基于多示例学习的化学物致病关系抽取
2019-02-15冯靖焜杨志豪罗凌林鸿飞王健
冯靖焜,杨志豪,罗凌,林鸿飞,王健
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
随着生物医学领域文献数目的迅速增长,大量的生物医学知识蕴含其中。调查表明,化学物质(药物)、疾病以及二者间的关系是PubMed用户最常搜索的主题之一[1-2],这反映出化学物(药物)-疾病关系(Chemical-disease relation,CDR)在生物医学和医疗健康等领域的重要意义[3]。例如,药物具有两重性,一方面可以防病治病,促进患者生理机能的恢复,另一方面也可能引起危害人体的药物不良反应,药物副作用(adverse drug reaction,ADR)成为困扰病人、医疗服务提供者、监管机构和药品制造商的一个非常严重的问题,给社会、家庭造成沉重的经济负担。据有关资料评估,中国每年约有5 000万人住院,其中至少250万人(20%)是因ADR住院,50万人是严重的ADR,每年死亡约19万人,从而增加医药费近40亿元。近年来,人们越来越注重从非结构化文本中提取结构化的CDR,一些通过人工标注而构建的生物医学数据库如CTD(Comparative Toxicogenomics Database)应运而生[4]。然而,生物医学文献迅速增长的需求,与需要耗费大量人力、物力而且耗时的人工标注之间存在矛盾。因此,利用文本挖掘技术从生物医学文献中自动抽取CDR信息对于生物医学研究而言具有重要意义。
BioCreative评测是国际上用于生物自然语言处理研究的重要评测[5]。其中,化学物致病(Chemical-induced disease,CID)关系抽取是BioCreative V评测任务中有关关系抽取的一项子任务[3]。该任务以来自PubMed文章的标题和摘要为输入,要求参加评测的系统从输入文本中抽取并返回具有CID关系的化学物-疾病实体对。与先前的句子级别的生物关系抽取任务(如蛋白质交互关系抽取,药物关系抽取等任务[6-7])不同的是,CDR抽取任务是文档级别的关系抽取任务,即对出现的CID关系在文档级别进行标注,而不指明关系所在的具体句子。图1展示了CDR数据集中一篇文档标注示例,首先给出了该文档相应的PubMed编码以及题目和摘要,然后人工标注出了化学物、疾病实体以及其相应的医学主题词概念标识符(Medical Subject Headings Concept Identifiers,MeSH®IDs)[3]。从图1可以看到文档级别的关系抽取,不仅有句子内的CID关系,还存在跨句子的CID关系(例如“AMNS-FSGS”)。

Fig.1 CDR labeling example图1 CDR标注示例
