采用机器学习算法的软件能耗感知模型及其应用
2018-12-12傅翠娇钱德沛栾钟治
傅翠娇,钱德沛,2,栾钟治
(1.北京航空航天大学计算机学院,100191,北京;2.中山大学数据科学与计算机学院,510275,广州)
随着通信网络、个人计算机以及数据中心规模的快速增长,它们消耗的能量也越来越多,2012年个人和商业计算机的能耗已超过470 TW·h[1]。在计算机硬件方面已经采取了一些节能技术,主要有根据系统中的负载来调节操作状态的动态电源管理技术[2]和根据计算能力的不同需要来动态调节电压和频率的技术[3]。然而,在软件方面,软件开发者一般不确定一段代码的具体能耗和如何减少能耗。虽然借助于某些测量工具可以直接读出软件的能耗,但是它不能解释能耗变化的原因以及定位程序能耗较高的代码段。本文提出了一种基于机器学习算法的能耗模型,软件开发者可以通过该模型来评估代码的能耗,而不需要用测量的能耗数据训练自己的模型。该能耗模型是基于性能事件工具测量的性能数据建立的,这些性能事件本身可以反映出程序运行时的行为,所以可以解释能耗变化的原因。实验数据表明,以测量的能耗为基准,该模型的平均能耗预测误差小于9%。程序员可以利用该模型对自己所编写的程序的能耗进行预测,而不需要专门对程序再进行能耗测量和训练;也可以利用该模型准确地估计一些重复使用率高的代码能耗,以便为优化这些代码提供依据。
1 软件能耗模型的研究现状
现有的关于软件能耗的研究工作主要包括:CPU级、功能部件级、进程级、分布式系统的应用程序以及基于系统调用的能耗模型等。
CPU的能耗是计算机系统能耗中的重要部分。CPU级能耗模型的研究主要集中在周期级和指令级两个抽象的级别。周期级体系结构模拟器是在每一个执行周期通过激活微体系结构级单元或者块来估测模拟处理器的能耗[4],David等对处理器各部分分别进行模拟然后计算出最后的能耗值[5]。指令级的能耗模型是用来估计程序中所有指令执行的总能耗,Seo等提出了基于Java编程语言的能耗模型[6]。
在通过收集和使用实时部件能耗信息建立功能部件级能耗模型方面,Chen等提出了计算机系统主要功能部件的能耗模型[7];Shye等发现整个计算机能耗的主要部分是屏幕和CPU功耗[8];Gurumurthi等发现最耗能的部件是硬盘[9];Zhang等研究了部件利用率的能耗模型[10]。
进程级能耗模型是一种更加细粒度的方法,它根据实时的能耗信息作出节省能耗的关键决策。Chen等把进程的能耗定义为进程对所有功能部件使用的能耗之和[7]。
Feng等在文献[11]中提出了分布式系统应用程序的能耗测量和分析框架;Seo等则提出了基于Java编程语言的分布式系统能耗模型[6]。
Pathak等提出了基于系统调用的有限状态机能耗模型[12],有限状态机的每个状态代表一个特定部件的功率使用模式。Aggarwal等提出了基于系统调用计数的模型[13],该模型不适用于新的应用软件,它只能预测能耗的变化,并不能给出具体的能耗情况。
2 软件能耗模型的建模准备
