基于教育数据挖掘的“探索和理解”问题解决过程研究——以PISA(2012)新加坡、日本、中国上海Log数据为例
2019-01-08首新何鹏陈明艳胡卫平
首新 何鹏 陈明艳 胡卫平
基于教育数据挖掘的“探索和理解”问题解决过程研究——以PISA(2012)新加坡、日本、中国上海Log数据为例
首新1何鹏2陈明艳3胡卫平4[通讯作者]
(1.重庆师范大学 初等教育学院,重庆 401147;2.东北师范大学 化学学院,吉林长春 130024;3.重庆渝北区 天一新城小学,重庆 401147;4.陕西师范大学 现代教学技术教育部重点实验室,陕西西安 710062)
Log数据不仅包括学习时间、学习进程、鼠标和键盘敲击等静态数据,还详细呈现了从学习开始到结束的动态数据。文章截取PISA(2012)新加坡、日本、中国上海的Log数据,运用相关、滞后序列、聚类等教育数据挖掘方法分析三个国家学生在“车票”一题的“探索和理解”问题解决过程。结果发现:相比新加坡和日本,中国上海学生仍缺乏深入试题情境进行比较、探索,反映出问题解决策略不足;中国上海学生在“错误倾向组”比例过大,反映出高、低水平问题解决能力的学生呈两极分化,亟待提高低水平学生的问题解决能力。最后,文章依据研究结果在课堂教学、教育决策等方面提出了相关建议。
问题解决能力;PISA;教育数据挖掘;序列分析
一 问题提出
学习系统和人机交互平台记录学习者行为操作的日志文档(Log File)是一种重要的教育原始数据,成为分析进而改善教育过程、学习进程的突破口。对Log数据的分析是探讨教育数据背后学习行为的重要措施[1],通过对操作历程的分析,教育决策者可以精准地发现学习过程与学习结果的因果关系,更好地理解学习行为、学习模式和所属学习环境,从而帮助教育工作者改善教学过程。
在2006年试测之后,2012年的国际学生能力测试(Program for International Student Assessment,PISA)已全面在数字化环境中进行各项素养测验,包括问题解决能力。测验系统的Log数据如实记录了学习者的操作路径,为分析其问题解决过程提供了大样本。PISA(2012)报告显示[2],问题解决能力排名前7的均为亚洲国家或地区,其中新加坡学生的平均分为562分,日本、中国上海学生分别为552分、536分。为了辨别新加坡、日本、中国上海学生问题解决能力产生显著差异的来源,本研究拟深入测试题分析学生的问题解决过程,探索三地学生的问题解决行为和问题解决群组,进而为提升中国学生的问题解决能力提供切实可行的建议。
二 教育数据挖掘理念下的Log数据挖掘
Log数据挖掘从属于教育数据挖掘。依据Baker[3]、Romero[4]等的观点,教育数据挖掘是通过应用数据挖掘技术,找出学生或学习环境的特点,为提高教育产出、理解教育现象提供线索和证据,最终指导教育决策行为,其过程包括数据预处理、数据挖掘和事后处理三个阶段[5]:首先,本研究截取新加坡、日本、中国上海“车票”一题的Log数据,并转化成Excel文档进行预处理,计算行为序列数、正误情况、合并得分、最后学生权重等形成SPSS预读文档。然后,借助SPSS 22.0进行变量加权、描述统计,运用序列分析、相关分析、聚类分析等方法进行数据挖掘。按照经济合作与发展组织(Organization for Economic Co-operation and Development,OECD)建议[6],对PISA数据进行描述性统计时,需考虑抽样权重问题,因此采用其提供的学生抽样权重对变量进行加权处理。最后,根据数据挖掘结果进行事后处理,即根据问题解决行为(序列)分析结果进行解释与评估,通过探讨学生问题解决特点、产生某一学习过程的原因、学习类别的特征等因素,提出有关课堂教学等方面的建议。
