基于学习者求助行为的论坛回答者推荐研究
2019-03-13叶俊民赵丽娴罗达雄王志锋
叶俊民,赵丽娴,罗达雄,王志锋, 陈 曙
1(华中师范大学 计算机学院,武汉 430079) 2(华中师范大学 教育信息技术学院,武汉 430079)
1 引 言
以MOOC为代表的在线学习社区应用的普及,为在线学习者提供了越来越多的学习资源和学习机会,同时他们在学习过程中也会产生各种各样的问题,这时如何有效地为这些学习者及时解决这些问题,就是一个值得研究的课题.依据在线学习者的行为来推荐问题回答者则是解决该问题的一种有效途径.为此,本文提出了基于学习者行为的论坛问题回答者推荐算法.
国内外相关研究现状如下:Bhat 等人[1]揭示了Stack overflow学习社区中问题得以解决的时长现象,即大部分问题在一小时内得到解答,但有30%左右的问题回答要在一天之后才能完成,还有许多问题的回答时间超过一天;Greer 等人[2-4]研究了典型问答社区中成功为少数学习者及时推荐问题解答的回答者特征,这些人员通常在多个不同领域有着丰富的知识及兴趣;Tian[5]使用主题模型方法来预测最合适的问题回答者;Xia等人[6-8]从静态特征挖掘角度,分析了开发者和主题之间关联,以实现为特定主题推荐开发者;Mao[9]通过GitHub上开发者对特定技术术语的使用频度,分析了问答社区上标签和技术术语之间的关联关系,为Stack Overflow实现了问答专家推荐.Tian[10]分析了Stack Overflow上开发者的历史数据,通过LDA主题模型分析,发现了开发者潜在兴趣,并基于这些兴趣和协作投票机制来推荐问题回答专家;Shola O M[11]等人基于个性化标签预测高质量的问题解决者;Elalfy D[12]等人使用问题的内容和内容特征训练机器学习模型直接得到推荐的问题答案.由上述研究现状,本文认为学习者在论坛提问行为属于求助行为,而发现问题的解决速度会影响学习者对论坛的使用频度,同时依据学习者的求助行为进行论坛回答者推荐有待进一步研究.
本研究研究意义表现在:
1)心理学研究者认为[13],好的求助体验将给学习者带来信心和鼓舞,而不良的求助体验将最终使得学习者放弃在线学习,同时快速并恰当的为学习者推荐具有合适在线学习求助行为的回答者,帮助其解决论坛问题,可提高学习者的求助体验;
2)可促进对学习者在线学习行为认知研究,以更好地设计出满足学习者要求的各种个性化服务;
3)本研究有助于在线学习环境设计者改进设计并使得在线学习环境产生更大的社会价值.
2 研究框架
本研究由两步组成:第一步,识别学习者求助行为类别,以获得学习者的求助行为类别;第二步,训练论坛回答者推荐模型,将具有合适学习者求助行为类别的并与论坛问题匹配度高的论坛回答者推荐给需要帮助的学习者.
2.1 自动识别学习者求助行为类别
所谓基于学习者求助行为的论坛问题回答者推荐,是根据给定的在线学习环境中的学习者在线学习行为数据(问题输入),获得该学习者的求助行为类别,并根据其类别为其推荐合适的论坛问题回答者(问题输出).
为了自动识别学习者求助行为类别,本文采用了聚类和分类相结合的方法,以识别出学习者求助行为类别,并依据学习者的求助行为类别为其推荐合适的论坛回答者.为此,首先采用Bik-Means算法对在线学习环境中的在线学习求助行为数据进行聚类分析,获得学习者求助行为类别标签;然后,使用部分学习者求助行为数据及其类别标签训练朴素贝叶斯分类器,并利用剩余的学习者求助行为数据来验证该分类器的准确率,通过使用该分类器达到自动识别学习者求助行为类别的目的.
2.2 论坛回答者推荐的研究框架
所谓在线学习环境下论坛回答者推荐,是根据给定的在线学习环境中的学习者在论坛中发布的问题(问题输入),对该在线学习环境中的学习者输出最善于回答该问题的回答者(问题输出).
识别学习者求助行为类别的研究是基于Linda Corrin相关工作[14]开展.本文抽取了学习者行为数据的部分属性表达学习者的求助行为.通过对该学习者求助行为数据采用聚类算法处理,可得到该学习者求助行为类别标签,用此学习者求助行为数据和求助行为类别标签作为训练数据来训练朴素贝叶斯模型,从而可自动识别出新学习者求助行为的类别.在此基础上,本文可为学习者推荐合适的论坛问题回答者,具体处理流程参见图1.