本文采用机器学习算法建立能耗模型,该模型以软件的性能事件为特征。在建立软件能耗模型的过程中,首先采集用作训练样本的性能和能耗数据,然后根据相应的算法进行特征选择,通过有监督的机器学习算法建立与性能相关的能耗模型,再根据模型预测测试程序的能耗,最后根据预测的能耗结果,通过修改程序代码来达到优化程序能效的目的。
2.1 性能事件
本文以性能事件作为模型的特征是因为性能事件与程序的行为和特征有关。Perf工具[14]是Linux下的性能分析工具。它支持多种性能事件,主要包含7个硬件事件、8个软件事件和26个硬件高速缓存事件。软件事件实际上是与硬件无关的内核计数器。硬件事件和高速缓存事件依赖于CPU架构[4]。我们应用Perf工具采集了41个性能事件,这些性能事件是cycles、instructions等。
2.2 训练样本数据的收集
为了建立一个健壮的能耗模型揭示能耗与性能的关系,需要收集大量的训练数据(即软件性能数据与软件能耗数据)。为了方便数据的采集,本研究团队专门研制了Marcher服务器,该服务器提供了能耗采集的基本功能。我们在Marcher服务器上运行大量的样本软件,采集软件运行的性能和能耗相关的数据。软件的性能数据是利用Perf工具采集的程序运行过程中的数据。能耗数据是在Marcher服务器读取的运行程序的功耗数据。用作训练的程序主要是C、C++、Python以及Java程序,这些程序中有100多个程序是本研究团队自己编写的程序,有300多个程序来自编程任务网站[15],此外还包括OMP2012[16]、SPEC2006[17]、FFT和Nbody等程序[18]。用做测试的程序是Bhomp[18]和NPB3.0[19]。为了使测试集中于计算等基本的操作,去掉了程序中所有与输入输出相关的代码部分。
为了获取实验所需的训练样本数据,专门设计了脚本程序。在服务器上运行这些脚本程序,自动实时记录能耗数据。从可测功率的高性能计算机(Marcher服务器)上实时读取程序运行时的功率数据并求其平均值,为了避免由于其他因素造成的干扰,每个程序运行3次,取3次功率数据的平均值。本文还设计了一些脚本用于记录从性能工具获取的性能事件数据,分别记录了多个点的性能数据。对于性能数据没有采取平均值而是采用了中位数。采用中位数是因为它不受极端数据的影响,可以避免数据相差较大。
2.3 影响程序能耗的运行特征选择
为了减少特征集中的特征数,需要进行特征选择。选择出的特征可以更好地解释模型并提高模型预测的准确性。
由于不同性能事件数据的取值是不同的,有的数值差距较大,所以将性能数据标准化到0~1的范围内。标准化的数据使机器学习算法运行的更快更准确[12]。
