软件定义网络中一种两步式多级流表构建算法
2018-10-11邱智亮孙士勇潘伟涛王伟娜张之义
郑 凌,邱智亮,孙士勇,潘伟涛,王伟娜,张之义
(1. 西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2. 中国电子科技集团公司第五十四研究所 通信网信息传输与分发技术重点实验室,河北 石家庄 050081)
软件定义网络(Software-Defined Network,SDN)[1]是一种新兴的网络技术,它将传统网络的控制面和数据面相分离,并通过开放的软件定义应用程序接口(Application Program Interface,API)实现网络功能的灵活重构,构建动态、开放、可控的网络环境,极大地改善了网络的扩展能力和灵活性.OpenFlow[2]是SDN最重要的南向接口标准,其主要思想是在数据平面上采用基于流表(Flow Table)的转发机制,并提供了数据面和控制面的标准接口.如今,随着网络新型业务的快速发展,流表匹配域不断增加、流表规模爆炸性增长,流表的存储与查找已逐渐成为OpenFlow交换机的性能瓶颈.并且自OpenFlow 1.1版本起提出了多级流表的概念,多级流表的划分与构建仍然是一个开放性问题.此外,随着 40/ 100 Gbit/s 以太网标准的出现,不断增长的转发速率需求对交换机的转发性能和硬件设计提出了新的挑战.因此,针对高速环境下OpenFlow的多级流表研究在近年来得到了广泛关注[3-4].
文献[5]提出了一种哈希表和三态内容寻址存储器(Ternary Content Addressable Memory,TCAM)相结合的多级流表实现方式,但是该方法依赖于流表中匹配域的类型,只能实现TCAM与哈希表互相交替的流水结构.文献[6]针对数据平面转发提出了可重构匹配流表(Reconfigurable Match Table,RMT)模型,该模型实现了一个可重新配置的流表,支持任意的数据位宽和深度,具备了协议无关和可编程的灵活性.但是这种思想在硬件实现时需要消耗大量的静态随机存取存储器(Static Random Access Memory,SRAM)和TCAM资源,不具备实际工程的可实现性.文献[7]提出了一种SDN流表化简机制(Flow Table Reducation Scheme,FTRS),该算法针对IP表项进行前缀聚合,能够在不影响网络功能的前提下,减少流表项的条数,从而压缩流表的存储空间.但是这种方法仅能应用于IP查找,难以适应OpenFlow的多字段匹配需求.考虑到OpenFlow匹配域的特征,文献[8]提出了一种启发式流表空间优化算法(Heuristic Storage space Optimization algorithm for Flow Table,H-SOFT),该算法分析了OpenFlow流表结构定义字段之间的共存和冲突关系,通过分级消除流表中的互斥字段从而降低流表的存储空间.文献[9]提出了一种OpenFlow多级流表结构及其映射算法,将单一流表映射到多级流表中进行高效存储和查找.但是该方法难以对流表中的匹配域进行均匀的拆分,导致流表空间压缩性能不够理想,且硬件开销较大.文献[10]提出了一种平衡时空的自适应多级流表构建方法,该方法根据每个匹配域的重复率对流表进行分级,并且在一片TCAM中为每一级流表分配一定的空间用于存储流表项.但是该方法仅使用了一片TCAM进行多级流表的存储,因而不能进行流水操作,带来了较大的时延,无法实现硬件交换机端口的线速处理.
针对OpenFlow流表面临的这些问题,文中提出了一种两步式多级流表构建方法,通过流表匹配域的流类别拆分和正交分解两个步骤实现多级OpenFlow流表的构建,能够实现流表存储空间的有效压缩,同时保证了多级流表查找的硬件可实现性和流水线处理速度,支持 100 Gbit/s 线速处理.
