多源文本下结合实体的事件发现方法ESP
2019-02-15秦宇君史存会刘悦俞晓明程学旗
秦宇君,史存会,刘悦,俞晓明,程学旗
(1.中国科学院大学,北京 100049;2.中国科学院计算技术研究所,北京 100190)
0 引言
随着互联网的不断发展,人们越来越多地通过网络进行信息的发布和接收,这也导致网络舆论对社会稳定的影响程度与日俱增,如Twitter在北非和西亚的“阿拉伯之春”的社会运动中,起到了重要作用;国内社会生活中的食品安全、自然灾害、惩治腐败、房市调控、法治热点、春运、高考等各种事件在网络用户间被热烈的讨论和传播,并最终对人们的现实社会生活产生了实质性的影响。基于国际社会对网络舆情的需求,舆情系统应运而生,这类系统的主要功能包括突发事件发现,热点话题分析,有害信息识别等。
在实际的舆情系统中,社会事件往往是系统关注的重点。互联网当前已经成为报道和传播各种社会事件的重要信息平台。在互联网中存在众多的信息发布通道,如微博、微信、新闻等。不同的信息发布通道有各自的特点,例如对于微博、微信等网络自媒体通道所发布的信息具有及时性、多样性等特点,许多社会事件的第一报道地点往往都来自于这些网络自媒体,而对于同一事件的报道者越多,观点越丰富,则能从侧面反映出该事件的舆论热度和潜在的舆论影响力。相对于微博发布信息的短、平、快的特点,许多来自新闻网站等通道的事件发布则更侧重事件的完整性、事实性,这些新闻媒体通道对于事件的描述更加详细,内容更加真实可靠。
对于网络舆情系统而言,系统所发现的事件如果能既具备很高的舆论热度和潜在影响力,也能有详尽的事件信息与很好的可靠程度,则能为后续相关事件的及时处理提供更好的帮助。鉴于微博等网络自媒体通道具有反映事件热度和影响力的能力,而新闻网站等通道具有规范化、可信度高等特点,如果能将这些不同通道的信息进行关联与综合利用,从而发现事件,则将会对网络舆情系统的效果有很大的提高。
目前事件发现领域[1]的研究大多是针对同种类型文档进行研究,研究方法主要分为以文档为事件中心和以词为事件中心。以文档为中心的事件发现方法主要采用分类和聚类的方式,将文档归为不同的文档集合,形成事件;以词为中心的事件发现方法则利用信号处理或主题模型等方式获取事件代表词,将包含代表词的文档归为同一集合,形成事件。无论是以文档为中心还是以词为中心的方式,其核心都是将文档转换成另一种表达形式,然后再利用新的表达方式将文档归纳到不同的集合中从而形成事件。对于单一通道,数据的结构和内容形式往往相同,因此在用相同的方法进行映射之后,在原空间相似的文档在新空间仍然相似,事件发现的效果相对较好。然而在多源文本中,新闻报道和微博消息在内容形式上具有较大区别,新闻报道往往用词规范,内容相对充实,微博消息则口语化较严重,内容相对短小精炼,如果采用相同的映射方法,很难保证在原空间相似的文档在新空间仍然相似。
本文则针对传统事件发现方法在处理多源文本时遇到的困难,提出了结合实体的事件发现方法ESP。首先提出了事件核心实体的概念,给出了事件核心实体的获取方法,并通过在经典的Single Pass方法中引入事件核心实体信息,丰富了多源文本中的各类文本的表达,使得多源文本中来自不同通道的文档能够在新的映射空间中具有更多的信息,从而提高了多源文本事件发现的效果。
传统的事件发现方法大概分为两类:以文档为事件核心和以文档的代表词为事件核心。前者是通过将文档映射到语义特征空间,通过分类或聚类的方法来发现事件[2-4];后者则是先利用词频突变,关键词筛选等方法获得代表文档特点的词语,再对词进行聚类或关联,从而发现事件[5]。
从文档角度出发的事件发现,传统的方法有层次聚类(Hierarchical Clustering)、K-means聚类、Single-Pass[6]聚类和局部敏感哈希[7](Locality-Sensitive Hashing,LSH)等,这些方法首先都是将文档映射到语义特征空间,然后进行相似度计算。
