创新构想话题生成
2019-02-15陈丽娟兰艳艳庞亮李家宁郭嘉丰徐君程学旗
陈丽娟,兰艳艳,庞亮,李家宁,郭嘉丰,徐君,程学旗
(中国科学院计算技术研究所,中国科学院网络数据科学与技术重点实验室,北京 100190)
0 引言
随着互联网2.0时代的到来,用户不仅从互联网获取海量信息,其参与程度和互动也代表了当前的社会舆论方向,对互联网经济的发展起着推动作用。用户通过自身的言论,比如对一个科技热点的关注和议论,推动着一些领域和互联网经济的发展。例如,AlphaGo,第一个击败人类职业围棋选手,第一个战胜围棋世界冠军的人工智能程序。在群众热议中,不仅推动着围棋领域的发展,同时引领了一波人工智能学习热潮,使得更多研究更加关注深度学习和强化学习[1]。
因此这样的话题不仅对互联网经济起着重大作用,甚至对推动科技发展有着巨大的潜力。因此根据以往的互联网信息,生成具有引导性的话题有着重要意义,我们将这一类话题称之为创新构想话题。
创新构想话题,是指具有以下特征的话题:在指定的时间段内,能够获得公众的关注,并能自主激发科技群体围绕其展开讨论的热情,具有推动科技发展甚至使构想落实为现实的潜力。由于其对创新性和时效性的要求,创新构想话题智能生成应能够密切关注科技界最前沿的信息,准确分析已有及新兴科技关键词的发展态势,对潜在可能成为公众关注焦点的话题具有一定程度的预判能力。
创新构想话题与新闻标题和主题不同,新闻标题通过陈述句来描述一件已经发生的新鲜事情来吸引用户的眼球;而创新构想话题则是基于已有知识、已发生的客观事实,以怀疑探索的语气去询问参与构想话题的讨论人,语句一般对话题的创新性有方向性的引导,从开放的网络知识资源中生成具有新颖性和热度性的前沿热点科技问题,推动人与人之间的交流引起用户共鸣。例如AlphaGo这个热点上,新闻一般会用如下方式去阐述该事实。
例“AlphaGo在围棋领域击败人类。”
这种新闻标题描述虽然基于客观事实,但描述方式是用简单的陈述方式,不能更大程度上引起用户的讨论热情,而且大多数新闻标题都是根据新闻内容人工撰写。本文则希望基于已有的互联网资源,挖掘数据中潜在的话题,能自动生成类似如下的话题:
例“如何看待AlphaGo战胜人类?”
例“AlphaGo战胜人类意味着什么?”

Fig.1 Framework of the generation of creative concept topic图1 创新构想话题生成框架
上述的例子以询问的方式提出话题,引发用户思考和讨论。并且基于原始数据的核心内容自动生成创新构想话题,无须人工参与资源阅读,可以大量提取潜在的可能引起关注和讨论的话题。
创新构想话题任务不仅要求自动生成上述形式的话题,还需要话题的客观基本属性,例如:标题、摘要、主题、类型、所属领域、生成时间等元数据。该任务从信息获取到最终生成完整的创新构想话题的过程如图1所示。
数据采集主要面向两种信息源:科技问答社区以及文献资料库。科技数据分析工具主要用于关键字抽取和内容摘要的生成,其中主要采用TextRank[2]算法。创新构想话题生成模型则是利用上述原始数据和数据分析工具得到的摘要,基于Encoder-Decoder[3]框架生成创新构想话题。
创新构想话题生成任务,最重要两部分分别是数据分析工具和创新构想话题生成。其中数据分析工具主要包含关键词提取和摘要生成算法。关键词提取算法有如下:TF-IDF[4]、TextRank、LDA隐变量生成模型[5]等。其中TF-IDF通过计算TF*IDF,来衡量词在一篇文档中的重要程度,从而达到提取关键字的作用。其中TF(Term Frequency)是词在文档中出现的频率,IDF(Inverse Document Frequency)逆文档频率是DF(文档频率)的倒数,弥补了TF中常用词的干扰,TF-IDF算法思想比较简单,但在实际中具有广泛的应用,本文采用该算法进行关键词抽取。
自动文摘生成分为抽取式自动文摘[6-7]和生成式自动文摘方法[8]。因为本文中在训练创新构想话题模型时,是利用摘要作为训练输入,所以采取TextRank算法对数据进行摘要提取。TextRank属于抽取式自动文摘生成,文摘中的句子是从原文中抽取得到,不对原文句子进行修改,可以尽量保留更多原文的信息。
