2017年我国沿海渔港地理分布数据集
2018-11-17陈孟婕徐硕刘慧媛蒋庆朝
陈孟婕,徐硕*,刘慧媛,蒋庆朝
1.中国水产科学研究院渔业工程研究所,中国水产科学研究院渔业信息工程研究中心,渔业信息工程功能实验室,北京 100141
数据库(集)基本信息简介
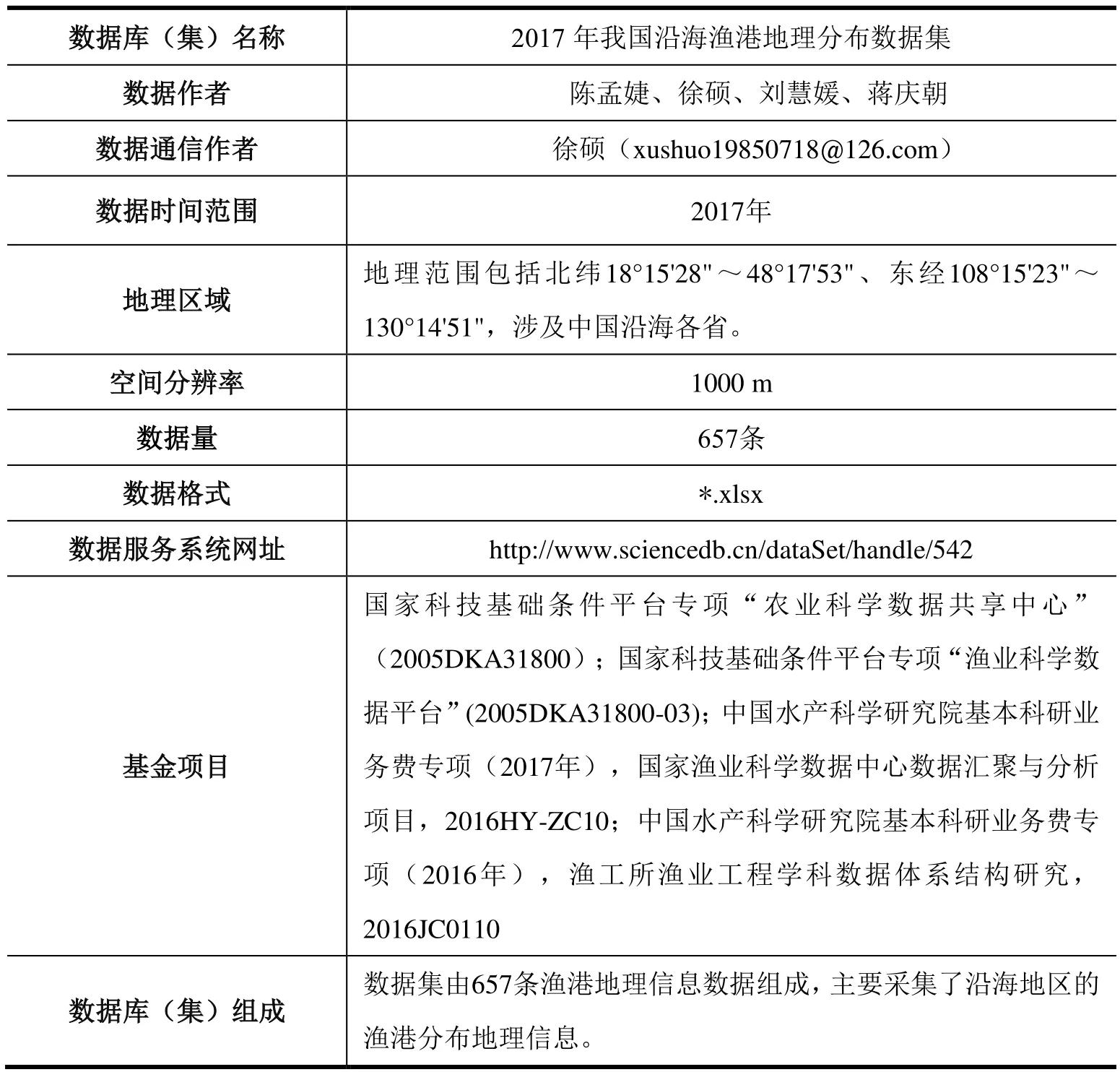
数据库(集)名称 2017年我国沿海渔港地理分布数据集数据作者 陈孟婕、徐硕、刘慧媛、蒋庆朝数据通信作者 徐硕(xushuo19850718@126.com)数据时间范围 2017年地理区域 地理范围包括北纬18°15'28"~48°17'53"、东经108°15'23"~130°14'51",涉及中国沿海各省。空间分辨率 1000 m数据量 657条数据格式 *.xlsx数据服务系统网址 http://www.sciencedb.cn/dataSet/handle/542基金项目国家科技基础条件平台专项“农业科学数据共享中心”(2005DKA31800);国家科技基础条件平台专项“渔业科学数据平台”(2005DKA31800-03);中国水产科学研究院基本科研业务费专项(2017年),国家渔业科学数据中心数据汇聚与分析项目,2016HY-ZC10;中国水产科学研究院基本科研业务费专项(2016年),渔工所渔业工程学科数据体系结构研究,2016JC0110数据库(集)组成 数据集由657条渔港地理信息数据组成,主要采集了沿海地区的渔港分布地理信息。
引 言
在移动互联网时代,地理信息应用,尤其是基于位置的应用,在交通、购物、餐饮等领域开始广泛发展和尝试,并极大地改变了人们的生活方式。人们对于地理上下文信息的需求进一步驱动了该技术的发展[1-5]。在渔业科学数据资源中,地理属性信息隐含在数据属性、数据细节里。开展数据的地理属性分析以及应用研究,促进用户对数据的理解,是渔业科学数据的重要研究方向。