基于顾客点分布的自提点逐渐覆盖选址模型
2018-12-19许茂增吕奇光
周 翔,许茂增,吕奇光
(重庆交通大学 经济与管理学院,重庆 400074)
1 问题的提出
2016年,网络零售市场交易额为5.3万亿元;网购用户规模达到5亿人,相比2015年同比增长8.6%;规模以上快递企业营业收入为4 005亿元,相比2015年同比增长44.6%[1]。面对迅速发展的市场环境,快递公司在积极寻找增加市场占有率和市场认同度的途径,通过优化配送网络布局,扩大顾客覆盖范围、提高顾客满意度无疑是最有效的途径之一。目前,快递公司针对网络零售为三级配送网络[2](如图1),即在这种配送网络中,货物首先从配送中心分送到各个中转站,再由中转站送至各末端节点。货物达到末端节点后,可以采用配送到户和顾客自提两种不同的投递方式,其中配送到户方式属于全送货制,顾客自提方式属于送货制和提货制的混合方式。顾客自提方式又分为定时定点取货和自提点取货两种,其中自提点取货是一种便利而环保的配送方式[3],目前大多数快递公司在末端节点配送时主要采用这种配送方式,这也是本文讨论的配送背景。
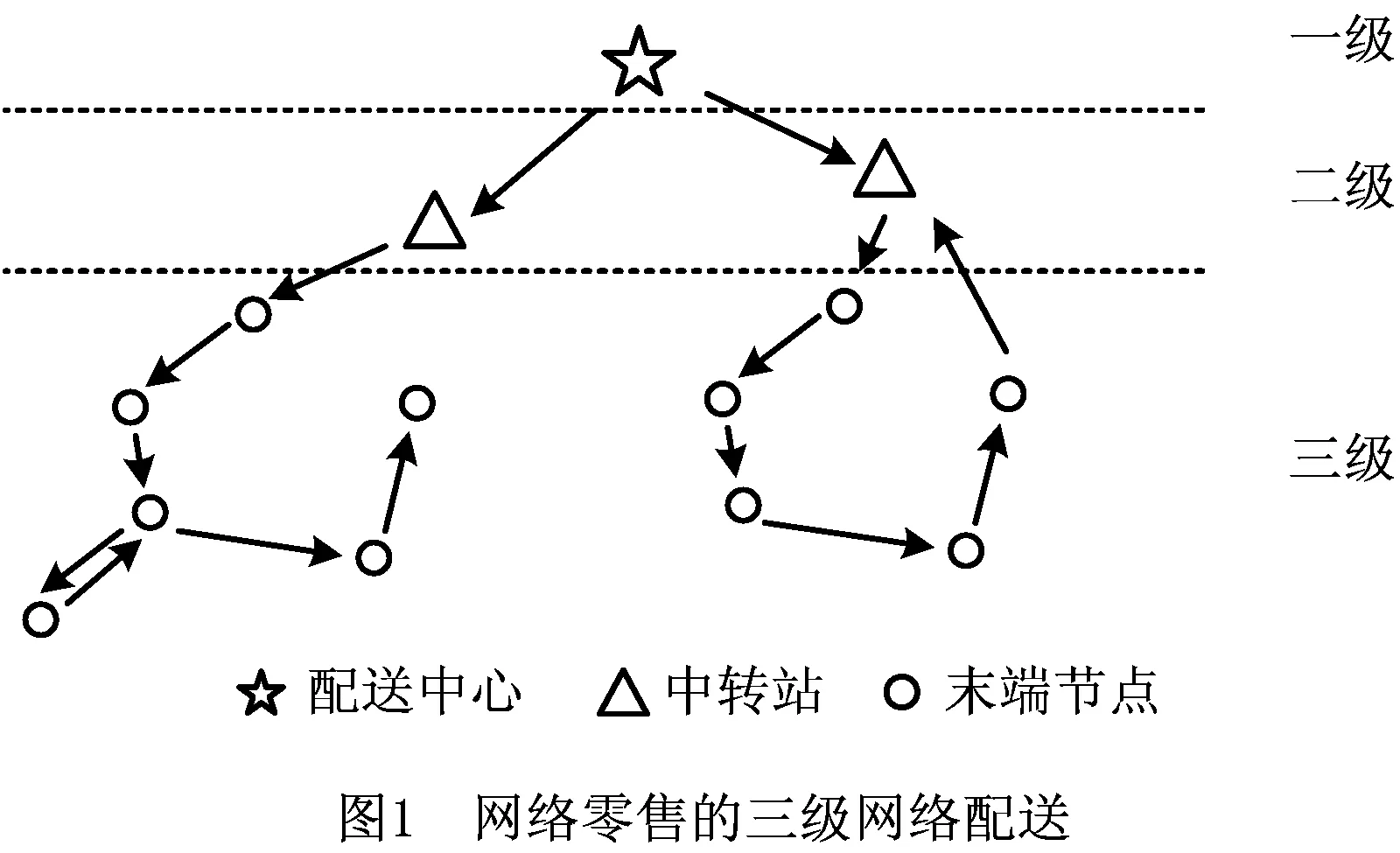
在这种三级配送方式的投递过程中,物流主体分别是配送中心、中转站、自提点和顾客。其中,配送中心和中转站都属于送货制中的节点选址,与传统送货物流的设施选址相似,目前已有大量文献,如孙会君等[4]、张晓楠等[5]、Gutjahr等[6]对此类物流设施的选址进行了研究。与送货制中的仓库、零售点、药店或工厂等物流设施选址不同,作为顾客取货场所[7],自提点属于提货制中的节点,其选址直接影响顾客覆盖程度和顾客满意度。目前已有文献对自提点选址展开研究,周林等[8]建立了集送货上门和客户自提于一体的多容量终端选址、多车型路径集成优化模型;陈义友等[9]构建了有限理性下自提点选址的多目标优化模型。这些研究在自提点备选位置已知和顾客划分已定的基础上进行,对于备选位置的确定和顾客划分,以及顾客满意度对自提点选址的影响还有待进一步研究。
鉴于此,本文分两个阶段对自提点选址展开研究。第一阶段,自提点备选位置规划阶段,提出网格动态密度聚类算法,将配送区域划分为多个网格,根据配送区域内顾客点的分布动态设置核心网格密度标准,通过网格连通性实现顾客点的聚类,以此确定自提点的个数和备选位置。第二阶段,自提点位置选址阶段,从取货距离、取货时间限制和地理阻隔三个方面衡量顾客满意度,建立以最大覆盖量为目标、顾客满意度为约束的逐渐覆盖模型。然后以VRP Instances中的Capacitated VRP数据集为算例,通过CPLEX计算并分析结果的有效性,最终提出适用于快递公司自提点设置的选址策略。
2 动态网格密度聚类算法
