A social media-based dataset of typhoon disasters, 2017
2018-11-17YangTengfeiXieJiboLiGuoqing
Yang Tengfei, Xie Jibo, Li Guoqing
1.University of Chinese Academy of Sciences, Beijing 100049, P.R.China;
2.Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences, Beijing 100094, P.R.China
Abstract: Typhoons are a category of natural disasters whose annual occurrence causes major life and property loss in the Northwestern Pacific region.During typhoon events, social media serve as an effective tool to transmit and acquire disaster information in real time.Texts and photos from social media can be used as a way of crowd sourcing to extract disaster loss information, analyze human behaviors and formulate responses.The dataset presented here consists of social media-based data collected from "Sina-Weibo" microblogs, "WeChat" articles, and "Baidu" news about the typhoon events in 2017, covering Typhoon "Merbok", "Roke", "Khanun", "Haitang","Mawar", "Hato", "Nesat" and "Pakhar".We mainly collected text data from these social media platforms and websites, which were then cleaned for redundancy and irrelevance.This dataset can be used for deeper disaster information mining of typhoon events.
Keywords: typhoon; social media; disaster reduction; data mining
Dataset Profile

Chinese title 2017年台风灾害社交媒体数据集English title A social media-based dataset of typhoon disasters, 2017 Data corresponding author Xie Jibo (xiejb@radi.ac.cn)Data authors Yang Tengfei, Xie Jibo, Li Guoqing Time range 2017 Geographical scope 15°N – 30°N, 101°E – 132°E; specific areas include:southeast China and surrounding area Data volume 1.70 GB (9749 texts from “Baidu” news and "WeChat"Subscription; 9601 records from “Sina-Weibo”)Data format.html,.xls,.sql Data service system

International Partnership Program of Chinese Academy of Sciences(131C11KYSB20160061)Dataset composition This dataset consists of two compressed (ZIP) files, which are“Data.zip” and “Classification example.zip”.Among them,“Data.zip” is made up of eight subfolders, which are “Haitang”,“Hato”, “Khanun”, “Mawar”, “Merbok”, “Nesat”, “Pakhar”, and“Roke”.Social media data are stored in these subfolders in different formats, which include.html,.xls and.sql.“Classification example.zip” is made of seven subfolders which represent seven large categories of disaster losses, respectively.Each subfolder contains a few subfolders which represent small categories under corresponding large categories.These data are saved in XLS format.Data.zip:● XLS file: Texts from social media are stored in XLS format in a structured form.● SQL file: Users can execute the SQL file in their own MySQL database to import the data which contain structured texts from social media.● HTML file: It is used to store original web pages retrieved from “Baidu” news and "WeChat" Subscription.Classification example.zip:● XLS file: It is used to store data of disaster loss.Each file corresponds to a specific category of disaster loss.
1.Introduction
Typhoons cause major losses to human life and property each year in the Northwestern Pacific region.How to quickly collect information and make reasonable responses is an urgent problem faced by disaster relief departments.Crowd sourcing and citizen observation has been an effective method to obtain disaster information, among which social media, in particular represented by Twitter,1Facebook,2micro-blog data,3etc., provide near real-time information during the disaster period.By making full use of the dynamic information collected by social media, the disaster relief department can get timely information about the disaster events and people’s responses to them.Research has been done on the mining of disaster information based on social media data.Evidence shows that people’s behavior is greatly influenced by social media when disasters occur.4A study commissioned by the American Red Cross5found that more than half of the respondents believed that government agencies should monitor social media to acquire timely and effective disaster information.As to how to use social media data to mine valuable disaster information, Chae J et al.6used Twitter data for hurricane disaster analysis, and the results provided support for government departments’policy decision-making.Some studies7,8built disaster event classifiers based on microblog data for disaster event identification, which detected disasters through citizen observation.In addition, achievements have been made in the spatio-temporal analysis of disaster,9,10the characteristics of disaster social responses,11and the prediction simulation of disaster trends,12,13etc., which greatly improved the efficiency of disaster relief.
Collecting useful information for disaster events from social media is quite time-consuming and complicated due to unstructured expression.Although some social media platforms provide the API (Application Program Interface) for public information access, they also set restrictions to limit the information we can acquire.For example, we can’t get the micro-blog information that relates to a specific disaster event; nor can we get the micro-blog information on a specified historical period directly through API.In other words, the API of these platforms does not provide corresponding retrieval functions, which undoubtedly increases the workload of subsequent data processing.Therefore, in our research project, we develop a toolkit to automatically harvest and process social media-based disaster information.We use the toolkit to generate a typhoon disaster dataset for 2017 based on several social media platforms.The dataset is mainly composed of text data that come from "Sina-Weibo" microblogs, "WeChat" Subscription and "Baidu" news.Figure 1 shows typhoon disaster data from "Sina-Weibo".The data contain textual descriptions and pictures of the disasters, as well as the time and location of data upload.It provides data support for the disaster relief departments to understand the timely progress of the disaster.
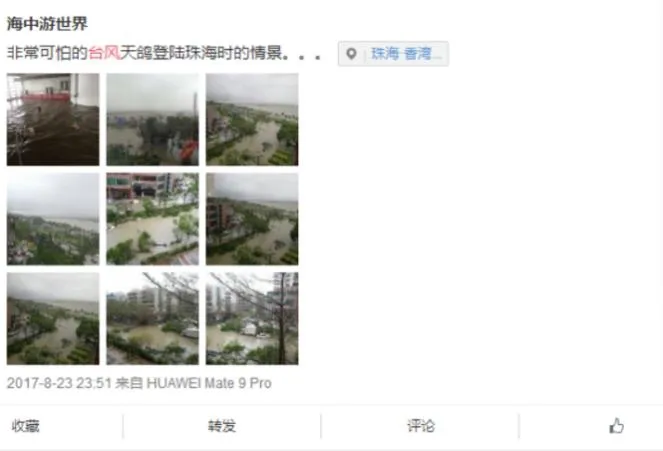
Figure 1 Disaster information from "Sina-Weibo" microblogs
2.Data collection and processing
2.1 Overview
The dataset records information on the following eight typhoon events:"Merbok", "Roke", "Khanun", "Haitang", "Mawar", "Hato", "Nesat" and "Pakhar"(Table 1).