渔业科学数据平台[6]汇聚了丰富的渔业科学数据集,并在平台上开放给用户获取和使用。不足是用户对数据集的访问量与数据集在平台上的展示位置直接相关,并且由于数据间关系、数据与用户的关系不明显,因此,数据主动服务能力较弱。为了提高用户对数据的兴趣,解决位置带来的数据访问量偏差,目前,较常见的技术方法是研究数据的个性化服务、数据挖掘、机器学习等[7-8]。对于该问题的另一种解决思路是,挖掘数据中的地理属性信息,便于为数据、用户建立地理上、位置上的上下文相关环境,以最直观的地图方式为用户展示数据,促进用户对关联数据的访问和使用。因此,本文选取具有代表性的数据集,采集地理属性信息,形成新的数据集,为今后的数据科研以及支撑工作奠定基础。
“渔港数量、分布、功能与现状数据库”[9]中,提供了全国1300多个渔港的避风等级、码头长度等参数的数据属性,同时还提供了文本结构的“地理位置”属性,例如大连市大连湾、东港市前阳镇等描述信息,表明该数据集具有鲜明的地理属性特点,可以通过相关技术手段,将数据转换成便于地理位置标记的格式。本文通过运用字符串处理工具、位置解析工具、JS脚本语言等相关技术,对“渔港数量、分布、功能与现状数据库”数据进行解析,得到量化的地理属性信息,为地理相关的渔港研究与实施工作提供基础数据支持。
1 数据采集和处理方法
1.1 数据来源与数据概况
本数据集由“渔港数量、分布、功能与现状数据库”通过一定的计算方法获取,因此,这两个数据集的关系是因果关系。“渔港数量、分布、功能与现状数据库”的数据来源于农业部1990年公布的我国大陆沿海的渔业港口数据,属于渔业科技基础数据,数据详细内容在渔业科学数据共享平台中提供,其在线链接地址为http://fishery.agridata.cn/grade3.asp?st=llsj&id=A040361。该数据集的数据饱满度为85.5%,根据字段缺失数量与所有记录总字段数量的比值计算得到,其中地理位置的饱满度为99.2%,相对完整。因此,选取该数据集进行加工处理。
