基于Fisher准则和Adaboost的语音情感多分类研究∗
2018-11-28刘立龙时满星李月锋
邢 尹 刘立龙 程 胜 时满星 李月锋
(1.桂林理工大学测绘地理信息学院 桂林 541004)(2.兰州理工大学土木工程学院 兰州 730050)
1 引言
语言是人类交流的重要工具,人的语音中不仅包含人的语义信息,也包含情感信息。随着人机交互的越来越紧密,传统的语音识别技术已经不能满足人们的需要。近年来,语音情感识别成为人工智能领域的一个研究热点[1]。在智能的人机交互系统中,通过对操作者的情感进行分析,可以更主动、更准确地完成操作者的指示,实时调整对话方式,使得交流更加友好、更加智能。目前,国内外学者在这方面进行了大量的研究。文献[2]使用高斯混合矢量自回归模型在柏林情感数据集上得到了76%的识别率;文献[3]使用深度信念网络与SVM相结合的算法对语音情感做了深入探讨;文献[4]使用经验模态分解法结合Teager能量对情感语音进行处理,得到了较好的效果;文献[5]使用改进的混合蛙跳算法对SVM进行优化,为实用语音情感识别提供了新思路。
本文在前人研究的基础上,提出了用Adaboost算法对语音情感多分类进行研究。提取了柏林数据集中的生气、开心、中性、伤心和害怕5种情感的140维特征,并采用Fisher准则和分层分类思想有效地实现了情感的分类。在与传统的BP神经网络和SVM模型的分类比较中,结果表明了该算法的有效性。
2 语音情感特征提取
语音情感特征反映了人的情感状态,对最终的情感识别有着重要的影响。经过研究者对心理学和语音语言学的大量研究,目前语音情感特征主要关注在韵律特征和音质特征[6~7]。本文选取了短时能量、基音频率、共振峰、梅尔倒谱系数(MFCC)这4类特征及其衍生参数[8],共构成140维的语音情感特征参数用于识别。在这140维情感特征中,必然存在大量的非重要特征和冗余特征,对特征进一步的处理是必要的。Fisher准则从均值和方差角度对特征进行评价。对d个维度,Fisher判别准则可以用式(1)来表示:
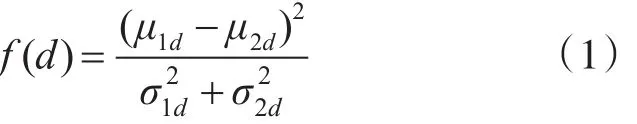
其中,μ1d、μ2d、和为第d个维度两个类别特征值的均值和方差。Fisher判别准则越大,表明该特征区分这两种类别效果越好。对于多类情况,采用式(2)进行计算:

式中,m为类别总数。依据Fisher判别准则,对生气、开心、中性、伤心和害怕5种情感选择出的前14个最佳特征见表1。

表1 前14个最佳特征
3 Adaboost算法
Adaboost算法是1995年由Freund和Schapire在Boosting算法理论基础上提出来的[9],它的主要思想是合并多个“弱”分类器的输出以产生有效分类。算法主要步骤如下:
Step 1:给定输入输出。输入:训练数据集:T={(x1,y1),(x2,y2),…,(xN,yN)} ,其 中 xi∈ X ⊆ Rn,yi∈Y={-1,+1},X为实例空间,Y为标记集合;本文弱分类器采用单层决策树;输出:最终分类器G(x)。
Step 3:对 m=1,2,…M ,使用具有权值分布Dm的训练数据集学习,得到基本分类器:Gm(x):X→{-1,+1}。
Step 4:计算Gm(x)在训练数据集上的分类误差率:

Step 5:计算Gm(x)的系数:
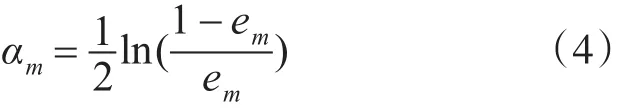
Step 6:更新训练数据集的权值分布:
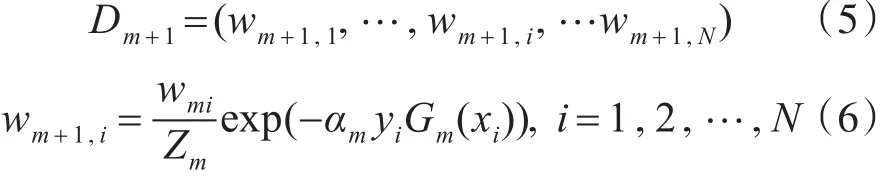
其中,Zm是规范化因子,为