三 研究样本与变量
1 PISA(2012)“Tickets(车票)”一题“探索和理解”问题解决过程
PISA(2012)主要测评15岁学生的数学素养和问题解决能力,全球共65个国家(地区)同步参与了测验。其中,共44个国家10207名学生参与PISA(2012)“Tickets(车票)”一题,产生了907760条Log数据。其中,中国上海、日本、新加坡学生1886名(18.49%)、产生Log数据25953条(2.86%)。
该题的情境是“花最少的钱购买4张城市地铁车票,由于你是学生,你还可以优惠购票(学生票)”。学生在阅读屏幕左侧的操作说明之后,便可点击鼠标在虚拟的轨道交通购票系统购买车票(操作过程如图1所示)。该题最佳操作路径是:“城市地铁”(错误操作是‘郊区火车’)—“学生票”(错误操作是‘全价票’)—“多次票”(错误操作是‘单日票’)—“4”(错误操作是‘其它数字’)—“购买”,即最少点击鼠标5次就能完成,但仅10.07%的学生如此操作且答对该题。这主要源于该题需要学生在三组选择中进行比较,购买最便宜的车票,难度较大。PISA(2012)将其设定为问题解决水平5(638分),考察问题解决过程中的“探索和理解”能力。PISA认为,达到该层次的学生能够深入探索复杂问题情景,了解相关信息结构,如面对不熟悉的、较复杂的设备(如自动售货机、家用电器),能够快速响应并掌握设备;他们能够仔细考虑约束条件,找到最佳问题解决策略,当发现意想不到的困难或偏离目标时,也能及时调整计划或返回正轨。
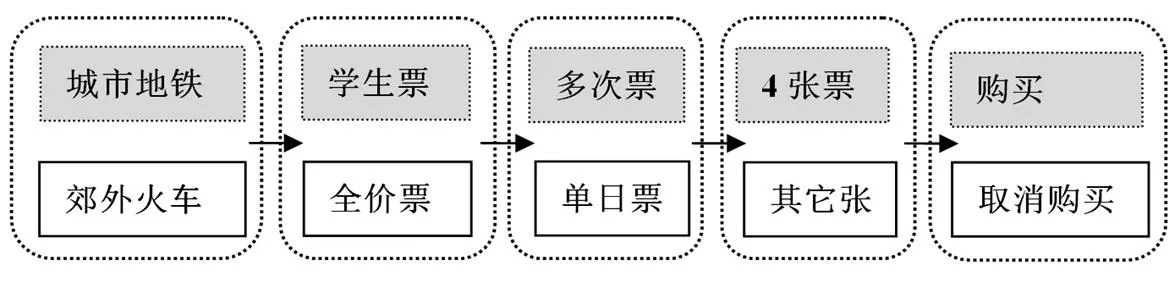
图1 PISA(2012)“TICKETS(车票)”一题操作过程(灰色为正确操作)①
2 变量选取及说明
本研究拟分析“车票”一题的Log数据探讨如下问题:①哪些行为影响个体问题解决表现?②三地学生问题解决过程有何差异?③三地学生可形成哪些问题解决群组,又有何差异?据此,本研究设计了如下变量:①“车票”一题的行为(序列),定义点击鼠标一次为一个行为,将两个连续的行为称为一种行为序列,根据“车票”一题的操作规则,实际上共产生了13种行为序列,编码如表1所示;②学生问题解决表现,根据Greiff等的建议[7],采用PISA(2012)提供的第一个似真值作为问题解决得分来表征个体问题解决表现。
表1 “车票”一题行为、行为序列编码

四 结果与分析
1 行为统计与分析
据描述性统计发现②,这三地学生13种行为序列发生频率最高的是,其次是、;发生频率较低的是、、。这一结果表明,在“城市地铁”和“郊区火车”、“学生票”和“全价票”、“多次票”和“单日票”的比较中,大部分学生能够完成前两组比较并做出正确的选择,但在第三组决策上犹豫不定,这主要缘于随着问题情境深入,探索的难度增加,部分同学随之产生了错误行为。具体而言,在中,新加坡和日本学生的人均频次均达到2次以上,而中国上海学生是人均1.3次;在中,新加坡学生人均1.4次,日本学生人均1.2次,中国上海学生人均只有0.8次。由于和反映正确行为,这说明随着问题解决的深入,中国上海学生偏离正确解题路径的概率相对较大,或者放弃了该题,这导致了行为序列的人均频次下降较快。
