一种应用于填空型阅读理解的句式注意力网络
2019-03-13邹依婷周澄睿薛瑶环黄君扬金轩城
霍 欢,邹依婷,周澄睿,薛瑶环,黄君扬,金轩城
1(上海理工大学 光电信息与计算机工程学院,上海 200093) 2(复旦大学 上海市数据科学重点实验室,上海 201203)
1 引 言
机器阅读理解(Machine Reading Comprehension,MCR)是一项对阅读理解中的问题、文章、答案三者间存在关系的建模任务,旨在根据问题给出的信息,从文章中抽取答案.填空型阅读理解(Cloze-style Reading Comprehension)是根据文章信息推导问题,并且用文章中的某个词汇作为回答问题的答案.因此,问题中的实体与文章中的实体间存在联系,可以利用实体间的相关性和相似性解决阅读理解任务.
目前很多工作都是基于神经网络模型和标准的软注意力机制(soft-attention mechanism)[1],如使用一个语法框架定义阅读理解中的句子,并且单向查询文章词汇的权重(Attentive Reader[2]);或者从行和列两个维度得到文章注意力矩阵和问题注意力矩阵(AoA Reader[3]);或者对给定的候选集进行打分、排序,选择最优的答案[4].
这三种方式能解决大部分阅读理解任务,但这三者是在单个词汇上进行分析,用包含一个空白单词的问题查找含有多个单词的文章,其候选答案的空间复杂度至少为O(n),其中n为文章中包含的单词个数.为此,文献[5]利用问题中的事实性的实体查找现有的知识库,进而给出问题答案.但结构化数据库不能再根据上下文进行问题推理,从而不能解决非事实性的推理问题.
例如,对于给定的句子“a young man wearing a blue skirt”,若采用以词为单位的编码,即每个词仅获取其相对于前后两个词的信息,那么对句子的理解就仅停留在单个词义上.例句为一个定语结构.但作为一个句子结构 “a young man ”为主语,“wearing”是谓语,“a blue skirt”为宾语.词级编码上面给出的方式则均不能分析出上述句子的结构信息.因此,本文针对典型的序列对序列(Sequence-to-Sequence,Seq2Seq[6])模型,着重解决句子中句式的解析问题,以兼顾词义信息理解和结构理解.
本文提出一种基于神经网络的句式注意力网络SAN(Syntactical Attention Network).SAN模型旨在对文章中包含答案的句子结构和问题结构进行对齐(Alignment)[7-9],即通过它来建立两个句子间词和词、短语和短语、词和短语的语义关系.与在文章中直接查找问题词汇的方式不同,SAN模型可以利用对齐操作解决语义问题.首先,SAN模型用问题向量矩阵对文章句子向量进行搜索,获取与问题相关的文章句子,建立候选答案句子集合;其次,SAN模型用一个双向神经网络分析句子中的实体以及实体间的联系,用词串表示实体名词,实体间的动词则用联系来表示,获取主体、联系和客体的三元组
本文的贡献主要有如下3点:
1)提出了一种神经网络模型SAN,在语义相关的基础上,利用句式结构对齐解决填空型阅读理解任务.
2)SAN采用了一种问题注意机制进行句子筛选,获取与问题相关的文章句子集合,缩减搜索空间.
3)利用句式注意力机制对句子结构进行三元组的模式设定,只对重点相关句子进行标注.利用三元组间的相似性,解决阅读理解任务中候选文章句子与问题间存在的不对齐问题,从而能高效地匹配问题答案.实验采用端对端(end-to-end)[10]的方式对模型进行训练,用合成数据集验证了SAN模型.同AOA相比,SAN模型的处理速度与答案的准确率均有提升.