1 OpenFlow多级流表结构
1.1 OpenFlow流表
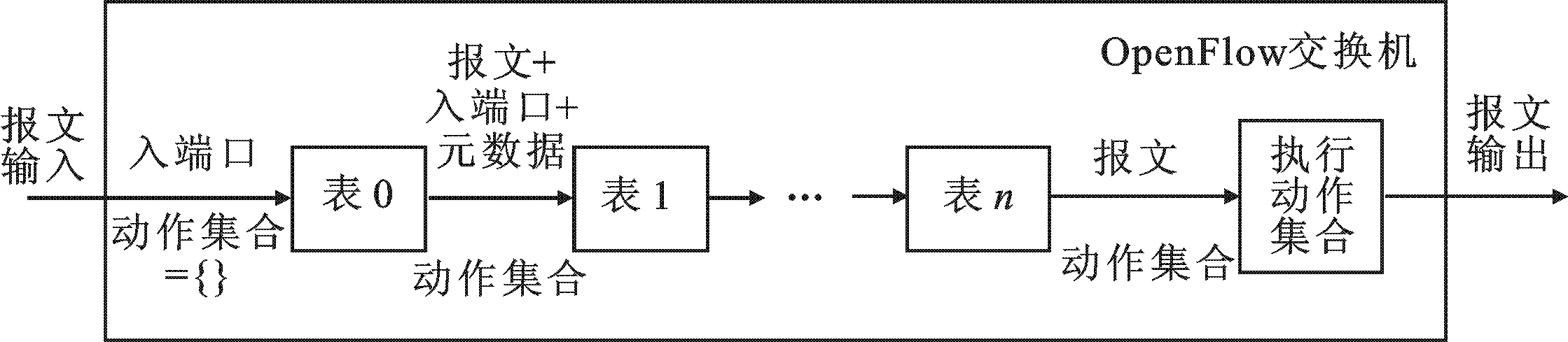
图1 多级流表工作流程
最初的OpenFlow 1.0版本将转发规则存放在一张单级流表中,但当网络规则变的很复杂时,这种单流表结构不仅会造成流表资源的浪费,而且还限制了应用层业务规则的制定.因此,在OpenFlow 1.1版本中提出了基于流水线工作方式的多级流表概念,多级流表的工作流程如图1所示.分组进入交换机后,将从流表0开始依次匹配,流表项将以优先级从高到低的顺序与数据包进行匹配,当数据包成功匹配到一条流表项后,根据流表项中的指令进行相应操作(例如跳转至后续的某一流表继续处理,增加或者修改该数据包对应的动作集合,更新元数据等).当数据包已经处于最后一个流表时,其对应的动作集合(Action Set)中的所有动作指令将被执行(例如转发至某一端口、修改数据包某一字段、丢弃数据包等).
1.2 符号描述
流表T,是包含多个流表项e的集合,每条流表项可以包含多个匹配域(Match Field).用符号f表示流表中的匹配域,如OpenFlow协议定义的IP源地址(IPSRC),IP目地地址(IPDST),以太网源地址(ETHSRC)等字段都称为匹配域.设流表T共有n条流表项,每条流表项由d个匹配域{f1,f2,…,fd}构成,令si表示匹配域fi的位宽(例如,IPV4SRC的位宽为 32 bit,ETHDST的位宽为 48 bit),则单级流表T的总存储空间为
(1)
如果将流表T分解为K个子流表{H1,H2, …,HK},则对于第k个子流表,其中 1≤k≤K,设其包含了Nk条表项,每条流表项包含了Mk个匹配域,令sk,j表示第k个子流表的第j个匹配域所占用的存储空间,则K个子流表所占用的总存储空间为
(2)
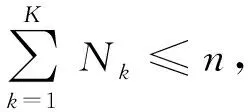
(3)
由式(3)可知,分级之后的流表存储空间小于分级之前的,因此,通过流表分级的方式能够减少流表存储空间,提高流表资源的利用率.使用流表空间压缩率作为指标衡量流表分级算法的性能.定义流表空间压缩率p为将单流表划分为多级流表之后节省的流表空间的比率,则
(4)
设已知交换机可接受的查找处理时延为D,系统的时钟频率为fCLK,则最大流表级数K=DfCLK.
流表分级问题从而转化为如下的最优化问题: 已知交换机中,原始单级流表T,交换机可接受的最大流表级数K为DfCLK,求多级流表的集合H= {H1,H2…,HK},使得
H=argminp(H1,H2,…,HK) .