本研究进一步采用新复极差测验法(Duncan’s Multiple Range Test)分析这三地学生在高频行为序列、、、间的差异③。在高频行为中,日本学生行为显著高于新加坡学生和中国上海学生(MJ=1.237,MS=1.028,MQ=0.575),新加坡学生行为显著高于日本学生和中国上海学生(MS=1.408,MJ=1.219,MQ=0.874),而中国上海学生在行为、均显著低于新加坡、日本学生。由于是错误行为,是正确行为,且是两个平行行为序列,这一结果表明日本学生在进行第三组比较时(“多次票”和“单日票”),可能更倾向于错误,从该题正误率来看,日本学生的错误率高于新加坡学生(55.5%>42.4%),很可能就是这一差异引起的。在高频行为中,新加坡学生与日本学生的差异不显著,而中国上海学生与新加坡、日本学生的差异均显著,中国上海学生的行为明显低于新加坡、日本学生。由于是正确行为,是放弃错误操作的修正行为,这表明中国上海学生在探索第二组比较(“学生票”与“全价票”)的深度还不够,且在自查过程中修正错误行为的操作也有待进一步加强,否则不能修正错误行为而沿着错误路径进行问题解决,最终导致答题错误。
2 行为与个体问题解决表现的关系
Pearson相关分析显示,行为序列与个体问题解决得分的相关性为0.309(P<0.01),进一步分析得到各行为序列与问题解决表现的相关结果,如表2所示。行为、、、、、与个体问题解决表现呈弱相关(|<0.2),这些行为绝大多数是错误操作,显然不能代表个体的问题解决表现。行为、、、、、与个体问题解决表现呈低相关(0.2<|<0.4),包含1个错误行为和5个正确行为,三地学生之间差异较小。行为与个体问题解决表现呈中等相关(0.4<|<0.6),它是终结性操作,与行为可构成正确解题的关键行为序列链(“多次票—4张—购买”),可代表个体的问题解决表现,也就是说一旦学生产生该行为序列链,基本可以确定正确答题。但中国上海学生在行为的相关系数偏小,且与其它两国学生的差异较大(行为也是如此),可能正是这个关键行为序列链的差异造成中国上海学生错误答题的比例较高,最终导致问题解决表现低于其它两国学生。
表2 行为序列与问题解决表现的相关结果
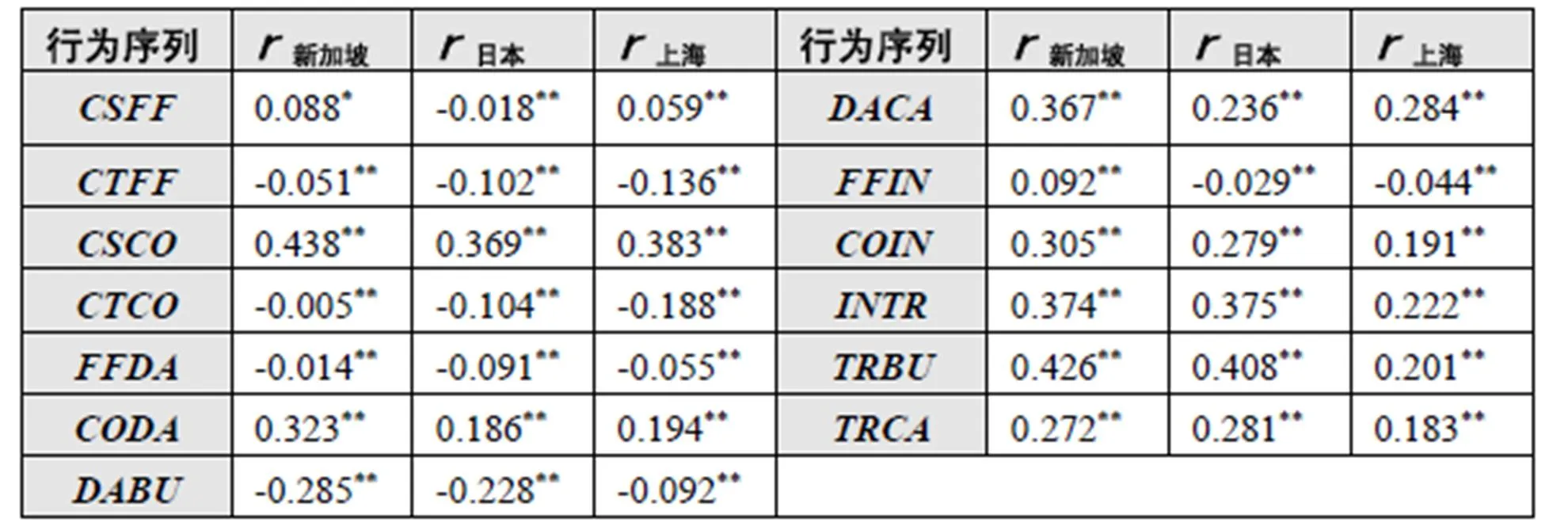
注:*p<0.05,**p<0.01。
3 显著性行为差异
本研究采用滞后序列分析寻找三地学生的显著性行为(序列),并基于这些行为构建行为序列链。此过程借助滞后序列分析软件GESQ 5.1建立行为转换频数矩阵(Z值)。一般认为,当值大于1.96,表示相应行为(序列)达到了统计意义的显著水平(P<0.05)[8]。以新加坡为例,GESQ 5.1生成的22个行为(序列)频率转换残差表如表3所示,可以发现,新加坡形成的显著性行为(序列)是,(),将显著性行为(序列)组成行为序列链——用同样的方法构建日本、中国上海产生的显著性行为序列链,得到三地学生的显著性行为序列链,如图2所示。
从图2可以发现,中国上海学生与新加坡、日本学生的显著性行为序列链差异较大。在正确链中,中国上海增加了,它是解答该题的终结性操作;在错误链中,中国上海缺少,它是放弃错误操作行为的终结性操作——可以推断,中国上海学生缺乏比较“单日票”和“多次票”的价格差异,或是比较了但没有得出结果而草草了事,所以没能成为显著性行为序列,取而代之的是能完成该题的行为。新加坡、日本出现,说明这两国学生在单日票和多次票、学生票和全价票之间不断尝试,最终理解题意,点击“Cancel”,取消错误操作,因此终结性行为相比而言就较少,没成为显著性行为序列。可见,与新加坡、日本学生相比,中国上海学生仍缺乏对题目信息的深入探索和比较,不能挖掘进而整合碎片化信息背后表达的正确结果。