层次聚类需要人为指定最终期望的结果个数,但是在实际的事件发现系统中,事件的个数往往不能预先确定,并且在计算簇内相似度时要对簇内的所有文档两两计算相似度,时间复杂度和空间复杂度都较高,不太适宜大量数据的场景。与层次聚类相似的方法还有K-means聚类,但它需要提前确定k个聚类中心,实际应用中k的确定十分困难,同时初始点的选择也极大地影响事件发现的结果。
Single-Pass聚类方法则是将每一篇新到来的文章与之前的事件相比较,如果通过两两比较,当前的文章与之前的任何一篇均不相似,则视为新的事件,否则加入现有事件列表中。此方法的优点是可以处理流式数据,增量式发现事件。但是相似阈值的设定以及文档到达的顺序会直接影响事件发现的效果。
局部敏感哈希方法则是利用多组哈希函数,将文档从高维空间向低维空间进行投影,再利用投影后的低维向量进行数据分桶索引,对于属于同一个桶中的数据进行相似度计算,从而缩小比较的次数,这种方式对于大量的数据能够很大程度上降低计算时间复杂度。但是在实际应用中,相似文档并不能很大程度的映射到相同的数据分桶中。
除了以上这些将文档进行特征映射后进行聚类的方法,分类方法也被应用在事件发现领域。当系统的主要任务是发现特定类别的事件时,通过合理的特征设置,可以利用分类方法定向的发现事件[8]。但是这种方法只能用于某些指定类别的事件,很难扩展应用到大范围事件发现系统中。
从词的角度出发的事件发现,主要是从词在时域和频域的变化进行事件代表词的筛选,将最终得到的一些词的集合作为事件的代表。
Kleinberg[9]提出消息的到达是有时序关系的,他提出二元状态自动机和无限状态自动机两种建模方法,通过模型可以得到某个词的状态变化序列,从而获得爆发词和相关文档。
Fung[10]等人则针对现有聚类方式的问题,提出了通过构造词的分布,判断某一词是否属于爆发词。获取到爆发词后,根据文档包含爆发词的情况,形成爆发事件。最终还可以通过跟踪爆发词的变化,获得事件爆发的周期。
Ge等[11]则提出了一种利用词频的突变以及词与词之间的共现关系,构造消息爆发网络,网络中的节点是符合突变性质的词,网络中的边则是代表词的共现关系,并且边上的权重随着共现次数的增多而增大。网络构造完成后再利用TextRank的方式发现网络中的关键词,作为最终事件的代表性词汇。
综上可知,无论是以文档为核心还是以词为核心的事件发现方法,都是获取文档在特征空间的一种表达,然后再利用特征空间的相似性将相似文档聚到一起形成事件。这种方法虽然可以在很大程度上将相似文档聚到一起,但是在针对“事件”这一特殊领域,还有可以提升的空间。
1 结合实体的多源文本事件发现算法ESP

Fig.1 Flow chart of ESP图1 事件发现算法流程示意图
ESP算法是基于Single-Pass流式聚类算法进行的改进。前人[12]的研究认为事件是指在某个特定的时间和环境下发生的,由若干角色参与,表现出若干动作特征的一件事情。形式上可以表示为由时间、地点、人物、机构等实体构成的多元组形式。由于实体对事件有很强的表达能力,如果能准确地识别文档中的核心实体,并将其作为文档在事件域的表达,则能更好地进行事件发现。因此,ESP算法首先要对每篇文档进行核心实体识别。在获得每篇文档的核心实体集合后,进行文档间核心实体集合间相似度计算。最终将文档间核心实体相似度引入现有的事件发现算法Single-Pass中,进行事件发现。算法流程见图1。
1.1 事件核心实体识别方法
由于目前对于事件核心实体尚未有统一的定义,因此本文首先对事件核心实体进行定义。
定义:事件核心实体是指对于描述、刻画一个事件起到重要作用的人名、地名、机构名等实体。