作为提货制中的顾客提货地点,自提点应根据被服务点位置进行选址。目前这类选址的研究主要有重心法、K-median和K-means等方法。姜大立等[10]提出适应于易腐物品配送中心的修改重心选址法;胡大伟等[11]讨论和比较了系统聚类、动态聚类、模糊聚类3种聚类分析法在公路运输枢纽布局选址中的应用;Nam等[12]将基于凸集上的平方距离聚类模型用于设施选址;王成等[13]提出一种基于覆盖率的递归K-means方法,不需要事先给定K值就可以自动得出最佳聚类的个数;Wang等[14]运用聚类算法初步实现顾客点到配送中心的分配。目前在快递配送网络中自提点选址的研究成果中,文献[2]通过区域与顾客取货距离的比值计算聚类个数,作为K-means聚类算法的K值;王鹏飞[15]用带有类内点数量均衡的K-means聚类算法实现快递网点选址。
目前研究均以所有顾客作为研究对象,这样必然会增加计算复杂度[16];另外,研究目标均为自提点到所有顾客的距离总和最小,事际上自提点的位置应该接近多数顾客点,以提高多数顾客的满意度。因此,有必要对现有网格密度聚类算法进行改进,提出网格动态密度聚类算法,以配送区域内顾客点聚集情况为研究内容,对顾客点按动态密度进行聚类,将顾客聚集密度大的位置作为自提点备选位置,由此确定自提点数量和备选位置。
2.1 动态网格密度聚类算法
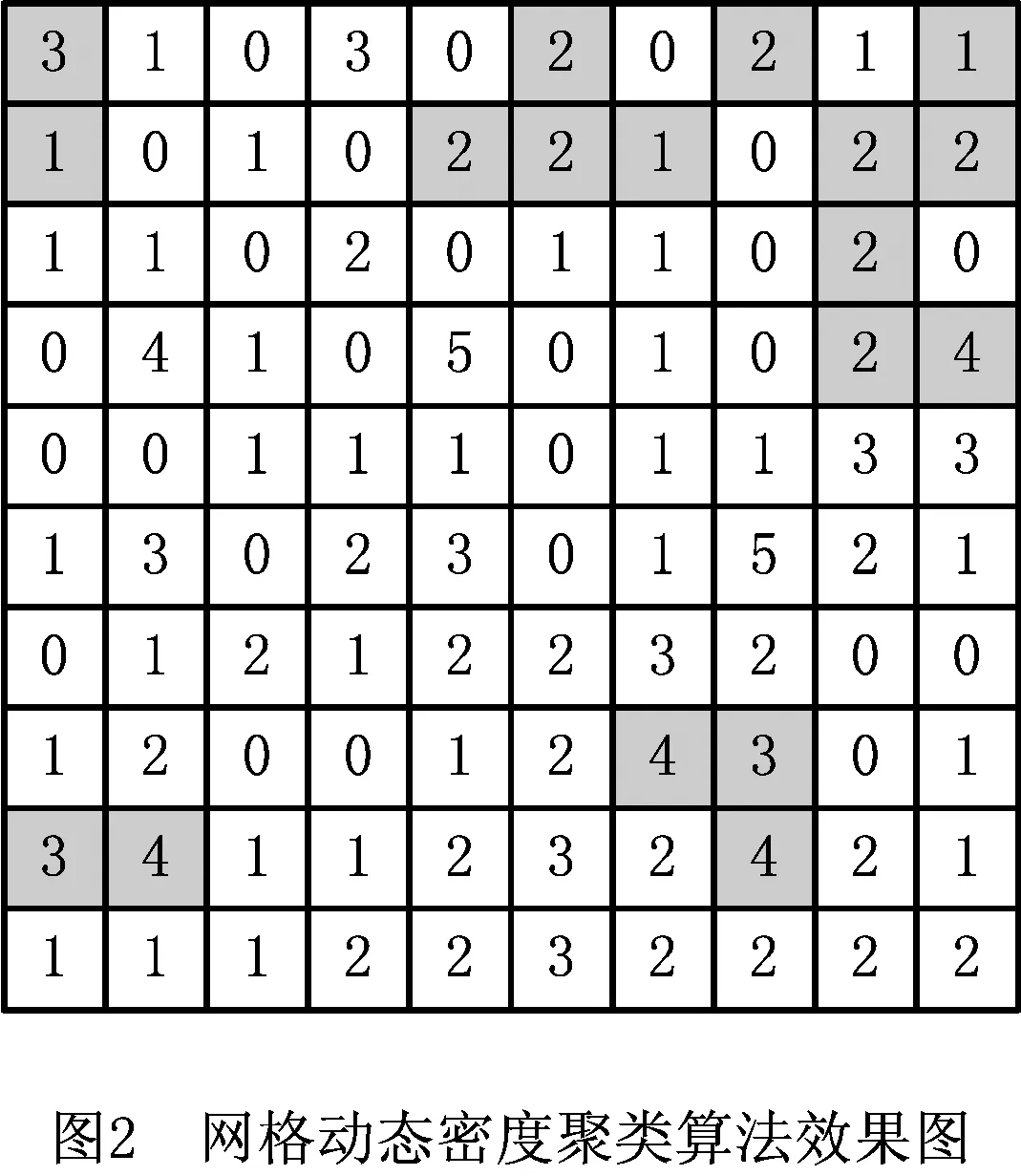
算法设计思路为:将配送区域划分为多个网格,以网格内顾客点的配送需求量作为网格密度值,计算所有网格的密度。若某个网格密度比邻近网格密度大,则将该网格选择为核心网格。本文通过设置动态密度选择核心网格,并计算其他网格与核心网格的网格直接密度可达性。若直接密度可达,则将它们聚类在一起。通过以上方法得到的每一个聚类即为一个需要设置自提点的区域,在如图2所示的10×10的网格区域中,每一个网络内的数字表示该网格区域内的配送需求量,每一个颜色块就是一个聚类区域。
2.1.1 算法定义
(1)网格 将区域划分为n个等大小的单元,每个单元为一个网格。G={Gi|G1,G2,…,Gn},其中Gi为一个网格,I={i|i=1,2,…,n}。
(2)邻接网格 指与该网格有相邻边或相邻顶点的网格[17]。Nb(Gi)表示网格Gi的所有邻接网格集合,|Nb(Gi)|表示网格Gi的邻接网格数量。
(3)网格密度 文献[18]将网格密度定义为网格内顾客的个数,本文定义网格密度为网格内顾客点的配送需求量之和,表示为den(Gi)。
(6)核心网格 定义为网格相对密度R(Gi)>1的网格单元。当R(Gi)>1时,表示其密度大于周围网格的密度,该网格为核心网格。
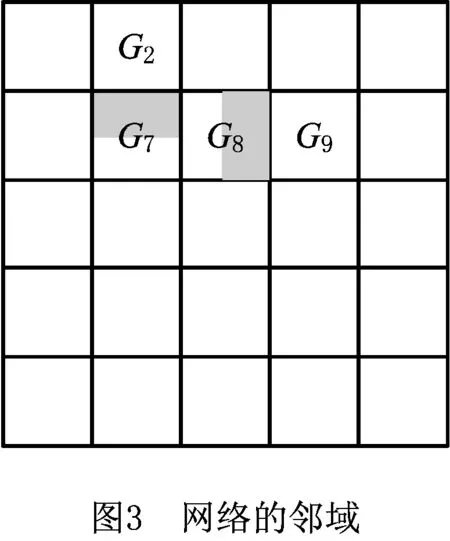
(7)网格相对邻域 A网格与B网格的相邻边位于A网格一侧的邻接区域(设为网格面积的一半)。如图3所示,G7与G2的网格相对邻域为G7内的阴影部分,同理G8与G9的网格相对邻域为G8内的阴影部分。通过分析网格相对邻域内的需求量,可以确定网格间的联系紧密程度。
(8)直接密度可达 如果两个网格的网格相对邻域内密度≥D(Gi)/2,则这两个网格的直接密度可达。当两个网格相对邻域内的密度≥D(Gi)/2时,说明其中一个网格与另一个网格之间联系紧密,因此定义为直接密度可达。