本数据集目前完成了数据采集、处理与存储过程,并已发布在渔业科学数据平台网站上,其访问地址为http://fishery.agridata.cn/grade3.asp?st=llsj&id=A040364。
1.2 数据采集与处理
1.2.1 总体流程图
数据采集及处理流程包括五个阶段:原始数据预处理、地理数据采集、数据加工处理、数据关联、数据校验。数据采集及处理总流程如图1所示。后续章节将展开介绍各个阶段的处理方法。
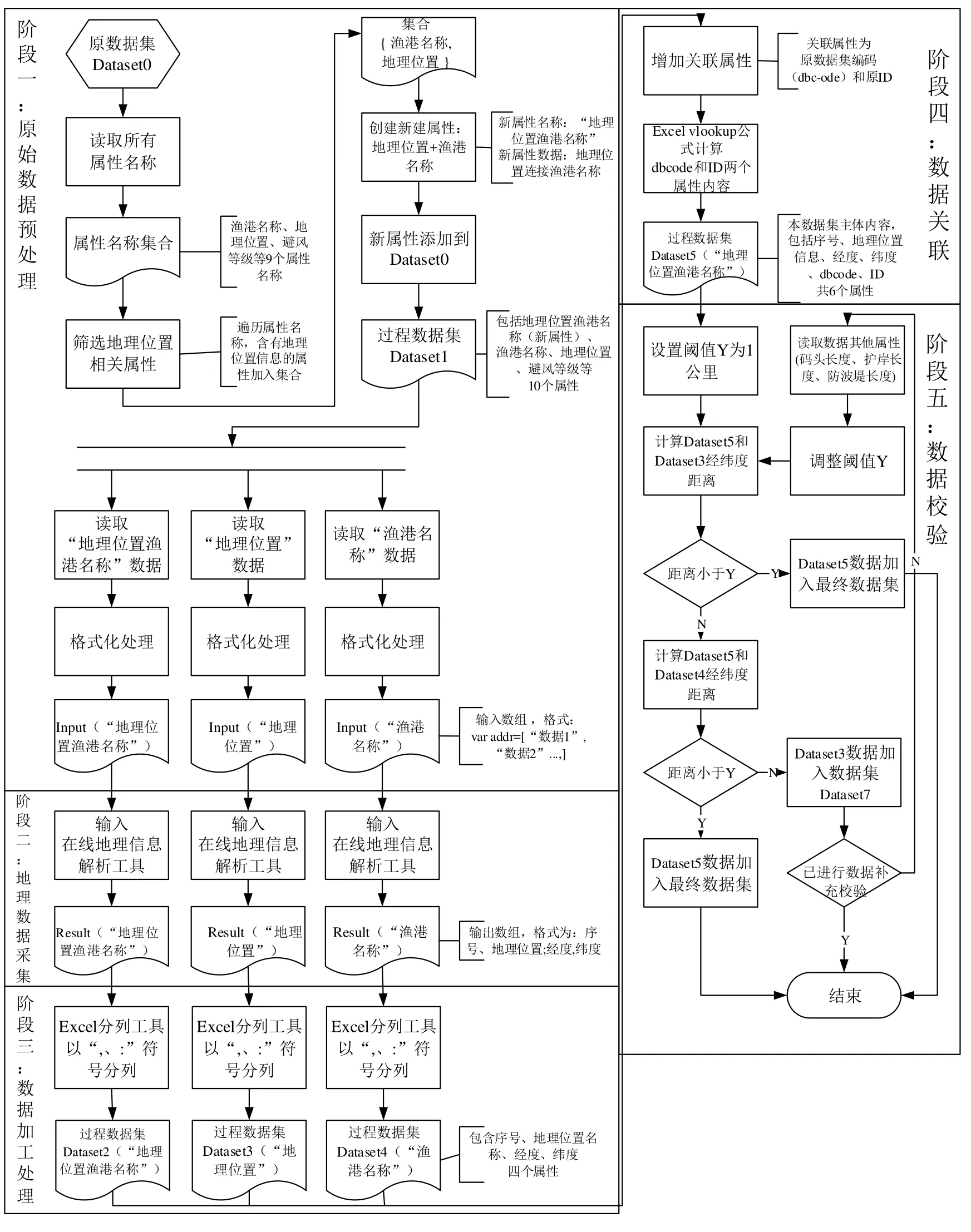
图1 数据处理总流程
1.2.2 原始数据预处理
在原始数据集中,每条数据由渔港名称、地理位置、避风等级、码头长度、护岸长度、防波堤长度、数据提供单位、更新日期、更新时间组成。查看数据详情,地理信息包含在渔港名称、地理位置2个属性中,而其他字段只与渔港本身的特性相关。原始渔港数据集中,有11条数据的地理位置属性未填写。对于这些渔港数据,只能通过渔港名称进行地理信息辨别。对于其他记录完整的情况,增加“地理位置渔港名称”字段,其内容为渔港名称、地理位置2个属性的拼接,得到完整的地理属性信息,作为数据加工处理的原材料。根据地址解析工具的输入数据要求,将数据集所有的“地理位置渔港名称”字段拼接成字符串数组格式,如图2所示。

图2 数据输入格式
1.2.3 地理数据采集
在数据预处理后,数据采集的任务是对渔港地理属性信息的进一步处理,实现定性的自然地理位置属性与定量的地理坐标信息的转换。
国际经纬度坐标标准为WGS-84,称作大地坐标,是目前广泛使用的GPS全球卫星定位系统使用的坐标系。国内必须使用国测局制定的GCJ-02坐标系(也称火星坐标系),对地理位置进行首次加密。通过常用的在线地图应用,如百度地图、高德地图、腾讯地图等,都提供了地理坐标拾取技术,即通过提供自然地理位置信息,得到绝对的经纬度坐标信息。