图1 论坛回答者推荐处理流程Fig.1 Forum respondents recommend process
图1的相关思路如下[15]:
1)对收集到的论坛文本数据进行Embedding处理,转换为CNN模型能够处理的数据集;
2)使用卷积神经网络算法(CNN)训练论坛回答者推荐模型,在这个过程中,数据集被分为互不相交的两个集合,一个用作训练集,一个用作验证集,以验证本模型的推荐有效性;
3)得到论坛回答者推荐模型之后,可根据新学习者未被解答的论坛数据,提取该数据的特征,基于该特征使用本模型为学习者推荐合适的回答者.
3 基于学习者求助行为的论坛回答者推荐
3.1 自动识别学习者求助行为类别
识别学习者求助行为类别算法的流程可以描述如下:
1)根据学习者的论坛行为数据获取学习者的求助行为特征向量,并使用Bik-Means聚类算法处理求助行为特征向量;
2)根据学习者所属的类别获取其类别标签,与求助行为特征向量一同作为贝叶斯分类算法的训练集;
3)根据训练数据集,计算每个求助行为类别出现的概率P(rj);
4)对学习者求助行为特征向量的每个特征属性计算所有划分的条件概率;
5)根据待分类项X的特征属性,对每个求助行为类别计算P(X|rj)P(rj);
6)以具有最大P(X|rj)P(rj)值的类别作为待分类项X所属类别.1)-2)阶段执行聚类算法,3)-6)阶段执行分类算法.
自动识别学习者求助行为类别的算法首先对学习者求助行为数据进行聚类分析,获得K个聚类中心,即得到K个类别.而后依据类别标签,训练朴素贝叶斯模型,对待分类学习者进行分类处理.该算法的时间复杂度为O(NK+NV+KV),其中N是学习者求助行为数据集的规模,K是学习者求助行为类别数,V是学习者求助行为数据的特征属性数.
3.2 推荐论坛回答者
在经过识别学习者求助行为类别之后,根据我们得到的类别结论,对学习者进行论坛回答者推荐,为其推荐具有合适求助行为类别的论坛回答者.
3.2.1 卷积神经网络的基本结构
论坛回答者推荐的目的根据学习者的发帖内容,为其推荐合适的回答者.我们使用了卷积神经网络模型达到推荐论坛回答者的目的.一般的卷积神经网络由以下五个结构[17]组成.
1)输入层.输入层是作为全部卷积神经网络的输入.在本文中输入层是学习者论坛文本数据经过Embedding处理之后所得的数据.
2)卷积层.卷积层是用于做特征提取的.在一个卷积层,上一层输出的特征值被一个可学习的卷积核进行卷积,然后经由一个激励函数,该卷积层的输出特征就可以被获得.卷积层试图对神经网络进行更深入的剖析,从而获得抽象水平更高的数据特征.
3)池化层.降低矩阵的规模依靠池化层实现.对输入的特征矩阵进行压缩,一方面使特征矩阵变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征.
以便于OA学术资源的发现、获取、利用为出发点,依托目前部分院校图书馆数字资源加工室,对资源进行科学高效、规范统一的组织管理是提高OA学术资源利用效率的有效措施。考虑到军队网络安全的特殊性和军队院校图书馆OA学术资源管理实际,笔者从军网和互联网两方面就军队院校图书馆OA学术资源的组织展开论述。
4)全连接层.分类任务主要由全连接层完成.在经过卷积层、池化层和激励函数的作用之后,原始数据已经被映射到隐层特征空间.全连接层就起到将隐层特征空间中的数据表示映射到样本标记空间的作用.全连接的核心操作就是矩阵向量乘积,本质就是由一个特征空间线性变换到另一个特征空间.在CNN中,全连接(full-connected)通常出现在最后几层.
