基于模糊聚类分析方法的高含水期油藏层系优化
2019-02-04李小波刘威李健
李小波 刘威 李健

摘 要:针对高含水期油藏的层系优化问题,提出了一种基于模糊聚类分析的方法,阐述了在高含水期油藏层系优化过程中的使用过程,并实际验证应用效果。研究表明:使用模糊聚类分析方法以后,各层之间的矛盾明显减少,且各层系都具有一定的原油储量和厚度,各油井都具有一定的产能,每个层系都可以成为独立的开发系统。
关 键 词:模糊聚类分析;方法概述;应用步骤;高含水期油藏;层系优化
中图分类号:TE 151 文献标识码: A 文章編号: 1671-0460(2019)11-2630-05
Optimization of Reservoir System in High Water Cut
Period Based on Fuzzy Clustering Analysis
LI Xiao-bo, LIU Wei, LI Jian
(China Petroleum Exploration and Development Research Institute, Beijing 100083, China)
Abstract: In order to optimize the layer system in high water-cut reservoirs, a method based on fuzzy clustering analysis was proposed. The use process of this method in the reservoir layer optimization process in high water cut period was expounded, and the application effect was verified. The study showed that after using the fuzzy clustering analysis method, the contradiction between layers was significantly reduced, and each layer had a certain amount of crude oil reserves and thickness, each well had a certain capacity, and each layer became an independent development system.
Key words: Fuzzy clustering analysis; Method overview; Application steps; High water cut reservoir; Layer optimization
对于我国油田而言,由于地层压力不足,因此必须采取加压采油方案,一般来说,我国大多数油田都是采用注水的方式增加地层压力[1]。随着油田注水时间的不断增加,大多数油田已进入高含水期阶段。高含水油田普遍具有层间干扰严重、地层剩余原油较为分散等问题,直接造成油田单位的采收率下降,原有的层系组合方式不能满足采油的需求[2,3]。因此,十分有必要对高含水期油田进行层系优化,为提高采油效率奠定基础。
