2010年中国工业产值公里格网数据集
2018-11-17薛倩宋伟朱会义
薛倩,宋伟,朱会义
1.中国科学院地理科学与资源研究所,陆地表层格局与模拟院重点实验室,北京100101
2.重庆交通大学建筑与城市规划学院,重庆 400074
数据库(集)基本信息简介
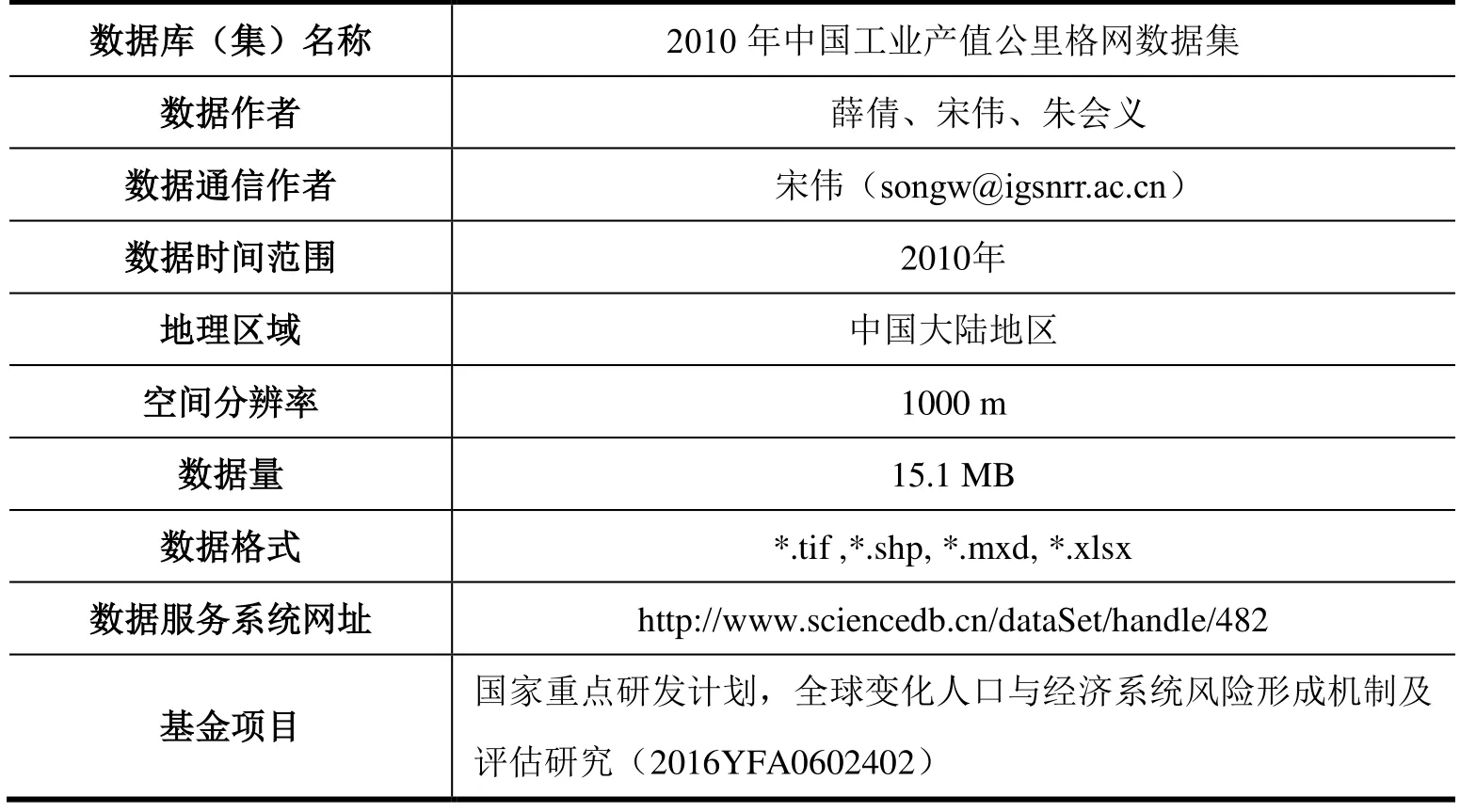
数据库(集)名称 2010年中国工业产值公里格网数据集数据作者 薛倩、宋伟、朱会义数据通信作者 宋伟(songw@igsnrr.ac.cn)数据时间范围 2010年地理区域 中国大陆地区空间分辨率 1000 m数据量 15.1 MB数据格式 *.tif ,*.shp, *.mxd, *.xlsx数据服务系统网址 http://www.sciencedb.cn/dataSet/handle/482基金项目 国家重点研发计划,全球变化人口与经济系统风险形成机制及评估研究(2016YFA0602402)

数据库(集)组成数据集由3部分数据组成,其中:1 2010年中国工业产值公里格网数据集.gdb.zip是包含行政边界信息以及栅格格式的中国2010年每公里工业产值数据(13.8 MB)。2.精度验证.xls是全国90个城市工业产值统计数据和验证精度说明(23 KB)。3.2010年中国工业产值公里格网数据集.mxd是可编写的ArcGIS数据文件(730 KB)。
引 言
辨析气候变化下的社会经济系统风险是目前气候变化研究的重点内容之一[1]。就工业系统而言,气候变化一方面通过均值波动间接对工业行业的原料存储、加工以及运输过程产生影响[2],另一方面通过极端气候事件对工业生产的各个环节及工作人员产生破坏性的影响(例如工厂基础设施破坏、人员伤亡等)[3-4]。准确评估气候变化带来的工业经济系统风险与损失,依赖于较高精度的工业经济系统暴露分析[5],工业产值的空间分布制图则是工业经济系统暴露分析的重要基础数据之一。
