基于SPARK平台的ALS预测模型实验研究∗
2018-11-28姜婷婷杜振军
姜婷婷 杜振军
(大连海事大学 大连 116026)
1 引言
在2000年之前,人类共存储了大约12EB的数据,但是现在我们每天产生2EB的数据[1]。过去两年的时间里产生了世界上百分之九十以上的数据[2]。数据量如此之大,如何将这些数据转换成我们所需的信息,是现在急需解决的问题。
随着信息技术的发展,网络信息的选择已经成为人们最头疼的事情之一,每当人们在网络上购物、听音乐、看电视节目、买票看电影时都会纠结很久,因为呈现在我们眼前的选择太多,无法从这么多的选择中找到性价比高、适合自己的东西,而且在选择的过程中会浪费许多宝贵的时间。然而在这其中你会发现许多不同的客户可能会选择同样的东西,或者同一名客户可能会选择类似的东西[3]。这就是本文研究的主要内容,如何利用这两点来提高预测的准确度。
基于SVD矩阵分解模型的协同过滤算法因为其运算复杂度高,需要的存储空间大,所以没有得到很好的推广[4];以往的算法和实验主要是在单机上进行调试,随着大数据时代的到来,推荐系统需要存储的用户数据和物品数据都在迅猛增长,使得在单机上实现这些算法变得非常慢[5],所以需要将这些算法进行并行计算,从而提高算法的计算效率,加速推荐准确度。
所以本文将在原有研究基础上利用原有的grouplens网站(http://www.gouplens.org)的数据,通过交替最小二乘法(Alternating Least Squares,ALS)模型在Spark平台上的模型训练,得到在现有条件下最优的模型参数,同时将用该文中训练模型得出的结果与用均值预测模型得出的结果进行比较,并且以用均值计算的结果为基准计算本ALS模型性能提升了多少。
2 关键技术
ALS是Alternating Least Squares的缩写,意思为交替最小二乘法。该方法常用于矩阵分解的推荐系统中,它是统计分析中最常用的逼近计算的一种算法,其交替结果使得最终结果尽可能地逼近真实结果[6]。例如,将用户(user)对商品的评分矩阵分解为两个矩阵:一个为商品所包含的隐含特征矩阵,一个为用户对商品隐含特征的偏好矩阵[7]。在这个矩阵分解的过程中,评分缺失项得到了补充,因此可以基于这个填充的评分给用户做一下推荐,具体的算法理论如下:对于Zm*n矩阵,ALS主要是找到 2个低维矩阵Xm*k和 Yn*k,来逼近 Zm*n,即