目前在CDR任务上,很多研究者将CID关系分成句内和句间两部分,然后对这两部分分别训练模型,作出判断后返回融合后的结果。例如,Xu等人使用丰富的基于知识的特征,分别训练了文档级和句子级的支持向量机(SVM)分类器[8]。Gu等人则使用词法、句法等特征,分别训练了文档级的最大熵(ME)模型和句子级的卷积神经网络(CNN)模型,并运用了规则预处理和后处理来进一步提高关系抽取性能[9]。在对关系示例进行构造时,大部分研究者假设:若一篇文档中两个实体存在CID关系,那么该文档中任何包含这两个实体的句子均被认为是表达了这种关系[9-10]。此外,有少部分研究者直接忽略了句间部分的CID关系[11]。然而,基于上述假设构造的关系示例会引入大量噪音,这是因为并不是所有提及实体对的句子均表示了实体对间的关系。
从图2可以看出,尽管“hypertensive”与“dobutamine”间存在CID关系,但是仅a句表达了这种关系。若根据上述提到的假设,将b句作为正例参与分类器的训练,那么这种噪音会干扰分类器,导致其性能下降。为了缓解这个问题,本文借鉴多示例学习的思想来进行文档级别的化学物致病关系抽取。
多示例学习[12]思想由Dietterich等人首次提出,并率先被用于预测药物分子活性。多示例学习的假设是将样本集看作是一个包含了很多包的集合,每一个包中包含了若干数量的示例,每个包中的示例数量是任意的。当且仅当一个包中最少有一个示例为正时,这个包是正包;反之,是负包。近年来,多示例学习框架也被广泛应用在基于弱监督的关系抽取方法中[13-16]。

Fg.2 Example with noise图2 包含噪音的示例
针对现存CID关系抽取方法构建训练样本正负例引入大量噪声的问题,本文提出了一种基于多示例学习卷积神经网络(multi-instance convolutional neural network,MICNN)的方法来抽取文档级别的化学物致病关系。将每个样本(一对候选化学物-疾病实体对)看成是一个包,候选实体对所在文档中的共现句子被当作它的示例。对于跨句子的实体对,则将两个实体所在句以及介于二者间的句子合并作为它的一个示例,然后使用MICNN模型对每个包进行分类,预测是否存在CID关系。实验结果表明,相比其他现有方法,MICNN仅使用了词向量特征、位置特征和实体特征三种基本特征,就在BioCreative V CDR任务提供的测试集取得很好的性能表现,F值达到了62.7%。
1 基于MICNN的CID关系抽取方法
本文方法的流程图如图3所示主要包括三个阶段。在预处理阶段,首先根据CDR语料的实体标注,为每对候选化学物-疾病实体对构造对应的实体共现句集合(即多示例学习中的包),然后使用生物主题词表(medical subject headings,MeSH)制定规则进行过滤。在关系抽取阶段,使用MICNN模型进行文档级的CID关系抽取。后处理阶段,使用简单而有效的启发式规则来进一步提高关系抽取性能。下面将对每个阶段进行细节描述。
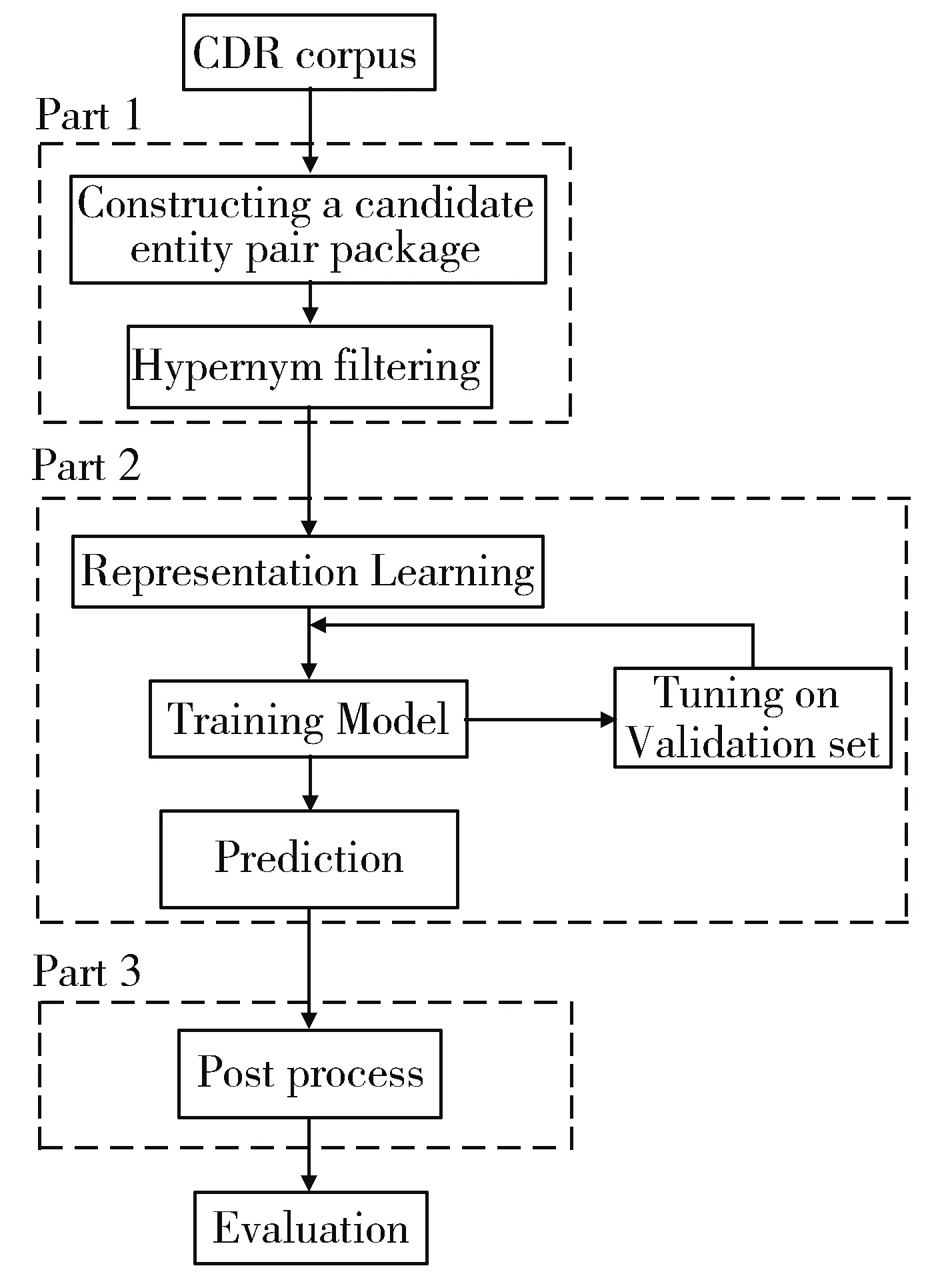
Fig.3 Method flow chart图3 方法流程图
1.1 预处理
