基于Elasticsearch 的校内全文搜索平台的研究与实现
2018-12-28钦蒋承沈宏良
钦蒋承,沈宏良
(湖州师范学院,湖州313000)
0 引言
在目前的国内高校中,随着数字校园的工作不断推进,无纸化办公的理念不断深化,校园网络中的各种新闻资讯、文档、多媒体等数字资源呈现出爆发式的增长。这些数字资源能够为师生的日常工作和学习提供有效帮助,但面对体量庞大的校园数字资源,使用人工查询的方式无法快速的定位到所需资源所在的具体位置,而通用的搜索引擎例如百度、谷歌搜索很难对一个域内的资源进行精准全面的搜索,非常不利于校内用户的搜索体验;同时,这些校内的信息资源分布在不同的服务器和存储中,无法通过集中管理来有效分析利用这些信息资源,从而无法获取数据背后的价值和知识。也就产生了所谓“数据富裕而信息贫瘠”的尴尬局面[1]。因此,有必要根据高校的校园网特色和本校用户的搜索需求来定制一套全面、高效、精准且易用的搜索平台。
针对当前现状,本文基于对新型分布式数据管理和检索核心ES 的研究学习,利用其强大的分布式数据管理能力和高效的实时文件存储和索引机制,建立校内全文搜索平台。在此基础上,根据校内用户实际的检索需求,针对ES 索引模块的中文分词缺陷,搜索结果相关度不够符合域内用户体验的缺陷进行进一步的优化,引入成熟的中文分词算法IK;并将搜索用户的校内身份信息引入搜索结果的相关度计算中,提高用户检索结果的相关度和准确性。实验表明,优化后的搜索平台与通用的搜索引擎和基于内容管理的搜索引擎相比较,本文实现的搜索引擎能够更快速、准确、全面地完成校内用户的搜索需求。
1 搜索引擎及Elasticsearch概述
1.1 搜索引擎概述
搜索引擎是用以在万维网中搜索信息的软件系统[2]。搜索引擎平台主要包括爬虫工具、索引工具、检索器和用户界面这四个主要部分组成。搜索引擎使用网络爬虫(Web Crawler)不断地挖掘网域内的网络内容,不断地周而复始来穷尽探索网域内的网页。索引工具则针对爬虫爬取的网页内容生成以词为索引项的索引表,提高检索器在数据库中查找目标文档的工作效率。全文搜索的索引会对网页内容中出现的每一个单词建立索引列表[3]。检索器会接收用户提交的搜索关键词,在数据库中通过关键词索引匹配来快速获取关联结果,并在用户界面上按照预设的相关性排序来向用户呈现搜索结果。
1.2 Elasticsearch概述
Elasticsearch 是一个基于Apache Lucene 开发而来的实时的分布式搜索和数据分析引擎[4]。ES 能够快速、全面地浏览大规模数据集,适用于全文检索,结构化数据检索和数据分析;ES 强大的数据检索能力和优秀的二次开发能力,使得很多商业软件和平台如百度、GitHub、Wikipedia 等也采用ES 作为数据资源检索的核心组件。通过文献的系统综述[5-8],我们总结ES 具有以下突出优点:
(1)ES 支持分布式的实时文件存储结构,任意一个爬取到的字段都可以建立索引,并且可以被搜索到。
(2)ES 有非常强大的可扩展性,分布式架构可以扩展到上百台服务器,能够应对PB 级结构化或非结构化数据。
(3)ES 提供了RESTful API,使用JSON 格式,提供了非常优秀的外部交互能力,使得搜索引擎能够支持多种文件类型的搜索。ES 项目提供了多种语言版本的客户端,包括Java、Python、.NET 和Groovy,提供了友好的二次开发平台。
(4)ES 面向文档,能够存储完整的数据对象或文档,同时能够对每一个数据对象的内容做索引。
(5)具备良好的数据备份和恢复功能,在发现有数据节点退出时,ES 能够根据服务器的负载对索引分片进行重新分配,丢失的数据节点在重新启动后,也会自动恢复连接。有较强的鲁棒性。
综合以上的特点,ES 可以有效地提升搜索效率,具有优秀的扩展能力以及数据操纵能力。因此,本文基于ES 进行校内全文搜索引擎的开发。
2 平台设计与实现
针对高校服务器的分布特点,本文设计的基于Elasticsearch 的校内全文搜索引擎的总体架构如图1所示,其核心组件包括爬虫模块、索引模块以及检索模块。