本文选用了Perman相关性分析、主成分分析法以及随机森林算法进行特征选择。根据机器学习算法和相关性分析算法选择了排名前22的特征,它们分别是:cycles、instructions、cache-references、cache-misses、bus-cycles、branches、branch-misses、ref-cycles、stalled-cycles-backend、stalled-cycles-frontend、L1-dcache-loads、L1-dcache-load-misses、dTLB-loads、LLC-loads、LLC-load-misses、LLC-stores、cpu-clock、cs、migrations、L1-dcache-prefetch-misses、branch-load-misses和branch-loads。其中随机森林算法在选择这22个特征时,预测的得分为96.06,这些特征主要与系统时钟、访问高速缓存以及执行指令的顺序有关。
不同类型的软件可选择出不同的特征。首先选择采集自程序Nbody的数据来训练模型,只选择LLC-stores和migrations特征时,预测的得分可达86.1,模型的系数是[16.861,71.254],常数是72.814。当选择bus-cycles、branch-misses、ref-cycles、LLC-stores、LLC-prefetches和migrations这6个特征时,预测得分高达94.77,模型的系数是[-5.554,3.005,-5.545,17.113,6.026,72.042],常数是72.490。Nbody程序是典型的并行程序。对于并行程序,在开始运行时需要把任务分派到各个处理器上,Migrations参数反映了程序的并行执行程度。对于计算密集型的程序来说,由于存在较多的写回操作,因此LLC-stores反映了最后一级高速缓存写回的次数。
2.4 用于能耗建模的机器学习算法
本文分别采用了线性回归、随机森林、岭回归和套索回归4种不同的机器学习算法建立预测能耗的模型,之所以选择这些算法是因为它们使用简单、预测准确。
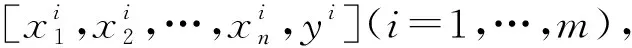
(1)
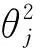
2.5 预测误差率
本文将预测误差率定义为测量的功耗与预测的功耗差的绝对值除以测量的功耗
ε=|y-p|/y
(2)
式中:ε为软件预测误差率;y为测量的功耗;p为预测的功耗。
2.6 软件分类方法
根据树型随机分类算法选择性能特征cache_miss对测试的程序进行分类。运行Weka软件的分类功能,根据实验数据得到cache_miss的阈值。在实验中,根据程序性能的cache_miss数值将软件分为两类,一类是cache_miss数值大于或等于2×107的软件,这类软件具有计算密集型和访存密集型的特征;一类是cache_miss数值小于2×107的软件。对于每个内存访问请求,处理器查找主缓存以检索数据,若找不到数据,则将其视为高速缓存缺失。cache_miss是软件的一个重要性能指标,非常适合对软件进行分类,然后根据类别分别建立能耗模型。
3 软件能耗模型的建立与实验分析
