结合排序学习的趣味成语生成模型
2019-03-13徐琳宏林鸿飞
徐琳宏,林鸿飞,杨 亮,徐 博
1(大连外国语大学 软件学院,辽宁 大连 116044) 2(大连理工大学 计算机系,辽宁 大连 116024)
1 引 言
成语作为中华民族悠久历史文化的一部分,一般来自于历史典故,是古代人智慧的结晶.成语大多具有丰富的历史底蕴,包含了汉语言文化的精华.在使用过程中,成语有较强的修辞效果,一个成语可以抵上多个形容词,形象生动,内涵深刻,简短精辟.成语的定义有多种,《现代汉语》中定义为:“一种相沿习用具有书面语色彩的固定短语”[1].《新华成语词典》中定义为:“相沿习用的固定词组或短语,能独立表意,形式短小,一般为四字格式”[2].无论哪种定义,都可以看出成语是人们长期以来习用的、简洁精辟的定型词组或短句,有固定的结构形式和固定的用法.
趣味成语就是将原有成语本身经单字和多字替换后的成语应用于一个新的场景,产生幽默的效果.因其具有趣味性,常常引人发笑和深思,被广泛接受.有时,仅仅一字的差异能出现多种理解和含义,也是汉语言博大精深所在.如,“默默无闻”中的“闻”经替换后变为“默默无蚊”,指没有蚊子的嗡嗡声,周围很安静,体现了一定幽默风趣的色彩.这种谐音的趣味成语可以用于广告、讽刺或幽默,能生动地表现产品的特色,有效地影响消费者.
2 相关工作
本文研究目标是以现代成语为基础,自动生成趣味成语,使其在某一固定场景中产生幽默的效果,而趣味成语大多是通过谐音替换得到,很多成语具有谐音双关的含义.因此,下面分别从幽默生成、双关语和成语三个方面介绍相关的研究工作.
近些年国内外有很多幽默生成方面的研究,2012年,Igor Labutov等人基于SSTH理论做幽默语句生成的研究,采用人工打分的方式评测生成语句的效果[3].2013年,Alessandro Valitutti等人通过词语替换,生成幽默文本,采用人工评估的方式评估幽默等级[4].国内研究者也在幽默研究方面进行了一定的探讨.2015年张冬瑜等人构建了情感隐喻语料库,这为幽默的识别提供了可以借鉴的方法[5].2016年林鸿飞等人回顾了幽默研究的发展历史,详细阐述了幽默计算中的多种基本理论和应用,对于谐音幽默的处理也给出了相应的讨论[6].
双关语作为幽默的一个重要分支,近些年也有很多的相关研究工作.2011年,Valitutti等又提出一种计算幽默程度的方法,评估生成的谐音双关语.首先利用音素距离、音节距离、单词距离和熟悉用语等多个特征生成谐音双关语,最后采用人工评估的方法检验生成系统的效果[7].2012年,Pawel Dybala等人生成日文的双关语,通过高频词汇统计的方式过滤候选词汇,降低双关语生成系统的时间代价.Valitutti等人也在2013年通过对普通文本的替换产生谐音幽默的句子,替换过程中主要考虑单词的声音相似性、拼写和可替换性三个特征,使幽默生成变为词语选择问题,最后通过人工打分的方式评估谐音文本的幽默性[3].
