一种面向预测任务的基于时间序列的病人表示学习方法
2019-02-15张乐方之家王祺雷丽琪阮彤高炬
张乐,方之家,王祺,雷丽琪,阮彤*,高炬
(1.华东理工大学 自然语言处理与数据挖掘实验室,上海 200237;2.上海中医药大学附属曙光医院,上海 200021)
0 引言
得益于医学信息化的深入开展,医院已积累了大量的电子病历(Eeltronic Health Record,简称EHR)数据。从简单的辅助诊疗(如患者相似度[1],死亡率预测[2])到复杂的临床决策支持系统(如IBM的Watson[3-4]),电子病历数据开始成为生物医学研究者和人工智能应用的重要资源。然而,直接使用电子病历进行数据挖掘面临着诸多挑战,如电子病历数据具有时序性、高维性、稀疏性、噪音性、偏倚性等特点。就时序性而言,每个病人通常有多次医院就诊记录,这些序列化的病历信息对于临床诊疗意义重大。因为之前发生的医疗事件可能会影响后来者,如由冠心病或高血压引起的心力衰竭在病理学上是不同的。因此,掌握此一时序性的医疗数据对辅助诊疗具有正面效益。再以高维性为例,电子病历数据中常常包含诸多医疗事件,如诊断、手术、用药、化验等,这使得电子病历的维度非常高。但是,传统机器学习所使用的特征提取方法难以应对这些挑战。
随着深度学习方法的普遍应用,研究者在一定程度上可以克服电子病历数据的复杂性所导致的特征学习困难。Choi等人[5]和Lipton等人[6]将循环神经网络(Recurrent Neural Network,简称RNN)应用于风险预测。Cheng等人[7]尝试将卷积神经网络(Convolutional Neural Network,简称CNN)应用于电子病历中进行表型分型。但他们的模型针对的是一些特定的任务,而不是一般的用法。即,训练完模型后只能针对一个特定任务进行分析,而不能为其他辅助诊疗任务所采用。当一个病人需要进行各类辅助诊疗时,这些模型就不能很好地适用。
另一方面,表示学习作为一个新兴的课题开始应用到医学领域。一些工作已经开始着手从电子病历数据中挖掘出常见的医学词汇,并将这些医学词汇表示成向量形式。由此,临床诊疗中复杂的医疗事件、医疗时间点等概念就可以转化成数学向量进行计算,从而方便辅助诊疗的开展与深入。而且通过表示学习,相较于原始的高维数据,不仅电子病历的维度降低,而且数据变得更稠密。Vine等人[8]通过纯文本的患者记录和医学期刊摘要,学习了医疗术语的向量表示。Choi等人[9]开始从电子病历数据中学习访问的表示。 Ho等人[10]则学习了医学表征,其重点是使用张量分解或因式分解以完成特定的预测任务。当然,这些面向任务的表示学习方法将注意力集中在特定的目标任务上会更有效率,但是,当给予另一项预测任务时,便需要重新学习或重新调整以得到新的表示。因此,在实际应用中,通用的患者表示变得更为重要。Riccardo等人[11]提出了一种无监督的方法使用自动编码器来推导出一种通用的病人表示。然而,这项工作受到观察窗口大小的限制。更重要的是,这些模型没有考虑时间序列特征,而由于多次就诊的存在,病历数据往往包含着时序信息。
因此,从序列化的住院记录中学习出一个通用的病人表示,并将之应用于多个辅助诊疗预测任务中变得很有必要。而如何将复杂多变的电子病历数据整合成统一、通用的向量表示,便是本文任务的难点所在。本文试图设计一种深度学习方法来训练一个通用的住院病人表示,并利用这一病人表示进行辅助诊疗任务。具体来说,本文提出了一种RNN自编码器,将每位患者的住院记录编码为一个低维稠密向量,并以心衰住院病人作为切入点,选择死亡预测和并发症预测作为对应的辅助诊疗任务。特别地,在实验验证方面,本文首先遵从医生的建议和指导,从上海中医药大学附属曙光医院的临床数据库中构建出一个关于心力衰竭的二次病历库。然后,将患者的原始电子病历数据转换为张量形式,这一张量形式是一系列院内病历记录的表示向量组合。这一过程包含了结构化数据的抽取、清洗与融合。最后对RNN自编码器模型进行训练,并将自编码器的中间向量提取出来作为心衰住院病人的表示向量。本质上,这一表示学习方法也是一个特征学习方法。