Step 7:构建基本分类器的线性组合:

得到最终分类器:
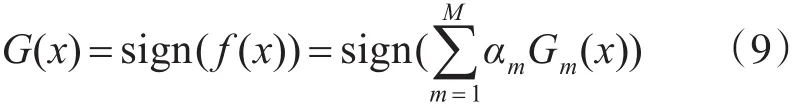
4 语音情感分层分类
Adaboost算法用于多分类问题时,本质上是转化为Adaboost二分类问题[10]。通过将生气、开心、中性、伤心和害怕5种情感进行分层,并逐层处理,最终得到识别结果。本文设置了如下三种二叉树分层方式。图1(a)、(b)顶层为三二情感训练,图1(c)顶层为一一情感训练。其中,图1(a)左边放置三个具备正负情感于一起,图1(b)放置三个相近情感于一起。以图1(a)为例,每个节点设置一个Adaboost分类器,这样共需要设置4个分类器。将初始情感放置于顶层,其中设置生气、开心、中性训练样本对应标签+1,伤心、害怕训练样本对应标签-1;第二层生气、开心训练样本对应标签+1,中性训练样本对应标签-1,伤心训练样本对应标签+1,害怕训练样本对应标签-1;第三层生气训练样本对应标签+1,开心样本对应标签-1。经过4个Ada⁃boost分类器训练,得出4个训练模型。当未知样本从顶层进入时,采用第一个Adaboost模型得出分类结果,进入下一层,由粗及细,逐层处理,并最终得到识别结果。

图1 三种分层方式
5 实验结果及分析
5.1 实验样本