目前,国内外众多学者对层系优化问题进行了深入研究,并取得了一定的成果。2011年,曾雪梅等[4]根据原油开发中面临的众多问题,结合影响原油采收率的相关因素和地层的层系特征,对层系进行了重新优化,使得层系与井网之间紧密结合,具有提高采收率的效果,但是该研究所考虑的地层因素不足,因此,提高采收率的效果十分有限;2012年,代兴斌等[5]对萨中油田地层内剩余油的分布情况进行了调研,根据油田井网的分布情况,提出了二次开发的层系优化方案,该研究为萨中油田的二次开发奠定了良好基础,但是该研究具有很强的针对性,所提方案对于其它油田并不适用;2014年,周羽佳等[6]对杏一区油田的地层特征进行了调研,并对层系进行了细分和优化,层间干扰得到了降低,使得开发效果得到了提高,在该研究中,所考虑的因素相对较小,同时所提方案也具有很强针对性。
通过以上分析可以发现,目前的研究主要针对特定的区块,并没有提出一种适用于大多数油田的方法,而且所考虑的因素并不完善。针对这些问题,本次研究提出了一种模糊聚类分析的层系优化方法,该方法具有一定的普适性,且所考虑的因素相对较为完善,最后,本次研究以G油藏为例进行了验证,以此证明该方法的可行性。
1 模糊聚类分析方法简介
1.1 模糊聚类分析方法概述
模糊聚类分析方法是数学中常见的一种分类方法,该种方法基于多元分析理论,目前该种方法已经在各个领域都得到了一定程度的应用[7]。模糊聚类分析方法的主要原理是:在现实中,任何事物都可以根据自身的相似性组合成一个群体,这里所谈论的相似性并没有严格的界限,可以定义成具有一定的模糊关系,而模糊聚类方法就是根据事物之间的模糊性(即无界限的相似性)进行划分,通过事物的各种特点建立模糊矩阵,使用数学的方式对事物进行分类,该种分类方法具有简单易懂且分类速度相对较快的特点[8]。
 (5)
(5)
(4)聚类分析
在实施聚类分析的过程中,需要使用上文计算得到的模糊关系![]() ,如果该模糊关系并不满足等价条件,则需要对其进行自乘处理,即
,如果该模糊关系并不满足等价条件,则需要对其进行自乘处理,即![]() ,然后再进行二次自乘,即
,然后再进行二次自乘,即![]() ,不断自乘,直到
,不断自乘,直到![]() ,当
,当![]() 满足模糊等价关系时,即可停止该过程[12]。得到
满足模糊等价关系时,即可停止该过程[12]。得到![]() ,即可根据置信水平
,即可根据置信水平![]() 的不同,进行聚类处理,
的不同,进行聚类处理,![]() 可以依次取值为
可以依次取值为![]() ,该过程的具体步骤为:
,该过程的具体步骤为:
首先假设![]() (最大值),然后对
(最大值),然后对![]() 进行相似类处理,即
进行相似类处理,即![]() ,该过程就是将满足
,该过程就是将满足![]() 的两个样本归为一类,从而形成相似类。相似类和等价类之间存在一定的区别,两个样本归为相似类,则说明两个相似类中可能含有共同的变量,即可能会出现
的两个样本归为一类,从而形成相似类。相似类和等价类之间存在一定的区别,两个样本归为相似类,则说明两个相似类中可能含有共同的变量,即可能会出现![]() ,此时就需要将两个样本中的共同变量进行合并,就可以得到
,此时就需要将两个样本中的共同变量进行合并,就可以得到![]() 的等价分类[13]。假设
的等价分类[13]。假设![]() 为次大值,在
为次大值,在![]() 中寻找相似度等于
中寻找相似度等于![]() 的樣本对,同时将样本对中共同变量进行合并,此时就可以得到
的樣本对,同时将样本对中共同变量进行合并,此时就可以得到![]() 的等价分类。以此类推。
的等价分类。以此类推。
2 G油藏模糊聚类分析方法应用
(1)评价指标的确定
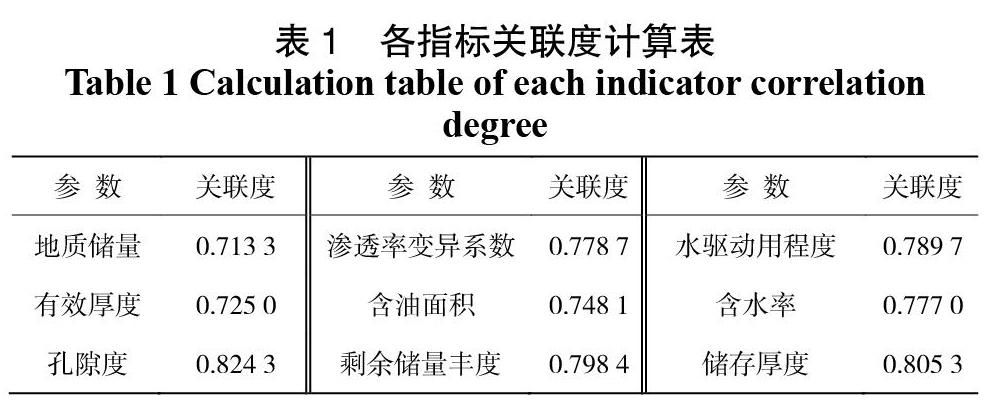
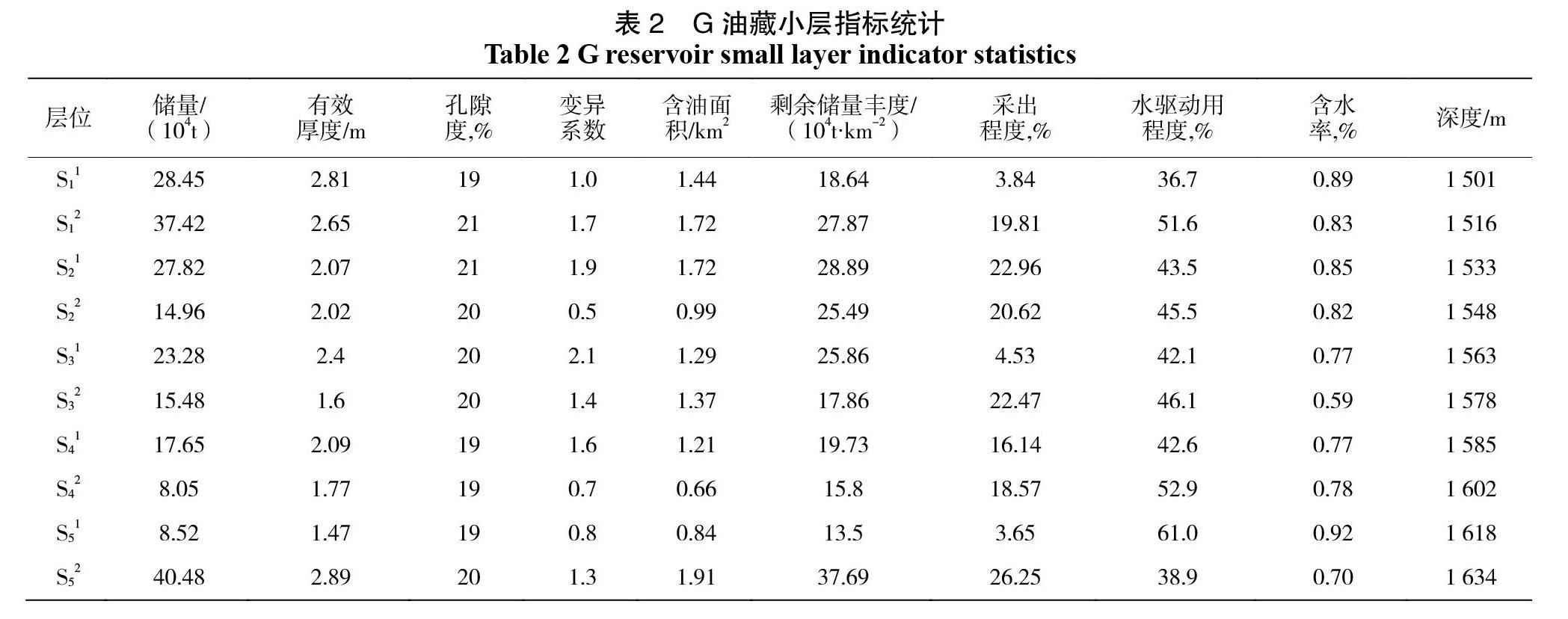