根据以上定义,本文提出的事件核心实体识别方法,流程分为以下两步:(1)对事件文本进行命名实体识别,获得事件的候选实体集合,候选实体集合中的每个实体都包含了实体的类型信息和位置信息。(2)利用本文提出的EntityRank算法对实体集合中的实体进行重要度排序,将重要度最高的实体作为核心实体。针对第一步中的命名实体识别,可直接利用现有命名实体识别方法获得,在此不再赘述。
EntityRank算法是在TextRank的基础上针对实体进行的改进算法。与TextRank类似,EntityRank首先要对文档中出现的实体进行构图,构图方法如下。
(1)按照段落作为实体共现的窗口,处于同一段落中的实体相互连边。原始的算法中两点之间有连边即表示两点之间有一定的相关关系。在一篇报道中,一个段落往往对应着一个相关主题,处于一个段落中的实体则通常具有相关关系,利用段落作为实体共现的窗口既能避免人为设定k值导致的偏差,又能使相关实体能够建立起联系。
(2)处于同一窗口内的实体按照距离远近关系计算,如式(1)所示。由于实体往往具有稀疏性,处于同一窗口内的实体并不会像普通词汇一样密集,此时如果再利用共现词频等作为连边权重往往不能起到相应的作用。但是根据语言学的规律,相关的实体往往会距离比较近,因此利用实体在段落中的距离来衡量实体之间的相关关系比较符合连边权重的意义。
(1)
其中Wij表示连边权重,dis(i,j)表示实体i和实体j之间的距离,max_distance为整篇文章的所有段落中最长段落的长度。
得到了连边权重Wij后,便可以按照公式(2)进行迭代运算,最终获得每个实体的重要度。
(2)
其中d是抑制因子,d∈(0,1),In(Vi)为与Vi有连边的所有节点,Out(Vj)为与Vj有连边的所有节点,WS(Vi)为节点Vi的重要度。
EntityRank算法的主要步骤总结如下。

算法:EntityRank输入:带有位置信息的实体集合S=[(entity1,loc1),(entity2,loc2),…,(entityn,locn)]输出:实体对应权重信息Res=[(entity1,weight1),(entity2,weight2),…,(entityn,weightn)] step1step2step3step4将实体集合按照段落进行切分,分成若干子集。S1, S2,…, Sn,Si∈S.针对每个子集Si,进行构图。构图规则为:(1)子集中的实体为图中的节点。(2)属于同一子集中的实体相互建立连边。(3)连边权重由公式(1)得到。针对步骤2得到的图,按照公式(2)进行节点权重迭代计算。返回结果Res。
1.2 实体集合间相似度计算方法
(1)字形字序法
字形字序法的主要作用是计算两个实体在字面上的相似度,主要借鉴现有的词形词序法[13]。设sameCC(A,B)为实体A和B中相同字的个数,当同一个字在A和B中出现的次数不同时,以出现次数少的计数,则实体A和B的字形相似度为:
(3)
可知,0≤WordSim(A,B)≤1.
设OnceCS(A,B)表示A和B中都出现且只出现一次的字的集合。Pfirst(A,B)表示OnceCS(A,B)中的每个字在A中的位置序号构成的数字排列,Psecond(A,B)表示Pfirst(A,B)中的分量按对应字在B中的字序排列生成的数字排列,RevOrd(A,B)表示Psecond(A,B)各相邻分量的逆序数。则A和B的字序相似度为
(4)
可知0≤OrdSim(A,B)≤1.综合字形相似度和字序相似度,词语A和B的相似度为:
Simword(A,B)=α1×WordSim(A,B)+α2×WordSim(A,B) ,
(5)
其中α1和α2均为常数并且满足α1+α2=1,因此0≤Simword(A,B)≤1.由于词形相似度相对词序相似度更能代表词的相似程度,所以一般有α1>α2.