成语是中华传统文化的璀璨明珠,语言学方面关于成语典故、结构和释义有许多研究工作.曾小兵等提出成语的稳定度高于习语,将成语定为语言中的高稳态的部分[8].徐耀民等认为成语的整体意义同字面意义往往不一致,使人产生联想,因而运用起来容易收到生动、形象、耐人寻味和言简意赅的效果[9].倪宝元指出由于表达需要而临时产生的成语语素变换的形式成为套式.语言的演变依据“从俗、从简和义明”等规范[10].成语大多是约定俗成的四字结构,在汉语书面或者日常会话中经常出现,特别是在文学作品中尤为频繁,而在新闻领域中成语的使用频率相对较低[11].以上是语言学方面对成语的部分研究.因为成语具有字数少,含义丰富的特点,机器理解困难较大,所以自然语言处理中关于成语方面的研究工作较少.冉婕等将成语的典故信息以本体的方式存储,分别从类、子类、属性、个体及关系几个方面进行了详细分析,为成语典故相关知识的查询奠定基础[12].杨雪松等提出了一种基于成语典故本体的信息检索模型,以问题模式和答案模式为基础,提高成语的语义检索效率[13].以上是国内外幽默生成、双关语和成语方面的研究进展,从成语的字形及语义角度出发,生成幽默成语的研究目前还很少见.
本文在大家使用频率较高的成语基础上,生成谐音趣味成语,主要的贡献如下:1.根据一定的语音替换策略,生成候选成语集合,并提取成语中包含的字形和幽默等特征;2.将成语的生成问题转化为查询检索问题,基于排序学习算法生成趣味成语;3.在多个维度中采用人工评估和机器评估相结合的方式,评测趣味成语的质量.
3 趣味成语特征集
趣味成语的生成首先是利用丰富的成语资源,在一定的语音替换策略基础上,抽取谐音成语集合.然后提取成语集合中每条成语的特征集,融合到排序学习的算法中,生成幽默性较强的趣味成语.最终建立一个多场景自适应的趣味成语生成模型,该模型的基本流程如图1所示.
输入层包含查询的关键字和场景词两部分,其中查询关键字是生成的趣味成语中包含的汉字,场景词是指趣味成语的应用场景.成语的幽默程度大多与应用的场景密切相关,如趣味成语“终身无汗”,查询的关键字为“汗”,生成的成语本身幽默性不强,但如果和场景词“空调”关联时,很容易理解,“无汗”是强调空调的制冷效果,“终身”夸张了空调的功能,两者结合呈现出一定的幽默色彩.可见,幽默特性通过与固定的场景词关联体现出来.因此本模型的输入为查询关键字和场景词两部分.以语音替换策略为基础,根据输入的查询关键字在现代成语语料库中生成候选成语集合.然后提取每条候选成语的特征集,利用排序学习算法,为候选成语集排序,输出排名靠前的趣味成语以及它与场景词关联的幽默程度.生成和检索算法的流程如下:
input={key,Q}//key为查询关键字,Q为场景词idioms=语音匹配(key)//idioms为候选成语集合
for idiom in idioms:
FVector=提取特征_11(idiom)
FMatrix=FMatrix.add(FVector)
indices=LambdaMart(FMatrix)
根据上述的流程可知,模型的输入为查询关键字key,输出是若干成语,关键问题是如何将生成的成语按其与场景词Q的相关度和幽默程度排序.这与信息检索的问题很相似,其中查询关键字相当于检索中用户输入的查询条件,场景词为查询的扩展部分,每个候选成语可以看作一个查询返回的文档,提取成语中的语义和幽默特征矩阵FMatrix,融入到排序学习的算法中,训练排序模型,返回候选成语集合中成语幽默程度的排序indices.这样可以把一个幽默成语的生成问题转化为信息检索问题,进而利用检索的相关技术生成和评估幽默成语.信息检索的核心问题是排序,趣味成语的核心问题也是如何将候选成语按其幽默程度排序.因此,本文在提取成语特征时,既考虑候选成语与查询的相关性,也考虑成语本身的重要程度和幽默特性.
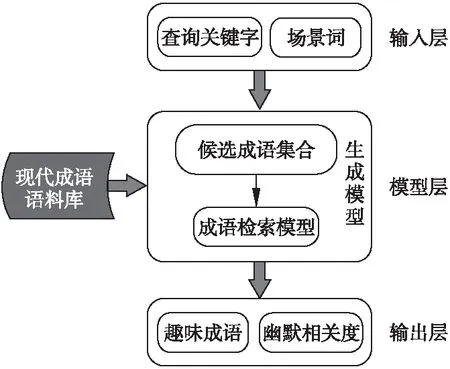
图1 趣味成语生成模型Fig.1 Model of interesting idioms generation
为了全方位、多层次的体现成语的查询相关度和幽默程度,本文在候选成语集合中提取语音、幽默、语义、情感和形态五个维度的特性,共11个特征.将上述特征融入到排序学习算法中,输出每个候选成语的重要性.因此,图1中的成语生成型可以进一步细化为特征集提取和检索模型两部分,其中提取的特征集如图2所示.