实验结果表明,与现有的特征学习算法相比,本文的方法在死亡预测任务中得到了0.754 8的AUC值(比第2名高了0.15),并在10个并发症预测任务中获得了4个第一名和2个第二名,显著优于其他方法。
本文的主要贡献如下:
(1)本文使用RNN自编码器将序列化的电子病历数据编码为通用的患者表示,可以同时应对不同的预测任务;
(2)本文在表示学习时考虑了时序信息,以捕获临床事件的先后顺序所带来的不同影响;
(3)本文的方法基于无监督学习,在进行表示学习时无须进行人工标注。
1 整体架构
1.1 问题描述
本文的任务目标是,给定医院各科室、各系统的多次住院的异构电子病历信息,预处理之后进行表示学习形成一个通用的心衰病人表示向量。需要注意的是,相较于以特定任务为目标从电子病历数据中抽取特征并训练模型,本文以通用任务为目标,并没有指定后续的辅助诊疗任务为何,而以构建通用的病人表示为追求。
在实验验证时,本文的主要研究对象为心衰病人电子病历,它具有以下特点:
(1) 心衰病人的电子病历数据形式各异,结构复杂。其中包含有结构化的人口学信息、入院信息、检查信息,以及非结构化的医嘱信息等;
(2) 心衰病人的再入院率较高,导致了序列化的电子病历的产生;
(3) 心衰病人的信息中包含各类空值、脏数据。例如性别中出现人名等输入错误,入院时间出现空值等遗漏错误等;
(4) 心衰病人的辅助诊疗需求较多,死亡预测、并发症预测等任务具有较高的实用价值,因此需要一个尽可能通用的特征提取方式来应对各类预测任务。
1.2 整体流程
图1展示了本文利用医院提供的电子病历数据为住院病人及其可能的应用生成向量表示的整体流程。首先,本文从医院系统中提取并建立了临床数据仓库(Clinical Data Repository,简称CDR),然后进一步提取了一个专注于典型心血管疾病(即心力衰竭)的子库。子库中的电子病历数据经过预处理、归一化、知识库匹配等一系列处理之后,以高维多热(Multi-hot)的向量形式进行表示(即原始表示)。 需要注意的是,多次再入院的患者具有多个连续的多热向量表示记录。因此,本文使用张量或多路阵列来表示多次住院的病人病历信息。最后采用一个RNN自编码器来进行表示学习。具体地,本文利用RNN自编码器,将由张量表示的病人信息转化为一个低维稠密的向量,即本文所提的病人表示形式。获得了病人表示之后,利用这个表示向量进行一系列辅助诊疗工作,即死亡预测和并发症预测。

Fig.1 Overview of patient representation learning and application图1 病人表示学习及应用的整体流程
2 实现方法
本文任务可以定义为:输入一个病人的历次住院记录X=[x1,x2,…,xn],输出一个可以用来实现预测任务的特征向量即病人表示c,其中xi表示该病人第i次住院的住院记录向量。
RNN模型适合处理序列化的数据。给定一个基于时间t的序列X=[x1,x2,…xt],RNN模型能不断迭代计算t时刻的状态ht:
ht=RNN(ht-1,xt).
(1)
在诸如词性标注[12-14]、机器翻译[15-17]、文本摘要[18-20]等领域,RNN已经被证明了它在处理序列化数据上的优越性。长短时记忆(Long Short-Term Memory,LSTM)网络[21]相较于原生的RNN模型,增加了门控机制,能够有效地克服梯度爆炸或者梯度消失问题[22-23]。序列到序列(即Seq2Seq)学习基于LSTM网络,在机器翻译[24]、文本解析[25]、图像注释[26]和会话建模[27]等方面也取得了实质性进展。本文的表示学习模型即是对序列到序列学习的一个扩展。
受序列化自编码器[28]启发,本文采用LSTM与自编码器相结合的方法,构建基于RNN 自编码器的通用病人表示学习模型,如图2所示。

Fig.2 RNN auto-encoder图2 RNN自编码器模型
该模型由两个部分组成:编码器与解码器。编码器与解码器实质上都是LSTM网络。编码器将输入的张量(即向量序列)X转化为中间变量c,这里的c即为LSTM网络中最后一个时刻的输出ht:
c=LSTM(ht-1,xt) .