2.1.2 数据初始化
算法中将用到网格和顾客点的相关信息,并且进行聚类后还需要存储聚类结果。因此设置存储网格数据和顾客点数据的属性变量,并对其进行初始化。
(1)设置网格分割距离E,将区域划分为多个网格。
(2)设置网格属性“网格序号”、“左上角横坐标”、“左上角纵坐标”、“右下角横坐标”、“右下角纵坐标”、“网格密度”、“网格相对密度”、“核心网格”和“分类值”。其中:“网格密度”、“网格相对密度”和“分类值”的初始值为0,“核心网格”的初始值为False。
(3)输入顾客点信息,每一个顾客点为一个居民居住点,顾客点的需求量为该居住区内的顾客数量。
(4)设置顾客点属性“顾客点序号”、“横坐标”、“纵坐标”、“需求量”、“网格序号”、“网格分类值”和“聚类号”。其中:“横坐标”、“纵坐标”为顾客点坐标;根据顾客点坐标将顾客点划分至网格,网格序号存入“网格序号”属性,“网格分类值”和“聚类号”初始化为0。
2.1.3 算法步骤
动态网格密度聚类算法通过设置动态密度选择核心网格,并计算其他网格与核心网格是否直接密度可达,如果直接密度可达则将它们聚类在一起,每一个聚类就是一个需要设置自提点的区域。算法的具体步骤如下:
(1)计算并存储每个网格的“网格密度”、“网格动态密度”和“网格相对密度”。
(2)如果网格的“网格相对密度”大于1,则将网格的“核心网格”属性修改为True。
(3)将“核心网格”属性为True的网格按“网格密度”从高到低排序构成核心网格表。变量mk用于记录当前处理的网格序号,赋初值为1;变量L用于存储分类号,初值为1。
(4)从mk位置在核心网格表中查找是否还有“分类值”为0的核心网格,如果有,则将该核心网格序号赋值给mk,转(5),否则转(10)。
(5)判断网格序号为mk的网格Gi的所有邻接网格是否已有分类值,如果有则转(6),否则转(8)。
(6)查看网格Gi与已分类邻接网格Gj之间是否直接密度可达,如果是则转(7),否则转(8)。
(7)将网格Gj的分类号Lj赋值给网格Gi的“分类号”属性,同时将网格Gi内顾客点的“分类值”属性标记为Lj,然后依次判断网格Gi与其他未分类邻接网格之间是否直接密度可达,如果是,则将对应邻接网格的“分类值”标记为Lj,同时将网格内顾客点的“分类值”标记为Lj,转(9)。
(8)标记网格Gi的“分类值”为L,依次判断该网格与其邻接网格之间是否密度可达,如果是,则将该邻接网格的“分类值”标记为L,同时将网格内顾客点的“分类值”标记为L,L=L+1。
(9)返回(4)。
(10)算法结束,得到多个聚类区域。
2.2 确定自提点的数量和备选位置
自提点覆盖半径是有限的,因此将网格动态密度聚类结果中存在的一些面积较大的聚类区域进行二次分解,以此确定自提点的数量和备选位置。二次聚类分解采用K-means聚类算法,算法步骤如下:
步骤1设置自提点的覆盖半径D,计算其覆盖面积S。