本文实验样本来自于柏林情感语音库[11]。柏林情感语音库是柏林工业大学通过演员表演形式所录制,10名非专业演员(5男5女)对生气、高兴、中性、伤心、害怕、厌恶、无聊7种情感10句录音脚本进行演绎,共录制了800条情感语句,经过20名志愿者试听辨别,最终保留了535条语句。本文选取前5种语音情感,共400条语句构成实验样本,具体为生气126条、高兴68条、中性78条、伤心62条和害怕66条。数据集是以16000采样率,16bit量化,wav格式存储,训练样本与测试样本按照1:1分配。
5.2 语音情感识别实验
本实验在Matlab R2014a平台上进行编程实现。采用Fisher准则进行特征选择,基于15个弱分类器的Adaboost模型,三种分层方式下情感特征个数与5种情感的平均识别率之间的关系如图2。从图2可以看出,采用方式2分层可以达到最大的识别率94%。可能是将相近情感分在一起进行训练,更有利于找出它们之间的内在差异性,从而达到较佳的识别效果。特征选择的原则是在保证识别率的基础上,采用尽可能少的特征。图2中,在最佳14个特征时,达到了最大的识别率,远高于原始140个特征的识别率,说明了Fisher准则对语音情感特征选择是有效的,具体的14个特征见表1。为了更好地说明进行特征选择的优越性,方式2分层下不同特征数的运行时间如图3。从图3可以看出,特征个数与运行时间基本呈线性增长关系。其中,14个特征时,运行时间为0.08109s;140个特征时,运行时间为0.7417s。因此,采用Fisher准则特征选择处理后,大大缩短了运行时间。
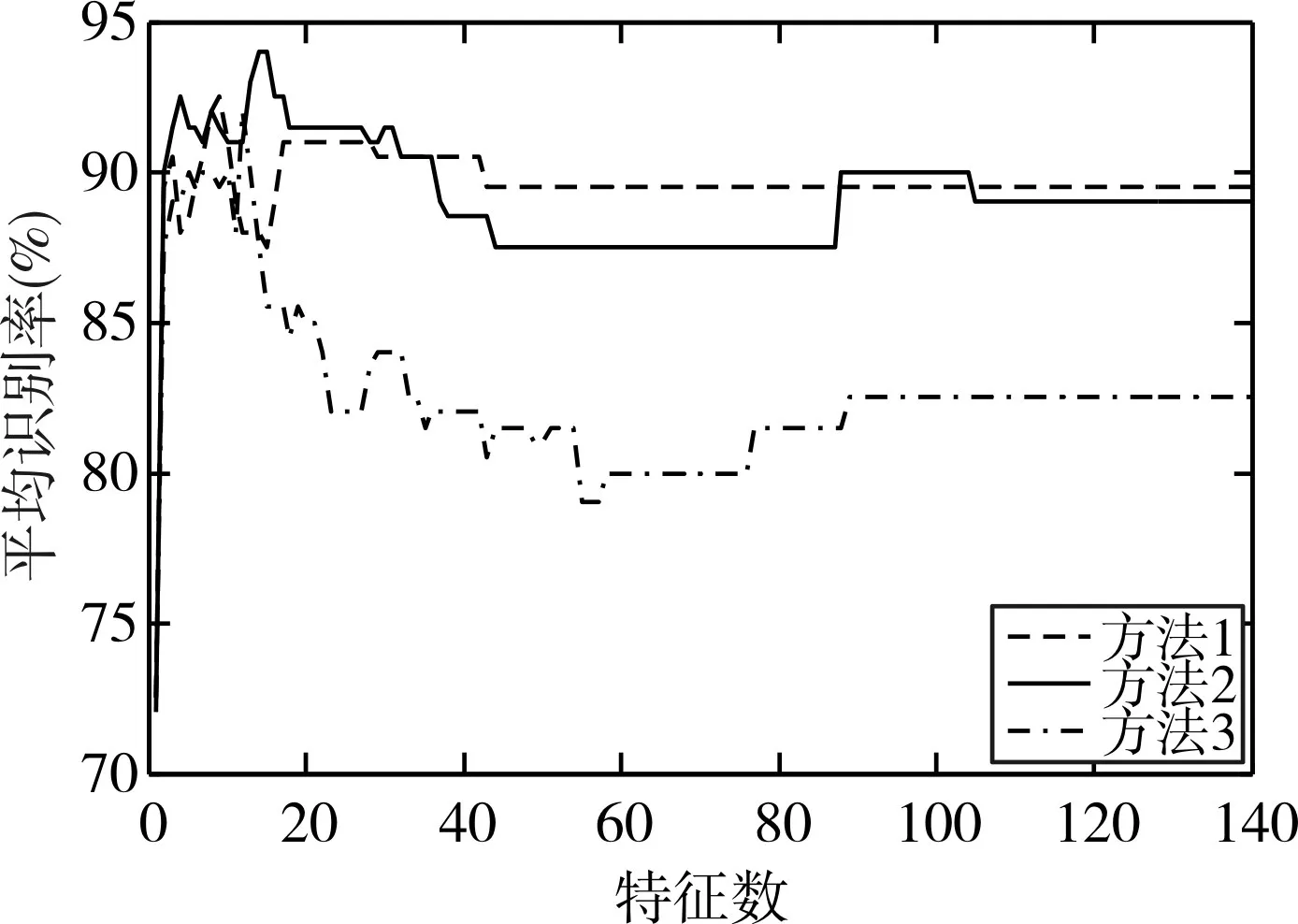
图2 三种分层方式下不同特征数的识别率