(2)
在解码阶段,解码器根据上一时刻LSTM的输出st-1、上一时刻解码器的输出yt-1和中间变量c得到当前时刻的LSTM输出st:
st=LSTM(st-1,yt-1,c).
(3)
据此得到当前时刻解码器的输出yt
yt=softmax(st,yt-1,c).
(4)
本文方法实质上将自编码器的编码过程和解码过程转换为两个不同的LSTM过程。一个病人的历次住院信息通过LSTM迭代编码成病人表示向量c,再将c通过另一个LSTM模型解码成为历次住院信息。当c解码后的历次住院信息与原来输入的病人信息保持一致时,则可认为c完整囊括了这一病人的历次住院信息。因此,RNN自编码器的训练目标在于尽可能保证X与Y(Y=[y1,y2,…,yn])最为接近,由此自编码器的中间向量c就可认为是病人住院记录张量X的降维结果,即RNN自编码器的训练目标在于最小化损失函数L(X,Y):
(5)
其中,xi表示X中第i个元素,xi(j)表示xi中第j个元素。同时在训练中,本文使用大小为100的mini-batch并使用RMSprop梯度下降方法[29]更新RNN自编码器的参数。
本文使用的模型中LSTM隐藏层的维度均采用经验参数300,即生成的通用病人表示维度为300。
3 数据集
3.1 数据来源
本文的电子病历数据来自上海中医药大学附属曙光医院。这是一家中西医结合的大型三甲医院,医院使用电子病历系统已有超过10 a的历史,病人的病历信息有充分的文件记录和时间戳。病人的电子病历记录包括人口统计学信息、主诉、化验、诊断、用药、手术和医嘱等信息。该院的电子病历使用疾病名称的国际疾病分类第10版(ICD-10)代码作为诊断编码标识,使用ICD-9-CM作为手术编码标识,另外还采用观测指标标识符逻辑命名与编码系统(LOINC)编码进行检验结果标识。其他信息如药物处方信息等不采用国际编码标准。本文的实验数据采用2005年1月至2016年4月期间发生的住院患者病历。整个数据集包含大约35万份住院患者的病历记录。
本文基于此构建了一个专注于心力衰竭病例的二次库(即心衰子库)。该过程在上海曙光医院的医学专家指导下进行。二次库中所包含的患者需要同时满足以下两个条件:(1)心力衰竭相关的ICD-10代码出现在患者的诊断或医嘱中。为此,医学专家们定义了一个包含63个与心力衰竭有关的ICD-10代码的清单。(2)前述诊断或医嘱中需要至少出现2次上述ICD-10代码。
3.2 序列化住院记录生成
本文对已构建的二次库中的每位患者的每一次住院记录分别生成一个向量表示,然后将每一住院记录向量按照入院时间排序并组合,构成一个序列化的住院记录张量。
对于数据集中的每位患者的每一次住院记录,保留一般人口统计学信息(年龄和性别)和临床事件,包括结构化的诊断、化验、用药以及非结构化的医嘱、诊断等。将这些临床事件表示为可计算事件序列时,归一化过程因类型而异。但除了人口统计学信息外,基本使用了多热(Multi-hot)向量的表示形式。这些向量拼合在一起形成了高维的单次住院病历原始向量表示。此外,脏数据的处理也因类别而异。