(2)语义相关法
语义相关法的主要作用是计算两个实体在语义上的相似度,主要利用Word2Vec[14-16]的方式对实体进行向量化表示,然后利用余弦相似度对两个实体的向量表示进行计算。
Simsem(A,B)=cos(Ai,Bi) ,
(6)
其中A和B为两个实体,Ai和Bi则为A和B对应的向量,Simsem(A,B)为实体A和B的语义相似度。
(3)实体集合相似度计算
两篇文本包含的实体之间的相关性是这两篇文本之间相关性的重要反映。最大实体关联法是计算两个实体集合之间相似度的方法,是在最大词语关联法[17]的基础上针对实体进行的改善。对于两个实体集合A和B,针对集合中的实体获得词向量A′={a1,a2,…,am}和B′={b1,b2,…,bn},不失一般性,可令n≥m.构建两个文档的实体特征相关矩阵为:
(7)
其中Sij表示实体Ai和Bj之间的综合相关度值,由字形字序法和语义相关度共同决定:
Sij=α3×Simword(Ai,Bj)+α4×Simsem(Ai,Bj) ,
(8)
其中Simsem(Ai,Bj)为实体Ai和实体Bj对应词向量的余弦相似度的值,α3和α4均为常数并且满足α3+α4=1,因此0≤sij≤1.可知矩阵S第i行中的最大值是实体集合A中实体Ai与实体集合B中实体相关度最大的实体的相关度值。取S中每一行具有最大值的元素,构成文档A和B的最大实体关联序列:
maxL={S1,x1,S2,x2,…,Sm,xm} ,
(9)
然后,由式(10)计算A和B之间的实体相关度:
(10)
其中,wi和wxi分别是Ai和Bxi在实体集合A和B中的权重,其定义如下:
(11)
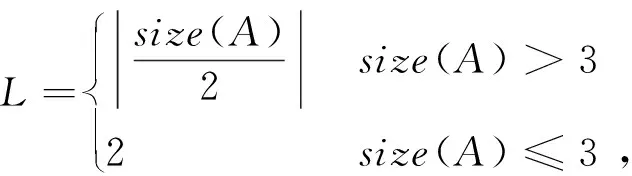
(12)
其中size(A)表示实体集合中包含实体的数量,t为当前实体在实体列表中的位置,L代表衰减周期,k则为衰减系数。
由于在多源文本中,来自不同通道的数据具有的事件实体数量多少不一、种类不同,不同类型的事件实体之间显然不能进行相似度计算,而在同种类型事件实体计算相似度时则既要考虑到字面的相似性,又要结合语义相似度。除此之外,例如某些微博数据中只会包含少量类型的事件实体,而新闻报道中包含的事件实体类型相对较多,这种情况下,如果两种文本共同含有的实体相似度很高,则两篇文章的整体相似度可能依旧很高,因此在文档间实体集合相似度计算方法设计的过程中不能简单地将不同类型的实体相似度进行叠加。基于以上的考虑,本文设计的文档间实体集合相似度计算方法主要有以下几个步骤。
1)共同出现的同类型实体之间计算相似度。
2)相似度计算方法选用最大实体关联法。
3)对于不同实体类型的相似度计算结果取平均。
根据以上几点,本文提出的文档间实体集合相似度计算方法可以用下式表示:
(13)
其中A,B表示两篇文档,Ae和Be表示两篇文档中属于类型e的实体集合,EntitySim表示文档间实体集合相似度,entitys为两篇文档中共同出现的实体类型,entitys-num为两篇文档中共同出现的实体类型的数量,Siment即上文中的最大实体关联法。
1.3 结合实体的多源文本事件发现算法ESP
ESP算法的核心在于利用两篇文档在事件实体间的相似度,辅助进行事件发现。事件核心实体的具体使用方式可以分多种情况:(1)当事件核心实体间相似度大于某个阈值时,直接判定为相似,归为一类,否则通过文本相似度进行判断。(2)当事件核心实体间相似度小于某个阈值时,直接判断为不相似,否则通过文本相似度进行判断。(3)将事件核心实体相似度与文本相似度进行结合之后再和阈值进行比较等。
在利用以上几种方式进行辅助事件发现的过程中,事件核心实体间相似度是指当前文档与现有事件中所有文档的事件核心实体相似度的平均值。如果当前文档能够加入现有事件,则用当前文档的向量更新事件代表向量,即