其中Zm*n表示用户对产品的偏好评分矩阵,Xm*k表示用户对隐含特征的偏好矩阵,YTn*k表示产品所包含的隐含特征矩阵。通常取k<<min(m,n)也就是降维。为了使矩阵X和Y尽可能地接近于Z,需要最小化平方误差损失函数:
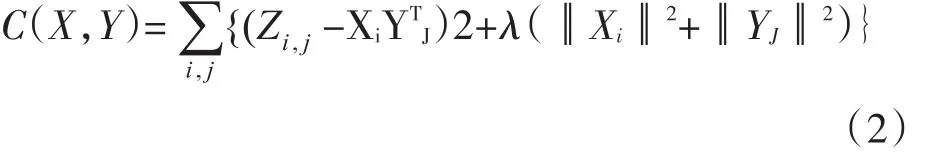
其中Xi表示用户i的偏好隐含特征向量,Yj表示商品 j包含的隐含特征向量,Zi,j表示用户 i对商品 j的偏好评分的近似,λ表示正则化项的系数。求解方法如下:
令 ∂Z/∂Xi=0,
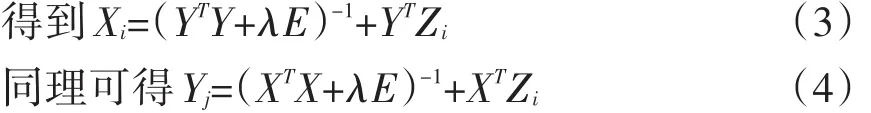
其中Xi是Z的第i行,Yj是Z的第j列,E是k*k的单位矩阵。其迭代步骤是:首先初始化Y,利用式(3)更新得到X,然后利用式(4),更新Y,直到RMSE(均方根误差)变化很小或者达到最大的迭代次数为止,均方根误差公式:
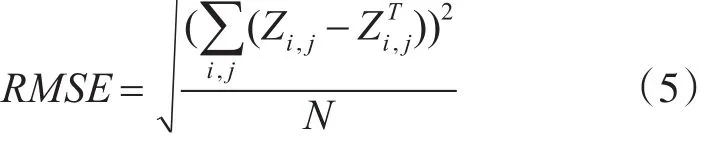
ALS算法功能强大,效果理想而且被证明相对容易并行化。这使得它很适合Spark这样的平台[8]。
Spark Apach是一个分布式计算框架,在各类基于机器学习的和迭代分析的大规模数据处理任务上有广泛的应用[9]。同时它也是一个简单的大数据处理框架,基于MapReduce并行算法实现的分布式计算,对数据分析细致准确[10]。Spark的优点有很多,最主要的有以下几个方面。首先,速度快。上文说到Spark是一个高效的分布式计算平台,不同于需要过多的文件读取操作的Mapreduce,Spark是基于内存的迭代计算框架,将中间结果存放在内存中,不必每次都需要读写磁盘[11];其次,Spark方便易用。Spark提供了80多个高级API,接口丰富,可以使用户快捷地建立自己的并行程序,而且Spark提供对java、scala、python、R四种语言的支持,根据需要选择编程语言[12];再其次,Spark是一个处理大数据的通用引擎,将SQL交互查询、流式处理、图处理、机器学习等无缝结合,可用于多种应用场景,完成多种运算模式。用户不必再采用不同的引擎来处理不同的需求。最后,Spark有多种运算模式,Spark可部署为单机模式,也可部署在hadoop Yarn或者Apache Mesos集群上[13]。
3 实验
