浅谈HBase
2018-12-20沈成龙
摘要:传统的RDBMS关系型数据库存储一定量数据时进行数据检索没有问题,可当数据量上升到非常巨大规模的数据(TB或PB)级别时,传统的RDBMS已无法支撑,这时候就需要一种新型的数据库系统更好更快的处理这些数据。我们选择了HBase
关键词:HBase;数据存储;数据库
HBase——Hadoop Database 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群,它的技术来源于Fay Chang所撰写的Google论文“BigTable”:一个结构化数据的分布式存储系统。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,另一个不同就是它是基于列的而不是基于行的模式。
HBase是水平扩展的、分布式的、开源有序映射数据库,它运行在Hadoop文件系统HDFS上,它不要求有预定义的模式,可以被看做弹性扩展的多维表格,通过动态添加列,在数据插入或查询之前修改列结构,以支持任意类型的数据结构。由于HBase运行在HDFS上,理论上HDFS有多少个节点就可以配置多少个HBase,因此,HBase非常适合存储海量数据
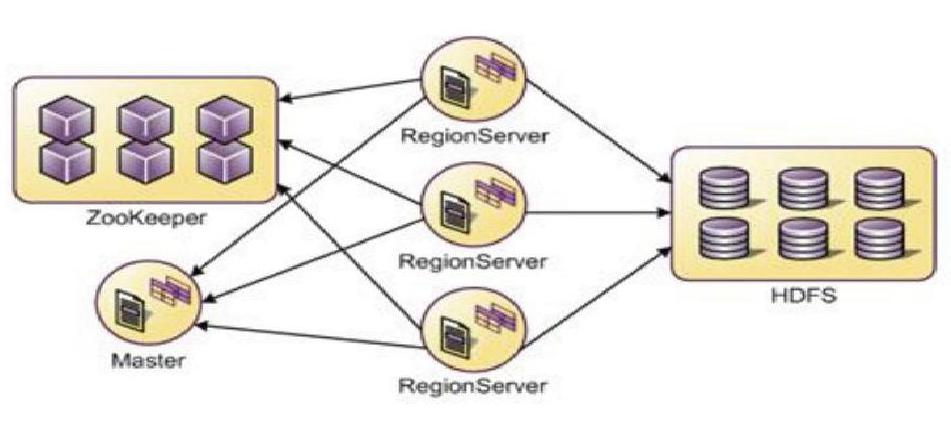
上图为HBase的架构设计,Master为HBase的主节点,用来协调客户端应用程序和RegionServer的关系,同时用来监控和记录元数据的变化和管理;RegionServer是从节点,用region的形式处理实际的表,region是HBase表的基础单元组件,它存储了分布式表,所以HBase表和HBase集群利用Master和RegionServer来协同工作;Zookeeper是一个高性能、集中化、分布式应用程序协调服务,它为HBase提供了分布式同步和组服务,在HBase中它用来选举主节点Master以便跟踪可用的在线服务器同时维护集群的元数据,一般安装多个用于提高Master的高可用。为了便于理解,可以把Master看做namenode,把RegionServer看做datanode,因为它们在HBase中的作用和namenode、datanode在HDFS中的作用相似,注意,这样的比喻仅仅为了方便初学理解,实际还是有着很大的不同。
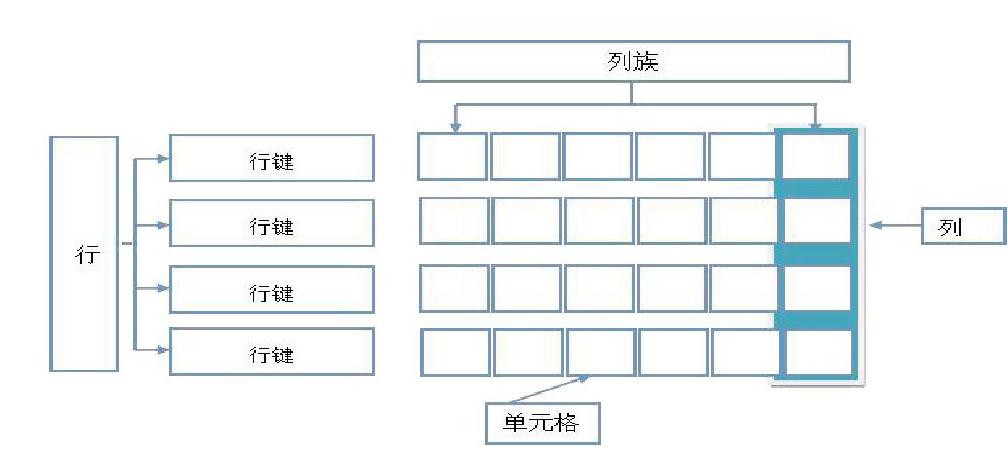
一个HBase表由以下几部分组成
行键:是HBase表中每个记录的唯一值,无论选择什么类型数据作为行键,它在内部、磁盘或内存里都将转换为字节数组进行存储,表中的每条数据都有唯一的标识符,即rowkey,相当于关系型数据库表中的主键
列簇:一张HBase表由表的不同列集合在一起。将相同功能或类型的列分类组合在一起,这样做的好处是可以更快的分开存储在HBase磁盘上的列簇中检索出所需的列
列:属于某一个列簇,相当于关系型数据库表中的非主属性字段
HBase沒有花哨的数据类型,它的所有数据都是字节数组。它是一种字节进字节出的数据库,其特征在于,当插入一个值时,HBase隐式的通过序列化框架将数据转化成字节数组,然后存储进单元格或者给出字节数组,当获取数据的时候,它在隐式的转化成等价的数据展示出来。单元格是HBase表最小的存储单元,在内部是一个列的实际值存储,因此一个单元格的数据由行键+列簇名+列名+时间戳:实际值组成
HBase在实际存储中,是按照列进行存储的,所有每一个列簇存储在单独的一个HDFS文件上。一张HBase表的行都是按照rowkey字典序进行排列的,并且表格在行的方向上被分隔为多个region,region是HBase中分布式存储和负载均衡的最小单元,不同的region分布到不同RegionServer中,也就是说,一个RegionServer中可以包含多个来自不同HBase表的region。
Region虽然是最小的分布式存储的最小单元,但却不是存储的最小单元。Region由一个或多个store组成,每个store保存一个列簇,每个store又由一个memstore(存储在内存中,是内存中的写入缓冲区,写入的数据会预先存储在其中)和零到多个的storefile(存储在HDFS上,存储的最小单元是它里面的HFile)组成。
作者简介:
沈成龙,1996年11月,男,汉,浙江省台州人,本科,学生,研究方向:计算机科学与技术