出于安全考虑,各个服务提供商并不提供真实的坐标,而是对数据进行不同加密技术的处理后再提供给用户。因此,其经纬度数值与真实值之间有一定偏差,而对于数据的位置关系分析、用户与数据关系分析并不影响。在我国信息安全允许范围内,本文采集了经加密处理的地理坐标信息。
本文选取百度坐标系作为数据标准,以百度开放平台的在线源代码编辑器作为工具采集地理坐标信息。首先,百度坐标在火星坐标系的基础上,进行了BD-09二次加密措施,更加保护了个人隐私。其次,百度在坐标转换技术上提供了批量的坐标转换的接口,包括地址解析和不同坐标系坐标的转换,具有更高的坐标转换效率。第三,工具对于输入的数据具有一定的容错性,并可以自动补全地址描述信息。第四,开放平台还提供了完整的文档,尤其是完整的演示Demo,使工具的使用简单易懂,并支持多种技术二次开发,如Android开发、IOS开发、Web开发、服务接口调用。针对本文中数据集采集需求,选择JavaScript接口的批量地址解析工具,其访问地址为http://lbsyun.baidu.com/jsdemo.htm?a#i7_3。
批量地址解析工具的输入是地理位置组成的字符串数组,输出是序号、地理位置、经度值、纬度值组成的地址信息。将预处理好的数据,代入该工具源代码中运行,得到输出结果A,执行时间约为10分钟,包含了网络延迟以及每条数据处理的等待时间,得到的输出结果1046条,其输出片段如图3所示。
为了后期对结果校验,将地理位置和渔港名称分别作为输入数据,利用工具得到另外两组输出结果,分别为输入结果B约900条、输出结果C约200条。对于原数据集的渔港数据,有11.11%渔港数据在3组输出结果中都没有获取地理坐标信息,需要运用其他的地理信息转换方法进行坐标转换。这些数据可以作为渔港地理分布数据集今后的增补数据来源。而3组输出结果中,A通过详细的输入信息获取;B的输入数据在语义上地理覆盖面更广,得到的结果相对粗略,而且有很多重复的数据;C的位置较精细,查询的结果也较少。