图3 方式2下不同特征数的运行时间
在不同数目的弱分类器下,分层方式2下5种情感的平均识别率如图4。从图4中可以看出,并不是采用越多的弱分类器识别效果就越佳。在15个弱分类器时,5种情感的平均识别率达到最大;在19个弱分类器时,平均识别率达到平稳。
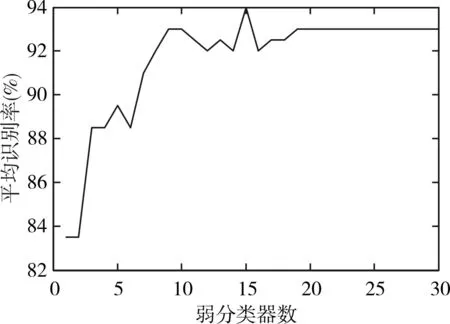
图4 方式2下不同弱分类器数的识别率
为了说明Adaboost算法的优越性,本实验分别建立了BP神经网络和SVM模型对5种情感进行识别。其中,采用的BP网络结构为14-10-5,参数设置:最大迭代次数为20000,目标精度为0.001,学习率为0.1;SVM参数设置:惩罚因子C=2.0,核参数g=1.0,RBF核函数。三种模型识别结果,见表2~4。
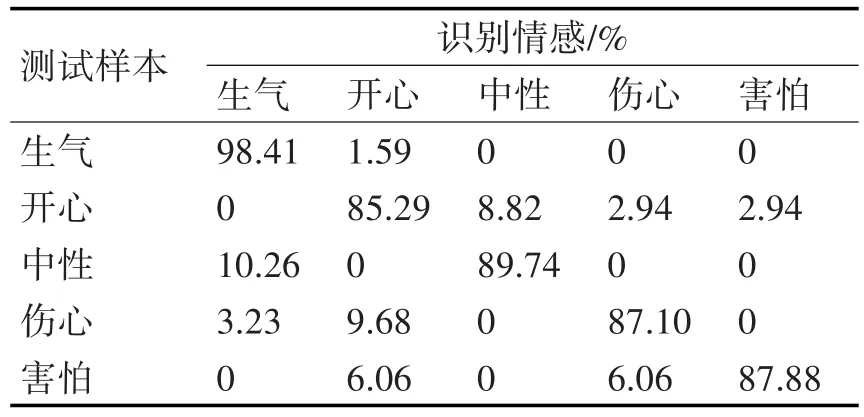
表2 Fisher+BP模型5种情感识别结果
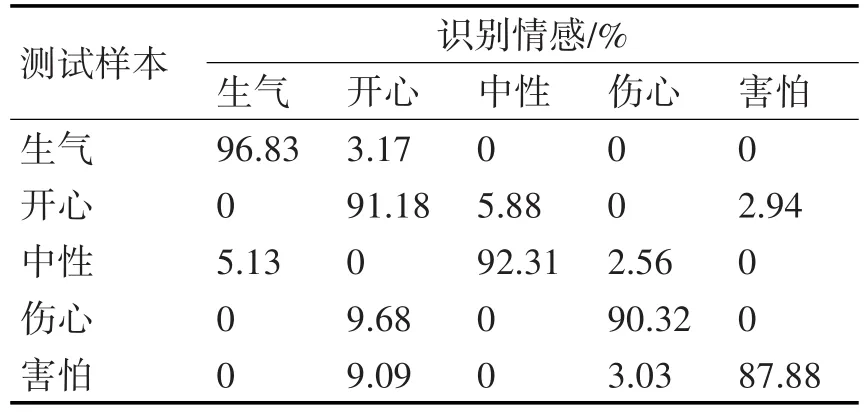
表3 Fisher+SVM模型5种情感识别结果
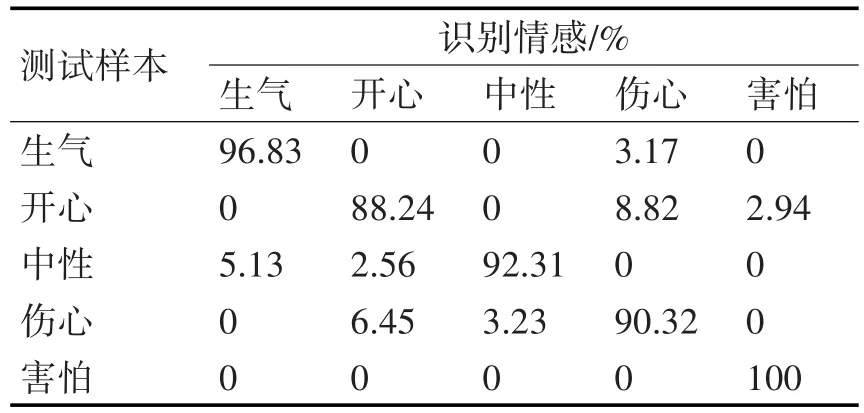
表4 Fisher+Adaboost模型5种情感识别结果
从表2~4可以得出,Fisher+BP模型的平均识别率为91.00%,Fisher+SVM模型的平均识别率为92.50%,而Fisher+Adaboost模型通过集合15个单层决策树构成的强分类器得到了94.00%的识别率,高于Fisher+BP模型3个百分点,高于Fisher+SVM模型1.5个百分点。特别地,Fisher+Adaboost模型对生气、伤心害怕的平均识别率达到了96.06%,而其他两种模型都只有92.91%。一般来说,负面情感对人的影响最大,如果能有效地识别人的负面情感,将有助于提高个体认知和工作效率。采用Fisher+Adaboost模型对负面情感的感知更为敏感,能更为有效地监测负面情感,具有重要的工程意义。
6 结语
本文提出利用Fisher准则对提取的语音情感特征进行评价,选择其中较佳特征。利用Adaboost算法对生气、开心、中性、伤心和害怕5种情感进行分类,实验结果表明,Fisher准则表现出了良好的特征数降低特性,以及将相近的情感状态分在一起训练达到了更佳的分类效果。此外,在与传统的BP和SVM模型比较中,Adaboost算法表现出了优越性。