步骤2计算每个聚类的大致面积和每个聚类的跨度。根据自提点个数与面积或跨度成正比的关系,分别求出按面积划分的个数和按跨度划分的个数,取两数中的数值大者为聚类区域内的自提点个数Tl,l∈L。
步骤3根据每个聚类的自提点个数,确定K-means聚类算法的类数k,其中每个聚类的Kl=Tl,l∈L。文献[19]明确指出,K-means聚类算法的结果受初始点位置影响较大。因此,为了保证需求量大的顾客点更接近中心位置,将每个聚类中需求量大的顾客点作为二次聚类的初始点。
步骤4在每个类中使用K-means算法进行二次聚类,得到聚类中心点。
步骤5在聚类中心点的附近选择多个适于设置自提点的位置作为自提点备选位置。
步骤6算法结束,得到需设置的自提点数量和多个备选位置。
3 带满意度约束的最大覆盖自提点选址模型
根据第2章得到的自提点数量,从多个备选位置中选择覆盖顾客点数量最多的一组自提点,显然这是Church和ReVelle在1974年提出的最大覆盖选址问题(Maximal Covering Location Problem, MCLP)[20]。文献[21]指出,MCLP已被证明是众多设施选址模型中最有效的模型之一。目前覆盖选址的主要研究领域集中在服务设施选址、应急设施覆盖选址和信号发射装置选址[22],主要的研究模型由最初的最大化覆盖到逐渐覆盖[23]、随机逐渐覆盖[24],发展到动态覆盖[25]。文献[26]指出自提点(末端节点)选址问题是服务设施选址的一种,采用逐渐覆盖选址模型更合理;另一方面,作为快递服务提供者,自提点选址还应考虑顾客满意度最大化,以稳定快递公司的客户资源,文献[13]也提出在对送货的终端节点进行选址时应综合考虑企业和顾客两个利益主体。鉴于此,建立以最大化顾客点覆盖度和最大化顾客满意度为双目标的自提点选址模型。
3.1 模型假设
(1)顾客点数量、位置和每个顾客点的需求量已知。
(2)顾客点与备选位置之间的距离已知。
(3)各备选位置的取货时间限制已知。
(4)备选位置与顾客点之间的地理阻隔已知。
(5)每一个顾客点由一个自提点提供服务。
(6)自提点不带容量限制。
3.2 参数与决策变量
I为自提点备选位置集合;
J为顾客点集合;
wj为顾客点j的需求量;
dij为自提点i与顾客点j的距离;
ti为自提点i的取货时间限制;
gij为自提点i与顾客点j之间的地理阻隔;
ri,Ri为完全覆盖半径、最大覆盖半径;
S为自提点数量;
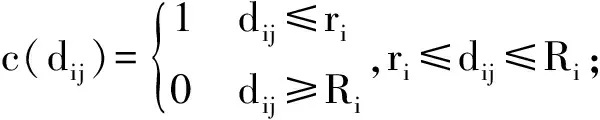
3.3 顾客满意度模糊函数
本文选取的顾客满意度影响因素为取货距离、取货时间限制和地理阻隔,如图4所示。取货距离为顾客点到自提点的距离,距离越小顾客满意度越大;取货时间限制为自提点可取货的时间限制,时间限制越小顾客的满意度越大;因为自提点为顾客自提货场所,所以应尽量避免自提点与顾客点之间存在地理阻断(如公路阻断)。此外,由于当前网络零售模式下,不同电商的快递收费和配送时间范围[13]与自提点位置无关,本文不将这两个因素作为自提点位置对顾客满意度的影响因素。