首先,为候选成语集中的每条成语计算五个维度的特征集合,将生成的特征矩阵作为排序算法的输入,经排序算法训练和学习后,使趣味性较强的成语尽量排名靠前,最后利用信息检索领域常见的平均准确率(MAP)和前N个结果的准确率(P@N)等指标评估算法的有效性.由图2可知,选取特征的质量直接影响排序算法的输出结果,它们是成语选择的重要原始数据,下面将详细介绍该模型的五个维度的特征.
3.1 语音替换策略
利用给定的查询字在成语集合中查找发音相同和相似的成语,可以生成候选的成语集合.语音替换策略是指在进行上述语音替换时的原则,替换策略宽松,损失生成成语的语音特性,且生成的候选成语数量庞大,会增加趣味成语的挑选难度.反之,替换策略过于严格,生成的成语数量较少,很多幽默性强的趣味成语不能进入候选成语集.为保证候选成语集合的数量适中,本文选择的替换策略是“严格匹配声母和韵母,宽松匹配声调”的原则.即替换字与查询字的声母和韵母必须完全相同,而声调可以不同.其中声母23个,韵母35个.需要注意的是这里的韵母是严格区分单韵母、双韵母、三韵母和组合韵母.例如,韵母“àn”和组合韵母“iàn”属于发音不同.
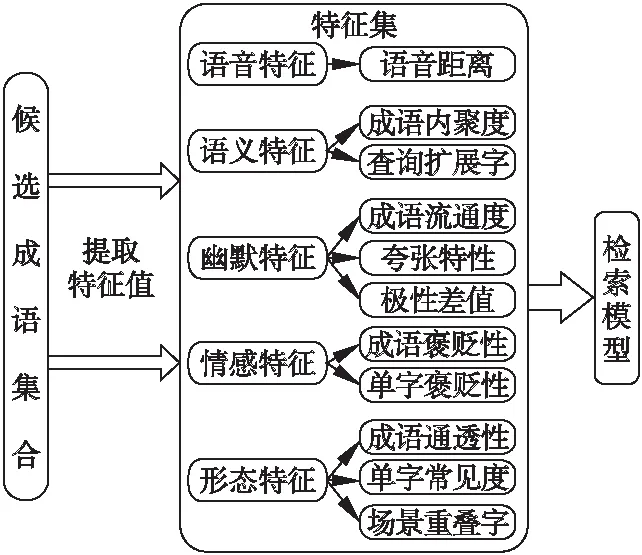
图2 成语特征集Fig.2 Features of idioms
语音距离:查询字与被替换字发音相同还是相似.因为语音替换策略中放宽了声调的匹配,发音完全相同比发音相似语音距离小,读起来更流畅,语感更强.语感是一种综合的语言直觉能力.它包括对语音、语法、语义和语用等许多方面的敏感的直觉能力.虽然,人与人之间的语感有差别,但每种语言都存在共同的语感称为“共同语感”[14].语音距离近,语感强,则该成语更可能语义通顺,趣味性强.
3.2 语义特征
成语作为一个语义单元,不像语句和篇章可以包含更多的词汇和汉字,体现更大的信息量.而成语大多只包含四个汉字,却能够体现较为丰富和生动的语义.为了让机器能更全面的了解成语的丰富含义,需要在四个汉字的字面含义基础上,多层次多角度的扩展语义.本文从两个方向扩展关联的语义:一个是向外扩展,通过大规模语料完成,另一个是向内扩展,将成语中四个汉字拆分计算.因此我们的语义特征包含查询扩展字和成语内聚度两个方面.