在使用上文所提到的模糊聚类方法对地层的层系进行优化时,首先需要对影响因素进行关联度分析,在另一方面,层系优化的优劣与否,将直接决定着地层原油的采出程度,因此,可以将采出程度作为该过程的母序列,将影响采出程度的因素作为子序列,计算子序列与母序列之间的关联度数值,然后确定进行模糊聚类分析的指标[14]。关联度分析的结果如表1所示。通过表1可以看出,本次选择的影响采出程度的9个因素都与采出程度之间具有良好的关联性,因此,在本次研究中,可以将这9个因素和采出程度共同作为模糊聚类分析的指标,然后将相似度较高的地层归为一套层系。如表2所示即为G油藏的相关指标数据。
(2)原始数据变换处理
由表2可以知道,进行模糊聚类分析的相关指标总共有10项,这就是进行层系优化的主要指标,由于每个指标的单位及数量级都存在差距,为了去除这种差距的影响,需要对其进行归一化处理,从而将每个指标数据都压缩到[0,1]之间。使用MATLAB软件对表2中的数据进行归一化,得到归一化数据以后,即可通过相似系数法来建立模糊聚类分析所使用的相似矩阵,使用MATLAB软件,通过相似系数法得到的相似矩阵,归一化后的矩阵和相似矩阵如下两式所示。

(3)模糊聚類
对得到的相似矩阵进行聚类处理,首先需要给出置信水平![]() ,当
,当![]() 的数值不断降低时,样本也将从细到粗的进行不断归类,根据置信水平所取数值的不同,得到的分类结果也将存在差距,在本次研究中,依次将置信水平分别取值为0.925、0.899、0.889、0.886、0.884、0.878,由此得到的分类结果如表3所示。
的数值不断降低时,样本也将从细到粗的进行不断归类,根据置信水平所取数值的不同,得到的分类结果也将存在差距,在本次研究中,依次将置信水平分别取值为0.925、0.899、0.889、0.886、0.884、0.878,由此得到的分类结果如表3所示。
根据表3所示的聚类结果可以形成6种不同的层系优化方式,但是置信水平分别为0.925、0.899、0.878时,分别存在一套层系原油的储量相对较少,一般情况下,层系优化以后,不但需要避免层间的干扰,还应保证每套层系都存在一定的原油储量,此时才能证明层系优化的结果相对较好,因此,对表5的聚类结果进行分析以后,优选出了置信水平分别为0.889、0.886、0.884时层系分类结果,最终确定了三套组合方式。
3 G油藏层系优化方案研究
目前,G油藏的剩余原油储量约为221.65万t,油藏的厚度大约为200 m,油藏的跨度相对较大,原油储层底部与底部之间的距离为1 450~1 640 m,井段的长度相对较长,如果仅使用一套井网进行后续的开发工作,则层间产生干扰的可能性相对较大, 此时会产生层间矛盾,由于不断开发以后,地层的含水率将持续上升,此时开发的难度也将持续增加,因此,必须对G油藏进行层系优化,减小层间矛盾,已达到在缓慢地层含水率的前提下提高原油采收率的目的。在对G油藏进行层系优化实际的过程中,所坚持的原则为:
(1)所提出的层系优化方案一定要简洁;
(2)每口油井的控制产量尽量要大于4万t;
(3)层系之间的矛盾必须得到显著降低;
(4)油层的动用程度一定要大于80%。
根据该油藏进行层系优化的基本原则,使用上文中模糊聚类分析后的结果,在考虑G油层开采现状的前提下,对层系进行了优化,从而制定出来三种优化方案,其结果如下表4所示:
方案1: S11-S32层共同形成一套层系,该层系的厚度为13.55 m,该层系的储量为146.93万t; S41-S52层共同形成另一套层系,该层系的厚度为8.22 m,该层系的储量为74.72万t,根据目前的开采现状,第1套层系的采出程度为15.25%,第2套层系的采出程度20.44%。