(5)
2 两步式多级流表构建算法
2.1 基本思想
虽然OpenFlow标准给出了13个必选的匹配域,但是在实际的应用场景中,用户通常并不需要同时用到全部的13个匹配域对流进行匹配.在特定应用中,只需要关注某些特定的字段.例如,在桥接路由器中,桥接分组只关注二层字段的匹配; 路由分组只关心IP地址的匹配; 而访问控制列表(Access Control List, ACL)采用五元组对输入分组进行过滤.由此可见,可以根据不同的数据流处理逻辑的功能,将一张包含所有匹配项的流表,划分成多个相互独立,且具备不同数据流处理功能的逻辑流表.例如,将桥接转发,路由转发,以及ACL各维护一张表,这样能够优化流表中通配符所占用的空间,节约流表所需的存储空间.
此外,由于SDN对业务流的细粒度分类需求,通过匹配域的正交组合而产生的流表项会导致流表中存在很多重复的内容,也会使得流表的规模显著增加.例如,在服务质量保证(Quality of Service,QoS)中,需要根据输入分组的源IP地址以及目的IP地址得出分组要入队的队列号,从而实现对不同数据流的区分服务.假设源IP地址包含了M种匹配,目的IP地址包含了N种匹配,则在单级流表中就需要M×N条表项.这种正交组合会导致流表项数爆炸性增长.而如果把单流表的流表项通过匹配域的正交分解形成多个流表,可以压缩各匹配域中的重复值,也能够在很大程度上节省流表的物理存储空间.例如,将源IP地址,目的IP地址分别存储在2个流表中以流水线的方式进行查找,查找得到的中间结果使用元数据(metadata)进行传递,则只需要存储M+N条表项,从而降低存储流表所需的空间.综上所述,可以通过流类别拆分和匹配域间正交分解两个步骤来实现多级流表的构建.
2.2 算法流程
2.2.1 流类别向量拆分
定义流类别向量α=(b1,b2,…,bd),对于某一条流表项e= {f1,f2,…,fd},若其匹配域fi不为通配符“*”,则将bi置1;反之,则将bi置0.例如,单流表T的所有匹配域为{ETHDST,IPV4SRC,IPV4DST,TCP/UDPSRC,TCP/UDPDST,IPPROTO},桥接转发只关注目的MAC地址,可将桥接转发规则表示为α1= (1,0,0,0,0,0).路由转发需要关注源IP和目的IP地址,因此,路由转发规则可以表示为α2= (0,1,1,0,0,0).而ACL表利用五元组对输入分组进行过滤,则ACL规则可以表示为α3= (0,1,1,1,1,1).
根据流类别向量的不同,可将单级流表T拆分为多级流表.为了衡量拆分某个流类别向量后能够压缩的流表空间,定义分级收益C(αi)为
(6)
其中,ni为流类别向量αi所对应的规则数.每次迭代时,优先选取分级收益最高的流类别向量作为新的一级子流表.在子流表存储时,需要根据该子流表对应的查找算法,选取合适硬件存储器进行存储,具体描述如下.

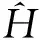
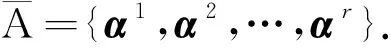

2.2.2 匹配域间正交分解
通过分解流表项中匹配域间的正交组合关系,压缩匹配域中的重复表项,进一步对流表进行分级.主要思想是统计出流表中每个匹配域fi的重复率,其定义为整个流表中匹配域fi中包含内容重复的次数,记为R(fi).每次迭代时,以贪心的方式选取重复率最高的匹配域提取出来作为一级子流表进行压缩存储,从而实现对流表规模的进一步压缩.直到流表级数达到最大流表级数约束K,或者全部匹配域均已提取完毕时,算法停止,具体描述如下.
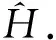

(6) 继续遍历集合S,直到集合S中所有元素遍历完毕或者多级流表H的级数等于K.
通过正交分解进行流表分级时,流表项中各个字段之间的组合关系也随之消失.为了保证子流表分级前后数据包匹配结果的一致性,需要通过metadata传递查找的中间结果,最后根据各级流表查找得出的元数据集合查找动作表,得出最终的action.而metadata只需在action表中存储前级表项查找得到的序号即可,因此,metadata的存储开销非常小.