5)Softmax层.Softmax函数主要处理多分类问题.经过Softmax层后,可得到样本属于不同类别的概率.模型的预测值ypred代表的是概率最大的类,具体如公式(1)及公式(2)所示.P(Y=i|x,W,b)表示在权重矩阵为W偏置向量为b的情况下,输入向量x是第i类的概率.
ypred=argmaxiP(Y=i|x,W,b)
(1)

(2)
3.2.2 论坛回答者推荐模型
依据文献[17],本文首先将论坛文本经过Embedding处理,将提问者的问题q转化成词向量q={w1,w2,…,wn}.卷积神经网络的输入层就是该向量组成的矩阵,例如论坛发帖最大长度为n,每个文字对应的词向量长度为m,则输入矩阵的规模为n*m.池化层采用Max-Pooling的方法,之后重复上述卷积和池化的过程,搭建多层网络.经过特征学习,提取出论坛数据的特征,利用这些特征进行论坛回答者推荐.在经过卷积和池化处理之后,池化层输出通过全连接的方式连接到一个Softmax分类层并且本文使用Adam optimizer优化器来加速神经网络.除此之外,为了防止训练过程中过拟合现象的发生看,本文使用了Dropout策略.依此设计的论坛回答者推荐方法所用的训练模型如图2所示.
本模型使用 ReLU( Rectified Linear Units)函数作为神经元的激励函数,使用该激励函数可以加快训练速度,有效的减少计算开销.在训练结束之后,采用了saver函数来保存最优损失参数,从而根据学习者的发帖内容为其推荐合适的回答者,达到一次训练多次使用的目的.本文根据回答者历来回答过的问题数据,对回答者进行向量表示,即将其表示为形如

图2 论坛回答者推荐CNN训练模型Fig.2 CNN training model for forum respondents recommend
算法1.论坛回答者推荐算法
输入:学习者论坛文本数据X;待解决论坛发帖d;学习者类别数据C.
输出:被推荐的回答者u.
1.V←buildvocab(X) /*构建词汇表,将文本数据X中的词汇提取出来*/
2.C←readrecommendation () /*将以往回答者用向量表示*/
3.W←readvocab(V) /*读取上述得到的词汇表,将词汇用向量表示*/
4.X,Y←professfile(C,W) /*将每一条文本数据都转换成固定长度的向量*/
5.Repeat/*运行CNN算法*/
6. loss,acc←run(cnnmodel.loss,cnnmodel.acc)
7. run(adam optimizer)
8. until acc==1||大于指定迭代次数
9. saver(cnnmodel) /*保存最优CNN模型*/
10. data←word_to_id(d) /*将待解决论坛发帖内容d转换为向量表示*/
11. u← run(self.cnnmodel,data) /*运行最优CNN模型,得到最优推荐回答者*/
12. if u not in c[0]/*若最优推荐回答者求助行为类别不适合,在具有合适求助行为的学习者中获取匹配度最高的回答者*/
13. u0← run(self.cnnmodel based on c[0],data)
14. return u and u0/*返回被推荐的回答者*/
15. End
图3 论坛回答者推荐算法
Fig.3 Forum replier recommendation algorithm
4 实证分析
4.1 自动识别学习者求助行为类别实证分析
4.1.1 实验对象与设计
学习者求助行为的主要表现场景为:
1)学习者遇到问题时,可以在论坛中搜索相关问题或者发布帖子,以此获取问题答案;
2)在学习者遇到感兴趣的帖子时,还可以在论坛中回帖,并通过讨论来解决问题;
3)学习者还可以通过多次参加测验,由测验的反馈来获得问题的解答等.
为了验证识别学习者求助行为类别方法的有效性,本文选用了《马克思主义基本原理》在线课程中的数据进行实验,在某次课程教学活动中,学习者人数为342.我们从学习者在线学习行为数据中抽取了6个特征表征学习者的求助行为,包括学习者的发帖数量、学习者的回帖数量、学习者发帖被浏览次数、学习者发帖被回复次数、作业提交次数以及学习者成绩.
4.1.2 实验结果
1)聚类高维原始学习者求助行为数据 根据识别到的6维学习者求助行为数据,对其进行BiK-Means聚类处理,得到了四种类别标签.分析这四种类别里面的学习者求助行为数据,本文将这四类类别定义为很少参与课程活动、主动参与课程活动、被动参与课程活动、专注于课程测验.