顾客满意度模糊函数为
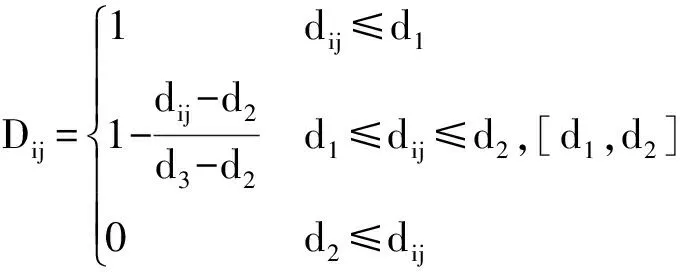
3.4 覆盖选址模型
以顾客满意度和逐渐覆盖为双目标的自提点选址模型如下。因为目前多数自提点与合作商(如社区超市等)之间的结算是以发件量为基础,与自提点位置无关,所以模型中未考虑成本因素。
(1)
(2)
(3)
(4)
s.t.
(5)
(6)
xi≥yij,i∈I,j∈J;
(7)
xi∈{0,1},i∈I;
(8)
yij∈{0,1},i∈I,j∈J。
(9)
目标函数(1)是为了实现自提点对顾客点覆盖量的最大化;目标函数(2)~(4)是为了实现满意度最大化。其中:目标函数(2)表示顾客对提货距离的满意度,目标函数(3)表示顾客对自提点提货时间限制的满意度,目标函数(4)表示对顾客点与自提点之间地理阻隔的满意度;约束(5)限制自提点的数量为S;约束(6)限制每一个顾客点只能被一个自提点覆盖;约束(7)表明自提点与顾客点之间的关系,顾客点只能在自提点被选中时才被该自提点覆盖;约束(8)和约束(9)是对决策变量xi和yij的0-1约束。
3.5 模型求解
模型中列出了5个目标函数,文献[28]指出求解这种多目标函数的模型可采用加权法或约束法。实际上,快递公司对顾客提供服务时,只要自提点的顾客满意度达到某一个期望值,如80%,该点就视为一个合适的自提点选址。因此,将目标函数(2)~(5)转变为约束条件对模型进行求解。转换后的模型为:
(10)
(11)
(12)
Ti≥α3xi,i∈I;
(13)
(14)
(15)
xi≥yij,i∈I,j∈J;
(16)
xi∈{0,1},i∈I;
(17)
yij∈{0,1},i∈I,j∈J。
(18)
其中,约束(11)~约束(13)表示满意度限制标准,α1,α2为α3快递公司指定的满意度约束标准。
4 算例研究
4.1 相关数据
通过算例检验所提出的算法和模型。使用ASUS笔记本,CPU是主频为2.50 GHz的Intel Core i7,内存空间为4 GB,操作系统是Windows 10(64位)。应用Visual Basic语言编写网格密度聚类算法,然后将聚类结果作为输入,在IBM CLPEX中求解模型。算例的数据来源于VRP Instances中Capacitated VRP的Set A集合中n69和n80的合集(http://neo.lcc.uma.es/vrp/vrp-instances/capacitated-vrp-instances/,注:进行合集时,对两个集合中坐标重合点的坐标进行了微调)。合集中数据的属性分别是顾客点的坐标和需求量,顾客点表示顾客聚居区,需求量表示该区域内的顾客配送需求量。合集中包括149个数据,分布在100×100的区域内,如图5所示,每个网格按10×10单位距离划分,每单位距离表示100 m,距离为欧式距离。

4.2 动态网格密度聚类结果及分析