3.2.1 查询扩展字
该特征首先通过大规模语料扩展查询场景词,将扩展后的关键字与成语匹配.匹配度越高,说明候选成语与查询的关联越大,语义上也就越相关.本文选择2G的微博语料做查询扩展,因为微博语料相对于新闻等语料更生活化、也更贴近人们日常的表达方式.一个用户发表的一段微博一般较短,可以将其看作一个文档,计算查询扩展词出现的文档编号,则该文档中的所有词汇都可以作为查询词的共现词汇,选择排名靠前的共现词汇作为该查询的扩展词.计算的公式如式(1):
(1)
其中,qk代表第k个查询的场景词,Corrence函数表示第i个文档中场景词qk与词汇wj的共现次数.因此,Cj代表语料中第j个词汇与场景词qk共现的频率.当前场景词qk与所有单词的共现矩阵为(C1,C2,…,Cm-1,Cm),选择其中共现频率较高的词汇作为场景词qk的查询扩展词,最后在qk的候选成语中匹配是否存在查询扩展词,将其作为查询扩展词的特征值.
3.2.2 成语内聚度
成语内聚度是指成语中每个汉字之间结合的紧密程度.结合越紧密,内聚度越高,说明该成语中每个汉字经常搭配使用,表达含义更容易被人们理解.四字格成语一般为二二结构[15],如“千山万水”、“画蛇添足”等,因此本文计算的成语内聚程度并不是将成语中每两个汉字组合计算,而是分为前后两部分,即先计算前两个字的内聚度,再计算后两个,最后将两者加和,内聚度是通过汉字的Ngram值表示.见公式(2).
(2)
其中,Coh(idiomi)为第i个成语的内聚度,由前后两部分相加得到.ngram函数计算相邻两个汉字的ngram值,本文集成KenLM Toolkit[22]工具包,在1G的中文维基百科语料中按字训练Ngram语言模型.
3.3 幽默特征
幽默具有 “戏谑”的特征,因此“有趣,可笑”可以作为判断幽默的广义标准[6].趣味成语中“趣”就是指具有幽默的含义,而幽默的表现形式多种多样.本文的幽默特性包含夸张特性、成语流通度和极性差值三个方面.
3.3.1 夸张特性
幽默有时与一定的修辞手法关联,例如,国内外很多学者认为夸张常常有幽默的效果[16],作为情绪的宣泄方式,夸张、反语都能达到幽默的作用[17].夸张是作者把描述事物的本质特征极力地夸大或缩小,从而使话语产生幽默效果.而夸张的表现手法是多种多样的,归纳起来就是利用多种语言资源,增强或降低事物的某些方面.包含语势和语焦两个方向.语势 可以扩大或缩小,语焦可以锐化或柔化[18].语势最经常使用的是数量上的夸张,如经典夸张表达“白发三千丈”[19].根据以上语言学中关于夸张的理论,我们提取成语中的数词及表示数量规模的量词等表示夸张特性.
3.3.2 成语流通度
“流通度” 是一种语言事实在社会交际中的流行通用的程度.词汇流行通用程度高,表明人们的熟悉程度高,也就是更多的人能够理解词汇的含义.幽默言语是说话者在某一特定情景下说出来的,听者利用自己的语言知识和常识去理解,在这种人的交际与认知中获取.如果一个成语的流通度较低,含义比较晦涩难懂,就很难在理解语义的基础上产生幽默.为了客观公正的在大规模语料中获取成语的流通度,我们利用百度搜索引擎,将原始成语作为查询关键字,获取该成语返回的相关结果个数,然后对生成流通度向量做归一化处理,得到成语对应的流通度数值.流通度数值越高,说明该成语在生活中越常见,其含义也被大多数人熟知,进而其幽默的含义也更容易被理解.反之,如果一个成语流通度较低,则说明大部分人对它表达的含义或者成语的典故出处不太了解,这样的成语生成候选成语后,即使其中包含一定的幽默含义,也很难被人解析和认知.