本节首先介绍了实验所用服务器的配置和测试程序,然后验证了实验的预测准确率,并以预测准确率较高的岭回归算法建立了能耗模型,最后根据模型分析了能耗产生的原因。
3.1 Marcher服务器系统配置
在美国国家科学基金会资助的可测功率的高性能计算机(代号Marcher)上进行实验。每一个服务器包含两个英特尔Xeon E5-2600处理器,每个处理器有16个内核、一个32 GB的DRAM、一个K20 GPU和一个英特尔Xeon Phi协处理器,以及硬盘和SSD的混合存储。在服务器上已开发了一个易于使用的API,它可以从多个来源来读取功率数值,包括英特尔RAPL接口[21]、NVIDIA管理库(NVML)接口[22]、英特尔micaccess API[23]和电力数据采集卡(PODAC)。通过这个API,可以很容易地在运行时收集所有主要部件(例如CPU、内存、硬盘、GPU和Xeon Phi)的细粒度的功率数据。由于测试样本程序不使用GPU和Xeon Phi,而磁盘的功率在大多数时候是相同的,所以在实验中只计算CPU功率数据。关于服务器系统更多的细节可参见文献[24]。
3.2 测试程序说明
在测试实验中使用的基准测试程序主要包括NPB3.0和Bhomp,共有27个独立的程序运行形式。其中,程序BT的S类型的可执行程序的形式是“BT.S”,Bhomp中的程序是不同的输入数据集下的Bhomp程序的独立运行结果。例如Nhome(5)是指Nhome(200 000,10,5),其中200 000、10、5 是程序运行时的输入参数,其他程序类似。这些程序主要是CPU计算密集型和内存访问密集型程序。
3.3 预测结果的验证
预测的误差率越小说明预测准确率越高。表1给出了不同机器学习算法下能耗测量数据和预测数据之间的差异。由实验结果得到,这些程序能耗预测的平均预测误差率为6.80%。岭回归算法的平均预测误差率最小为5.70%。随机森林算法、套索回归和线性回归算法的平均预测误差率分别为6.5%、8.18%和6.81%。可以看出,所得到的预测数据基本上是准确的。由于岭回归算法的误差最小,所以在建立能耗模型时选取岭回归算法。
3.4 软件能耗模型
本文首先建立了软件平均能耗模型,然后在此基础上建立了实时能耗模型,并对二者的预测误差率进行了比较。
3.4.1 平均能耗模型 通过对4种机器学习算法的实验比较,选择岭回归算法作为模型所用的算法,建立了预测平均功耗的模型p=cx+b,其中c为模型的系数向量,c=[c1,c2,…,cn];b为常数。程序能耗的公式是E=pt,p为CPU的功耗,t为程序的运行时间。代入p得到能耗公式
E=(cx+b)t
(3)
当性能参数cache_miss值大于等于2×107时,能耗模型E1=(c1x+b1)t。当cache_miss值小于2×107时,能耗模型E2=(c2x+b2)t。根据岭回归机器学习算法可以得到模型的系数,其中
b1=109.74
b2=63.2