表3 新家坡的行为频率转换残差表(Z-scores)
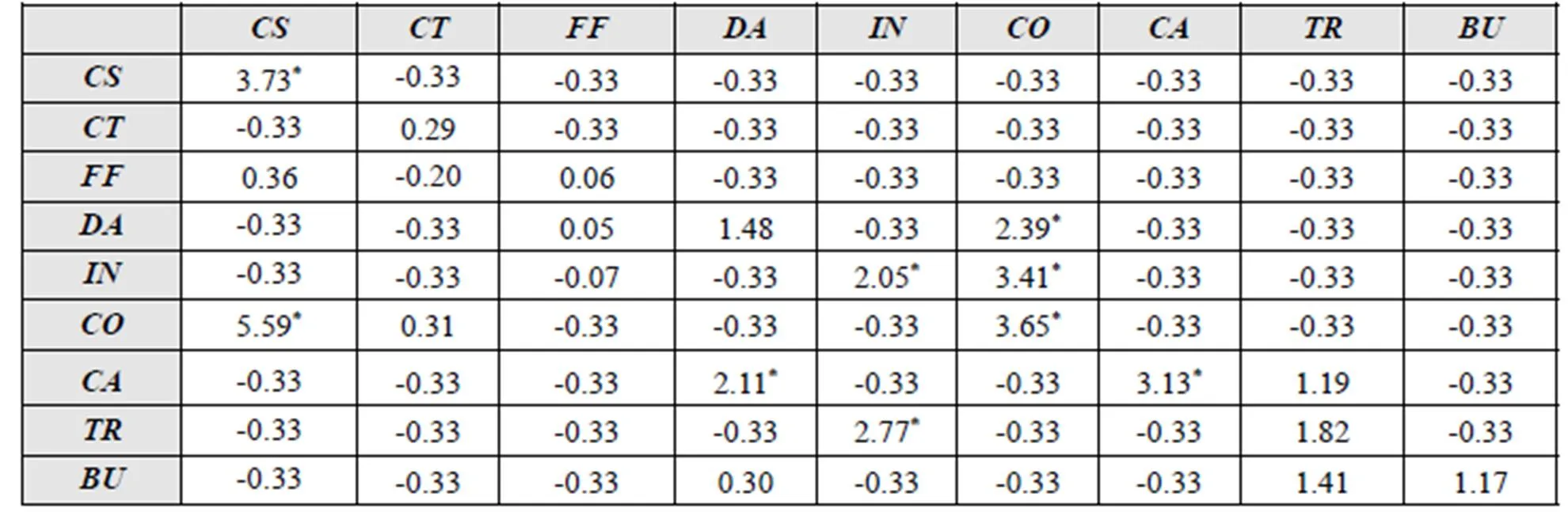
注:*p<0.05
4 群体问题解决行为群组
本研究将13种行为序列纳入分类变量,依据对数似然距离计算两个变量之间的相似性,并采用自动确定聚类数量的方式(Bayesian Information Criterion)对样本进行两步聚类分析,共获得4组稳定的聚类结果。随后,又采用滞后序列分析法寻找四类群组的显著性行为序列,考察不同群组形成的行为序列链,结果如图3所示。图3显示,群组1多是错误行为序列,足以说明这类学生问题解决能力太低,尚未理解题意就点击鼠标草草了事,或信息技术素养太差,不知如何点击鼠标答题等,正确率极低;群组2包含少量正确行为序列,说明这类学生正在试图理解琐碎信息背后的结果,能够进行自查和反思,但倾向于漫无目的地点击鼠标而没有形成正确的解题策略,导致正确率不高(44.12%);群组3包括正确和错误行为序列,说明这类学生能够通过不断尝试错误,大部分能寻找到有效信息,虽然花费较长的作答时间,但能通过探索错误信息而理解题意,透过不断的自查而避免错误,正确率较高(88.35%);群组4都是正确行为序列,说明这类学生通过少量的错误行为便能做出正确判断,快速理解题意,做到了既快又准,正确率也较高(83.21%)。综上,群组1是“错误倾向组”,群组2是“随机检查组”,群组3是“全面检查组”,群组4是“正确倾向组”。
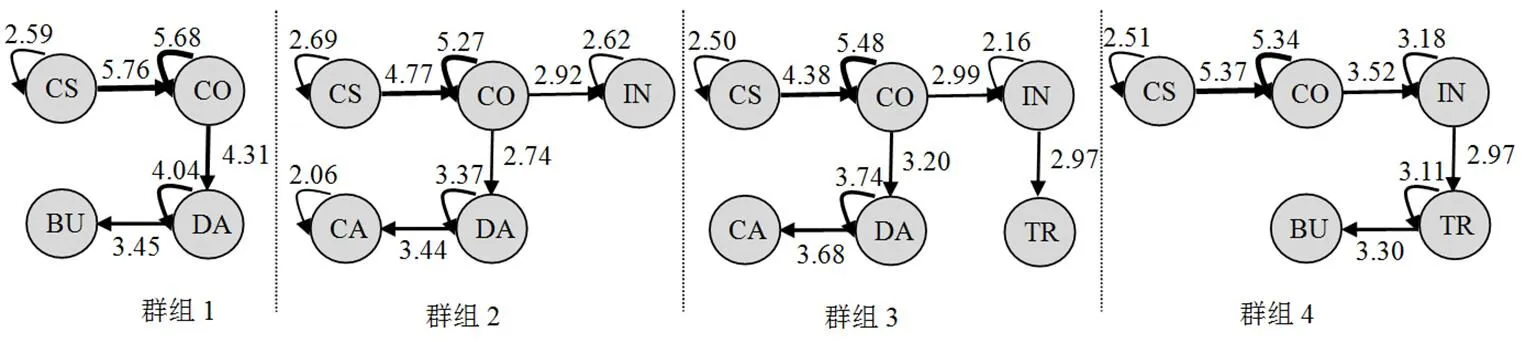
图3 “车票”一题形成的问题解决群组(数字表示Z值)
最后,本研究对三地学生形成的问题解决群组进行统计分析④。整体而言,三地学生“错误倾向组”占比最大(40.8%),这是由于PISA(2012)将该题列于水平5,对部分学生来说仍有一定难度。“全面检查组”、“正确倾向组”占比相当(23.8%、22%),“随机检查组”占比最小(13.8%),说明能反思和自查的学生大部分能答对该题。另外,错误倾向组、正确倾向组分别反映了高、低水平学生的问题解决状况。新加坡学生在这两群组较合理(28.4%,28.2%),日本、中国上海学生则呈现两极分化——特别是中国上海学生,虽然在“正确倾向组”占比较大(43.1%),但由于“随机检查组”、“全面检查组”占比很小(6.4%、8.9%),故“错误倾向组”占比也较大(41.6%),说明两极分化非常严重,高、低水平学生泾渭分明,这反映出中国上海学生在促进教育公平,特别是提高低能力水平学生方面还有待进一步加强。
五 总结与建议
1 重视和加强问题解决策略、方法的指导
滞后序列分析显示,中国上海学生的显著行为序列链与新加坡、日本学生不同,造成此差异的原因主要是中国上海学生缺少错误行为序列。错误行为序列反映比较、自查、反思的过程,并非错误行为序列越多就说明问题解决能力越低,相反,错误行为序列成为显著性行为序列恰好体现较高的问题解决能力,因为大部分学生通过“探索和理解”深入问题情境寻找正确操作。
上述差异暴露了中国上海学生在问题解决策略、方法上的不足,广义而言,这是缺乏学习策略和问题解决自我监控意识淡薄的结果。PISA(2015)报告显示,中国加入其它三省(市)后高协作问题解决精熟度水平的学生占6.4%,较PISA(2012)下降11.8%;而低协作问题解决水平占28.2%,比例上升17.6%。据此可以推断,我国学生在问题解决方面仍缺乏有效的学习策略和方法,未来我们的课堂教学应着重放在学习策略和方法的掌握上。