3.3.3 极性差值
极性差值是指计算查询字与被替换字之间的极性差值.因为幽默言语大多来自于交际过程中最大关联与最佳关联之间意义的反差[20],语义信息有限的成语中,情感极性的差值从一个侧面体现了这种反差,造成一种意料之外的效果.本文计算极性差值的方法是:首先,在大连理工大学的情感词汇本体[21]基础上,根据每个字出现在褒贬义词汇中的次数计算单个汉字的褒贬义;然后根据汉字的褒贬义,计算替换前后成语的褒贬义变化,计算公式如式(3):
polarDiff(idiomi)=polar(zori)-polar(znew)
(3)
其中,zori表示成语中的原始字,znew表示替换zori的查询字.polarDiff(idiomi)代表替换前后成语中汉字的极性变化,它的绝对值越高说明替换前后情感的反差越大,则越可能含有幽默色彩.
3.4 情感特征
成语和习语中通常包含丰富的情感信息,对情感识别作用较大[22].从情感的角度出发,趣味成语分为两种类型,大部分是褒义成语转化而来,少部分成语原始是贬义成语,但替换后不再具有贬义色彩.本文的情感特征包含成语褒贬性和单字褒贬性,分别针对两种类型的趣味成语.成语褒贬性主要处理大部分趣味成语是褒义成语转化而来的情况,而单字褒贬性主要处理少部分成语的去贬义化问题.
3.4.1 成语褒贬性
本文使用的成语来源于《成语大词典》[23],词典中具有情感极性的成语标注为褒义、贬义.我们手工录入词典中的情感标注,作为成语褒贬性的特征值.贬义值为1,中性值为2,褒义为3,需要说明的是词典中明确标注了具有褒义和贬义的词语,未标注褒贬极性的成语划分到中性类别中.从情感极性的角度看,由褒义成语替换成的候选成语成为趣味成语的概率更大.
3.4.2 单字褒贬性
单字褒贬性是判断候选成语中是否包含褒义字.包含褒义字的成语其贬义被去除的概率加大,即更可能为去贬义化的成语.这主要是针对一些贬义成语具有趣味性,它们通常是通过单字替换后,原来的贬义倾向性消失的现象.例如,“口蜜腹健”,原始成语中的“剑”字被“健”替换后,原始的贬义消失,带有一定褒义色彩.
3.5 形态特征
汉字是象形文字发展而来,能通过字形表达丰富的语义,因此外在形态包含了语义表示的重要信息.本文选择的形态特征包括成语通透性、单字常见度和场景重叠字.
3.5.1 成语通透性
成语的通透性是将组成成语的每个汉字的通透性叠加.1999年,曾捷英等提出汉字空间通透性的概念,它是衡量汉字笔画之间离散程度的可量化指标,汉字空间的通透性和笔画间的离散程度成正比[24].因此,可以将笔画数作为衡量通透性的一个标准.现代汉字学把笔画看作是“构成汉字字形的最小单位”[25].目前广泛采用的笔画是1965年文化部和中国文字改革委员会颁布了《印刷通用汉字字形表》.笔画数的多少标志着字的繁简[26].曹傳詠等[27]也肯定了汉字识别中的笔画数效应.因此,本文中成语的通透性通过构成成语的每个汉字笔画数的加和来计算.通透性越好,说明成语被人们识别和理解的概率越大,也就更可能成为趣味成语.
3.5.2 单字常见度
汉字的常见度反映了汉字在人们生活中的使用频率.越常见的汉字,其语义越易被大多数人理解,在充分理解语义的前提下,也就越容易理解其中的幽默等含义.本文的常用汉字是选择国家语委汉字处1988年制定的《现代汉语常用字表》中的常用汉字.判断成语的汉字是否为常用字,计算公式见公式(4).