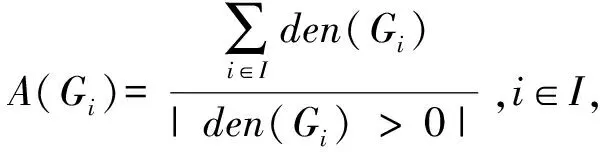

图6a和图6b中,大部分聚类的中心点非常理想地标记在了多个顾客点的中心位置,如图图6a的中心点3,29,49等、图6b的中心点2,24,32等。然而个别中心点却孤立存在,周围没有其他顾客点,如图6a中的中心点9。对比顾客点分布图发现,这个点就是网格39(第3行第9列)的顾客点,查看顾客点和网格数据,位于网格39内的是顾客点64,该顾客点的需求量大于网格平均需求量,因此即便只有一个点也被聚为一类,表示这里需要设置一个自提点对该顾客点进行覆盖。但这种情况在图6b中发生了改变,因为自提点覆盖半径增加,顾客点64被自提点7覆盖,所以就不再单独设置自提点。另外,图6a和6b中都有一些网格没有被任何自提点覆盖,如网格61,62,65,66,71等,特别是网格71(第7行第1列),其中有3个顾客点。查看顾客点和网格数据,网格71中有101,122,140三个顾客点,虽然该网格符合网格动态聚类算法中核心网格的要求,但是由于没有达到设置自提点的密度阈值的要求,该区域内未设置自提点。在实际规划中,快递公司可通过权衡需求量和自提点设置成本来确定并设置密度阈值δ,例如在大学校园内,只有学生宿舍一个顾客点,但需求量大,应该设置一个自提点;而在别墅区,可能有多个顾客点,但每个点的需求量都很小,应该采取其他配送策略。
综上所述,网格动态密度聚类算法根据密度阈值δ得到多个顾客点的聚类和一些孤立顾客点,实现了算法的预期效果,由此可见算法是合理、有效的。对算法得到的聚类和孤立点分别采用不同的配送方式:聚类中采用自提配送方式,运用3.4节提出的覆盖选址模型选择自提点位置;孤立点采用快递员直送方式,但直送方式会导致成本上升,因此孤立点的配送策略可借鉴航空公司的优质航空和廉价航空自选服务模式,快递公司提供优质配送和廉价配送两种配送策略供顾客选取。选取优质配送策略的顾客支付较高的配送费用,快递公司送货到户;选取廉价配送策略的顾客支付较低的配送费用,定时定点取货。由此,既可以避免成本上升,也可以保证孤立顾客点对快递配送的满意度不受影响。
4.3 带满意度约束的逐渐覆盖选址模型结果分析
对网格动态密度聚类算法得到的聚类中的顾客点运用覆盖选址模型进行计算时,要用到顾客点信息、自提点设置个数、备选位置相关信息。顾客点信息为已知,自提点设置个数和备选位置通过网格动态密度聚类算法可得。通过设置覆盖半径参数r和R,顾客可接受取货距离为[d1,d2],顾客可接受取货时长为[t1,t2],计算覆盖度c(dij)、距离满意度Dij、取货时长满意度Ti和道路阻隔满意度Gij。其中,覆盖最大半径依旧分别设为R1=400,R2=500,最小半径r=300。根据文献[32-33],顾客可接受的距离应为随机值,最大可接受距离d2在[400,500]之间。因此,设置d2=450+σ,d1=250+σ,其中σ为[-50,50]的随机数,单位为m。通过调查问卷获知,顾客可接受的最少取货时长t1=4,理想取货时长t2=8,单位为h。