2 关注低水平问题解决能力的学生
聚类分析结果显示,上海高、低水平问题解决能力学生分化严重,低水平占比过大(41.6%),反映出我国在促进教育公平方面还有待提高。我国基础教育的工作重点是提升精英学生比例,还是降低低成就学生比例?从本研究的结果看,中国上海学生在“正确倾向组”的比例也已超越新加坡、日本学生,而在“错误倾向组”的比例也同样大于两国,中国上海更应该着力减少低成就学生比例,从而促进教育公平。因为中国上海有其独特的经济、教育、文化优势,尚且在促进低水平学生发展方面有所不足,广阔的东中西部省市就更应注重城乡义务教育均衡、一体化发展。虽然我国教育投入占国内生产总值4%的目标在2012年已经实现,但是教育投入地域的均衡化远没有达到目标,各级政府和教育行政部门应切实落实教育经费的均衡配置,着力提高偏远薄弱地区的学校建设、师资水平、基础设施等,注重提高教育质量的同时兼顾教育公平,缩小高低水平学生间的差异,从整体上提升教育质量。
[1]郭炯,郑晓俊.基于大数据的学习分析研究综述[J].中国电化教育,2017,(1):121-130.
[2]OECD. PISA 2012 results: Creative problem solving: Students’ skills in tackling real-life problems (Volume V)[R]. Paris: OECD Publishing, 2014:52.
[3]Baker R S, Yacef K. The state of educational data mining in 2009: A review and future visions[J]. Journal of Educational Data Mining, 2009,(1):3-17.
[4]Romero C, Ventura S. Educational data mining: A survey from 1995 to 2005[J]. Expert Systems with Applications, 2007,(1):135-146.
[5]Romero C, Ventura S. Data mining in education[J]. Wiley Interdisciplinary Reviews Data Mining & Knowledge Discovery, 2013,(1):12-27.
[6]OECD. PISA data analysis manual: SPSS and SAS (2nd edition)[M]. Paris: OECD Publishing, 2009:115-119.
[7]Greiff S. Computer-generated log-file analyses as a window into students’ minds? A showcase study based on the PISA 2012 assessment of problem solving[J]. Computers & Education, 2015,(11):92-105.
[8]杨现民,王怀波,李冀红.滞后序列分析法在学习行为分析中的应用[J].中国电化教育,2016,(2):17-23.