3 性能仿真
3.1 软件仿真
由于OpenFlow还没有广泛部署于实际网络中,所以外界难以获取实际OpenFlow网络中的流表信息.文中的实验数据来源于ISN国家重点实验室研发的高性能同轴电缆宽带接入(HIgh-performance Network Over Coax,HINOC)[11]网络中的流分类规则集,并结合OpenFlow 1.3版本的必选匹配域加以扩充,生成不同规模的流表测试集,包括从INPORT到UDPDST的13个匹配域,能够在一定程度上反映实际OpenFlow网络中的流表情况.文中实验数据均是在该实验条件下得出的.
首先分析文中提出算法的流表存储空间压缩性能,其中流表压缩率指标的定义由式(4)给出.不同流表级数N以及不同的流表规模下的仿真结果如图2所示.可以看出,相对于单级流表结构,文中方法分级之后能够节省60%以上的流表空间.在相同的表项数量下,流表划分的级数越多,流表的空间压缩率越高.这是因为随着流表级数增加,流表中不关注的字段表项以及字段内重复的表项被压缩的越多,从而节省更多的存储空间.但是,为了实现流水线方式的查找,多级流表需要存储在相互独立的硬件存储器中,因此,更多的流表级数会消耗更多的硬件资源,同时更长的流水线也会增加控制逻辑的复杂度.因此,在实际应用中,要视实际的硬件资源情况来确定流表的级数.此外,从图中可以看出,在流表级数相同的情况下,随着流表规模的增大,流表压缩率的变化较为平缓.这表明在测试集中,文中提出的算法的流表空间压缩性能对于流表规模变化不敏感,具有较高的稳定性.
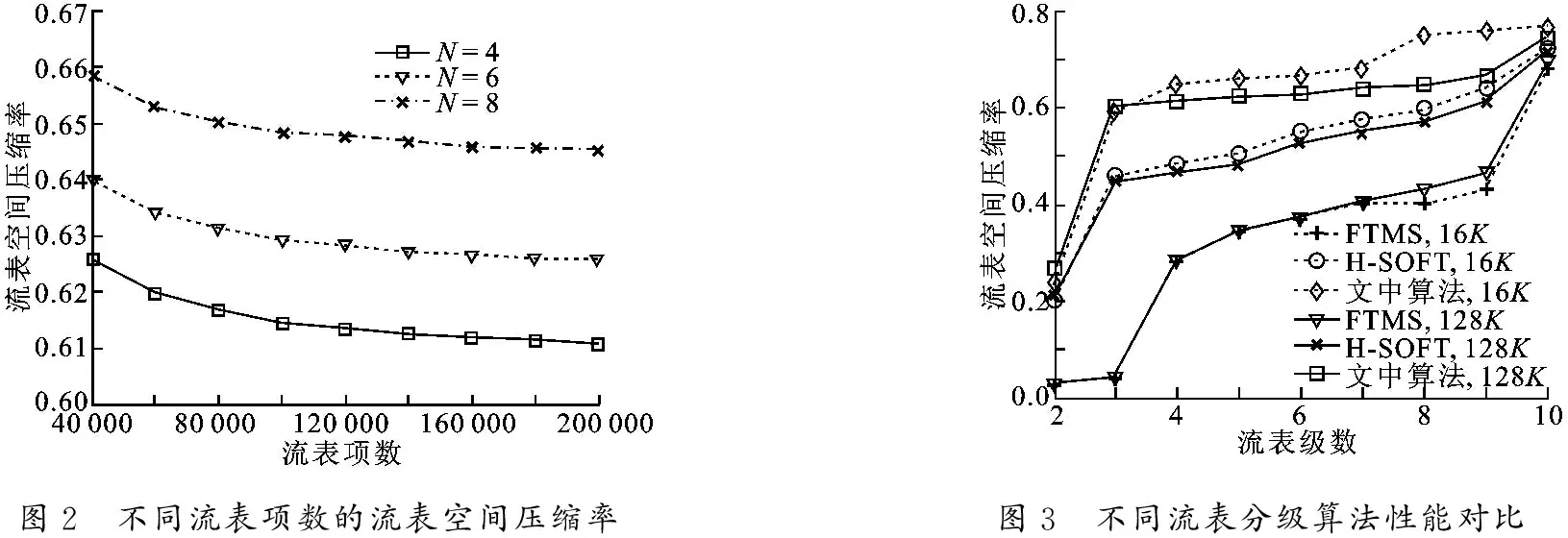
图2 不同流表项数的流表空间压缩率图3 不同流表分级算法性能对比
接下来分析不同流表分级算法之间的流表空间压缩率性能对比,对比方法包括FTMS[9]算法以及H-SOFT[8]算法,流表规模设置为16K以及128K条表项,仿真结果如图3所示.从图中可以看出,各方法的流表压缩率随着流表级数的增加而增加.当流表级数较小时 (K=2,3),FTMS算法的流表压缩性能较差.这是由于这种方法每次分级时只提取出一个匹配域作为一级流表进行压缩存储,这种方式无法实现多个匹配域的均匀拆分,导致在流表级数较低时性能会受到严重影响.H-SOFT算法是一种启发式的流表分级算法,该算法首先对流表的匹配域进行分析,删除表项中的互斥字段从而节省空间.从图3中可以看出,在不同的流表级数和流表规模下,文中算法均具有较好的流表压缩性能.当流表级数N=8,流表规模为128K条表项时,相对于FTMS算法,文中算法性能提高了51.5%; 相对于H-SOFT算法,文中算法性能提高了21.4%.当流表级数继续增大时 (N=10),几乎所有字段都被拆分出来作为一级单独的流表,此时各种算法性能较为接近.