最后,模型求解还需设定距离满意度、时长满意度和地理阻隔满意度约束。为了观察不同满意度约束下覆盖量的变化,将满意度约束分别设置为0.1~1,如表1所示。其中:R表示覆盖半径,a1,a2和a3分别为距离满意度、时长满意度和地理阻隔满意度,nodes为当前需设置的自提点数,data1,data2和data3为网格动态聚类算法得到的理论位置附近随机生成的3组备选位置数据。由于模型求解计算在第一阶段网格动态密度算法聚类结果的基础上进行,当模型从备选位置中进行自提点选址时,只需在第一次聚类结果的每个大类中进行计算,可以大大降低模型的计算量。因此,本文选择直接使用CPLEX对3组备选位置进行精确求解,每一组备选位置的覆盖量显示在“覆盖量”栏。

表1 设置相同满意度约束值的计算结果
对比表1上下两组值,当R=400,满意度约束值为1时,3组备选位置数据均无法找到满足条件的自提点组,模型无解;当R=500,满意度约束为1和0.9时,均无解。并且,R=400的所有解几乎都大于相同约束值为R=500的解。产生这两个结果的原因是自提点设置数量不同,R=400设置自提点49个,R=500设置自提点37个。当自提点数量增加时,每个自提点负责的区域更小,与顾客点更接近,在相同满意度约束下,覆盖度更高。另外,对比R=400和R=500的objective value 3组备选位置的覆盖量,可发现3组数据有共同的规律,如图7和图8所示。在满意度约束值从0.1~0.9增加的过程中,0.1~0.5阶段,由于约束的增加,覆盖量有所减少,但是减少量不显著;但是,在满意度约束值增加到0.6之后,覆盖量出现剧烈减少。这说明大多数自提点的3个满意度值都能够达到0.6左右,但当满意度约束值超过0.6之后,部分覆盖率高的自提点因不再符合约束条件,而被另外一些符合约束但覆盖率低的自提点替代,这个结果验证了之前建立模型时提出的顾客满意度与覆盖量之间是不可能同时最大化的假设。
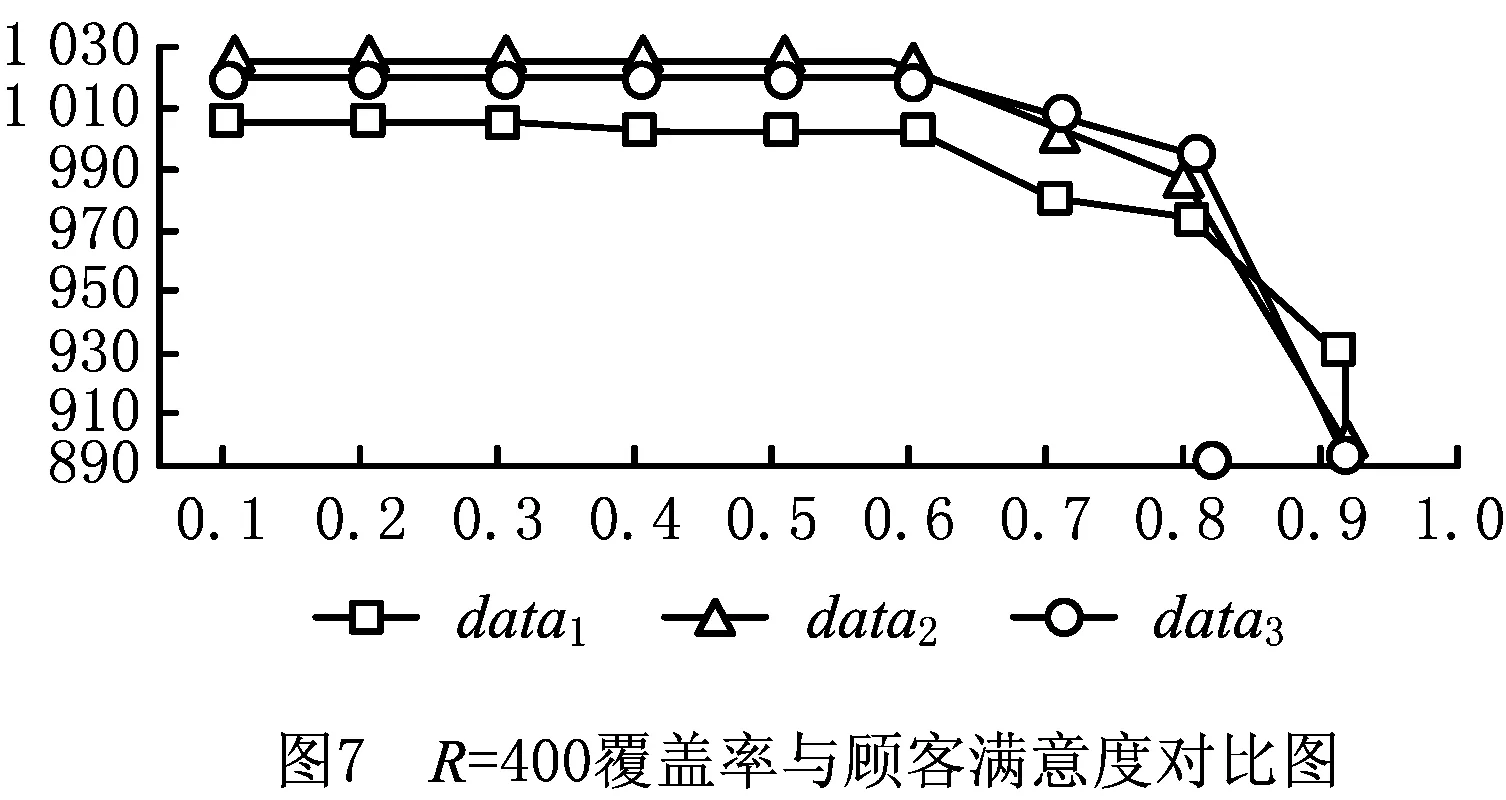
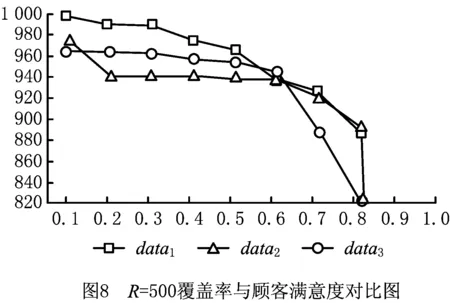
表1中,3个满意度约束值设置相同,但在实际中,快递公司可以根据实际情况将3个约束设置为不同值。例如,地理阻隔对顾客评价快递服务影响不大时,快递公司可以设置较低的地理阻隔约束值,以此换取更高的覆盖度;当某个自提点经常收到顾客针对取货距离的投诉时,快递公司就可以适当提高取货距离这个约束值,重新优化自提点位置。
为进一步验证算法和模型的有效性,在当前算例中快递公司选用参数R=500、data1数据,以及满意度约束值分别为a1=0.7,a2=0.6,a3=0.6的方案。模型计算的最终结果为覆盖度为948.51,自提点选址结果如图9所示,每一个带标号的点为一个自提点。图中有34和35两个特别的自提点,这是聚类15的两个备选自提点,它们被同时选中时,必然有另外一个聚类中的多个备选自提点一个都没有被选中,查看数据发现是聚类17的备选自提点没被选中。