c1=[-3.97,-2.64,-8.13,-3.41,3.76,-6.7,-0.97,3.77,-11.14,2.46,-8.7,0.74,-8.7,-9.64,3.12,-11.66,3.85,9.64,3.76,3.54,-0.94,-6.31]
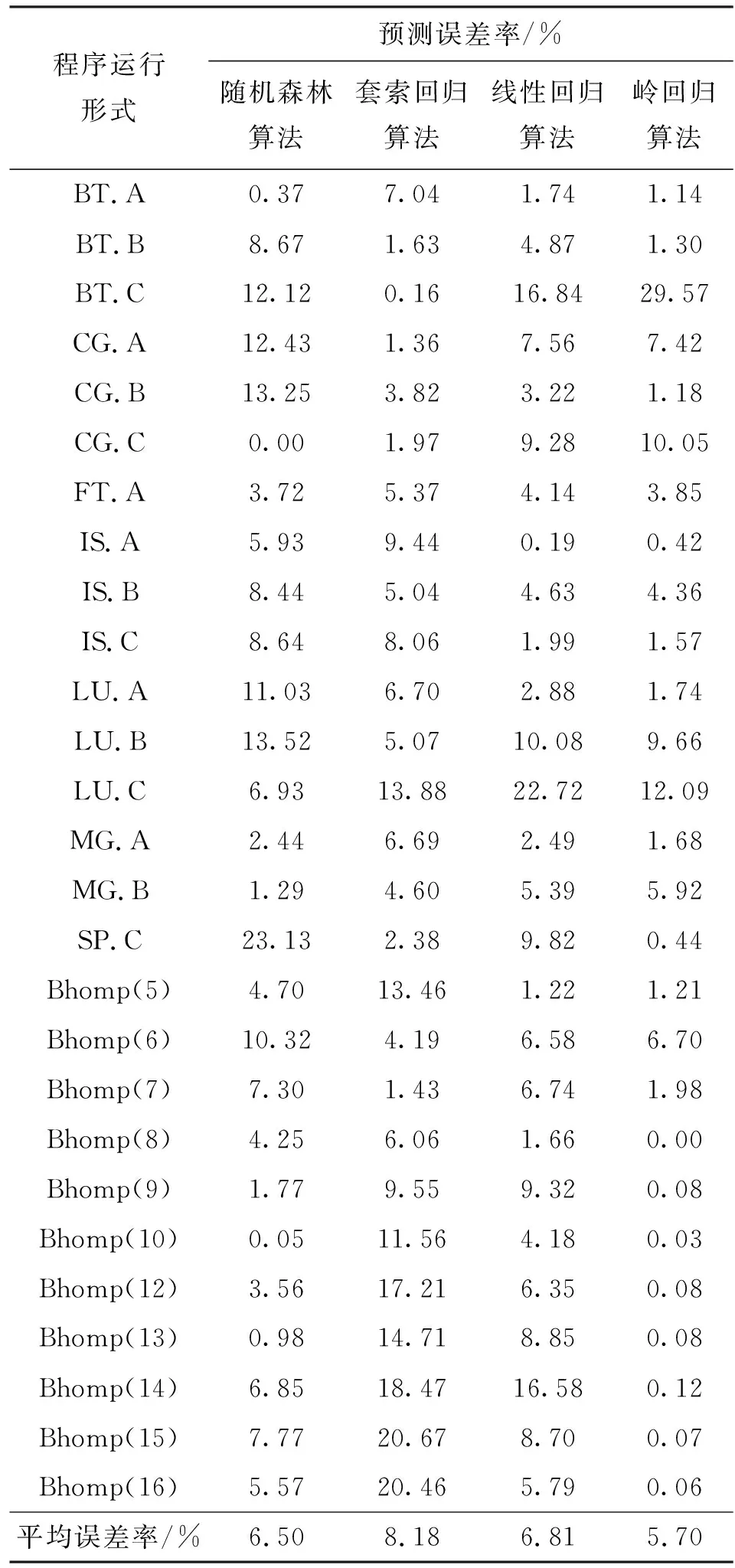
表1 不同机器学习算法软件能耗的预测误差率
c2=[2.45,-1.93,-1.64,1.51,2.44,-3.73,-0.78,2.44,0.1,8.2,1.3,-3.04,1.3,-2.81,1.55,1.69,2.45,2.34,21.51,-0.4,-0.8,-3.71]
3.4.2 实时能耗模型 建立上述能耗模型时,选取性能数据中位数作为训练数据,虽然中位数可以规避数值差异较大带来的问题,但是它不能实时地反映系统的实际运行功率,所以需要建立实时的能耗模型。根据实时的性能信息实时预测出能耗的值。当cache_miss的值大于等于2×107时程序的j时刻(在0.02 s的一段时间内)的实时功耗模型为p1=c1x+b1;当cache_miss的值小于2×107时程序的功耗模型为p2=c2x+b2,对应j时刻的实时能耗模型分别为E1j和E2j,即
E1j=(c1xj+b1)t/N,E2j=(c2xj+b2)t/N
(4)
Perf工具的采样频率为N,程序运行的时间为T,那么在时间T内,Perf工具共采样了TN次。两类程序的平均能耗分别为E1和E2,即
(5)
表2给出了以Bhomp基准测试程序为测试程序的预测误差率结果,从表2可以看出,实时能耗模型预测误差率平均值仅为0.79%,比平均能耗模型预测误差率降低了17%。
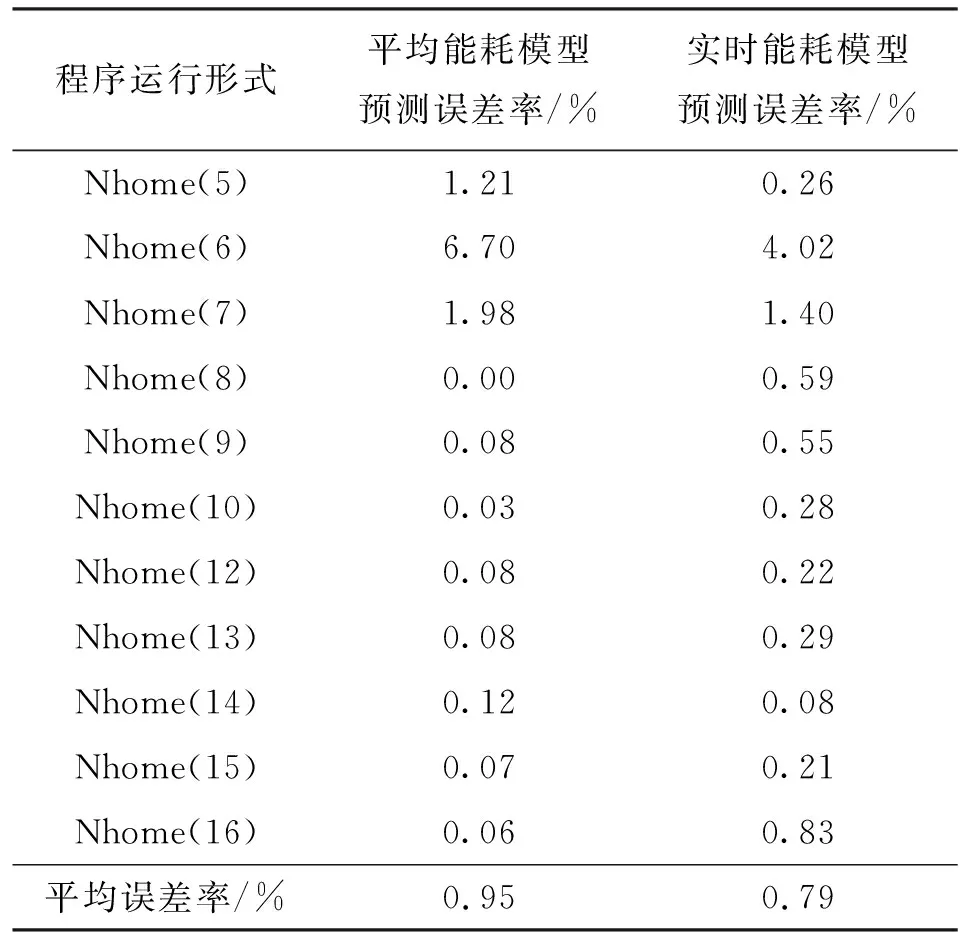
表2 不同应用程序的平均能耗模型和实时能耗模型预测误差率比较
3.5 程序能耗的原因分析
从3.4.1节的能耗模型可以看出,和功耗相关的主要性能特征可以分为以下几类。
(1)与CPU的执行周期有关的参数为cycles、bus_cycles、ref-cycles以及cpu-clock,这些都是和时间相关的参数。这些参数的值越大,程序的执行时间越长,CPU的能耗也越高。
(2)与分支预测相关的参数为branches、branch-misses、branch-loads和branch-load-misses。如果分支预测正确,指令的执行沿最短时间的路线前进,程序的执行时间较短。但是如果这些数值变大,说明程序在分支预测上花费了更多的时间,会延长整个程序的执行时间。
(3)与高速缓存访问相关的参数为cache-references、cache-misses、L1-dcache-loads、L1-dcache-load-misses、dTLB-loads、LLC-loads、LLC-load-misses、LLC-stores、L1-dcache-prefetch-misses。其中cache-references是高速缓存的访问次数,cache-misses是高速缓存访问不命中的次数。一般假定所有的存储器停顿都是由高速缓存缺失引起的,把命中时钟周期数包含在CPU执行时钟周期数中。最后一级高速缓存的读写、TLB的读取、L1数据高速缓存的读取、读取失败的次数以及预测失败的次数都对高速缓存的缺失率起重要作用。CPU频率越高,CPU满载时的功率也越高,每次缺失会需要较多的时钟周期数,从而导致存储器停顿时间延长、性能降低、能耗增加。
