交换机的数据转发性能.目前,一种典型的流表区分存储算法是:TCAM存储带通配符流表项,SRAM存储精确流表项[13].该算法在网络规模较小的情况下,能有效满足OpenFlow流表的存储需求,且流表查找效率高.然而,随着OpenFlow协议版本的不断升级,流表匹配域持续增多.同时,当OpenFlow进入大规模部署时,流表项数量也急剧上升.这将导致现有的TCAM芯片难以满足大量通配流表项的存储需求.对此,一种改进的存储算法是:TCAM存储大象流,SRAM存储老鼠流[14,15].该算法不仅解决了OpenFlow大规模流表的存储问题,而且使得大部分数据包查找命中TCAM流表,只有少部分数据包查找命中SRAM流表,在一定程度上控制了网络包流的平均流表查找开销.该算法考虑的是网络流中数据包的长期统计特性,忽视了数据包到达的动态变化特性,因而缺乏对网络包流的动态适应能力,因此,本文提出一种包成批流识别方法,以增强OpenFlow流表存储的动态适应能力.
3 基于包成批特性的OpenFlow流表区分存储算法
3.1 数据包成批到达特性
大量研究结果表明:在分组交换网络中,包到达过程并不是通常所预测的泊松流,而是彼此相关,具有局部性特点[16-18].从应用角度来看,网络流量局部性主要由网络应用程序和数据传输协议共同作用所致,例如Web应用产生大量的文件下载活动;网络电话、网络电视以及视频聊天等流媒体的应用,这些网络行为都会产生持续的大块数据传输活动,使得网络数据包流表现出明显的局部性特点.
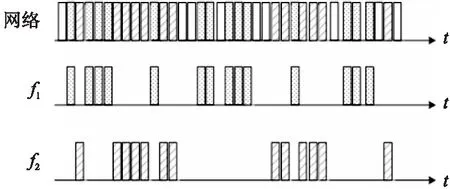
图2 网络流量局部性示意图Fig.2 Network traffic locality
从流的角度来看网络流量局部性表现为:同一流中的数据包分布并不均匀,而是呈现出分批集中到达的特点.图2展示了某段时间内网络数据包流分布的局部性特点.该时间段内共到达36个数据包,其中,流f1为web访问流,包含14个数据包,分3批集中到达;流f2为ftp流,包含13个数据包,分2批集中到达;剩余9个包则零散分布于f1、f2之外的稀疏数据包流中.由此可看出,大部分数据包分布在少数流上,且表现出明显的分批集中到达特点.
SDN作为一个新型的网络架构,并没有改变网络用户行为及其流量的分布特性,反而因OpenFlow中引入通配符,将多条数据包流汇聚到一条,使得网络流量的局部性特点更加明显.网络流量局部性在OpenFlow流中表现为:
a)从时间维度上看,同一流中的数据包分布往往呈现出分批集中的特点;
b)当某条流连续到达几个数据包时,说明该流已出现包成批现象,后续将还会有若干个数据包紧接着到达.
3.2 算法思想
基于上述包成批到达特性,可将OpenFlow网络流区分为数据包分批集中到达的包成批流和数据包分散到达的包稀疏流.对于OpenFlow交换机而言,可建立相适应的流表区分存储算法,通过采用包成批流识别方法和流表项替换方法,将少量的包成批流存储在TCAM中和大量的包稀疏流存储在SRAM中,以解决OpenFlow大规模流表的存储空间问题,并提高OpenFlow流表的查找效率,实现网络包流的快速分类.
抱着美好的愿望,老王家让王祥去了离家乡最近的L市。初到城市里王祥自然觉得什么都新鲜,不过王祥从各种电视节目里也了解了一部分城里人的劣根性,比如说骄傲,比如说冷漠,比如说狡诈。王祥虽然也不觉得这些玉器能像电视里说的那样值那么多价钱,但是连蒙带骗,能拼凑到1 0万元的话就够本了。
3.2.1 包成批流识别方法
为实现上述存储算法,需要根据OpenFlow网络中的包到达过程识别包成批流.在OpenFlow交换机中,每条流表项对应一条OpenFlow流,记录其短期内的包到达情况.当一条OpenFlow流刚出现时,将其对应的流表项存入SRAM中;当该流到达一个数据包时,若出现包成批现象时,将其流表项换入到TCAM,否则继续存放在SRAM中.