2 相关工作
Attentive Reader作为第一个用于仿真阅读理解的神经网络模型,用一个双向的RNN 网络单独编码文章与问题,并且用问题的表示匹配文章中的词汇.Window-based Memory Networks(MemNN)是Project Gutenberg在工作[11]中提出的CBTest数据集的基准模型,使用记忆上下文嵌入的方式代替RNN编码,并用上下文嵌入的内容匹配问题.这些模型都是学习用问题中单个词的表示方式匹配文章中的词汇,并获取答案.类似地,序列对序列的神经网络模型[12]、基于神经网络的记忆网络如神经图灵机[13]和它的变种也是使用上下文嵌入的方式处理候选答案[14].
最近,已经有很多对比较复杂的阅读理解进行推理的工作,比如Memory Network(DMN)[15],针对短文本阅读理解,使用多次动态迭代的方法,根据问题表示的内容迭代用记忆网络中关注到的文章信息获取问题答案.针对长文本填空型阅读理解,AS Reader[16]使用简单的注意力模型直接从上下文中选择答案,而不是通过计算文档中单词混合表示的相似度获取最终答案.AoA Reader介绍了一种问题与文章间的双向查找方式,并且对查找采用加权和不加权重的处理方法,汇总每个问题单词的注意力,该模型在CNN数据集和CBTest NE/CN数据集上均获得了一个较高的准确率.
为了解决阅读理解任务,上面这些工作都在关注文章内容与问题词汇间的匹配问题,并没有对问题以及文章句子进行句式分析.本文介绍一种基于GRU的句式注意力网络分析问题中的实体和实体关系,并用标记词串的方式表示句子.此外,利用问题词串对齐问题相关的文章句子中词串的方式,匹配答案位置,提高模型输出答案的准确性.
3 背景知识
这部分将介绍阅读理解任务中填空型阅读理解的系统框架以及数据预处理部分的嵌入层、编码层、以及数据分析部分的句子筛选层和句式注意力层.
3.1 系统框架
机器阅读理解中通常用三元组
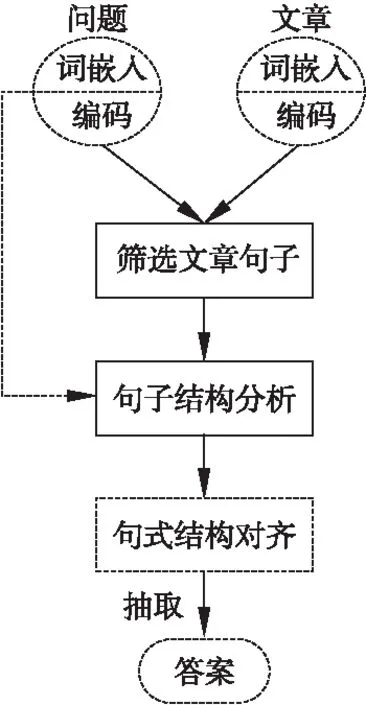
图1 SAN流程图Fig.1 SAN flowchart
设一篇文章包含L个句子,并且每个句子Sl(l∈L)有Tl个单词,Sl=[wl1,wl2,…,wlt],wlt表示句子Sl中的第t个单词,t∈[1,T].所有文本信息用相同维度的词向量表示,得到问题的表示为Q=[w1,w2,…,wn],文章的表示为D=[S1,S2,…,SL].图1为SAN模型的数据处理流程图.下面将简单分析每层的作用.
3.2 词嵌入层
在图1中,词嵌入层将输入的词汇x通过词嵌入[17,18]的方式化为词向量w,w=E(x).通过词嵌入模型得到的词向量中既包含了词本身的语义,又蕴含了词之间的关联,同时具备低维、稠密、实值等优点,可以直接用于阅读理解的后续分析.
3.3 编码层
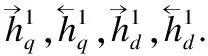
(1)
(2)
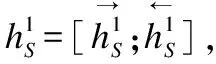
3.4 句子筛选层
主要作用是筛选出全文中与问题最相关的句子.给定一系列的表示,句子筛选模块利用注意力分配权值选择关键句,同时产生以问题和文章为前提的句子向量矩阵.
3.5 句式注意力层
与句子筛选层的处理方法相似.为每个句子设定一个基准模式
本文第四部分详细分析了句子筛选层和句式注意力层的处理过程以及数学建模.