①该题英文版体验网址:https://www.oecd.org/pisa/test-2012/testquestions/question5/。
②相关图表可参见http://blog.sciencenet.cn/blog-3361920-1144210.html。
③相关图表可参见http://blog.sciencenet.cn/blog-3361920-1144210.html。
④相关图表可参见http://blog.sciencenet.cn/blog-3361920-1144210.html。
Log File Data Analysis of Exploration and Understanding Process——A Case Study of PISA (2012) Problem Solving Test in Singapore, Japan, and Shanghai China
SHOU Xin1HE Peng2CHEN Ming-yan3HU Wei-ping4[corresponding author]
Log file data is not only static data that includes learning time, learning process, mouse and keyboard clicks, but also dynamic data that reflects the process of learning. Based on PISA (2012), methods of correlation, lag sequence and clustering were employed to analyze the log file on the item of TICKETS in Singapore, Japan and China. The results indicated that a) The behavioral sequences of students in Shanghai China were different from that of Singapore and Japan, reflecting a lack of strategy and method, b) Chinese students in Shanghai owned large proportion in ‘error prone groups’, indicating the polarized distribution of the high and low problem-solving ability students. Finally, some suggestions were proposed at end to improve Chinese students’ problem-solving performance.
problem solving performance; PISA; educational data mining; behavioral sequence
G40-057
A
1009—8097(2018)12—0041—07
10.3969/j.issn.1009-8097.2018.12.006
首新,讲师,博士,研究方向为科学课程与教学,邮箱为346532216@qq.com。
2018年5月16日
编辑:小西