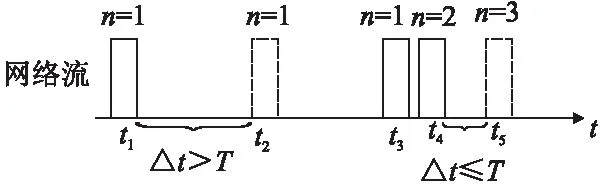
图3 OpenFlow包成批流识别示意图Fig.3 OpenFlow packet-in-batch flows identification diagram
包成批流识别是上述OpenFlow流表区分存储算法中的一个关键问题.为此,根据包到达过程设计包成批流识别方法如下:
a)每条流表项记录对应流的最近一个包到达时间tlob和最近一批包个数n;
b)对于每个新到达的数据包,根据其到达时间tcur,判断该包与最近一个包是否属于同一批次,即判断时间间隔Δt=tcur-tlob是否小于设定的批包间隔阈值T;
c)若该包与最近一个包同批,则更新批包信息,即n=n+1,tlob=tcur;
d)根据当前批包个数n判断是否出现成批现象,即是否大于设定的批包个数阈值N.图3形象展示了OpenFlow包成批流识别的两种情形.对于t2时刻到达的数据包,Δt=t2-t1>T,判定其与t1时刻到达的数据包不同批,该流处于包分散状态;对于t5时刻到达的数据包,Δt=t5-t4≤T,且n≥N,判定该流处于包成批状态.
3.2.2 流表项替换算法
依据上述包成批流识别方法,当SRAM中的某条流到达一个数据包时,若被判定为包成批流,则需换入TCAM.此时,若TCAM已满,即TCAM.storage=full,则需换出一条流到SRAM中,因而需要设计合适的流表项替换算法.考虑到不同流的包批间隔差异性,每条流的空闲时间无法准确反映未来一段时间内对应流表项的失效概率.为此,每条流表项记录最近一个包到达以来的空闲时间tidle和对应流的平均包批到达间隔Δtavg,进而将两者的比值定义为流表项的失效预测值P.流表项替换的具体选择方法如下:
a)每条流刚出现时,平均包批到达间隔Δtavg初始化为T;
b)每到达一批新的数据包,即新到达的数据包与最近一个包不同批,则更新平均包批到达间隔为Δtavg=αΔt+(1-α)Δtavg,其中α是权重系数;
c)当TCAM需要替换一条流表项时,计算TCAM中每条流表项的空闲时间tidle=tnow-tlob,即当前时间tnow减去最近一个包的到达时间tlob,进而计算流表项的失效预测值P=tidle/Δtavg;
d)找出TCAM中P值最大的流表项,即为需换出的流表项.
4 算法实现
依据上述OpenFlow流表区分存储算法,可得到对应的流表查找过程,其伪代码实现如表1所示.当数据包p到达OpenFlow交换机时,首先提取其关键字段,得到流标识符fid,进而并行查找TCAM和SRAM中的流表(1~2行).若流表查找失败,则将数据包p封装成packet-in消息发送给控制器,待控制器生成并下发流规则后,再转发处理数据包p,同时将对应的流规则添加到SRAM流表,并生成流表项f(3~8行).若流表查找成功命中某条流表项f,则根据其动作集转发处理数据包p,并更新其相关参数,包括:最近包到达时间f.tlob、当前批包个数f.num、平均包批到达间隔f.Δtavg(9~15行).若流表项f属于SRAM流表,且f.num达到批包个数阈值N,则进一步判断TCAM是否已满(16~17行).若TCAM未满,则直接将流表项f换入TCAM,否则计算其每条流表项的失效预测值P,找出P值最大的流表项e,并将其换出到SRAM,最后将f换入TCAM(18~23行).

表1 OpenFlow流表包成批流识别算法和替换算法Table 1 OpenFlow packet-in-batch flows identification algorithm and replacement algorithm
5 实 验
5.1 网络流量样本
实验选取江苏省计算机网络技术中心发布的2个高速骨干网络流量样本*1 Network traffic traces. http://iptas.edu.cn/src/system.php,2015.(CERNET20110418、CERNET20140509)作为数据集.这2个数据集是从速率为10Gbps的中国教育科研网骨干链路上按照1:4的比例采集而得,采集日期分别为2011年4月18日,2014年5月9日,持续时间分别约为107秒和58秒,采集的数据包个数均为15,420,235.
流表规模对流表存储与查找性能具有重要影响,图4给出了上述两个数据集中的并发网络流数量.为简化起见,选取传统5元组(源IP地址、目的IP地址、源端口、目的端口和协议类型)做为流标识符.实验从数据集中逐个读取数据包,提取其关键字段,并计算流标识符,然后每105个数据包输出一次并发流数量.其中,流超时间隔设为10秒.
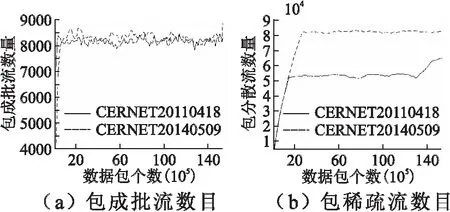
图4 并发网络流数量Fig.4 Concurrent network traffic
从图4可看出:
1)包成批流数量整体上比较稳定,基本保持在8K~9K范围内,适合采用容量较小的TCAM存储;
2)包稀疏流的稳定数量是包成批流数量的好几倍,且与流量样本密切相关,可采用容量相对较大的SRAM存储.