4 SAN模型
SAN模型是由词嵌入层、编码层、句子筛选层、句式注意力层以及输出构成,如图2所示.
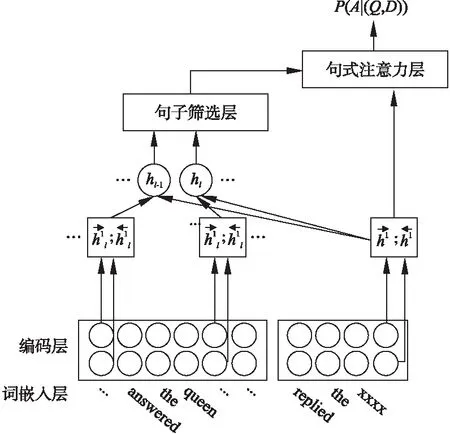
图2 SAN模型概览Fig.2 Overview of the SAN
4.1 句子筛选层
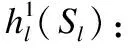
(3)
Vl=vReLu(Wlhl)
(4)
Pl(Sl|Q,D)=softmax(Vl)
(5)
如图3所示.其中[;]表示问题与文章句子在行上面的级联符号,矩阵Wl,向量v以及词嵌入所使用的矩阵是网络学习过程中获得的参数.
4.2 句式注意力层
计算每个句子Sl的注意力p(Sl|Q,D)后,需要分析与问题相关的句子信息.而对于填空型阅读理解任务,机器需要分析问题实体与文章中的实体间存在的联系.所以对于给定的句子,模型应该分析句子中的主体、客体以及两者间的联系.本文使用神经网络用向量表示句子中的主体、客体、两者的联系.一种方法是使用语义解析[22]中的依赖树[23],为句中的每个词汇标注属性,然后同问题中缺失部分的词性对比,获取问题答案.使用这种方式处理文本能提升答案的准确,但同时伴随着低效率.另一种方式则是使用词串来解析一个句子,再依据问题与文章句子词串间存在的对齐关系,获取问题答案,如图4所示.
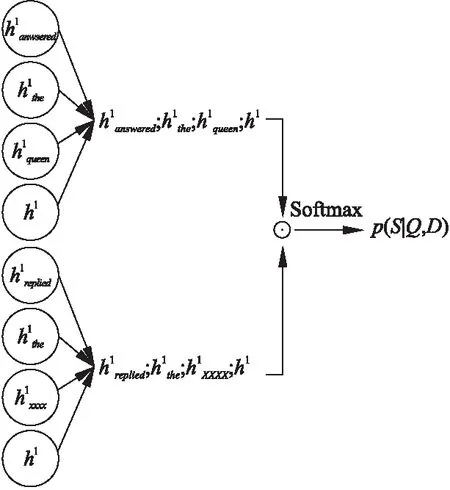
图3 句子筛选细节图Fig.3 Details of sentence-selection layer
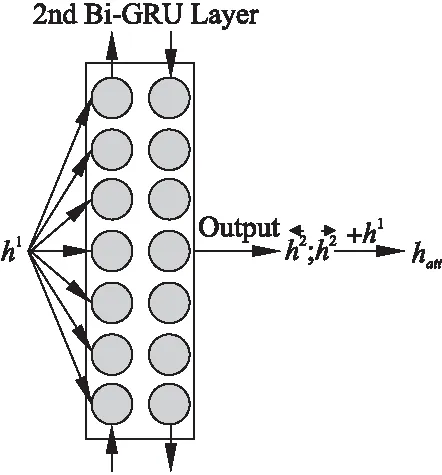
图4 句式注意力细节图Fig.4 Details of syntactical attention layer
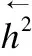
(6)
级联后的向量hatt中包含有相对于全文以及全句的前向与后向四个信息.接下来需要计算三元组注意力权重值:
αt,Sub=softmax(βSubhatt)
(7)
αt,RE=softmax(βREhatt)
(8)
αt,Obj=softmax(βObjhatt)
(9)
用具有权重值得词嵌入向量et求加权平均后抽取出句子中主体Sub、关系词RE以及客体Obj,并且用向量表示.