1.2.4 数据加工处理
地址解析工具的输出结果是非结构化的文本存储格式。优点是体积较小,查看方便,适用于少量数据的存储。当数据量增多,数据查询、处理需求越来越复杂,需要将文本格式转换为结构化数据存储格式。常见的方法是用程序逐行读取数据并转换成结构化存储格式,另一种更为简单有效的方法是利用Excel电子表格丰富的数据函数来处理。通过结构化处理,新的数据集与原始数据集可以建立更加清晰的对应关系,例如以渔港名称作为关联字段。
对于规范化的输出结果A,采用Excel处理。Excel有多种处理技巧,其一,直接书写公式,截取渔港名称、两个地理坐标,涉及的函数为字符串截取函数 MID、字符位置查找函数FIND。例如,截取渔港名称的公式为:MID(A1,FIND("、",A1)+1,FIND(":",A1)-1-FIND("、",A1)),A1即输出结果A的一条记录。其二,Excel预定义了便捷操作,可以直接利用数据分列工具,以预定义分隔符或者指定特殊的分隔符,对数据进行切割,分成多列,分割过程如图4所示。通过分列得到的数据结果可以直接存储为结构化数据。
1.2.5 数据关联
数据基本转换为结构化数据存储格式后,初步形成了本数据集的主要内容。但由于该数据集关注点为地理分布,并不涉及渔港的其他参数信息,因此需要将新的数据集与原数据集“渔港数量、分布、功能与现状数据库”进行关联。
通过解析原数据集所在的发布平台“渔业科学数据平台”的链接地址,可以得到新数据在原数据集中的唯一标识。例如,渔港名称为“丹东市海洋红中心渔港”的数据记录,其唯一标识符id为2,如图5所示。
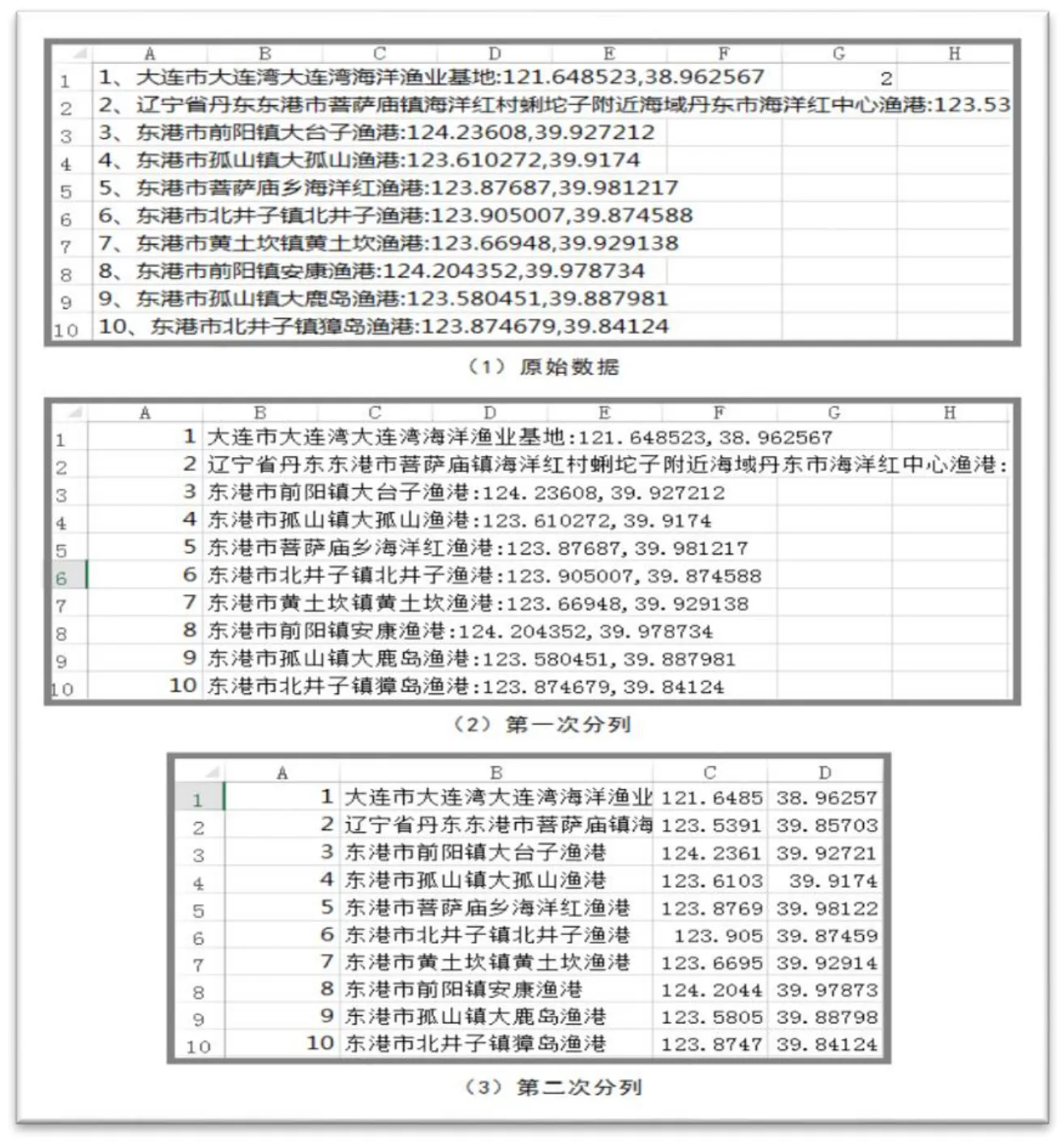
图4 数据格式化转换

图5 原数据URL解析