1.1.1 构造候选实体对包
在关系抽取之前,需要构建用于训练,验证和测试阶段的候选实体对包。首先根据CDR语料中的实体标注信息生成候选化学物-疾病实体对。假设一篇文档中存在a个不同的化学物实体和b个不同的疾病实体,那么可以从该文档中生成a×b个候选化学物-疾病实体对。
然后为每对候选实体对生成相应的包。在多示例学习中,包为多个示例的集合[12]。对于每对候选实体对,本文根据以下规则生成相应的示例:对于句间实体对,实体1所在句、实体2所在句以及这两句间的所有句子一同合并作为该实体对的一个示例;对于句内实体对,该实体对共现所在句作为其一个示例。根据上述规则,可为候选实体对产生这篇文档中的所有示例,其示例集合为该实体对的包。
最后根据CID关系标注信息为生成的包打上正或负的标签。在多示例学习中,标签仅与包对应,包中的示例并无标签[12]。若包对应的候选实体对存在CID关系,该包为正包;反之则为负包。
1.1.2 上位词过滤
在某些情况下,相同类型的实体概念间存在上下位关系,即一个概念从属于另一个更一般的概念。CDR任务要求提取最具体的化学物和疾病间的关系,这要求研究者应该只关注下层概念间的关系,忽视上位概念间的关系[10]。例如下面的句子:
a) Carbamazepine-induced cardiac dysfunction.
b) A patient with bradycardia and atrioventricular block, induced by carbamazepine, prompted an extensive literature review of all previously reported cases.
上面两句话摘自同一篇文章(PMID:1728915)。句a和b分别是文章的标题和部分摘要,其中“Carbamazepine”和“carbamazepine”是同一化学物实体(C1);疾病实体则为“cardiac dysfunction”(D1)、“bradycardia”(D2)及“atrioventricular block”(D3).句中存在三种CID关系,分别为C1-D1,C1-D2,C1-D3。D1是D2和D3的上位词,因此后两种关系要比第一种关系更为具体,根据CDR语料的标注准则[17],仅C1-D2,C1-D3应被标为正例。
然而,从关系抽取的角度来看,句a是表达CID关系的常用句式,若在训练中将它看作负例,那么它会干扰分类器,导致其性能下降。因此在该阶段,本文参照Gu等人的方法[9],利用MeSH词典寻找并过滤了上位概念关系的负例。如上面的例子,C1-D1关系被直接过滤。
1.2 关系抽取
本文提出的MICNN模型将候选化学物-疾病实体对(e1,e2)及对应的包作为输入,最后输出一个二维向量来判断实体对间是否存在CID关系。图4所示为MICNN整体结构图。该模型主要分为三个部分:(1)示例级别特征抽取;(2)多示例池化;(3)二元关系分类,具体介绍如下。