(10)
(11)
(12)
其中βSub,βRE,βObj为训练后得到的参数,et∈{et},et表示词嵌入层输出的词向量.
句子通过句式注意力层后,模型已经对句子的每个单词进行了标记.包含正确答案的词串上也有标记.最后,模型用词串与词串间的相似性,也就是相同文本间的对齐,获取最终答案词串:
(13)
4.3 学习方式
SAN主要使用soft-attention机制.训练采用有监督的方式,特征X为阅读理解的文章与问题,模型的输出为最终的问题答案,目标是获取准确的问题答案,即目标为数据集给出答案.这里定义最终输出的答案为y*,并且用最大似然估计来最小化模型的最终损失:
L(θ)=logpθ(y*,S|Q,D)
(14)
其中θ是模型中所包含参数的缩写.
5 实 验
5.1 数据集
实验采用CBTest数据集.CBTest数据集采用儿童读物中连续的20句话作为文章,第21句话作为问题等方式构建.根据答案的词性可分为四个子集:命名实体(NE)、公共名词(CN)、动词、介词.但是,由于后面两种答案与文本并没有十分紧密的关系,人们常常不需要读文本就可以判断出介词填空等,所以,本实验仅使用实体名的包含(NE)和常用名词(CN)两部分数据,每部分数据包含训练集、验证集和测试集三部分.表1为CBT NE/CN数据集词汇信息的统计信息.MemNN网络也是在该工作中一起提出来的.实验中,SAN网络与MemNN网络在CBTest验证集与测试集上进行准确率的对比.
5.2 训练参数
模型参数:本文使用500维预训练集词向量表840B-GloVe[24]来表示输入的问题、文章和答案.对OOV(Out-Of-Vocabulary)词,使用[-0.05,0.05]区间内的随机分布向量作为初始化词向量.词向量的长度固定为500维.小批量训练(mini-batch training)[Q,D,A]对的大小为64.当一个batch内出现长度不一致时,选取最大长度值,并且为长度不够的句子后面补上额外的标记NULL,它对应的长度是一个500维的0向量.训练迭代数(training epochs)为30,当连续3次迭代在验证集上的准确度没有提升甚至出现降低后便提前停止训练(early stopping).实验保存在验证集(dev)上准确度最高的那个模型参数,作为最优模型来对测试集进行预测.
表1 填空型阅读理解数据集的字母个数统计:CBT NE/CN(单位:个)
Table 1 Number of letters in cloze-style reading comprehension datasets:CBT NE/CN

CBT NECBT CN训练集测试集验证集训练集测试集验证集Query1087192000250012076920002500Max candidates101010101010Average candidates101010101010Average tokens433412424470448461Total Tokens5306353185
超参数:实验采用Kingma等人[25]提出的ADAM作为梯度下降优化器.其中,第一动量系数(first momentum coefficient)β_1和第二动量系数β_2分别设为0.9和0.999.初始学习率(initial learning rate)为0.001.为了加速梯度下降过程,实验时为全局每1000训练步长(training steps)设置了大小为0.95的衰减率(decay rate).同时,为了避免在CBTest数据集上测试的SAN模型发生过拟合(overfitting)的现象,本文引入dropout机制[26],在编码层的输入和输出端、控制层的输出端随机关闭20%的神经元.此外,词嵌入层的嵌入权值是随机初始化并且服从区间[-0.05,0.05]上的均匀分布.中间隐藏层的权值是一个随机初始化的正交矩阵.表2 模型每一层所含有的GRU单元个数.