图1 校内全文搜索引擎总体架构设计
2.1 爬虫模块
本文设计并实现的爬虫模块架构如图2 所示。

图2 爬虫模块架构设计
初始化的URLs 列表为校园网的首页以及各二级行政单位和二级学院首页,并提交给多线程工作分配单元,将列表内的URLs 平均的分配给n 只爬虫。每个爬虫单元在接收到各自的URLs 列表后,向目标URL发送HTTP 请求,接收返回的网页内容数据并进行解析。一方面,将文本内容按照预设的文档标准进行结构化整理并保存在本地ES 数据库中。另一方面,提取网页内容中包含的URL 链接作为新增URLs。这些新增的URLs 将通过预先设定的URL 筛选规则,将重复的、无效的以及校园网域外的URL 剔除,将剩余的URLs 提交给多线程工作分配单元来进行下一轮的数据抓取工作。
本文基于开源的Java 爬虫框架WebCollector 定制开发了并行爬虫模块。通过8 条爬虫线程连续30 天不间断爬取,共累计获取超过四百万份校园网域内的文档。这些文档内容都按照预设的JSON 标准文档结构预处理后存储在ES 的非关系型数据库内,等待索引模块处理。
本文预设的JSON 文档结构:


2.2 索引模块
ES 引擎的索引机制基于倒排索引(Inverted Index)技术开发,文档的关键词来组成文档集合。在用户搜索时,首先将搜索词与关键词文档集进行匹配,再根据各文档在该关键词集的权重量来对搜索结果排序。但是,由于ES 搜索核心的分词表默认为英语,对中文文档的分词和归类能力比较薄弱;同时,在文档的权重计算上,也没有考虑到域内用户的检索偏好,在搜索结果的相关度上与用户实际要搜索的内容匹配度不高。针对以上两个ES 系统的缺陷,本文针对性地对分词技术和文档权重计算算法进行了优化,进一步提升校内用户的搜索体验。
(1)中文分词
本文引入的中文分词技术基于IKAnalyzer 中文分词语言包开发而来,其本质是一个开源的,基于词典分词和文法分析算法的中文分词组件。同时,根据对校内搜索用户的了解,其特点是周期性的搜索关键词重复率较高[11]。相比广域的搜索引擎,校园网络范围内的用户的搜索关键词统计结果分布的离散度相对较低。将这些高频词汇引入分词词典,对中文分词的表现和结果集的分类表现都有较大提升。针对这一特点,我们重新设计了ES 的索引模块,如图3 所示,将用户检索的高频关键词按用户身份分类收集在扩展词库内,并对爬虫爬取的校内文档进行实时分词索引。最终生成的索引结果能够更加匹配校内用户检索的关键词,也能进一步提升搜索结果的相关度。
(2)权重计算
一个文档在索引内的排序由文档的相关性权重决定。一个文档的权重计算由关键词在该文档中出现的位置和出现次数计算得来(出现的次数越多,出现该词的文档数量越少,则权重越大)。基于ES 存储文档的JSON 特性,以及校内检索用户的身份识别特性,我们可以根据关键词在不同位置(标题、作者、机构、内容等)分别出现的次数来综合计算关键词的权重,使搜索结果能够进一步的匹配用户的期望。
根据鲁松等人[12]基于空间向量模型的文档词语权重计算方法,本文的权重计算公式如下:
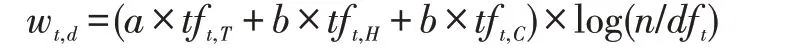
wt,d表示词t 在文档d 中的权重;tft,T,tft,H,tft,C分别表示词t 在文档中标题、段落标题和内容中分别出现的次数;n 表示文档的总数;dft表示出现词t 的文档总数;而a,b,c 分别代表标题、段落标题和内容中的关键词的权重系数,约束条件为:a+b+c=1且a>b>c>0。
2.3 检索模块
检索模块是面向检索用户的Web,接收并解析用户键入的搜索关键词,在后台匹配索引并反馈满足搜索条件的结果。

图3 基于IKAnalyzer的优化索引模块设计
用户界面的设计参照了目前世界主流的搜索引擎,谷歌搜索和百度搜索的界面设计,来降低用户的使用学习成本,如图4 所示。页面通过输入框来接收用户键入的搜索文本,并提交给查询解析器。最终查询的结果按照预先设定的相关性排序进行列表呈现,如图5 所示。
图4 校内搜索引擎首页面
最后,为了优化引擎的用户体验,我们对部分搜索关键词生成检索结果进行排序优化,提高校园网域内的各主要站点和热门站点的排序名次。

图5 搜索结果页面
3 实验结果分析
为了验证基于ES 的校内全文搜索引擎的搜索性能,分别选用了国内通用搜索引擎百度和校内CMS 集成搜索引擎(CMS)来进行对比测试。测试的指标为前50 个搜索结果的相关度和搜索结果的反馈时间,测试的关键词为“学校名称+图书馆”。对比结果如表1所示。

表1 搜索性能对比
测试结果显示,基于ES 的校内全文搜索引擎在搜索用时和搜索结果的准确率上要优于百度和校内CMS集成搜索引擎,有效的提升了校内文档检索的效率和准确性。
4 结语
基于ES 的校内全文搜索引擎平台在校园网域内运行稳定,成功解决了校内数字资源无法精准和快速的定位的问题,同时也满足了校内用户的搜索需求。本文的下一步工作是在搜索引擎的基础上,增加用户搜索热词的功能,全校园网域特定时间段内对特定数据的需求量,并动态更新检索结果的相关度权重排序,进一步提升校内用户的搜索体验。