因此,渔港地理分布数据集需要对每一条数据增加关联信息,即原数据集编码和原id。数据集编码为统一的 A040360,id则需要通过两个数据集的渔港名称、地理位置的比对查找。利用Excel中VLOOKUP函数,逐一查找新数据集中名称在原数据集中的位置,并获取数据id编号,如图6所示。渔港地理分布数据集的采集工作基本完成。

图6 数据索引方法示意图
1.2.6 数据校验
输出结果A是数据集的主要数据,其输入数据是地理位置和渔港名称的连接,数据描述更加准确,然而会有冗余、重复的信息。这样的信息输入到工具中,便可能得到不准确甚至错误的结果。当误差过大直至错误时,则需要进行处理。
以A数据集作为渔港地理分布数据集的主要数据,通过A、B的对比检验数据的合理性,C从一定程度上补充A、B所采集数据的不足。
(1)三组输出结果数据对比
输出结果A、B、C中,其地理分布数值的欧氏距离从0~25不等,图7为A和B的数值分布情况。
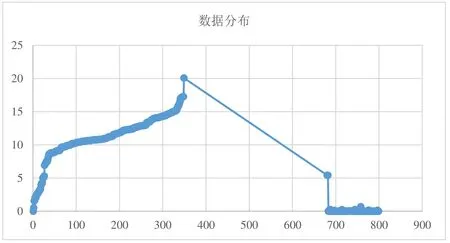
图7 A和B数据分布图
数值欧氏距离的概念比较抽象,需要转换成实际距离。基于百度地图开放平台,利用其中距离计算函数map.getDistance(pointA,pointB)计算距离。对A、B、C数据进行两两距离计算,可以得到3组距离,如图8所示。其中,有些距离为空,其原因是地址解析工具没有解析出相应的坐标点。通过对比距离,设定误差值为1公里距离进行讨论。当AB组距离在1公里误差范围以内时,认为该数据可以进入最终的渔港地理分布数据集;当AB组距离超过1公里时,参考C组数据,若C组数据接近A,则采用A输出结果,否则采用B输出结果。

图8 三组数据距离计算结果示意图
(2)渔港属性校验数据