方案2: S11-S31层共同形成一套层系,该层系的厚度为11.95 m,该层系的储量为131.23万t; S32-S52层共同形成另一套层系,该层系的厚度为9.88 m,该层系的储量为104.11万t,根据目前的开采现状,第1套层系的采出程度为14.39%,第2套层系的采出程度20.79%。
方案3: S11-S12、S22-S31层共同形成一套层系,该层系的厚度为9.88 m,该层系的储量为104.11万t; S21、S32-S52层共同形成另一套层系,该层系的厚度为11.89 m,该层系的储量为118万t,根据目前的开采现状,第1套层系的采出程度为12.59%,第2套层系的采出程度21.30%。
进行层系优化以后可以发现,每一层之间都具有一定的原油储量,地层的有效厚度和单井储量也相对较好,层系与层系之间具有一定隔层,可以形成独立的原油开发系统。
4 结 论
在本次研究中,首先对层系优化目前的研究成果进行了简单分析,指出了目前研究成果的缺点,提出了基于模糊聚类分析方法的层系优化方法,对该种方法的使用步驟进行了简单介绍,然后以G油藏为例,使用该种方法进行了层系优化,验证了该种方法的可行性。通过本次研究,可以得出以下两条结论:
(1)模糊聚类分析方法可以对存在模糊关系的事物进行分析,且这种方法的使用步骤较为简单,并不需要太专业的知识就可理解,同时,该种方法还具有分类速度相对较快的特点,因此,对于石油领域存在模糊关系的样本可以使用该方法进行聚类;
(2)使用模糊聚类分析方法对G油藏进行了层系优化,共提出了三种层系优化方案,这三种方案满足层系优化的基本原则,层系优化以后,每一层之间都具有一定的原油储量,地层的有效厚度和单井储量也相对较好,层系与层系之间具有一定隔层,可以形成独立的原油开发系统,证明该方法完全可行。
参考文献:
[1]黄志双. 萨北油田三类油层注聚对象及层系优化组合研究[J]. 大庆石油地质与开发, 2006, 25(8):83-84.
[2]方艳君, 孙洪国, 侠利华, 等. 大庆油田三元复合驱层系优化组合技术经济界限[J]. 大庆石油地质与开发, 2016, 35(2):81-85.
[3]孙洪国, 周丛丛, 张雪玲, 等. 大庆油田特高含水期三元复合驱层系优化组合方法研究[J]. 长江大学学报(自科版), 2018(9):25-31.
[4]曾雪梅. 北二东开采层系重组改善水驱开发效果试验研究[D]. 东北石油大学, 2011.
[5]代兴斌. 特高含水期萨、葡、高油层井网、层系重构方法研究[D]. 东北石油大学, 2012.
[6]周羽佳. 杏一区薄差油层层系重组及开发效果研究[J]. 长江大学学报(自科版), 2014, 11(5):112-114.
[7]张敏, 于剑. 基于划分的模糊聚类算法[J]. 软件学报, 2004, 15(6):858-868.
[8]高新波, 谢维信. 模糊聚类理论发展及应用的研究进展[J]. 科学通报, 1999, 44(21):2241-2251.
[9]汤荣志, 段会川, 孙海涛. SVM训练数据归一化研究[J]. 山东师范大学学报(自然科学版), 2016, 31(4):60-65.
[10]梁家政, 薛质. 网络数据归一化处理研究[J]. 信息安全与通信保密, 2010(7):47-48.
[11]高新波. 模糊聚类分析及其应用[M]. 西安电子科技大学出版社, 2004:7-8.
[12]何清. 模糊聚类分析理论与应用研究进展[J]. 模糊系统与数学, 1998(2):89-94.
[13]鲍艳, 胡振琪, 柏玉, 等. 主成分聚类分析在土地利用生态安全评价中的应用[J]. 农业工程学报, 2006, 22(8):87-90.
[14]肖新平. 关于灰色关联度量化模型的理论研究和评论[J]. 系统工程理论与实践, 1997, 17(8):77-82.