2)自动识别学习者求助行为类别 经过第一步处理,我们得到了学习者求助行为类别标签.我们将学习者求助行为数据及其类别标签分为互不相交的两个集合:训练集和验证集.训练集中数据用于训练朴素贝叶斯分类模型,而后使用验证集中数据测试该分类模型的准确率.测试结果用五元组

表1 部分测试结果Table 1 Part of the test results
4.2 论坛回答者推荐实证分析
经过识别学习者求助行为类别,我们得到学习者的四种求助类别,研究发现这四种类别的主要区别在于论坛发帖量的不同,并且论坛发帖量和学习者绩效有正相关性,即越主动参与论坛活动的学习者越容易获得更好的学习绩效.因此,为了提高学习者解决问题的效率,使其对求助结果更为满意,从而促进其更加主动的参与课程活动,需进行论坛回答者推荐.
4.2.1 实验对象与设计
针对该在线课程中的论坛数据,首先获取学习者的发帖内容;其次,获取该贴中被赞次数最多的回答者信息.实际中我们共获取了850 条实验数据.本文的论文数据分为最佳回答者和回答者历来回答过的问题两个部分.
由4.1节的研究可知,主动参与课程活动的学习者参与论坛发帖,回帖的可能性更大,并且普遍具有更高的学习绩效.因此,为了保证学习者求助的有效性和求助结果的可靠性,若得到的被推荐回答者不属于主动参与课程活动的学习者,可在主动参与课程活动的学习者中为其匹配到最适合回答该问题的回答者,而后将以上得到的两位被推荐的回答者推荐给该需要帮助的学习者.
4.2.2 实验操作
本部分所做研究主要是基于Tensorflow库[19],该库中包含了基本的深度学习算法,包括卷积神经网络CNN和循环神经网络RNN等.此外,还需要用到数组处理numpy库、机器学习算法库sklearn以及用于绘制图像的Matplotlib库等内容.
首先将论坛文本数据进行一次划分,将其分为训练集、验证集和测试集,根据训练集可得到论坛回答者推荐模型:具体而言,本文中得到的词向量维度为64,最大序列长度为600,调用Tensorflow库中的CNN算法,设置CNN模型中的dropout参数为0.5,学习率为0.001.在训练集的准确率达到100%、验证集正确率长期不提升或者迭代次数超过1000次的情况下结束训练,而后保存最佳推荐模型,绘制出误差和准确率的变化情况.在进行模型有效性测试时,直接读取该最佳推荐模型数据,避免重复计算.通过检验测试集的准确率、召回率、F1-score以及混淆矩阵来验证该推荐模型的有效性.最后,我们使用上述最佳论坛回答者推荐模型,为学习者推荐论坛问题回答者.准确率P、召回率R和F1-score三个指标[20]相关的计算如公式(3)-公式(5)所示.
(3)
(4)
(5)
4.2.3 实验结果
1)训练并验证论坛回答者推荐模型表2表示论坛回答者推荐模型的训练及验证情况,由表2可以看出,本次训练经过300次迭代终止,此时训练集的准确率达到100%,训练集误差为0.044,误差很小.验证集准确率达到了90%,验证集误差为0.32.训练过程中训练集的准确率以及误差变化分别如图4和图5所示.
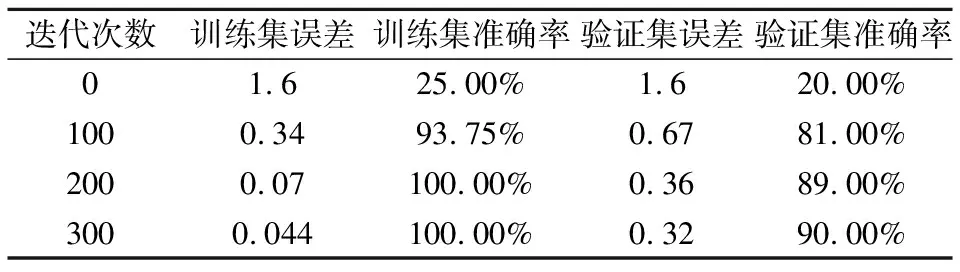
表2 训练并验证论坛回答者推荐模型准确率情况Table 2 Training and verifying the accuracy of forum respondents′ recommendation models
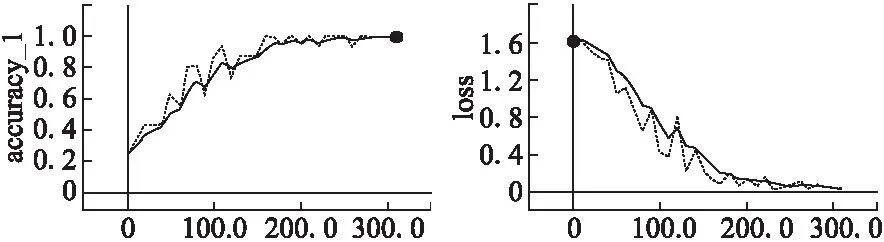