在原数据集“渔港数量、分布、功能与现状数据库”中,码头长度、护岸长度、防波堤长度的数据单位为长度单位,体现渔港实际建设规模和大小。这些属性对于渔港地理分布数据集的意义是对于有些数据,可以适当放大误差范围。例如,数据集AB的距离为2公里,而渔港规模有3公里,则所采集的地理信息数据是合理的,可以进入渔港地理分布数据集。渔港属性提供的校验方法补充了部分数据记录。通过以上两步数据校验,最终形成渔港地理分布数据集,合理数据量657条。
2 数据样本描述
本数据集由657条数据记录组成,每一条数据记录包含id、name、x、y、dbcode、preid五个属性信息。Id为数据记录的唯一编号,一般是整型。Name是包含地理位置描述信息和渔港名称的文本字段,为原数据集的地理位置与渔港名称的连接。渔港在坐标系中的经度信息用x记录,纬度信息用y记录。Dbcode和preid指向原数据集代码和数据编号。
以数据集第2条记录为例(图9)。该数据对应的渔港名称即name字段的内容,是石塘车关村车关渔港,该渔港的经度属性取值为117.641872,纬度属性取值为31.93985,其引用的数据来源是渔业科学数据平台中A040360(decode)中第737(preid)条记录。
3 数据质量控制和评估
数据质量依赖于“渔港数量、分布、功能与现状数据库”的数据内容完整性、准确性以及地理信息解析工具的准确性。
对于“渔港数量、分布、功能与现状数据库”,主要来源于农业部1990年公布的我国大陆沿海的渔业港口数据,数据的可信度和准确性较高。
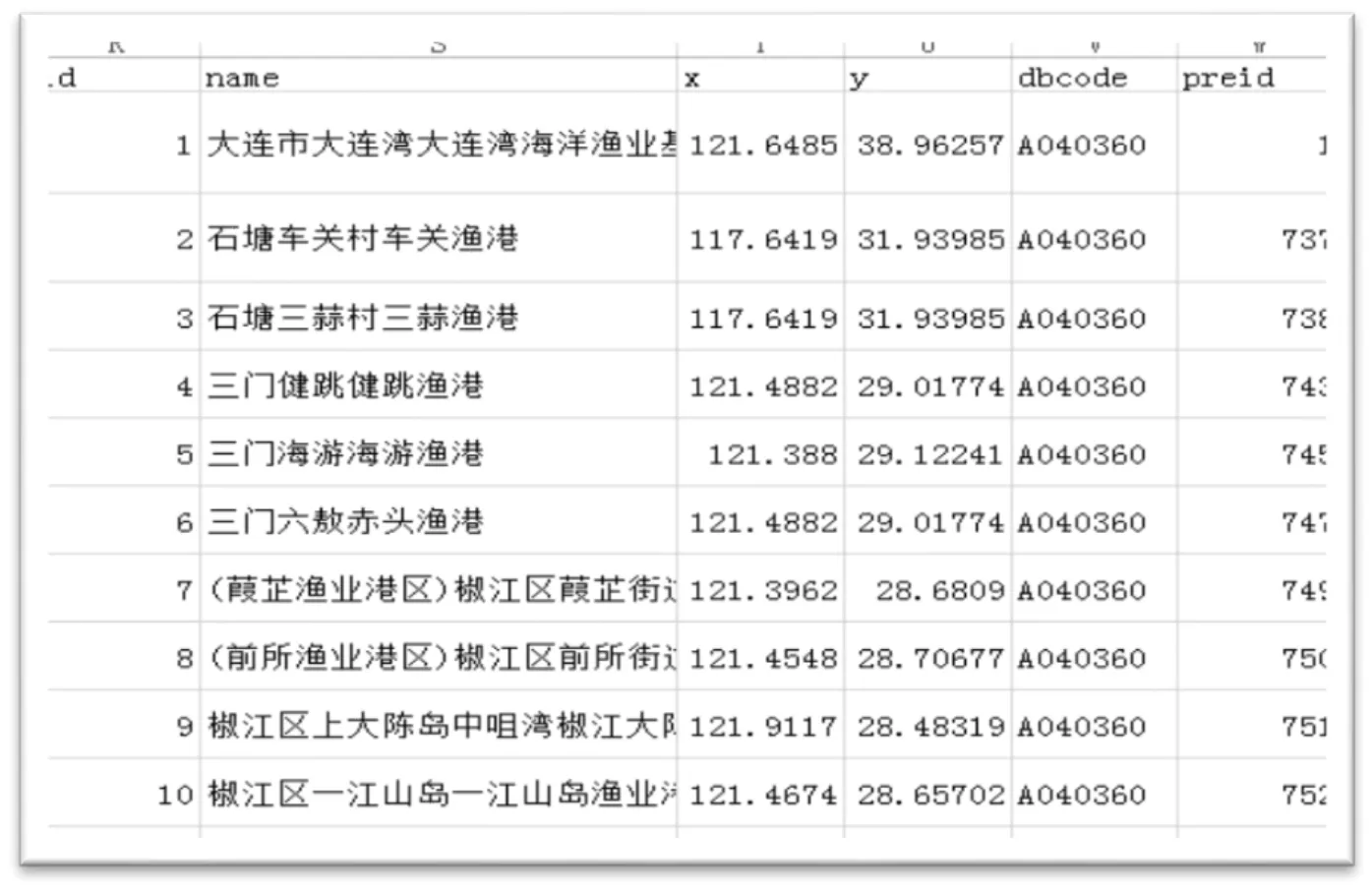
图9 数据样本
对于地理信息解析工具,获取的地理信息坐标允许一定的误差,其误差主要来自地理描述信息的精度问题,另一方面是服务提供商对地理信息坐标的加密,以符合相关法律法规。但误差范围必须符合人们的常规认识。将数据集依次输入百度地图在线经纬度拾取工具(http://api.map.baidu.com/lbsapi/getpoint/index.html),对数据集中渔港位置进行定位对比,其中,有20条数据所在位置与实际偏差较大,数据的准确率为96.97%。