话题生成模型主要分为传统的机器学习方法和深度学习方法。本文采取了深度学习中的话题生成的方法,主要基于Encoder-Decoder框架[9]。首先利用Google的word2vec[10-12]算法,对预处理后的文本进行词向量的学习,作为模型的输入,在话题生成方面,基于该框架还引入了注意力机制,找到输入数据中显著的与当前输出相关的有用信息,从而提高输出的话题的质量。对模型进行训练,模型的输出就是整个任务最重要组成部分,即生成的创新构想话题。
1 数据采集工具
创新构想话题的生成需要大量数据作为驱动,对模型进行训练学习,所以需要对相关领域的数据进行采集,任务主要面向科技领域,科技数据采集主要面向两种信息源:科技问答社区以及文献资料库。
数据采集主要面向科技问答社区。以网易为例,其下设有人工智能话题专栏,凡是与人工智能相关的讨论大部分都收录在这个栏目下,且绝大多数内容都与人工智能主题相关;其帖子以问答的形式给出,标题大部分是可供讨论的话题形式,这为本文提供了很好的话题样板来源。面向科技问答社区的数据采集工具主要负责周期性地从问答社区中抽取更新的帖子,包括帖子标题和内容以及发布时间。
文献资料库主要包括各大重要会议、期刊以及预印本上发布的文献信息。文献资料主要提供文献的标题、摘要、作者、关键词与正文。尤其从标题、摘要与关键词中结合发布时间信息即可分析得到科技关键词的演变态势,为候选热点关键词的分析抽取提供了丰富的材料。基于文献资料知识图谱[13],面向文献资料库的数据采集工具主要负责定期访问相关知识图谱接口,抽取新发布文献中的标题、摘要、作者、关键词和正文信息。
2 数据分析工具
在对获取到社区问答数据和文献资料库数据进行分析前,需要对数据进行预处理。对文本内容进行分词,本文主要采用jieba分词,同时对分词后的文本去除停用词,作为数据分析工具的输入。
数据分析工具主要包含两个方面,一方面是科技数据关键词的抽取,采用了TF-IDF算法提取若干关键词,另一方面是科技数据摘要生成,采用了TextRank算法进行抽取式自动摘要生成。
2.1 关键词抽取
关键词抽取主要负责从科技数据中抽取关键性的、可以作为话题研讨核心的科技实体词。TF-IDF是计算文本相似度中最为典型的一种方法,由于衡量一个词在文档中的重要程度。
(1)词频(Term Frequency,TF),就是某个词汇出现的频率,具体来讲,就是词库中的某个词在当前文章中出现的频率,可以用如下式计算。
(1)
其中,TFi,j为词汇j在文档中i中的出现频率,ni,j为词汇j在文档i中出现的次数。词汇在文档中出现的频率越高,TF值越大,它和文本的主题内容越相关,可视为文档的关键词。但是这个指标容易受常用词干扰,比如:因为、所以、然后等连词,这类词汇的TF很高,所以仅仅使用TF来衡量词汇的重要性是有缺陷的,所以引入了IDF。
(2)逆文档频率(Inverse Document Frequency,IDF),某个词汇在多篇文档集合越频繁出现,例如常用词,该词汇的区分能力越差。例如:在一个文本集合中,词汇A在100篇中文本出现,词汇B在10篇文本中出现,则词汇B比词汇A更具有区分度。其中逆文档频率IDF就是一个词在整个文库词典中出现的频率,计算方式为:
(2)
其中,IDFi表示词语i的逆文档频率,|D|是历史数据中的文件总数,分母是出现词语i的文档总数,+1是为了防止分母为0。
根据TF-IDF计算公式,关键词在文档中出现频率越高,或者包含该关键词的文档数越少,则TF-IDF得分越高,按照TF-IDF对文档中的词进行排序,选取若干个排序最靠前的词作为文档的关键词。
2.2 摘要生成
通过网站爬取的数据,有时候存在大量的数据冗余和垃圾信息,文献数据正文大都是长篇幅,所以生成历史数据的摘要可以方便用户判断是否阅读该话题相关的原文。本文中将生成的摘要作为创新构想话题的属性,用于描述创新构想话题相关的内容细节,方便用户决策是否参与该话题的讨论。同时生成的摘要长度也有利于创新构想话题生成模型的学习。本文主要采用TextRank算法进行抽取式自动摘要生成,尽可能保留原文的信息。