经过预处理得到的用于病人表示学习的序列化住院记录数据统计如表1所示。其中,辅助字段包括唯一标识病人的EMPI字段、唯一标识住院记录的HospitalID字段以及入院时间、死亡情况等用来帮助整理序列化电子病历信息和生成标注的信息。
由于仅一次住院的病人不符合本文序列化数据的特点,并且在后续预测任务中无法构成有效的训练数据,因此本文舍弃了仅一次住院的病人。
排除少于两次就诊的患者,本文最终留下了10 898名住院患者记录和4 682名患者,中位随访时间为0.96 a(四分位间距为0.31~2.19 a),其中568名患者(12.1%)在医院死亡,而剩下的患者很难跟踪。

表1 病人住院记录中的维度分配
4 结果与分析
4.1 实验准备
4.1.1 采样策略
电子病历数据通常只记录在院死亡人数,而大多数患者在不治之后选择出院或者转院,亦有心衰病人突然死亡而没能及时入院的情况,所以实际上可观测到的死亡病例数量非常有限。本次实验所采用的10 898条住院记录中,共有4 682个病人,其中死亡病人仅568例,生存病人(正例)与死亡病人(负例)的数据极其不平衡。数据不平衡对分类器的性能会造成很大的挑战,因为分类器会更倾向于训练数据量大的类别。同样的问题,也存在于一些低频的疾病中。一些疾病在实验数据中仅出现了较少的次数,与常见疾病相比,分类器更倾向于这些常见疾病。本文在预测前先进行一次下采样以平衡数据集中正负例的个数。

Fig.3 Pre-experiment:(a) Sampling Strategies Selection; (b) Classifiers Selection图3 前置实验 (a)采样策略选择;(b)分类器选择
本文对比了8种传统的下采样方法,如图3(a)所示,其中Raw表示未进行采样的实验数据。采样方法的评价指标采用支持向量机(Support Vector Machine,简称SVM)分类器预测180 d死亡时的AUC值。其中,NearMiss的AUC值最高,为0.670 9,表现优于第2名的ClusterCentroids下采样方法(0.626 4)。在后续实验中,若遇到数据不平衡时,若非具体说明,均使用了NearMiss下采样。同时,Raw数据在预测中的表现最差,这也说明了采用下采样算法的必要性。
4.1.2 分类器选择
为了验证本文表示学习方法的有效性,本文将训练得到的病人向量表示作为特征,通过分类器完成两项预测任务,分别是预测该病人在180 d后是否死亡,以及预测该病人的并发疾病。本实验对比了6种分类方法以选择一个最有效的分类器,对比的方法包括K近邻(K-Nearest Neighbor,简称KNN)、支持向量机、朴素贝叶斯(Naive Bayesian,简称NB)、随机森林(Random Forest,简称RF)、梯度上升决策树(Gradient Boosting Decision Tree,简称GBDT)、逻辑回归(Logistic Regression,简称LR)。实验结果如图3(b)所示。其中,SVM的分类效果最好,为0.6709,在后续实验中,若非具体说明,均使用了SVM作为分类器。