通过数据加工处理过程中数据校验方法的应用,设置误差范围,得到相对准确的渔港地理分布数据集。
4 数据使用方法和建议
数据集通过定量的数值对地理位置进行量化,使数据之间的关系更加易于分析和利用。(1)数据关联关系分析。通过利用数据挖掘、数据统计、机器学习等算法工具,对数据自身的特性进行分析,例如分析渔港位置与渔港属性的关系,对渔港聚类后分析其共同特点等。(2)用户与数据关系分析。根据用户的访问位置,可以得到用户与数据之间的位置关系,并据此进一步提供相关的应用服务,如数据主动推荐、个性化服务,例如将用户感兴趣的数据推送给用户,将用户周边热点数据进行推荐等。
数据应用的一个实例如图10所示。基于用户访问位置,将阈值范围内的渔港在百度地图中标记。位置远近、数据访问热度等都可以作为阈值的指标,据此,可以进一步为用户规划其感兴趣的内容进行推荐。
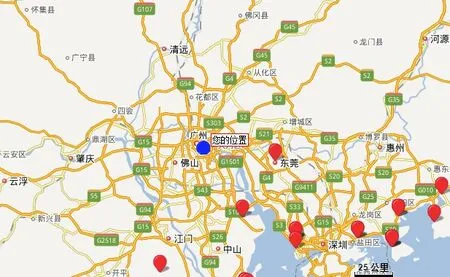
图10 应用实例
猜你喜欢
杂志排行

中国科学数据(中英文网络版)的其它文章
- 2010年中国工业产值公里格网数据集
- 中国四川省峨眉山特有小鲵类(两栖纲,有尾目)龙洞山溪鲵(Batrachuperus londongensis Liu and Tian, 1978)正模标本骨骼μCT三维数据集
- 2011~2017年“银河画卷”巡天数据集
- A dataset of agro-meteorological disasteraffected area and grain loss in China (1949 –2015)
- A social media-based dataset of typhoon disasters, 2017
- A dataset of Ya’an Earthquake based on social media