程序采用IntelliJIDEA集成开发环境完成。从grouplens网站(http://www.gouplens.org)下载10MB大小的数据集作为本文的数据源,其中数据包含了71567个用户对10681部电影的评分,共10000054条记录[14]。利用这些用户已经做出的评价来训练我们的模型,最后通过比较平均方差MSE,均方根误差RMSE和平均绝对误差MAE的值来查看我们的模型是否达到提高预测准确度的目的[15]。
其中将rating数据分成3部分(基于时间戳的最后一位):train(占60%),validation(20%)和test(占20%)三个数据集。Train数据集用于训练ALS模型,validation数据用于验证模型,得出ALS模型的最优参数。在得出模型的最优参数后,用test数据集做最后的测试。从而得到我们需要的最优参数。
一开始,设rank为20迭代次数为5(rank和迭代次数越大,效果越好,为了节省计算资源,我们先取一个合适的rank值和一个较小的迭代次数:正则参数分别取(0.01,0.1,1,10)。在对每组参数用train数据训练模型后,用validation数据计算均方差MSE、均方根误差RMSE和平均绝对误差MAE。实验数据如表1和图1所示。
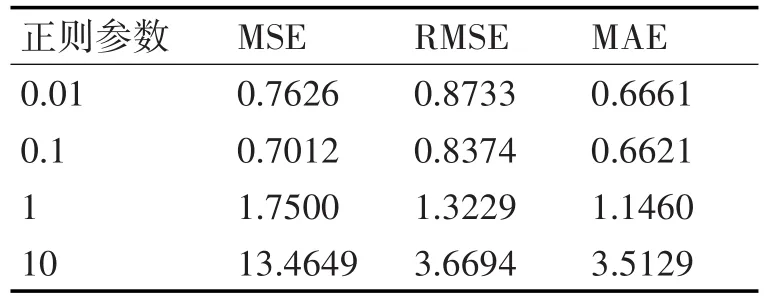
表1 固定rank和迭代次数的值
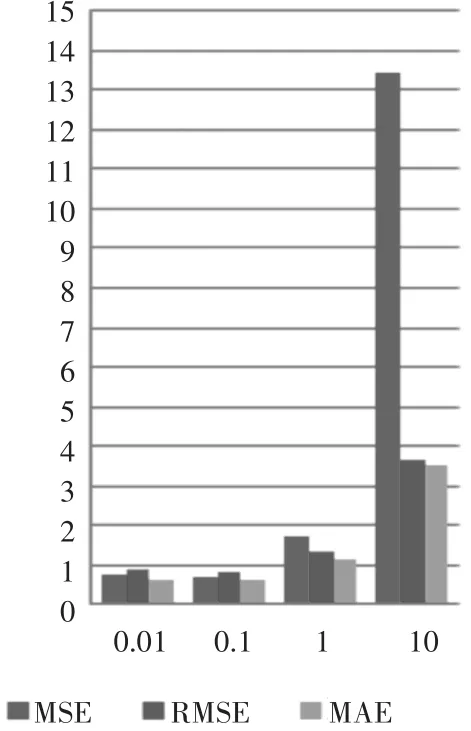
图1 固定rank和迭代次数的值
通过上面的结果,可判断:在rank值取固定值20,迭代次数取5的时候,正则参数lambda取0.1效果最好,下面固定rank=20和lambda=0.1,逐步加大迭代次数为10,15,20,25,30。实验结果如表2和图2。
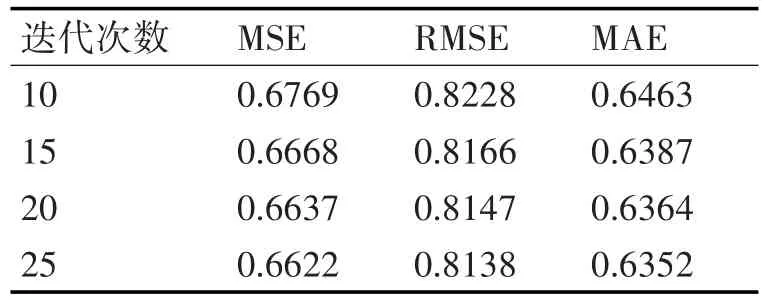
表2 固定rank和正则参数的值
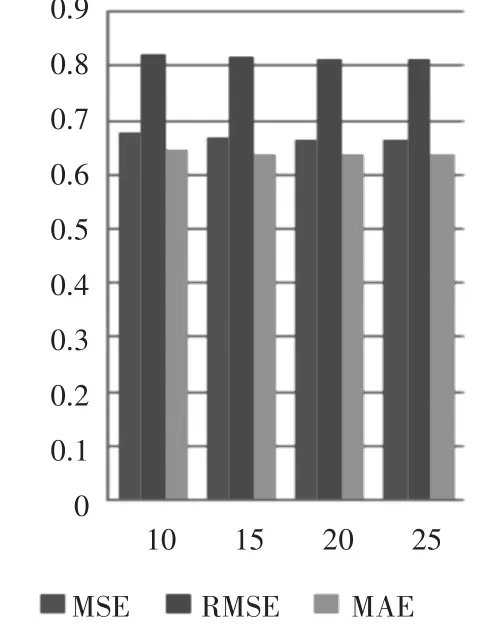
图2 固定rank和正则参数的值
通过上面的结果,在固定rank值为20,正则参数为0.1的时候,迭代次数达到20~25时就已经很好,故迭代次数取20。下面固定迭代次数20和lambda=0.1,加大rank值。当rank值为50的时候,MSE=0.6633,RMSE=0.8144,MAE=0.6365,和 rank为20时相比,几乎无改善,故rank取20。所以目前得到的最优参数为20,20,0.1,该模型计算出的MSE=0.6640,RMSE=0.8147,MAE=0.6364。现在再固定rank=20,在0.1附近寻找最优的正则参数lambda。实验结果表3和图3。