表2 模型中GRU Cell使用的个数
Table 2 Number of GRU Cells used in the model

数据集词嵌入层(个)其他隐含层(个)CBTest NECBTest CN256256128128
5.3 实验步骤
为了探究SAN模型的效果,本文的实验是在Tensorflow框架[27]上实现的.实验中使用的基准模型为AOA Reader(单模型).AOA Reader是由讯飞Cui等人提出,使用了两个注意力机制挖掘文章与问题间的联系.在结构上,与SAN模型的(句子筛选注意力与句式注意力)类似.表3给出了人工测试与现有单模型在CBTest NE/CN数据集上的准确度,从表3可以看出AOA reader单模型在CBTest NE/CN数据集上均比其他模型表现优秀.实验在模型执行速度和准确率两方面上比较SAN与AOA Reader.下面先简要的介绍实验步骤.
5.3.1 SAN模型效果验证
使用参数设置中的数据,对去掉句子筛选、去掉句式注意力以及SAN模型进行训练.三个模型的网络参数均为模型学习最好的一组,即获取准确率最高、代价最小的一组参数数值,并在验证集和测试集上测试模型解决填空型机器阅读理解任务的准确率.
表3 使用CBT NE/CN 验证集与测试集实验数据的准确率
Table 3 Accuracy of using CBT NE/CN verification sets and test sets experimental data

CBTest NECBTest CN验证集测试集验证集测试集Human(context+query)-81.6%-81.6%MemNN70.4%66.6%64.2%63.0%AS Reader73.8%68.6%68.8%63.4%CAS Reader[28]74.2%69.2%68.2%65.7%GA Reader[29]74.9%69.0%69.0%63.9%Iterative Attention[30]75.2%68.6%72.1%69.2%EpiReader[31]75.3%69.7%71.5%67.4%AoA Reader(单模型)77.8%72.0%72.2%69.4%去掉句子筛选的SAN模型78.1%75.7%73.2%72.9%去掉句式注意力的SAN模型66.4%64.1%65.9%62.1%SAN网络79.2%76.3%74.7%72.8%
5.3.2 SAN模型速率验证
对于一个定义好的模型,它应该具有编码输入的问题与文章对的能力,同样需要设定很多目标促使模型能预测最终答案.AOA模型是一个以问题同文章间双向查找的方式来建模,而且AOA同其他工作相比能给出一个更加准确的结Reader模型和SAN模型、去掉句子筛选的SAN模型与去掉果.为了凸显SAN模型的优势,实验对调参后的AOA 句式注意力的SAN模型进行比较.在相同的环境(intel i7 7700k,TURBO GTX1080)下,获取平均处理数据的数量.
5.3.3 实体对齐型验证
为了获取文章中与问题最相关的句子,并对相关句子进行句式分析,本实验对SAN模型的句子筛选与句式注意力 两块进行单独训练,获取问题与相关句间的相关度.用两个句子的相关矩阵保留相关度,从而获取实体间的对齐关系.
5.4 实验分析
表3展示的是SAN同去掉句子筛选的SAN模型,或者去掉句式注意力的SAN模型,以及MemNN和AOA Reader(single model)模型输出的准确率.其中,去掉句式注意力同SAN相比较可知,对输出准确答案来说,抽取出的句子得句式结构与问题的句式结构对齐至关重要,因为两者间的相似词串和词性能为答案的寻找提供很强烈的信号.去掉文章句子筛选结构,模型设置为:用标准的注意力机制计算文章与问题的词间相似性度,该相似度即为每个词获得的权重值,并将其乘在句式注意力得到的权值上.其最终答案的准确率也有 3.7%与3.5%的提升.从表3可以看出,SAN 同其他两个比较优秀的模型相比,答案的准确率更高,同最早使用CBT NE/CN数据集的MemNN相比,SAN提升了9.7%和10.5%.同AoA Reader相比准确率提升了4.3%和3.4%.以上实验结果表明,SAN同其他使用该数据集的基准工作(AoA Reader(single model),MemNN)相比可以给出一个比较精准的答案,包括表现最好的AOA模型,在CBTest NE/CN上都有相对较高的提升.