近年来,国内外在国内生产总值(GDP,Gross domestic product)空间分布制图方面已经取得了比较多的进展[6]。但是,由于常规的遥感手段很难在空间上实现第二、三产业产值的准确识别,全球以及中国工业产值格网数据仍然相对缺乏。目前,已有的一些工业经济系统产值数据空间化制图,多为省、市、县级尺度[7],且空间分辨率多以行政区为最小单元,无法表征省或者城市内部工业产值的差异及空间分布,在风险评估中很难与气候格网数据等开展叠加分析;基于此,也有一些针对工业某一具体行业产值的空间化研究数据[8-9],但是总体上缺少大尺度(中国)、高分辨率、综合性的工业产值空间化数据。所以,本数据集结合DMSP/OLS夜间灯光数据、中国各省工业产值统计数据以及MODIS中的植被指数产品,对中国 2010年工业产值进行遥感反演,并利用工业用地空间分布数据对其进行修正,形成中国1 km分辨率的工业产值格网数据集。本数据集可以为全球变化中工业经济系统的风险与灾害评估等提供基础数据支撑。
1 数据采集和处理方法
本数据集构建过程包括数据收集、夜间灯光数据和植被指数数据预处理、构建基于增强型植被指数的夜间灯光调整指数(EANTLI)及利用工业用地空间分布数据进行灯光修正、构建分配模型、数据质量精度验证几个步骤(图1)。
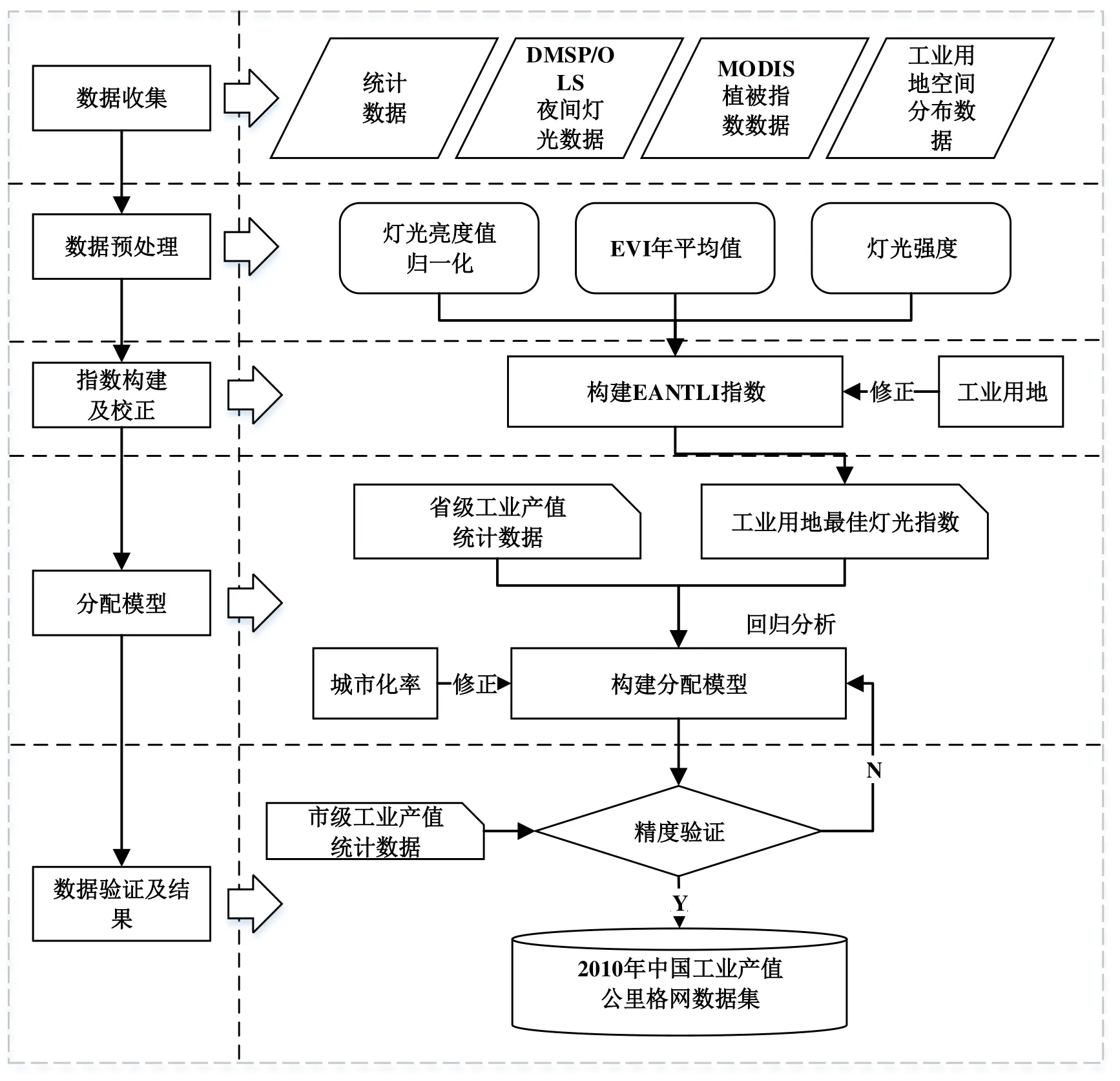
图1 数据集构建及处理流程
1.1 数据来源
本数据集对工业的定义以世界银行数据统计标准为主,包含采矿、制造、建筑、电力、水和天然气生产和供应业,与中国统计局差别在于将建筑业纳入了工业。所以,本数据集中所采用的 2010年全国各省份工业产值和市级工业产值数据为工业产值和建筑业产值之和。数据均来自于国家统计局发布的《中国统计年鉴》和各省统计年鉴(http://www.stats.gov.cn/tjsj/ndsj/)。
夜间灯光数据选取美国气象卫星DMSP/OLS成像得到的非辐射定标夜间平均灯光产品。其优势在于能通过灯光强度变化反应地理实体信息,特别地,该产品中的稳定灯光数据通常被用于提取城市区域[10-11]、反演社会经济数据[12-13]等研究中。本数据集所选取的夜间灯光数据为稳定灯光数据(https://ngdc.noaa.gov),其空间分辨率为1 km,像元灰度值(DN,Digital number)范围为0~63,数据时间为2010年。由于DMSP/OLS数据存在的饱和与溢出现象会削弱灯光数据和社会经济数据的相关性[14],并影响反演精度。而且有研究表明,植被指数和灯光强度值变化存在较好相关关系[15],因此可以通过植被指数来消除夜间灯光数据的饱和与溢出现象对社会经济数据反演的影响。