TextRank算法由PageRank算法[14]延伸而来,是一种基于图形的文本处理排名模型。本文在TextRank算法基础上,通过无监督的方法进行关键句提取,从而组合形成原文的摘要,不需要事先对多篇文档进行学习训练。
图的排序算法的核心是绘制全局信息,通过顶点的重要程度来提取顶点的信息。而顶点的重要程度不仅取决于链接到该顶点的结点个数,还取决于链接结点的重要程度,当一个顶点链接的结点数越多,并且链接的结点的重要程度越高,那么该顶点就越重要。
自然语言文本要利用图的排序思想就需要构建文本的图。在摘要生成中,基本元素是句子。所以文本的图排序构造可以归纳为以下三步。
(1)把给定的文本按照完整句子进行分割,即T=[S1,S2,…,Sm]将每个句子作为基本单位,并将其视为顶点添加到图形中。
(2)根据文本识别句子之间的关系,绘制出顶点与顶点之间的连接边。
(3)迭代直至图的排序算法收敛。根据顶点的最终得分进行排序。
摘要生成则是选出上述一定数量的关键句,并将关键句按照原始文本的顺序进行组合,形成文本的摘要。所以TextRank算法中最关键的部分在于如何定义句子与句子之间的关系,即如何确定构建的文本图中的边与边之间的关系,以及如何对构造的图进行迭代。可用下式来确定两个句子是否存在“相似性”。
(3)
其中Si,Sj分别表示两个句子,ωk表示句子中的词语。分子部分表示的是同时出现在两个句子中的词的个数,分母是对两个句子中的词的个数的对数求和,分母的设计可以缓和长句在相似度计算上的优势,达到长短句之间相似度计算的平衡。
根据式(3)可以计算任意两个句子结点之间的相似度,根据阈值去掉相似度较低的边连接,构建得到以句子为基本单位的有权无向连接图G=(V,E).在此基础上计算TextRank值,有权图G=(V,E)有点集合V和边集合E组成,图中任意两个顶点Vi和Vj之间边的权重为ωij,对于给定顶点Vi,ln(Vi)指向该结点的点集合,Out(Vi)为Vi指向的点集合,所以类似PageRank可以用下式计算TextRank值:
(4)
其中WS(Vi)为第i个句子的重要性(TextRank值),d是阻尼系数,一般设置为0.85,图中顶点的值初始化为任意值,然后根据式(4)迭代至收敛。根据TextRank值文本中的句子进行排序,选出对应值最高的结点对应的句子作为摘要,本任务中规定生成的摘要长度不超过100个字符。
抽取生成的摘要不仅作为创新构想话题的属性,对创新构想话题进行解释描述,同时作为创新构想话题生成模型的输入。因为提取到的摘要与文本主要内容高度相关,在摘要基础上生成话题,可以避免原始文本中关联性低的句子的干扰,同时摘要的句子过长,不利于创新构想话题生成模型的训练和学习,其得到的话题结果往往不太理想,所以本文用提取的摘要作为下一步的输入。
3 创新构想话题生成模型
创新构想话题生成主要负责将生成的文本摘要转化成一个话题的表述形式,多以询问或者试探的语气表述,起到引发用户共鸣进而产生讨论热情的效果。与TextRank抽取式方式不同,TextRank是通过原文中抽取来构成结果,而话题生成模型需要“理解”文档,生成新的话题,挖掘文档背后更深入的问题,这种方式更接近人工生成话题的方式,是该任务实际操作中希望达到的效果。
创新构想话题生成模型属于生成式的模型,基于深度学习Encoder-Decoder框架,完整的模型框架如图2所示。

Fig.2 Model of the generation of creative concept topic图2 创新构想话题生成模型
模型主要由三个部分组成,Encoder层,Control层和Decoder层。Encoder层对摘要中的每一个句子进行编码,得到每一个句子的表达向量;Control层从每个句子的表达得到摘要的上下文表达向量;Decoder层对摘要的表达进行解码,生成与摘要相关的创新构想话题。
3.1 Encoder层
关键定义假设提取的摘要S有k个句子,表示成{S1,S2,…,Sk}.作为整个模型的输入。Si是第i个句子,表示成{x1,x2,…,xT},包含T个词,每个词用Google的word2vec算法得到每个词的词向量[15]表达为{x1,x2,…,xT},然后最终生成的摘要为Y={y1,…,yN}.