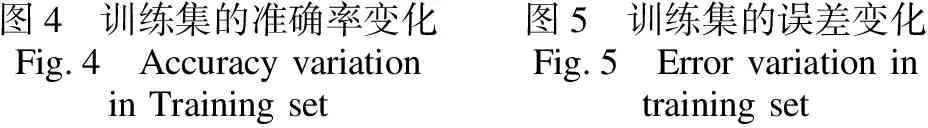
图4 训练集的准确率变化Fig.4 Accuracy variation in Training set图5 训练集的误差变化Fig.5 Error variation in training set
2)测试论坛回答者推荐模型在测试论坛回答者推荐模型时,抽取了250条数据,其中合适的问题回答者共有5人.在训练回答者推荐模型之后,采用了saver函数保存最优损失参数,在测试回答者推荐模型时,可不必再次训练回答者推荐模型.测试回答者推荐模型的有效性如表3所示.根据表3,可知论坛回答者推荐模型的平均准确率达到了90%,准确率最低的D同学也达到了77%.召回率均在75%以上,F1-score均值达到了90%,其中F1-score最低的E同学也达到了81%.因此本回答者推荐模型具有较好的推荐效果,并由图6所示的混淆矩阵(Confusion Matrix)也可以看出每位回答者的推荐准确性普遍较高,这是因为混淆矩阵中的主对角线上的数字越大,推荐的准确性就越高.例如,矩阵中第一行数据代表A同学,在其50条测试数据中,48条数据被正确分析.因此,本方法用于推荐论坛问题回答者是有效的.
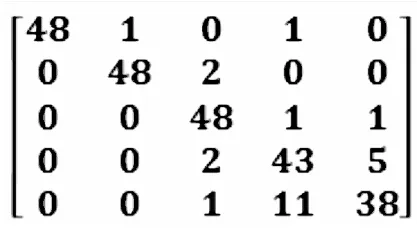
图6 混淆矩阵Fig.6 Confusion Matrix
3)推荐论坛问题回答者在得到准确率较高的论坛回答者推荐模型之后,使用该模型针对学习者新发布的帖子,推荐合适的回答者.例如,本实验中使用了一个学习者新发布的论坛问题:“绝对真理和相对真理的关系”.使用论坛回答者推荐模型之后,所得到的推荐回答者如图7所示.

图7 问题的推荐回答者实例Fig.7 An example of recommending responder
分析E同学的求助行为类别,我们发现其属于被动参与课程活动者,不属于主动参与者.因此推荐模型同时推荐了C同学,该同学在具有较高匹配度的同时,具有主动参与课程活动的特征.分析C、E这两位回答者历来回答的论坛发帖情况,我们得出该推荐确实有效的结论.同时这也证明了使用卷积神经网络(CNN)算法推荐论坛回答者的有效性.
5 相关工作对比
与文献[19]开展的研究相比,本文与该工作相同之处是:
1)在推荐研究问题中使用了深度学习;
2)采用了卷积神经网络CNN算法构建推荐模型.
与该文工作不同之处是:
1)本文做了识别学习者求助行为类别的研究.本文在推荐论坛回答者的同时,除了推荐与问题具有最高匹配度的回答者,还会在主动参与课程活动的学习者中推荐一位具有最高问题匹配度的回答者;
2)优化算法不同.该文献采用了SGD(Stochastic Gradient Descent,随机梯度下降)[21]算法加速神经网络,调节其学习速度.在本文中采用了Adam Optimizer优化器,该优化器在一般情况下能够使神经网络更快速地完成学习.
6 结束语
通过分析在线学习课程中的学习者在线学习行为数据,发现了学习者求助行为的几种不同的类别;研究了能够为学习者推荐合适的论坛问题回答者的方法,在推荐过程中,本文不仅考虑到了问题匹配度问题,还考虑到了被推荐回答者的求助行为类别情况,以使得学习者获得帮助更加便捷,求助结果更为有效.进一步的研究是根据学习者求助行为类别,结合学习者行为模型和领域知识模型等构建更有针对性的推荐模型,从而能够更有效的使用教学资源,最终共同达到提高学习者学习绩效的目的.