Fig.4 MICNN structure diagram图4 MICNN结构图
1.2.1 示例级别特征抽取
该过程为包中示例生成矢量特征。本文定义单示例的最大长度为h,长度小于h的示例用0填充至h,长度大于h的示例则被截断。对包中的每个示例,本文使用卷积神经网络进行特征抽取,该网络包括表示层,卷积层和池化层。图5对该过程的具体流程进行展示。
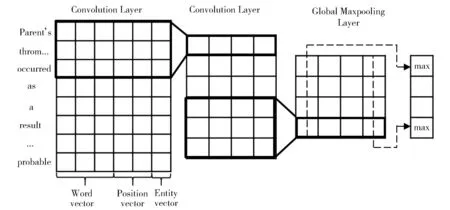
Fig.5 Instance level feature extraction图5 示例级别关系抽取
1.2.1.1 表示层
在对每个示例进行输入表示的过程中,本文使用了以下三种特征:
(1)词特征:将示例中的每个单词映射成dw维的词向量,最终获得词向量矩阵Ew,即词嵌入。为了获得高质量的词向量,本文以disease和chemical为关键字,从PubMed上下载了200 000篇摘要,然后利用word2vec[18]工具进行训练,最后获得了200维的词向量表示。
(2)位置特征:对当前示例对应的两个实体出现的位置用整数进行标记。下面以化学物实体为例对标记过程进行说明:首先以化学物实体所在位置为原点,将其标记为0。对于该实体以前的单词,位置标记随着与原点距离的增加依次减1;对于该实体以后的单词,位置标记随着与原点距离的增加依次加1。然后按照预先为[-h,h]间的所有整数随机初始化的dp维向量表,将标记中的每个整数映射成dp维的向量,即位置嵌入。最终,每个示例拥有两个分别表示化学物实体和疾病实体位置特征的位置矩阵Ep1和Ep2.
(3)实体特征:对当前示例中出现的所有化学物和疾病实体的所在位置用整数进行标记。若当前位置为化学物实体,则用1标记;若为疾病实体,则标记为2;若未出现实体,则标记为0。为每个标记随机初始化一个de维的向量后,根据标记情况对其进行实体标记嵌入。最终获得实体标记矩阵Ee.
最后将以上三种特征矩阵进行拼接,得到矩阵X=[Ew,Ep1,Ep2,Ee] 作为示例的输入表示。其中,ds=dw+2dp+de.
1.2.1.2 卷积层
卷积运算旨在从输入矩阵X中提取特征,公式如下:
(1)
其中,W∈wc×ds是卷积矩阵,wc是卷积窗口大小,b为偏置值;f()是激活函数,本文使用ReLU作为卷积层的激活函数。为了学习更高层的特征,连续使用了两层卷积层。它们的卷积窗口大小分别为wc1和wc2,那么两次卷积完成后,得到一个特征映射c=[c1,c2, …,c(h-wa+2)],其中,wa=wc1+wc2。为了从每个示例中抽取出n个特征,本文在每层卷积层中均设置了n个权重不同的卷积窗口。最后得到特征集矩阵C∈n×(h-wa+2).
1.2.1.3 全局池化层
为了捕获全局最重要的特征,在卷积层后进行全局最大池化,公式如下:
pij=max(cij) ,
(2)
其中,1≤i≤n, 1≤j≤h-wa+2。池化完成后,将特征集中的每个特征拼接起来,最终得到当前示例的特征表示p∈n.