(4)与程序的切换有关的参数为cs、migrations。cs是上下文切换的次数,migrations是线程从一个CPU的核转移到另一个核上执行的次数。在计算量较大的情况下,CPU会把一些计算任务转移到空闲的核上去执行。
(5)与程序执行指令条数相关的参数为instructions。指令数是独立于硬件的,一般用来评价性能,在时钟周期不变的情况下,执行的指令越多,程序的执行时间越长。
通过性能参数对CPU的功耗建模,可以揭示功耗产生的原因。当通过调节CPU的功率来降低能耗时,从模型上可以看出调节功耗影响了程序的性能,进而延长了程序的执行时间,从而增加了程序能耗,所以不能为了降低能耗而盲目地降低或者增加CPU的功率。
4 基于能耗预测的能效优化
能效优化可以通过对采用不同方法编写的相同功能的程序对比实验来说明。实验中实际测量与预测的CPU功耗基本一致。实验中所有程序都运行了3次,实验数据取平均值。在第1组递归和非递归程序对比实验中,递归程序运行了6.798 s,CPU的功耗实际测量值为378.994 W,预测值为382.549 W;非递归程序运行了0.201 s,CPU的功耗实际测量值为8.085 W,预测值为7.444 W,可以看出递归程序的能耗较大,原因在于递归程序因为要保护现场占用了太多的资源,因此在编写程序时不建议采用递归方法。本实验的第2组数据是重载和未采用重载操作的程序。采用重载操作的程序运行了58.419 s,CPU的功耗测量值为77.826 W,预测值为78.257 W;而未采用重载操作的程序运行了28.817 s,CPU的功耗测量值为80.522 W,预测值为79.280 W,可以看出采用重载操作的程序运行时间较长,因为带有多个重载操作符的表达式可能会导致临时对象创建中间结果。通过两组程序的能耗对比,为程序员编写高能效的程序提供了依据。
5 结 论
本文提出了一种利用机器学习算法预测软件能耗的方法,并建立了以软件性能事件为特征的能耗模型。在实验中使用了4种机器学习算法,通过预测误差对比实验选取了最适合的岭回归机器学习算法。实验结果表明,以测量能耗为基准的能耗预测误差率低于9%,并且根据模型更容易分析能耗产生的原因。基于模型的能耗预测方法避免了采用程序代码插桩方式测量能耗会影响程序性能的缺点。本文还提出了一种基于性能特征的软件分类方法,即根据cache_miss的阈值将软件分类并分别建模。本模型对计算密集型和内存访问密集型程序的能耗有更精确的预测。下一步我们将基于神经网络和深度学习等算法,结合更大规模的程序数据训练样本,建立更为准确的能耗模型。