(4)
其中,T(zj)表示汉字zj是否为常见字,是值为1,否则为0.T(idiomi)表示成语i中汉字的常见度,如果候选成语中除查询字外每个汉字都为常见字,值为1,否则值为0.
3.5.3 场景重叠字
场景重叠字特征是判断生成的候选成语中是否包含场景词中汉字.每个查询字都配有一个场景词,因为成语的幽默程度大多与应用的场景密切相关,在具体场景下才能体现幽默.如果候选成语与场景词高度相关,则产生幽默的可能性会变大.例如,趣味成语“闻‘机’起舞”中的“舞”与场景词“跳舞机”重叠,两者的语义相近.反之,如果候选成语与指定的场景语义距离较远,很难产生幽默的联想,那么成为趣味成语的概率会变小.场景重叠字特征计算候选成语有多少个字与场景词重叠,字数越多,两者语义越相近.
4 趣味成语检索模型
依据语音替换模板和查询字,生成了候选成语集,通常一个查询字可以生成几百甚至几千个候选成语,这些成语中哪些与规定的场景词更相关,哪些更具有幽默特性是下一步需要解决的问题.即我们需要根据选择的5大类特征,将生成的多个候选成语排名,使语义更相关、幽默性更高的成语排名靠前.这与信息检索的问题非常相似,在信息检索中用户搜索一个查询关键字,可能返回多个相关的文档,提取特征后通过合适的排序学习算法,将相关度大的文档排在前面.信息检索的核心问题是排序,就是把用户最需要的信息排在返回列表的最前面.而趣味成语的检索模型也是要解决排序问题,将趣味性强的成语排在候选成语集的最前面.因此,本文采用信息检索领域应用广泛的排序学习算法和相关评测方法,实现趣味成语的检索模型.该检索模型的主要结构如图3所示.

图3 趣味成语的检索模型Fig.3 Model of interesting idioms retrieval
首先,在已标注的训练集中提取5个维度的11个特征值,使用排序学习算法训练,利用开发集调整参数后,得到效果较好的排序模型.然后利用排序模型分别排序已标注的测试数据和未标注的用户需求两个数据集.最后评估阶段,已标注的数据采用机器评估,未标注的数据采用人工评估,以更全面、客观地评价趣味成语的生成质量.
4.1 检索模型
排序学习的思想是将排序问题转化为机器学习问题,利用机器学习的相关方法,以排序特征为依据构建合适的排序模型.它的主要目标是利用排序函数计算文档和查询的相关度,然后根据相关度进行排序.参照信息检索的定义,本文的趣味成语检索模型任务定义为:对于给定的候选成语集合C,其中每个候选成语表示为
排序学习中列表级[28]方法因为不再将排序问题直接转化为分类问题,而是对整个候选文档列表进行优化,是目前研究的重点.本文采用列表级方法中效果较好,使用范围较广的LambdaMart算法训练模型,以位置信息敏感的MAP为评价准则,评估候选成语的排序效果.

(5)
其中,I表示某查询下的所有候选对象.LambdaMart方法在众多检索任务中都获得了较好的效果.
4.2 评估方法
信息检索的评价指标很多,如F值、E值、AP值、MAP、P@K、NDCG和MRR等.为了客观公正地评估趣味成语的质量,本文选择通用的MAP和P@K作为评价指标.AP(Average Precision)值是计算单个查询中每篇相关文档的平均准确率.而MAP(Mean average Precision)是计算集合中多个查询的平均AP值,具体方法如式(6).
(6)
其中,Pi(r)指查全率为r时的平均查准率,N为查询的个数.MAP是反映全部相关文档性能的指标,相关文档排名越高,MAP的值越高.
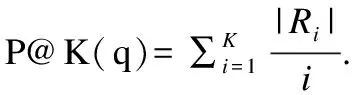
5 实验结果
生成的候选成语经检索模型排序后,生成趣味成语集合.采用机器评估和人工评估相结合的方法评估生成趣味成语的质量.本节主要介绍使用的语料、实验方案及结果.
