复杂情境感知下用户聚类协同推荐算法
2018-12-28毕孝儒
毕孝儒
(四川外国语大学重庆南方翻译学院国际商贸与管理学院,重庆401120)
0 引言
随着Web2.0 互联网技术普及和飞速发展,网络上的资源正在爆炸式地增长,致使用户从网络大量数据中获取感兴趣的信息需要耗费大量时间。因此,各种形式的推荐技术应运而生。作为当前主流的推荐技术,协同过滤推荐技术由于其算法实现简单、鲁棒性强等优点,已经广泛应用到各个行业和领域。其基本思想是基于用户-项目评分数据集,通过收集相似用户的兴趣信息进而对目标用户推荐。但随着用户和项目数量的指数增长,该算法存在计算量大、数据稀疏性、推荐质量不高的问题[1]。
针对以上问题,李涛[2]提出了一种基于用户聚类的协同过滤推荐算法;王晓耘[3]将基于粗糙理论和用户聚类相结合以提高协同过滤推荐算法精度;郭弘毅[4]在融合社区结构和兴趣聚类基础上,实现协同过滤推荐;段元波[5]通过对基于项目评分与类型评分进行聚类分析,降低了协同过滤推荐算法计算量;许鹏远[6]提出一种基于聚类系数的推荐算法,将推荐系统抽象为一个有向加权二分图并考虑聚类系数因素的影响重新定义相似度计算方法;以上算法较好地解决了以上传统协同过滤推荐算法计算量大的不足,但由于其并未考虑用户对项目评分时的复杂情境信息,因此推荐精度不高。
基于上述分析,提出了一种复杂情境感知下用户聚类协同推荐算法(Collaborative Filtering Recommendation Algorithm of User Clustering based on Complex Circumstance Awareness,UCCA-CF)。实验结果表明,该算法在降低推荐计算量的同时,提升了推荐质量。
1 基于用户的协同过滤算法
基于用户的协同过滤算法通过在用户-项目评分矩阵上计算用户间相似性,以确定目标用户的的邻居集,并将目标用户所感兴趣的项目通过一定推荐方法返回用户。
1.1 用户对项目评分数据
推荐系统中存储的用户评分数据包括用户id、项目id 和用户对项目的评分。设有m 个用户和n 个项目,U={U1,U2,…Um}表示用户集,I={I1,I2,…In}表示项目集,则用户评分数据可采用一个m×n 阶的用户-项目评分矩阵R={rm,n}表示。其中,rm,n表示用户Um对项目In的评分值,rm,n值越大,说明用户对其越感兴趣。
1.2 用户相似性度量
当前,常用的相似性度量方法有Pearson 相关系数和修正余弦相似性。设为用户Ui评过分的项目集合为用户Ui产生的评分均值。则Pearson 相关系数计算用户Ui与Uj相似性方法如式(1)所示:

修正余弦相似性计算用户相似性方法如式(2)所示:

1.3 预测评分
根据用户间的相似度可以获取目标用户的最近邻居集合,并将其相似性作为权重预测目标用户对未评分项目的评分,故目标用户Ui对项目i 的评分Put,i预测如式(3)所示:

2 复杂情境感知下用户聚类协同推荐算法
2.1 基本定义
情境是指用于表征与交互环境相关的实体状态的信息集合,它包括空间、时间、物理环境状态、人的情绪、心理状态及相互关系等。
定义1 复杂情境协同过滤推荐系统中用户情感、社交圈、用户位置、基础设施和物理条件等信息的集合,用向量表示为
定义2 情境感知协同过滤推荐系统通过对用户的复杂情境信息进行推理和分析、挖掘以实现推荐预测。
以下通过表1 分析用户在不同情境组合下的项目评分对对推荐结果产生的影响。

表1 不同情境信息对推荐结果影响
表1 中复杂情境包括社交圈、位置、时间和情感4大类。而每一类又分成若干子类。推荐系统可以通过情境感知不同的情境层次为用户推荐不同的项目。譬如,User1 和User2 在家人,图书馆、下午和愉快情境下Id1 和Id4 偏好一致,User1 和User2 在朋友,购物商场、上午和悲伤情境下Id1 和Id4 对项目评分相同,因此,可认为在相同情境下User1 和User2 具有较高相似性。故可以根据User1 在其他情境下对项目的评分为User2 在相同情境下进行推荐,比如,在家人、工作区、下午和愉快情境下可为User2 推荐Id3。
通过以上分析,在引入复杂情境信息后协同推荐函数F 可表示为:
F:User×Item×Circums tan ce →Rating
其中,User 表示用户,Item 表示项目,Circumstance表示复杂情境信息,Rating 表示用户对项目的评分。
2.2 用户复杂情境信息相似因子
在协同过滤推荐系统中,可对用户的复杂情境信息进行细粒度划分,产生不同层次的环境信息。例如,将社交圈情境细分为家人、同事、朋友、陌生人等;将位置情境划分为商场、实验室、工作区等。在此基础上,形 成 复杂情境向 量CUCCA-CF 算法在对各个情境信息取值量化、归一化后,定义用户复杂情境信息相似因子为:

2.3 改进的用户相似度度量
针对传统户相似度计算公式未考虑用户情境信息的不足,UCCA-CF 算法依据式(1)和式(2),给出改进的Pearson 相关系数用户相似度度量公式为:

改进的修正余弦用户相似度度量公式如下:

2.4 考虑复杂情境信息的用户聚类分析
对于文献[2]在仅在User-Item 矩阵上对用户进行聚类,而并未考虑用户当时评分的复杂情境信息的问题。UCCA-CF 算法在User-Item 矩阵上加入用户评分时的复杂情境信息维度,并采用改进C 均值聚类算法,实现用户评分信息和复杂情境信息聚类分析,生成用户类别所属度矩阵。
算法1 复杂情境信息下用户聚类算法
输入:用户聚类的类别数目k,原始数据source=(User,Item,Circumstance,Rating),用户相似性阈值t。
Step1:确定初始聚类中心;
Step2:for r=1:m{
(1)采用式(5)或(6)计算第r 个用户的评分和情境信息与各个聚类中心的相似度;
(2)取出这些相似性中最大值;
(3)if(该最大值>t)
将用户r 所属类别归入该聚类类别;
Step3:将属于同一类别的所有用户评分和情境信息平均值作为该类中心;返回Step2,直到聚类中心不再发生变化。
依据上述用户聚类结果,定义用户类别所属度矩阵如下:

其中,n 为用户数量,k 代表用户聚类中心数。
Sij,i=1,2,3,…,n,j=1,2,3,…,k 表示采用式(5)或(6)计算的第i 个用户到与第j 个聚类中心的相似度。
2.4 最近邻用户确定
UCCA-CF 算法在用户聚类分析的基础上,通过算法2 确定目标用户的l 个最近邻用户。
算法2 目标用户的最近邻用户确定算法
输出:目标用户的L 个最近邻用户。
Step1:依据公式(5)或(6)计算目标用户与k 个聚类中心之间的相似性,得到相似度向量V={ v1,v2,v3,…,vk}。
Step2:计算向量V={v1,v2,v3,…,vk} 与类别所属程度矩阵S(n,k)各行的欧氏距离;
Step3:将上述欧氏距离最小的前L 个用户作为目标用户的最近邻用户。
2.5 预测评分计算
考虑到改进的用户相似度度量公式,以及算法2确定的目标用户L 个最近邻用户,UCCA-CF 算法对项目评分预测公式修改为:

3 实验与分析
3.1 实验数据集及评价准则
实验采用GroupLens 研究小组提供的MovieLens(http://movieslens.umn.edu)数据集,它包括943 个用户对1 682 个项目的10 万条投票记录。其中,用户属性有年龄、性别、邮编和职业。实验将用户属性和电影评价时间作为情境信息,验证UCCA-CF 算法有效性。
3.2 实验环境
实验硬件环境为Intel Core i5 系列CPU、2.2GHz 主频、2GB 内存;实验软件环境为Windows 7 操作系统、Microsoft VS 2008、SQL Server 2010 数据库。
3.2 评价指标
实验将平均绝对误差(Mean Absolute Error,MAE)作为算法性能评价标准。MAE 通过计算预测的用户评分与实际的用户评分之间的偏差度量预测的准确性,MAE 越小,推荐质量越高。假设预测的用户评分集为{ p1,p2,…,pn} ,对应 实 际 评分集 为{q1,q2,…,qn},则MAE 计算公式如式(19)所示:

3.4 仿真实验结果与分析
实验将数据按75%和25%的比例划分为训练集和测试集,在分别采用改进的Pearson 相关系数用户相似度和改进的修正余弦用户相似度公式计算用户相似性的同时,将本文提出的UCCA-CF 算法与传统基于用户的协同过滤算法U-CF、文献[2]基于用户聚类的协同过滤算法UC-CF、文献[3]基于粗糙集聚类协同过滤推荐算法RC-CF、文献[4]融合社区结构和兴趣聚类的协同过滤推荐算法CIC-CF、文献[5]基于项目评分与类型评分进行聚类的推荐算法ITC-CF 进行了对比实验。
由图1、图2 可知,无论采用改进的Pearson 相关相似性公式,还是改进的修正余弦相似性公式,在邻居数目相同的前提下,UCSA-CF 算法的MAE 值均明显小于其他算法,表明文本提出算法的有效性。
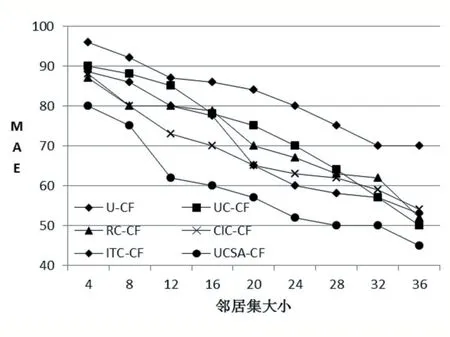
图1 改进的Pearson相关相似性公式下的MAE值

图2 修正余弦相似性公式下的MAE值
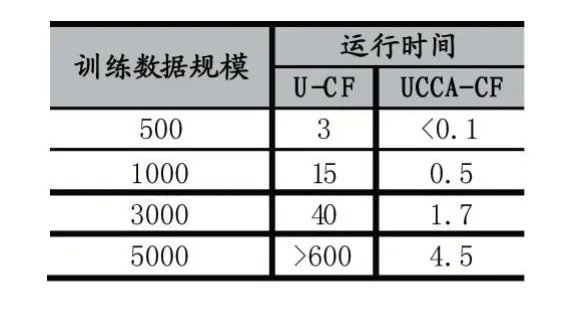
表2 算法运行效率对比(单位:秒)
由表2 的数据可以看出,随着训练数据数目增加,与传统的基于用户协同过滤算法U-CF 相比较,UCCA-CF 算法运行效率具有明显优势。
4 结语
本文从减少协同推荐算法计算量、提高推荐质量角度出发,提出复杂情境感知下用户聚类协同推荐算法,首先,本文在定义用户复杂情境信息相似因子基础上,现对传统用户相似性度量公式改进。然后,对用户历史评分信息与复杂情境信息进行聚类分析以产生用户类别所属度矩阵;最后,在类别所属度矩阵上确定目标用户最近邻居,进行项目推荐。实验结果表明本文算法是有效的。