(14)
其中n为当前事件所包含的文档数,V为当前文档向量,VEold为当前事件代表向量,VEnew为更新后的事件代表向量。
Entity Single-Pass算法的核心伪代码如下。

算法:Entity Single-Pass 输入:documents,SIM-THRESH,ENTITY-THRESH 输出:eventSet 123456789 101112131415161718192021222324252627FOREACH doc in documents max-sim=0.0 matchEvent=NUL matchFlag=False doc-entity=getEntitys(doc) doc-vec=getDocVec(doc) FOREACH event in eventSet event-entitys=getEntitys(event) event-vec=getEventVec(event) entity-sim=GetEntitySimilarity(doc-entity,event-entitys) IF entity-sim> ENTITY-THRESH THEN UpdateEvent(event,doc,doc-entity,eventSet) matchFlag=True BREAK END IF vec-sim=getCosinSim(doc-vec,event-vec) IF vec-sim> max-sim THEN max-sim=vec-sim matchEvent=event END IF END FOR IF not matchFlag and max-sim> SIM-THRESH THEN UpdateEvent(event,doc,doc-entity,eventSet) ELSE CreateEvent(doc,doc-entity,eventSet) END IFEND FORReturn eventSet

算法:GetEntitySimilarity 输入:doc-entity,event-entitys 输出:similarity 1INIT: sim-sum=0 2 FOREACH event-ent in event-entitys 3 sim-sum=sim-sum+siment(doc-entity,event-entity) 4 END FOR 5Return sim-sum/size(event-entitys)
2 实验结果及分析
本节利用真实的微博事件语料和新闻事件语料对所提算法进行验证。
2.1 实验数据集
实验数据来自于新闻报道和微博数据,其中包含台湾花莲地震、云南九寨沟地震、四川凉山山洪、辽宁灾害天气、青海地震、美国枪击案等30个事件共2 000条数据,其中新闻数据和微博数据各1 000条。
实验中核心实体的获取方式根据文章所属通道的类型不同而有所区别。对于新闻报道等数据,利用事件核心实体识别方法进行核心实体识别。对于微博等数据,首先根据微博数据格式的特点,对于微博间格符“##”之间的内部实体进行识别和提取,将其直接作为事件核心实体。如果并未存在特殊结构,则同样利用事件核心实体识别方法进行识别。
2.2 评价标准
实验的评价指标采用聚类算法常用的标准化互信息(Normalized Mutual Information,NMI)和兰德指数(Rand Index,RI),其定义分别为:
(15)
其中I为互信息,H代表熵:
(16)
(17)
其中p(xi)表示文档属于簇xi的概率,p(x,y)表示文档属于簇x∩y的概率。
(18)
2.3 实验设计
K-means和Single-Pass是经典的事件发现算法,因此本文选择K-means和Single-Pass作为baseline。由于事件核心实体与传统的Single-Pass方法有多种结合方式,本文分别针对以下情况作了实验。