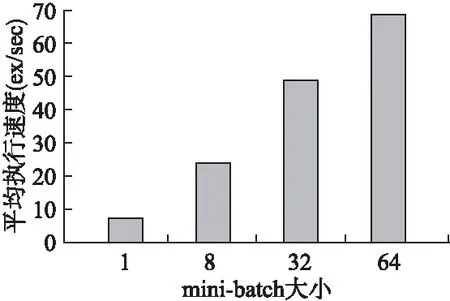
图5 调参后的SAN平均处理速度Fig.5 Post-reference SAN average processing speed
图5是在测试集上,SAN模型在不同大小的批处理(mini-batch=1,8,32,64)上获得的最终平均处理速度.

图6 与AOA模型在测试集上的速度比值Fig.6 Ratio of speed to the AOA model on the test set
图6是调参后最优模型以及除去句子筛选层,除去句式注意力层模型三种模型的处理速度与AOA模型处理速度之比.从图6可以看出SAN模型处理阅读理解任务,在速度上有明显优势.在批处理抽取为64的时候,模型处理速度仍旧为AoA Reader的快0.12倍.从SAN、去掉句式注意力的SAN模型以及去掉句子筛选的SAN模型三者的对比可以看出,相对于句式注意力,句子筛选对填空型阅读理解速度的影响更大,所以减小机器的阅读范围能明显提升机器的阅读速度.

图7 SAN对齐句子Fig.7 SAN on sentence alignment
图7展示的是SAN中问题表示与文章句子注意力标记的热力图,其中颜色越深表示其相关程度越高.输入的文章经过句子筛选层后获得与问题相关的句子.在图7中的横轴为获取的句子,纵轴为问题句.句式注意力会利用问题中已有的词串对齐给定的文章句子词串(如文章中的rose and placed,问题中的looked at的对齐),然后从描述包含答案的词串中抽取最终答案.因此,使用句式表示问题信息会更加注重与其词义相似的词汇,这样使得获取的文章单词的词性与词义更加接近答案的词性与词义,从而保证了答案的准确率.
5.5 案例分析
从图7可以看出,SAN能从输入的文章句子集中准确的找出与问题语法相同,语义相近的句子.通过句子间的结构对齐匹配出最终答案.在解决对齐问题时,SAN模型中的句子筛选层与句式注意力层是相互独立的网络结构.表4给出了一个由SAN模型最终得到的<文章句子S,问题Q,答案A>对.值得注意的是,预测目标答案时,匹配的文章句子l与问题Q间存在句式相关性但不具备语义相关,导致SAN输出一个错误答案“Snow-daughter”.所以用SAN模型解决填空型阅读理解时,答案匹配是句子句式解析后对应块间相似度匹配,句式相似度决定了最终答案的准确与否.所以,SAN模型不能动态权衡句式相关与语义相关间的重要性,从而导致回答的准确度不高.
表4 CBTest NE/CN测试集上的实验例子
Table 4 Experimental example on the test set of CBTest NE/CN

问题Q:The XXXXX built himself a hut where he always kept up a huge fire,while his sister with very few clothes on stayed outside night and day.文章句子l:The Snow-daughter herself avoided him as much as she could,and always crept into a corner as far away from him as possible.目标答案:Fire-sonSAN预测答案A:Snow-daughter
6 结 论
本文提出了一种神经网络模型SAN,在语义相关的基础上,利用句式结构对齐解决填空型阅读理解任务.SAN采用了一种问题注意机制进行句子筛选,获取与问题相关的文章句子集合,缩减搜索空间.利用句式注意力机制对句子结构进行三元组的模式设定,并对句子进行标注.利用三元组间的相似性,解决阅读理解任务中候选文章句子与问题间不对齐的问题,从而能高效地匹配问题答案.通过实验分析可知,句子筛选的方式能提升模型处理阅读理解任务的速度.句式注意力结构能细化分析句子信息,并且能联系相同标签下的词串,抽取出问题的最终答案.在未来的工作中,将对模型进行优化,以便适用于更多阅读理解场景.