所以本数据集选取空间分辨率为1 km的MODIS月合成植被指数产品(MOD13A3)中的增强型植被指数(EVI,Enhanced vegetation index)(http://ladsweb.nascom.nasa.gov/data)对灯光饱和与溢出现象进行预处理。
此外,选取中国科学院资源环境科学数据中心 2010年工业用地空间分布数据(http://www.resdc.cn)对EANTLI指数进行精度修正。
1.2 数据处理
利用夜间灯光数据与植被指数之间关系消除灯光数据饱和与溢出现象,并构建最佳灯光指数,同时利用工业用地空间分布数据对其进行修正,得到工业用地上的最佳灯光数据,并与工业产值数据构建分配模型。此外,针对西部地区工业产值较低且工业用地分布较为离散造成的较大低估现象问题,利用城市化率对新疆、西藏等四个灯光值较弱的省份进行修正,最终形成2010年中国工业产值公里格网数据集。具体流程如下:
(1)对夜间灯光数据进行预处理,包括按行政边界剪裁、二值化、归一化等,提取灯光强度值,并计算归一化的灯光强度值;
(2)对MODIS植被指数数据进行处理,从MOD13A3产品中提取出中国2010年1-12月的EVI,然后进行初步的剪裁、镶嵌、投影等工作;
(3)EVI数据处理,计算EVI的均值,为去除月份不同对夜光数据造成的敏感性,所以本数据集选取EVI全年12个月的均值数据,并剔除EVI小于0.01的区域,此区域包括水体、裸岩等无人区域;
(4)构建最佳灯光指数,其计算公式如式(1)[14]:
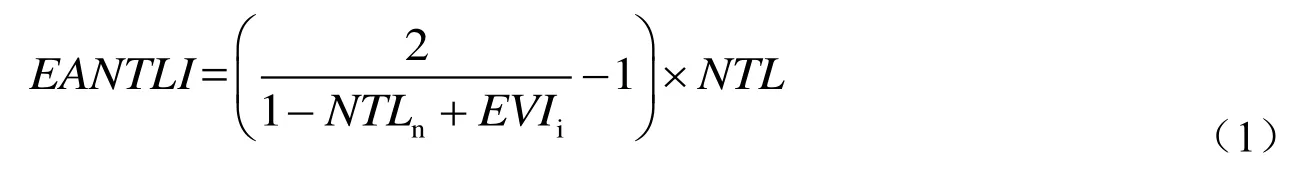
其中,EANTLI为最佳灯光指数,NTLn为归一化灯光强度,EVIi指处理过后的EVI数据,NTL为原始灯光强度。
EANTLI能够较大程度上削减灯光饱和与溢出现象,以凸显城市内部灯光强度差异,更好地对经济数据进行反演。
(5)通过工业用地空间分布数据对第4步得到的EANTLI指数结果进行修正,本数据集认为仅工业用地上存在工业产值,通过工业用地数据对EANTLI指数进行工业工地上的灯光值提取,得到工业用地最佳灯光指数EI。
(6)利用国家统计局《中国统计年鉴》[16]中计算得到的全国各省 2010年工业产值数据与工业用地最佳灯光指数进行回归分析,构建分配模型:
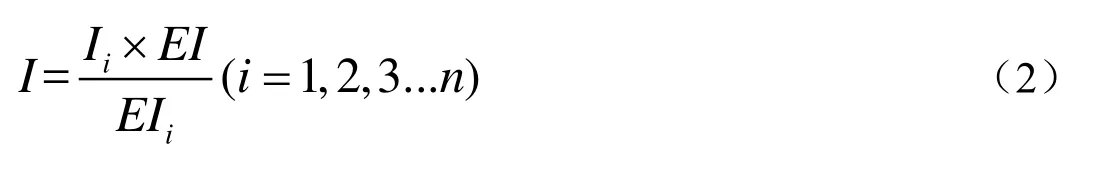
其中,I代表每个栅格上的工业产值,Ii代表每个各省的工业产值,EIi代表每个省的工业用地最佳灯光指数。
经过该步骤,初步获得到工业产值公里格网数据。
(7)通过对第6步获得的数据验证发现,由于新疆、青海、西藏、云南四个省份的工业产值较低、工业用地较少且分布较为离散,导致存在较大的产值低估现象。针对这个问题,本数据集利用与工业产值在市级尺度上存在显著相关(0.01置信度水平下)的辅助数据——四个省份的土地城市化率进行构建多元线性回归模型进行数据修正,模型如下:

其中Ig代表修正后的工业产值,In代表第(6)步中得到第n个栅格的工业产值,Un代表第n个栅格的城市化率,a、b分别为In、Un的参数,c为常量。
(8)利用市级统计年鉴验证各城市工业产值数据精度,满足则得到最终 2010年中国工业产值公里格网数据集,否则重新构建分配模型。
2 数据样本描述
经过数据处理,得到2010年中国工业产值公里格网数据集。本数据集可以比较清晰地反映每公里工业产值的空间分布特征。由于地理位置及政策优势,我国工业产值的高值区域主要分布在我国沿海区域,特别是长三角、珠三角、环渤海等几个典型地区(图 2);而西北地区由于地处内陆,交通运输条件较差,工业产值普遍较低,且呈点状零星分布,且相较于沿海区域数值明显较低。
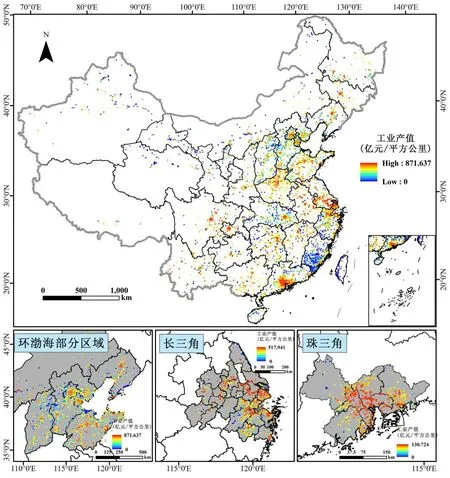
图2 2010年中国工业产值公里格网数据(审图号:GS(2018)2341号)
3 数据质量控制和评估
数据验证时,开展了省级工业用地最佳灯光数据与工业产值的相关性分析,结果显示两者显著相关(在0.01置信度水平下),且相关系数达到0.72。同时,随机选取了全国105个不同市级行政单位(图3),利用ArcGIS的统计工具,将工业产值公里格网数据进行统计,并与市级统计年鉴中计算得到的工业产值数据进行对比。整体而言,平均精度达到81.40%(图4)。为了使数据能够给其他行业深度分析带来参考,我们又按照城市主导功能的不同,从 105个验证样本中挑选了不同产业类型城市进行了精度验证比较。