5.1 实验数据集
成语生成模型中需要成语语料库,现代汉语中到底有多少条成语,很难有一个具体、明确的数字[30].因为辞书常常设有主条、副条或主条、附见条,如果这种单位也被视为成语,则成语的总数 可能达到两三万条,如果将其排除在外,那么成语的总数可能为 10000 条左右[31].四字格是成语最典型的格式,数量也是最多的,体现了汉民族追求和谐、崇尚对偶的审美观.据许肇本的统计,在不下万条的成语中,四字格约占 97%[32].因此,本文采用商务印书馆的《现代成语大词典》为基本的成语语料库,选择四字格成语10604个,其中褒义成语1981个,贬义成语1840,中性成语6783.趣味成语的已标注数据集是从互联网上收集,包含72个查询,82个趣味成语,查询涉及生活用品、电器、保健品和住房等多个领域.72个查询中12个作为测试集,50个训练集,10个开发集.除了这些已标注的数据集,我们还准备了25个用户查询构成未标注的数据集,利用人工评估的方法检测趣味成语的生成质量.为了全面地评测该模型的质量,上述25个用户查询来源于国家统计局2013年发布的《居民消费支出分类》表,从衣、食、住、用和行5个大类中,每个类别分别随机选择5个产品作为查询字的场景词,总计25个查询.
5.2 实验结果及分析
本文主要完成两大类实验:已标注数据集上的机器评估和未标注数据集上的人工评估.排序算法采用LambdaMart,使用开发集调整参数,将排序模型应用到上述两类测试集,分别采用MAP和P@K两种评价指标.
5.2.1 机器评估结果
72个查询中12个作为测试集,采用交叉验证的方式,单独使用各维特征及所有特征叠加的实验结果如表1所示.
表1 各维特征对MAP值的影响
Table 1 Features′ impaction in MAP
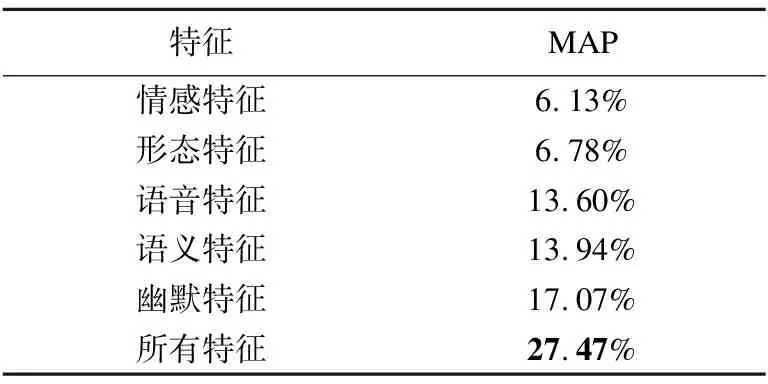
特征MAP情感特征6.13%形态特征6.78%语音特征13.60%语义特征13.94%幽默特征17.07%所有特征27.47%
从表1可以看出,将5个维度的11个特征都加入到模型中,效果最好,MAP值达到27.47%.如果一个查询只有一个趣味成语,则该趣味成语平均排名在3到4名左右.在排序模型中单独使用各维特征,幽默特征作用最大,MAP值为17.07%,而情感特征的作用最小,只有6.13%.这是因为情感特征主要依据成语的褒贬性来区分,而10604个成语集合中具有明显褒贬义的成语数量较少,只有3821个,因此影响范围不大.幽默特征的作用最大,因为衡量趣味成语好坏的关键指标是趣味性,即幽默.为了细化幽默特征的作用,本文分别在所有特征中删除每个幽默特性,以MAP值的提升程度表示各个幽默特性的效果,结果如表2所示.