1.2.2 多示例池化
根据多示例学习的思想,同一包的所有示例共同表示了对应候选实体对的关系,因此有必要在多示例间抽取跨示例信息。在上节中,尽管已经将包中的每个示例均表示成了n维的特征向量p,但并未充分考虑示例间的信息。
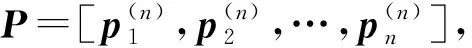
(3)
由(3)可以看出,多示例池化融合了所有实例的特征,构造出实体对级别的特征,从而使分类器可以根据来自不同示例的多个特征对同一实体对进行预测。
1.2.3 二元关系分类
在本文中,将CDR任务定义成一个二分类问题,因此在获得实体对级别的特征表示后,又经过一个全连接层来学习更高层次的特征,最后使用Softmax层进行分类。
在Softmax层,首先计算每个标签的置信值:
o=Woutv+bout,
(4)
其中,Wout是每个标签对应的权重矩阵,v为上层全连接层的维度,bout为偏置值。随后对向量o的每个元素值应用softmax函数,从而获得每个标签的概率值,计算过程如下:
(5)
其中,M为当前实体对对应的包,θ为模型的全部参数。
最后,本文选择具有最大概率值的元素所对应的标签作为当前候选实体对的预测结果。
1.3 后处理
为了进一步提升CID关系抽取性能,本文也采用了已有相关工作中常使用的后处理规则[9]。具体地,当模型未能从一篇文档中提取到CID关系时,则使用启发式规则来寻找该文档中最可能为CID关系的实体对:文章标题中若出现化学物实体,则认为该实体与该篇文章提到的所有疾病实体均存在CID关系;若未出现化学物实体,则文章中提及次数最多的化学物实体与该篇文章中所有的疾病实体存在CID关系。
2 实验结果及分析
本节首先介绍CDR语料的数据分布以及实验设置,然后展示模型在CDR任务上的实验结果,最后对模型的表现进行系统分析。
2.1 实验数据和设置
本文在BioCreative V CID关系抽取子任务上进行实验。CDR数据集一共包括1 500篇PubMed文章(仅有标题和摘要),训练集,开发集和测试集各500篇,表1展示了数据集中文章数量和CID关系的统计情况[17]。

表1 CDR数据集
为了与现存的相关工作比较,采用同样的实验数据设置,即原始训练集和开发集合并作为新的训练集,测试集保持不变[9]。为了选择超参数模型,抽取20%的训练集作为开发集。在实验结果的评估上,使用常用的准确率(Precision),召回率(Recall),综合分类率F值(F-score)作为实验数据的评估指标,其中F值为主要参考指标。
在MICNN模型的训练中,使用Adam算法[19]进行参数优化,并使用开发集对模型超参数进行优化调整,最后根据在开发集上的模型性能使用早停机制选择训练迭代次数。表2展示了本文模型的主要超参数。
2.2 示例个数对模型性能影响实验
为了调查一个包中示例个数对模型性能的影响,实验测试了使用不同示例个数的模型性能,实验结果如表3所示。
由表3我们可以看出:随着包中示例个数的增加,模型性能呈先上升后下降趋势,当一个包中含有5个示例时,模型性能最好,后面的实验均设置包大小为5。从以上结果可知,当包中示例个数过少时,噪音(即仅提及候选实体对,未表示实体对间关系的示例)在包中所占的比重大,多示例的优点未能得到发挥,对模型的表现造成了一定损害;随着包中示例的增加,噪音所占的比重下降,对模型的干扰也随之降低,模型的性能因此得到提升;然而,当包中的示例个数过多时,由于引入了额外的噪音,对模型的干扰增加,从而导致模型的性能下降。

表2 MICNN超参数列表
2.3 策略和特征对模型性能影响实验
为了探索预处理策略和输入特征对模型性能的影响,在使用了预处理策略和全部输入特征的MICNN模型基础上,每次单独减去一个策略或特征来考察它们对模型性能的影响。实验结果如表4所示,其中,-preprocessing表示去掉上位词过滤;-word表示将词向量替换为随机初始化向量;-position表示去掉位置特征;-entity tag则表示去掉实体标记特征。

表4 策略和特征实验
通过表4可以看出,上位词过滤能显著提升性能;词特征、位置特征亦能大幅提升模型的性能;此外,实体标记特征也能比较明显地改进模型的性能。原因在于,在预处理阶段利用上位词对负例过滤后,之前会干扰分类器的负例被过滤,分类器的性能因此得到提升;同时,过滤负例后会在一定程度上提高结果的准确率,这对F值的提升而言也是有益的。除此之外,通过分析语料,发现除了候选实体对,其他相关的实体往往对要抽取的关系有一定影响,标注出这些实体的位置和类型会在某种程度上为分类器预测提供额外的信息,提高关系抽取性能。