产生这个结果的原因是,聚类17的备选自提点在符合满意度约束时产生的覆盖度没有聚类15中的自提点34,35大。该结果对快递公司设置和优化自提点布局具有重大启发意义,依据这个结果,快递公司同样可参考航空公司推出的廉价航空和优质航空自选模式,将配送区域分为廉价配送区域和优质配送区域,对不同配送区域的自提点选址采用不同的策略。对于廉价配送区域内的自提点选址,采用降低顾客满意度、提高覆盖范围的选址策略,形成低成本高覆盖;对于优质配送区域的自提点选址,采用提高配送单价、提高顾客满意度、降低覆盖率的选址策略。快递公司通过联合实施两种选址策略,对不同配送区域区别对待,既可以满足市场的实际需求,又能扩大覆盖范围、增加收益。

上述算例的计算结果和分析表明,网格动态密度聚类算法有效实现了对顾客点的聚类,确定了自提点数量和备选位置;带顾客满意度约束的逐渐覆盖选址模型根据快递公司设置的不同满意度值实现了不同约束下自提点位置的选址。因此,这个基于顾客点分布、带顾客满意度约束的逐渐覆盖选址模型符合实际应用,是合理、有效的,其对快递公司进行网络零售配送中自提点的选址具有实际指导意义。
5 结束语
本文在网络零售配送自提模式背景下,以顾客点分布为研究基础,针对配送网络中的自提点,从数量和备选位置确定,以及位置选址两个方面进行了研究。首先,为了将自提点设置在顾客聚集区域内,对现有网格密度聚类算法进行改进,设计了网格动态密度聚类算法,算法中以动态密度设置核心网格,根据顾客点的位置和需求量进行聚类,以此确定自提点数量和备选位置,并提出对未设置自提点的孤立顾客点采取不同的送货策略;然后,在最大覆盖选址模型的基础上,将取货距离、取货时间限制和地理阻隔3个影响自提点选址的顾客满意度,与覆盖度最大化共同作为目标函数,建立了带满意度约束的逐渐覆盖自提点选址模型;最后,将VRP Instances中的数据作为算例数据,考虑模型的求解是在二次聚类的结果中进行,计算复杂度不高,选择直接在IBM CPLEX中对模型进行了精确求解。对计算结果的分析表明,网格动态密度聚类算法能够实现确定自提点数量和备选位置的功能。在带顾客满意度约束的逐渐覆盖模型中,通过设置不同约束值,产生了不同覆盖量的自提点选址结果。虽然提高顾客满意度与覆盖度在自提点选址过程中是两个互斥的目标,但是算例分析结果也表明,快递公司可以将快递业务划分为廉价模式和优质模式,分别采用不同的自提点选址策略为顾客提供差异化服务,从而在占领市场份额的同时获得市场认同。
本文也还有需要进一步研究的内容。首先,带满意度约束的逐渐覆盖自提点选址模型中的地理阻隔满意度函数设置较为简单,可进一步考虑引入地理信息系统(Geographic Information System,GIS)进行研究;其次,作为文中研究基础的顾客点,其位置和需求量均假设为静态不变,而实际网络零售配送中的顾客点位置和需求量是动态变化的,因此如何在顾客点动态变化下实现自提点选址将是下一步的研究方向。