按照全国资源型城市可持续发展规划(2013-2020年)的分类标准和相关文献[17-18],选取了11个资源型城市、10个综合型城市和17个工业型城市(表1)进行验证比较,结果表明资源型城市整体平均精度为82.27%,其中7个煤炭型城市平均精度为82.75%,1个有色金属城市精度为94.08%,3个石油城市平均精度77.22%;总体而言,综合型城市整体平均精度为82.34%;工业型城市整体平均精度为 77.25%。不过,部分西部欠发达区域精度略低,环渤海区域、长三角、珠三角等工业较发达区域工业产值反演精度较高。西部地区精度偏低的主要原因在于经济发展水平偏低导致区域灯光强度较弱,且内部差异较小,使得反演精度偏低。为了解决这个问题,我们利用与工业产值有较好相关性的城市化率数据对新疆、西藏、青海、云南四个省份进行了数据校正,校正后精度有较大的提升,提高了 12.1个百分点(由 62.4%提高到74.5%)。
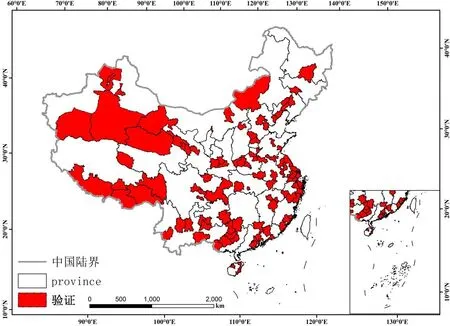
图3 精度验证选择的105个样本城市的位置(审图号:GS(2018)2341号)

图4 数据集中数据与统计年鉴数据对比及精度

表1 分类型城市精度验证
本数据处理过程在地理信息系统软件ArcGIS平台下进行,数据处理过程科学合理规范,保证了数据空间分辨率的准确性和可靠性。
4 数据价值
工业产值公里格网数据打破了行政边界的限制,通过夜间灯光数据对工业产值数据进行大尺度反演,得到高精度、高分辨率空间化的栅格数据,从而可以直观地分析工业产值区域间数量差异以及时空分布特征,为划分中国工业重点区域、厘清工业产业变化趋势、评估工业用地效率等提供了数据支撑,特别是为气候变化下工业产业暴露及脆弱性评估提供了基础数据,从而为工业布局规划及极端灾害条件下工业产业受灾预警及灾害评估提供参考。
此外,本数据集中工业定义以世界银行中工业定义为准,可用于全球尺度的工业产值变化评估研究。特别地,虽然全球或者区域空间化产品较多,但大都是 GDP、人口的空间化产品,特别是现有GDP空间化数据集大多是对二三产业合并处理,鲜有单独的二产或三产空间化数据集产品。本数据集提出的遥感反演、工业用地修正、城市化率修正等方法,能够有效在空间上区分第二与第三产业产值,丰富了社会经济数据的空间化方法,为以后的类似研究提供了借鉴。在精度上,本数据集的平均精度达到了81.40%,相较于以往类似研究有了明显提升。