3.2 FPGA实现
在现场可编程门阵列(Field Programmable Gate Array,FPGA)平台上验证了该多级流表构建与查找算法,实验环境为Xilinx Virtex 7 xc7vx690t,ISE 14.6以及Modelsim 10.4.FPGA多级流表模块设计如图4所示,主要包括帧解析模块,流表管理模块,分组处理模块以及多级流表模块.当一个分组到达时,分组头部进入帧解析模块中提取待匹配的字段信息,而分组数据传送至分组处理模块中进行缓存.分组头部字段提取出之后进入多级流表模块,以流水线的方式依次匹配各个子流表.多级流表模块包括TCAM、SRAM和FPGA片内随机存取存储器(Random Access Memory,RAM).FPGA片内RAM根据查找算法的不同,分为精确匹配模块、前缀匹配模块和范围匹配模块.精确匹配模块使用哈希表查找,前缀匹配模块使用比特向量(Bit Vector,BV)[12]算法进行查找,范围匹配算法使用范围比特向量编码(Range Bit Vector Encoding,RBVE)[13]算法进行查找.多级流表匹配结束后得到的匹配结果通过指令码传递到分组处理模块中,分组处理模块从输出缓存中提取出分组数据并执行相应的操作.流表管理模块负责表项的配置,更新和管理.仿真的输入数据为64字节的以太网最短帧突发,仿真结果显示在一定的流水线时延之后,查找结果能够连续输出,与输入数据的速率相同,说明文中方法能够实现流表的线速查找.ISE综合工具显示该设计的最高时钟频率能够达到197MHz.在具体硬件实现中,只需系统时钟在150MHz以上,即可满足150MPPS(Million Packets Per Second)的分组处理能力,实现 100 Gbit/s 的线速处理.
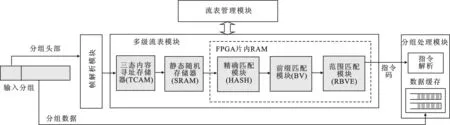
图4 多级流表模块的FPGA实现
4 结 束 语
针对SDN中多级流表的分级和查找问题,提出了一种两步式多级流表构建方法.通过对流表进行流类别拆分和字段间正交分解两个步骤将单级流表构建为多级流表,在保证硬件可实现性的前提下,充分利用了流水操作提高了数据吞吐量.软件仿真与FPGA验证的结果表明,该方法能够实现流表存储空间的有效压缩,并且能够满足 100 Gbit/s 的线速查找要求.