5.2 TCAM流表命中率
TCAM流表命中率是衡量OpenFlow流表区分存储算法优劣的关键性能指标.
5.2.1 影响因素
实验首先通过设置不同的批包间隔阈值T和批包个数阈值N,测量这两个参数对TCAM命中率的影响.实验分别将N取固定值且T取不同值、T取固定值且N取不同值,依照上述实验过程,得到本文所提算法的TCAM命中率如图5和图6所示.从图5可以看出:当批包间隔阈值T取800ms时,批包个数阈值N越小,TCAM命中率越大.图6给出了当N=3,T每隔50ms取到不同值时,对应TCAM命中率平均值的变化曲线,从图6可以看出:当T在[750,850]范围内,两个样本对应的平均TCAM命中率均处于最高水平.因此,认定在批
包个数阈值N为3、批包间隔阈值T取800ms时,本文所提算法取得最高TCAM命中率.
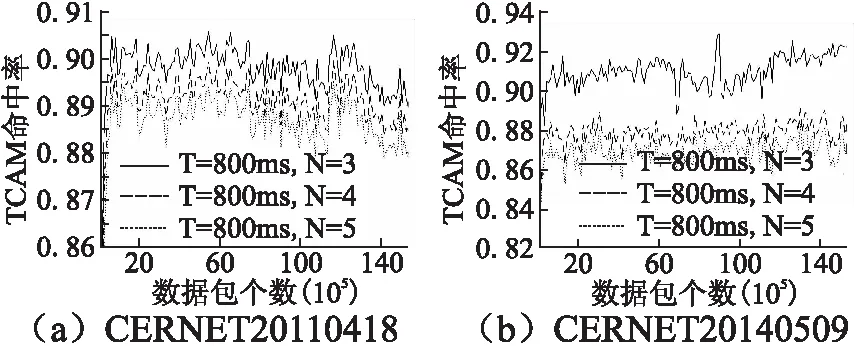
图5 不同批包个数阈值的TCAM命中率Fig.5 TCAM hit rate of different batch number thresholds
5.2.2 对比
实验将本文所提的包成批流/包稀疏流区分算法DFT-BS与目前主流的大象流/老鼠流区分算法DFT-EM进行对比.首先,根据上述实验结果,为DFT-BS算法设置批包间隔阈值T=800ms和批包个数阈值N=3,为DFT-EM算法设置不同的大象流包个数阈值PKT.然后从数据集中依次读取每个数据包,计算流标识符,执行流表查找过程,并记录TCAM命中次数.每105个数据包统计一次TCAM命中率,最后得到两个流表区分算法的TCAM命中率如图7所示.

图6 不同批包间隔阈值的TCAM命中率Fig.6 TCAM hit rates for different batch interval thresholds
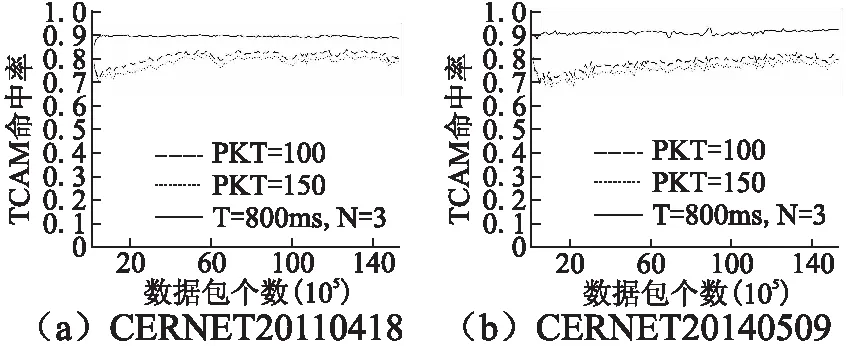
图7 TCAM命中率对比Fig.7 TCAM hit rate comparison
从图7可以看出,无论哪个样本,本文所提DFT-BS算法的TCAM命中率明显高于DFT-EM算法,且始终稳定大于0.9.
综合上述实验结果表明:本文所提算法的TCAM命中率明显高于目前主流的大象流/老鼠流区分算法,且基本稳定保持在0.9以上,当批包个数阈值N为3、批包间隔阈值T取800ms时,TCAM命中率达到最大值,可有效提高OpenFlow流表查找性能.
6 结 论
针对TCAM难以满足OpenFlow流表的存储需求的问题,本文基于网络包成批特性,提出了一种OpenFlow流表区分存储算法,在设计包成批流识别方法和流表项替换方法的基础上,将少量的包成批流和大量的包稀疏流区分存储在TCAM和SRAM中.该算法有效提高了TCAM流表命中率,增强了OpenFlow流表存储的动态适应能力,对加快web下载、在线视频等网络行为的数据包查找速度具有现实意义.