2.4 方法性能对比实验
为了探索文档级别模型在当前任务上的性能,本文分别使用BiLSTM和CNN模型,以整篇文档作为输入,使用和MICNN同样的特征直接进行文档级别的CID关系抽取,作为基线系统,实验结果如表5所示。可以看出与这两种基线系统方法相比,MICNN的性能有了很大的提升,原因在于以整个文档作为输入包含了大量与候选实体对关系无关的噪音内容,使得模型抽取性能不理想。

表5 方法性能对比实验
其他的现存系统可被分为两类:机器学习方法和神经网络方法。
对于基于机器学习的系统,Xu等人[8]和Gu等人[9]使用基于语义的特征,为句内和句间候选实体对训练了两个分类器。在基于神经网络的系统中,Gu等人[9]使用了词法、句法特征,为句间,句内候选实体对分别训练了ME模型和CNN模型,并进行了后处理;Zhou等人[11]仅对句内候选实体对做预测,使用了SVM与LSTM结合的混合模型。
由表5可以看出,基于神经网络的系统达到的F值普遍高于基于机器学习的系统。此外,除了MICNN,另外两种未使用KB的系统在未进行后处理时,其准确率均比召回率高,原因可能是这些系统使用了较为复杂的词法、句法特征,获得了较高的准确率;然而,由于跨越句子边界的CID关系未能被系统有效识别,因此召回率偏低。
与这些现有的先进方法相比,MICNN模型能够同时对句间和句内CID关系进行抽取,无须进行多模型结果融合,并且获得了比其他多模型更好的结果。从使用特征方面来看,MICNN仅使用了三种基本特征,即词向量特征、位置特征和实体特征,并未使用词法分析,句法分析等特征。在不使用任何后处理的情况下,MICNN在测试集上获得了比其他方法更高的召回率和F值。在使用了与其他方法同样的后处理规则后,F值由61.7%进一步提升至62.7%。
3 噪声及错误分析
3.1 噪声分析
为了验证模型在降低噪声影响上的有效性,利用图2中的示例a和噪声b,分别构造包,并用模型做预测,结果如表6所示。其中,A包仅包含示例a,其余示例由0表示;B包仅包含噪声b,其余示例由0表示;C包包含示例a和噪声b,其余示例由0表示。

表6 预测结果
由表6可知,当包中仅包含噪声时,模型会做出错误的预测;当示例与噪声共存时,模型能做出正确的预测。这是因为在多示例学习中,只要包中的一个示例是正例(比如C包),MICNN便认为该包对应的实体对存在CID关系;当且仅当示例中全为负例或噪声时(比如B包),MICNN才会为实体对打上负标签。因此,MICNN能对噪声数据起到一定的改善作用。
3.2 错误分析
在与现有先进方法的比较中发现,尽管MICNN拥有比其他系统高的召回率,但是其准确率偏低。为了分析准确率低的原因,同时也为了进一步评估模型在句间和句内上的分类性能,本文在未经后处理的测试集结果上对句间和句内的评价指标分别进行了计算,结果如表7所示。

表7 句内和句间CID关系的抽取结果
由表7可以看出,模型在句间的表现远低于句内的表现,原因可能在于,在句间CID关系中,实体对跨度往往较大,另外由于仅使用了简单特征,模型不能很好地在长距离上捕获实体间信息;此外,在CDR语料中,句间CID关系的数量远远少于句内CID关系的数量,导致模型的训练不充分,进而影响了在句间的表现。由此可见,在句间CID关系提取上的低准确率表现,是模型整体准确率低下的重要原因。
4 结论
本文提出了一种用于CID关系抽取的MICNN方法。与现存的CID关系抽取方法相比,MICNN方法能够从文档级别同时对句间和句内CID关系进行抽取,无须训练多模型再进行结果融合;基于多示例学习的思想,本文方法为每对候选实体对构造相应的包,包中含有多个示例。与现有方法使用单示例对候选实体对进行训练和预测不同的是,MICNN使用包进行训练和预测,有效地降低了噪音对当前实体对的干扰;MICNN仅使用关系抽取基本特征(即词向量特征、位置特征和实体特征),无须大量特征工程,通过神经网络自动学习文档级别特征具有较好的鲁棒性和泛化能力。实验结果表明,与现存的先进方法相比,MICNN具有更好的性能表现,在CDR数据集上F值达到了62.7%。
然而现阶段,抽取CID关系的相关系统仍有很大的提升空间,句间CID关系抽取的性能也需要得到进一步的提高。而从现有方法来看,依存句法这类特征对模型性能而言是有益的,因此将在未来工作中尝试使用这类额外特征。除此之外,额外的知识库已经被证明能够有效提升CID关系抽取性能,探索在MICNN中加入知识库的方法也是我们未来的工作。