由表2可以看出,三个幽默特性中极性差值作用最小,夸张特性作用最大.在特征集中加入夸张特性,整体的MAP值能提高7.37%.可见,夸张是幽默的一种重要体现形式,能够帮助识别部分趣味成语中的幽默效果.成语流通度特性能提高6.54%,说明人们越熟悉的成语替换后越容易产生幽默色彩.极性差值的提升幅度为2.73%,与其他两个特性比效果较小,这是因为字的褒贬义本身与其在实际上下文中的含义可能有一定的误差.
表2 幽默特性对MAP值的影响
Table 2 Humor features′impaction in MAP

特征MAP提升幅度所有特征-极性差值24.74%2.73%所有特征-成语流通度20.93%6.54%所有特征-夸张特性20.10%7.37%
5.2.2 人工评估结果
考虑到目前机器对幽默等隐式情感的理解不足,在高级情感的鉴别和解析中人的感受更为准确和具体.因此,本文针对25个查询字及场景词采用人工评估的方法,进一步评价趣味成语生成模型的效果.每个查询生成的候选成语数量庞大,对每一条候选成语进行人工评估,人力成本较大.因此,对于每个查询,我们选择排名在前10的成语人工评估,每名评测员完成250个成语的评估工作.评测员为每条成语打分,分为“不相关”、“一般相关”和“非常相关”.“不相关”的成语还需要细化不相关的原因,如语义不通,或者与场景词关联度较小等,这主要是为后续改进模型提供依据.“非常相关”是指成语趣味性较强,与查询场景比较贴合的成语.“一般相关”是指与查询场景语义相关,但趣味性稍弱的成语.人工评估的结果如表3所示.
表3 人工评估的P@10结果
Table 3 P@10 values of artificial assessment

评测标准平均P1P2P3P4P5非常相关34%27%30%42%34%39%相关60%55%69%63%56%57%
表3中给出了趣味成语p@10的评测结果,“相关”是指“非常相关”和“一般相关”的叠加.从结果可以看出,排名靠前的10个成语中平均有6个成语是相关的,其中有3个是非常相关的.这从人工的角度验证了趣味成语生成模型的效果,基本能够满足大部分查询的实际需求.此外,5人评测组中,组员评分的方差为0.003,方差较小,也说明评测员的评测结果一致性较好,结果的可靠程度较高.25个查询分别来自衣、食、住、用和行5大类别,各类别趣味成语的生成质量如图4所示.

图4 各个类别人工评估的p@10值Fig.4 P@10 values of each category through artificial assessment
由图4可以看出,食品类和服饰类查询生成趣味成语的质量较高,相关成语的平均值为68%,而交通出行类查询的生成质量最低,非常相关的成语15%,相关成语也只有46%.这是因为成语多来源于古代的典故,而出行类的查询场景词多为出租车和飞机等现代词汇,两者的语义相关度较小,所以趣味成语的生成质量最低.
表4 部分趣味成语
Table 4 Examples of facetious idioms

查询字场景词趣味成语羽羽绒服“羽”众不同无“羽”伦比巾围巾情不自“巾”“巾巾”有味鞋皮鞋一“鞋”千里齐心“鞋”力麦小麦一“麦”相传含情“麦麦”甜巧克力巧夺“甜”工“甜”下第一
表4给出了生成的部分趣味成语,从结果可以看出大部分成语趣味性较强,与场景词的语义相关度较大,趣味成语的质量较好.
6 结论及不足
本文依据语音替换规则生成候选成语集合,从中提取语音、幽默、语义、情感和形态五个维度11个特征,并以此为基础,利用排序学习的相关算法,从候选成语集合中检索趣味成语,进而构建趣味成语的生成模型.该模型将成语生成问题映射到信息检索领域,以查询及相关反馈的技术解决生成问题.经机器和人工的双重评估,实验结果表明五个维度的特征能够细致刻画趣味成语,区分度较好,生成质量较高.
但我们的研究工作也存在一些不足,如很多近现代出现的查询词与古代成语的相关度较低,生成质量有待提高.另一方面,能否理解幽默与人类的常识高度相关,而这部分幽默特征表示困难,还需要进一步加强.