4.2 180 d死亡预测
4.2.1 观测窗口大小选择
为了评估本文基于时间序列的病人表示学习方法的有效性,本文与文献[11]所提出的单次就诊自编码器(简称DeepPatient)在180 d死亡预测任务上进行对比。同时参照文献[11],我们还对比了另外3种传统特征学习方法,分别为主成分分析(Principal Component Analysis,简称PCA)、高斯混合模型(Gaussian Mixed Model,简称GMM)和K均值(Kmeans)算法。传统的方法需要确定观测窗口大小,为了对比不同窗口大小的影响,进行了由不同窗口大小下使用传统特征选取方法生成的特征的180 d死亡预测对比实验。文献[5,11]提到医疗任务中窗口大小通常设置在30 d、60 d至180 d。评估数据集得知,往过去回顾指定天数的时间区间内,存在其他记录的记录数如表2所示。

表2 不同窗口大小记录数统计
如表2所示,每一行中的记录数表示在该窗口大小下,往过去回顾指定天数的时间区间能获取到住院记录的记录数。例如,第一行表示有4 989次住院记录的前180 d内还住过院。结合每个窗口大小相应的记录数,为了渐进地表示数据的丰富性,将窗口设置为30 d、60 d、90 d以及180 d。
SVM分类模型使用不同的特征提取算法在不同窗口大小下生成的特征,其180 d死亡预测结果如表3所示。其中,Sum表示原始的观测窗口内向量线性相加生成的特征,PCA、GMM、Kmeans、DeepPatient分别表示在窗口特征上作相应降维后的特征。随着窗口大小的增大,数据量增加,数据所包含的信息也相应增加,分类模型的AUC也逐渐增加(只有DeepPatient方法在窗口大小为60 d时不符合规律),基本没有出现预期中过于久远数据对当前病人的病情预测进行干扰的情况。由此,后续实验设置窗口大小固定为180 d。同时,该实验可以看到虽然其他方法的AUC值不断增高,但始终不及本文方法生成的特征(由于本文方法不存在窗口选择的问题,故AUC值均为0.754 8),差距始终在0.1以上。
4.2.2 180 d死亡预测评估
本实验将病人表示向量作为特征与其他方法获得的特征进行病人死亡预测对比。实验结果如表4所示。从实验结果中我们可以看到,本文方法在住院病人死亡预测上获得了0.754 8的AUC值,显著高于其他算法(平均高了0.15左右)。
特别地,本实验将分类模型的阈值取0.8做特别分析。在死亡预测中,无论病人还是医生对于预测的结果的期望都是乐观的,只有正例(死亡)的准确率较高,才能保证正常的医疗行为的进行,因此取经验阈值0.8。在0.8阈值下的分类结果,本文方法的Acc值取得了最高的结果(0.759 8),F1值(0.443 6)仅比最优的DeepPatient方法(0.447 2)低了0.003 6。