3.1.1 词向量
利用相关语料的上下文信息,通过神经网络模型,最大化语言生成概率获取词的词向量,在自然语言处理研究领域被广泛地应用。该层利用分词预处理后的预料作为word2vec模型的输入,输出所有单词的低维向量表达。本文选用基于负采样的Skip-gram神经网络模型训练词向量,用词来预测上下文,即认为语义越接近的词,上下文语境也越接近。该模型包含三层结构:输入层、投影层和输出层,如图3所示。

Fig.3 Neural network model of Skip-gram图3 Skip-gram神经网络模型
3.1.2 Encoder阶段
Encoder阶段就是在得到原文的词向量后,对摘要中的每一句话进行编码,将句子转换为中间语义表示。因为语义需要保留句子完整的信息,所以采用循环神经网络(RNN)对摘要中的每一句话进行编码。RNN在实际应用有很多变种,本文采用LSTM(Long-Short Term Memory)可以有效地防止梯度爆炸的问题,其主要由记忆单元(memory cell)、输入门(input gate)、输出门(output gate)和遗忘门(forget gate)组成,对于{x1,x2,…,xT},LSTN在t时刻的输出向量ht可以用如下方法计算:
it=σ(Wxixt+Whiht-1+bi)
ft=σ(Wxfxt+Whfht-1+bf)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
ot=σ(Wxoxt+Whoht-1+bo)
ht=ottanh(ct),
(5)
其中,i,j,o分别表示输入门,遗忘门和输出门,c表示从记忆单元的信息h中得到的表达。通过LSTM可以得到第i个句子{x1,x2,…,xT}的中间语义表示{h11,h21,…,hT1},最后一个隐状态hT1则认为是该句子的最终表达,因为它包含了该句子上下文所有的信息。用上述方式对摘要中的所有句子进行Encoder,取最后一个状态作为每一个句子最终的表达,则可以得到所有句子的隐状态表达{hT1,hT2,…,hTk},其中hTi,表示第i个句子编码状态。
3.2 Control层
在提供了文本摘要每个句子的编码表达下,需要获取有关上下文句子的表达。所以{hT1,hT2,…,hTk}作为Control层的输入,双向的LSTM(Bi-LSTM)同时从两个方向考虑了先前的句子和后文的句子。希望生成的话题是和上下文高度相关,所以采用Bi-LSTM处理输入,即
(6)

3.3 Decoder层
关键定义根据Control层得到的和上下文相关的句子隐状态表示,Decoder层要根据这些中间语义,解码得到本文任务需要的创新构想话题。希望利用到Control层得到的所有位置的表达,同时又有侧重点,所以在解码时候,使用了注意力机制[16]。解码阶段每产生一个词都是基于Control层的得到的表达和前面已经产生的词共同决定的,即
yt=argmaxP(y′|{y1,…,yt-1},ct;θ).
(7)
在主流的解码模型中,不论输出第几个词汇,ct都是一样的,且ct对于整个输入而言,表达要足够好,才能利用固定长度向量表示整个摘要的信息。任务中使用了注意力机制,允许在解码阶段关注输入的不同部分,也就是对于产生不同的词汇而言,状态ct是变化。
etj=g(St-1,hcj)
(8)
(9)
(10)
St=f(St-1,yt-1,ct),
(11)
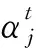
3.4 模型训练
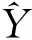
由公式(7)已知输出序列Y的输出方式,所以整个模型的优化目标如下式
(12)
创新构想话题生成模型选择Adam[17]进行优化训练,对训练样本进行迭代训练,其中损失函数是生成训练集D上的创新构想话题的负对数似然,
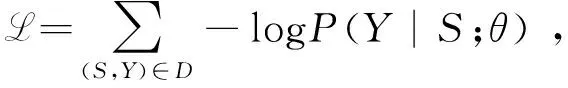
(13)
其中S,Y是训练集中的一条样本,S是文本内容,Y是与话题相关的文本内容。
4 实验结果
4.1 数据集描述
本文实验采取的训练集是实时从网络爬取的新闻内容,以网易人工智能板块为例,训练集的每个样本包含话题和正文内容。
4.2 模型的参数设置
词向量设置为100维,模型的Encoder层的LSTM和Control层的双向LSTM的隐藏状态设置成h=256。学习率设置成0.000 5,训练过程采用Adam优化方法,批量大小设置成16。
4.3 实验结果
在爬取到的新闻中,包含新闻标题和原文,作为模型的输入,完整的结果将包括生成的话题,关键词和新闻摘要。任务生成的完整结果如表1所示。

从表1展示的例子,整个任务可以生成完整的结果,得到的关键字和原文标题内容相关,生成的话题以询问的方式引发用户思考,抽取的摘要也能涵盖新闻的大体内容。所以本文方法可以很好地从新闻内容中,自动提取到创新构想话题。
表2展现了若干从网易人工智能板块数据中,自动生成的一系列话题,可以发现生成的话题语义清晰,表达流畅。生成的话题具有新颖性,不仅生成与人工智能领域有关的话题,还涉及人工智能领域对生活的影响,挖掘出新闻内容下更丰富的话题,能更大程度上引起用户的兴趣。
5 结论
本文提出了创新构想话题的任务。该任务对激发用户讨论热情,推动相关领域发展有着积极作用。该任务主要通过网络爬虫获取相关科技数据以及通过指定接口获取相关文献数据。对获取的数据进行相关预处理;然后利用科技数据分析工具获取关键词并生成摘要;最后利用创新构想话题生成模型生成具有引导性的话题。并根据任务需求,生成指定的数据格式,作为系统的接口。该任务对潜在可能成为公众关注焦点的话题具有一定程度的预判能力。对相关领域发展可以起到良好的推动作用。

表2 网易数据生成的创新构想话题