(1) 当事件核心实体间相似度大于某个阈值时,直接判定为相似,归为一类,否则通过文本相似度进行判断。
(2) 当事件核心实体间相似度小于某个阈值时,直接判断为不相似,否则通过文本相似度进行判断。
(3) 将事件核心实体相似度与文本相似度进行结合之后再和阈值进行比较,如果相似度大于阈值,则归为一类,否则不能归为一类。
同时,为避免阈值设置导致的结果偏差,本文在实验过程中,针对实验(1)和实验(2)分别按照事件核心实体相似度阈值以0.1为间隔,从0.1到1共10组阈值,文本相似度阈值以0.1为间隔,从0.1到1共10组阈值,排列组合共100种阈值组合中选取最优组合作为最终的实验结果。针对实验(3),按照阈值以0.1为间隔,从0.1到2共20种结果中选取最优组合作为最终的实验结果。K-means方法中聚类中心K分别取20,25,30,35,40,选取最优结果作为最终的实验结果。
2.4 实验结果
实验对比结果如图2。
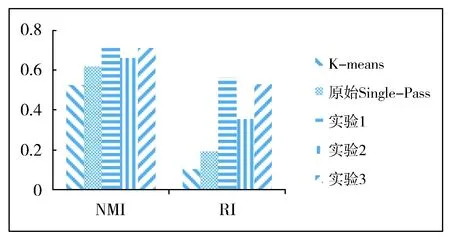
Fig.2 Result of text clustering图2 事件聚类结果图
5种方法取得最好结果时的参数设置如表1所示。其中Textsim为文本相似度阈值,Entitysim为实体集合相似度阈值。

表1 五种方法最优阈值表
可以看出,与K-means和原始Single-Pass方法相比,在结合了事件核心实体间相似度之后,各次实验的结果均好于原始Single-Pass方法。其中方法1和方法3相比原始Single-Pass结果在NMI和RI评价指标下均有较明显提高。方法2的最优结果则与原方法有一定的提升。
针对方法1的效果提升,可以看出当事件核心实体相似度大于某阈值时,即使不计算文本相似度,直接归为一类,也能达到准确发现事件的效果,并且相对于只利用文本相似度,消除了一些文本中的噪音,提高了事件发现的准确性。
针对方法2的效果提升,可以看出在原始Single-Pass方法中,存在某些文本相似度上较高,但属于不同事件的文档被判断为同一事件。而通过利用实体相似度进行过滤,将这些错误聚类到一起的文档更好的分开。
针对方法3的效果提升,可以看出事件核心实体相似度可以弥补文本相似度的不足,两种相似度结合后,同一事件下的文档能更好地结合在一起。但是同样,由于某些不属于同一事件的文档其文本相似程度偏高,使得结合实体相似度后,仍旧使得总体相似度高于阈值,导致聚类错误。
此外,方法1的效果相对于方法3有更好的表现,说明了在新闻报道和微博消息在一起进行聚类时,文章长度的不同使得文本在表达后进行相似度计算的效果并不理想,同时也说明了事件实体能够更好地对事件进行表达,从而使得多源数据一起聚类时效果更好。
在Single-Pass算法的改进过程中,事件核心实体间的相似度作为阈值起到了过滤作用。根据实验结果来看,以上改进的方法相对于原始Single-Pass的事件发现方法的效果有所提升,因此可以说明结合事件实体的改进事件发现算法是有效的,同时文档间实体集合相似度计算方法也是可行的。
3 结论
本文提出了一种适用于多源文本场景下的结合实体的事件发现算法ESP,算法针对传统事件发现方法在处理多源文本事件发现问题中的缺陷,提出并设计了事件核心实体识别方法,同时设计了实体集合间相似度计算方法,并给出了将实体集合相似度与Single-Pass结合的多种方式。算法通过引入事件核心实体的信息,丰富了多源文本中原始文档的表达信息,从而提高了事件发现算法的效果。在微博、微信和新闻等多源数据上对算法的有效性做了验证。通过与K-means和Single-Pass方法的比较,我们的方法在NMI和RI两项评价指标上分别提高了0.2和0.3,证明了ESP算法的有效性。