5 数据使用方法和建议
本数据集中包含工业产值公里格网文件(.tif)和检验数据文件(.xls)以及处理过程数据库(.gdb),可用ArcGIS软件对数据进行读写,也可用 Python 等主流编程语言调用相关函数库读写,实现数据批处理。
对于全球气候变化的相关研究工作,1km的全国工业产值数据集可以满足目前研究的精度。同时,1km也是夜间灯光影像数据、MODIS 植被指数数据、土地利用栅格数据(全国尺度)常用的空间分辨率,这个分辨率能够最好地匹配制作工业产值所需的空间基础数据。鉴于制作工业产值空间化反演的基础数据在空间分辨率均为 1km,数据集的分辨率已达到最高。如果后期需要匹配大尺度低分辨的气象数据(如0.1°,0.25°等),可以借助于百分比栅格的方法对数据集进行升尺度,这个方法不会影响降低分辨率之后的数据集精度。
此外,在数据集更新方面,我们在此数据集的基础上会根据基础数据——土地利用(更新周期:5年)、夜间灯光影像数据(更新周期:1年)、MODIS植被指数数据(更新周期:1年)、统计年鉴数据(更新周期:1年)的更新周期进行数据更新,拟依据更新周期最长的土地利用数据的更新周期(5年)进行数据集更新。同时,对未来工业产值格网格化数据,我们会通过动力降尺度的方法进行多源数据融合模拟,制作未来不同气候变化情景下的工业产值空间数据。
猜你喜欢
杂志排行

中国科学数据(中英文网络版)的其它文章
- 中国四川省峨眉山特有小鲵类(两栖纲,有尾目)龙洞山溪鲵(Batrachuperus londongensis Liu and Tian, 1978)正模标本骨骼μCT三维数据集
- 2011~2017年“银河画卷”巡天数据集
- A dataset of agro-meteorological disasteraffected area and grain loss in China (1949 –2015)
- A social media-based dataset of typhoon disasters, 2017
- A dataset of Ya’an Earthquake based on social media
- 2017年我国沿海渔港地理分布数据集