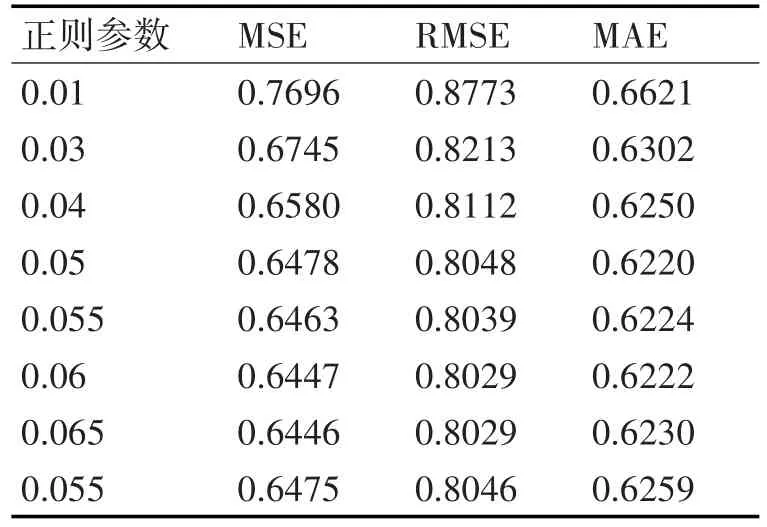
表3 固定rank和迭代次数的值
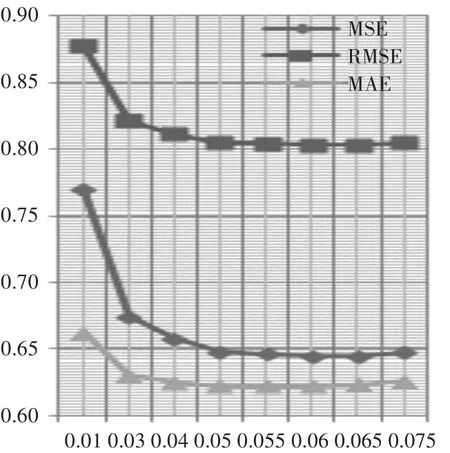
图3 固定rank和迭代次数的值
当lambda=1和lambda=0.1时,相比lambda=1时,值明显恶化。当lambda=0.1/2时,与lambda为0.1时更优。当lambda=0.05和0.1的中值时,和lambda为0.05时对比,RMSE基本没变,但MAE略微升高;当lambda=0.05和0.01的中值,和lambda为0.05时对比,恶化;当lambda=0.05和0.03的中值时,和lambda为0.05时对比,恶化;当lambda=0.05和0.075的大约中值0.06,和lambda为0.05时对比,更好;当取0.065时,与0.06时相比RMSE基本没变,但MAE略微恶化;当取0.055时,和0.06相比,稍有恶化。所以,最优lambda值为0.06,得出最优ALS模型(20,20,0.06)。最后用test数据集测试最有模型(20,20,0.06)的效果,实验效果和validation数据集上实验效果一致,MSE=0.6450,RMSE=0.8031,MAE=0.6222。
最后,将ALS模型和均值模型做对比(在test数据集上计算误差),RMSE改善了24.22%,MAE改善了27.26%。从而证明我们训练的模型的参数得出的预测值准确度提升了。
4 结语
本文主要将ALS模型与Spark平台相结合,通过训练模型参数得到最优的ALS模型。进而证明用最优参数ALS模型得到的值比用平均值更加接近真实值。最优的ALS模型可以提高同一用户对相似物品影片以及相似用户对同一影片的评分的估计值[16]。
本论文的研究内容还有待改进与进一步研究的地方,结合本论文内容与目前研究情况,下一步工作可以从以下几个方面展开:目前研究的课题只适用于实验室的内部环境,并且采用原有的数据集,下一步应该扩展研究,使其应用于真实的环境中;论文中所采用的算法都是最基本的算法问题,下一步的研究可以考虑对算法做出改进,继续加深对最优ALS模型的研究,将预测评分的准确度进一步提高,并对相关用户做出推荐[17];Spark平台适用于多种应用场景,基于其各模块间无缝连接,下一步可以考虑结合更多模块,根据需求实现新的应用研究等。