表3 不同窗口大小下的预测对比
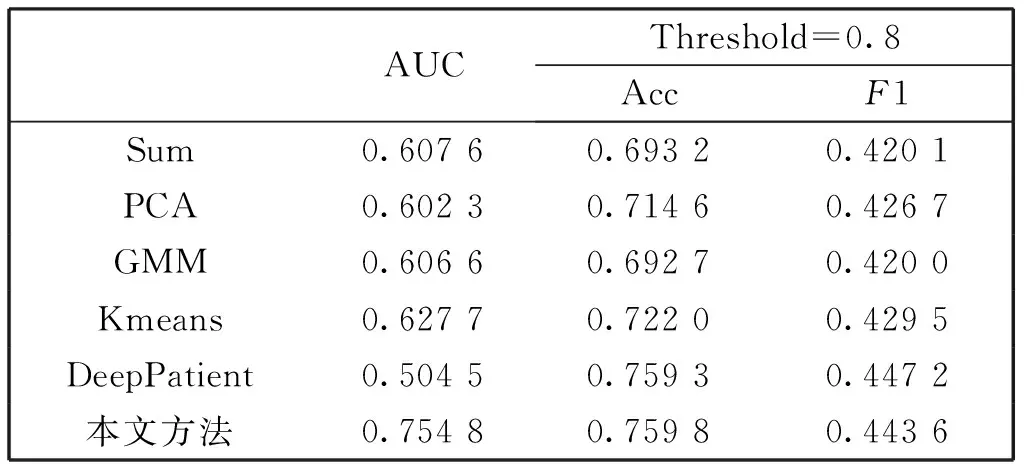
表4 死亡预测实验结果
4.3 并发症风险预测
4.3.1 并发疾病预测AUC评估
本实验对比本文得到的病人表示向量与其他方法获得的特征,预测病人并发疾病风险的优劣,实验结果如下表5所示。本实验预测的对象是10种常见的心衰患者的并发疾病,疾病如第一列所示。特别地,一些疾病由于其出现在实验数据集中的样本较少,当其低于30%时,本文采用了Near-Miss进行采样。
表6中实验结果为各个方法所得特征在各个疾病风险预测上的AUC值。其中加粗代表最优和次优。由实验结果可知,本文的方法在4项疾病预测中排名第一,2项疾病预测中排名第二,明显优于其他特征学习方法。DeepPatient和GMM方法则仅次于本文方法,分别获得3项第二、1项第一和1项第一、4项第二。当然,本文的方法并不是在所有疾病预测中都占优,有些疾病在其他方法上预测更佳。然而,本文方法最大的优点在于不需要手工进行特征选择。而且本文在实践中发现,其他方法经常受限于窗口大小的选择,不同的窗口大小会影响分类效果,不及本文的方法简单方便。因此本方法仍然是疾病预测的最佳选择。
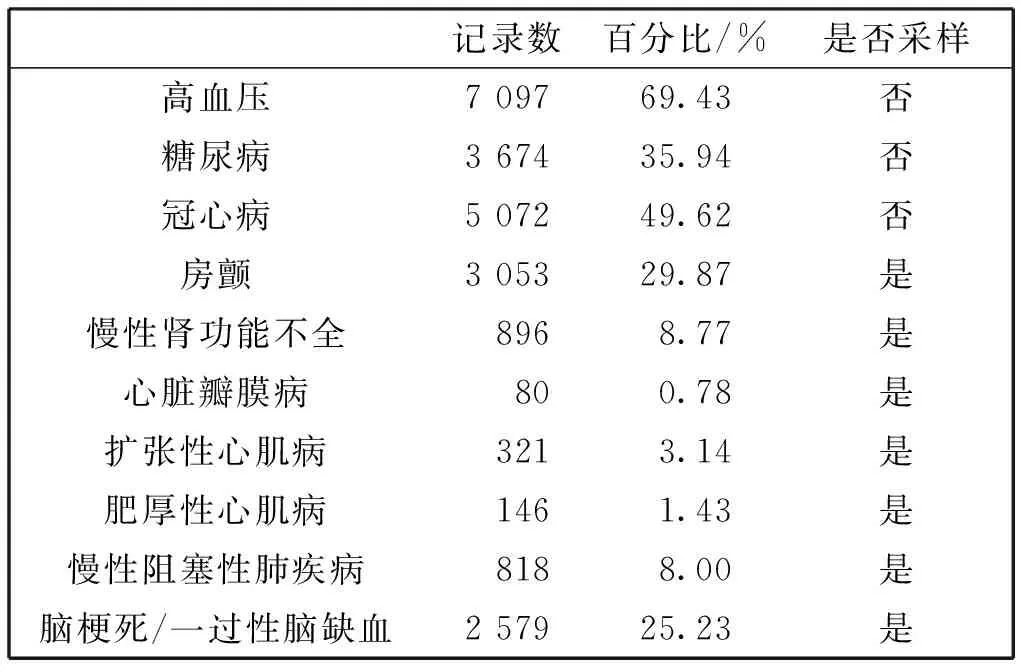
表5 疾病采样分析

表6 疾病预测实验结果
4.3.2 并发疾病预测Prec@k评估
本实验对比本文得到的病人表示向量与其他方法获得的特征,预测病人的Prec@1、Prec@2、Prec@3上的优劣,其中Prec@k表示每个病人预测出的前k个疾病(根据预测概率排序)中包含标准结果的平均个数,其结果如表7所示。特别地,部分预测的标准结果少于3种上述疾病,甚至不存在任何一种疾病。亦即,预测的标准结果中就不存在前k个疾病,而分类模型在预测的时候无法预测到疾病的空缺。因此Prec@k存在理论上界,即不可能达到100%。Prec@1、Prec@2、Prec@3的理论上界如表7中所示。由实验结果可知,本文的方法在Prec@1、Prec@2、Prec@3的对比中都发挥出了最优的表现,其结果分别为0.616 6、0.513 9和0.418 5。和上一节一样,本文的方法仍没有受限于分类窗口的选择,仍是疾病预测的最佳选择。

表7 Prec@k疾病预测实验结果
5 结论
本文使用RNN自编码器将时间序列化的电子病历数据编码为定长的通用的病人向量表示。实验表明,相较于其他特征学习方法,本文提出的向量化的病人表示在心衰患者死亡预测和并发症预测任务中有着更好的表现。对于未来的工作,我们计划将电子病历数据中的更多信息囊括进来,包括病历文本数据中的症状和疾病史等。同时,也可以尝试将本文方法迁移至其他疾病领域。