Table 1 The list of typhoons in 2017
The data from "WeChat" Subscription and "Sina-Weibo" are mostly from unofficial media and public uploads, which mainly describe the progression of a disaster based on public observation.In order to give a more comprehensive understanding of the disaster, we added data from Baidu news which were released by official media, which mainly contained disaster loss statistics, relief measures, etc.We used different methods to obtain data from varied data sources.Among them,keyword search was used to retrieve data from "WeChat" Subscription and "Baidu"news.For example, when "Typhoon Hato 2017" was entered, the "Baidu" search engine returned the news related to "Typhoon Hato" in 2017.The toolkit we developed was used to conduct the search and to automatically generate relevant contents.Then, we parsed and cleaned these texts and stored them into the database in a structured form.The same method was used to obtain data from "WeChat"Subscription.For "Sina-Weibo", we used the advanced search function of the platform to obtain data related to the typhoon events.According to the track of the typhoon events (Figure 2), we selected the name of the Typhoon plus the characters"台风 (Typhoon)" as the keywords for setting retrieval conditions.

Figure 2 Tracks of the typhoon events in 2017
2.2 Data collection process
We developed a social media data harvesting system with functions of data collection, parsing, cleaning, and management, as shown in Figure 3.We acquired data from different platforms by using the collection module, and then parsed them into a structured form.The HTML pages from "WeChat" Subscription and "Baidu"news were stored in their original HTML format.Cleaning the data involved a process that comprised removing duplicated information, translating traditional Chinese into simplified Chinese, translating full-width characters into half-width characters, etc.Finally, these data were stored in a structured form.The structure of the data is shown in Table 2.
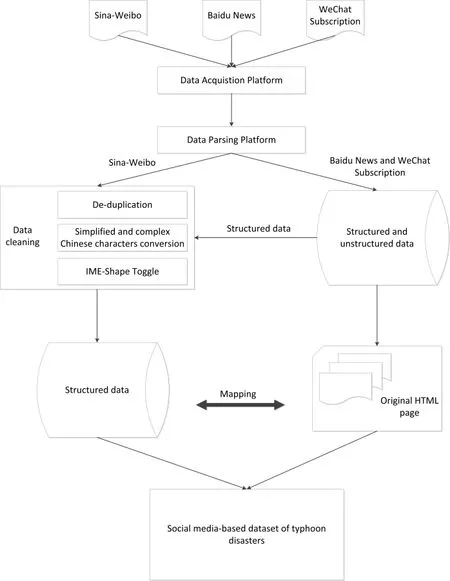
Figure 3 Flowchart of the social media data harvesting system

Table 2 Structure of the data
2.3 Data classification
Social media data contain a lot of disaster loss information, and different types of damage may be included in the same data.For example, a text from "Sina-Weibo"writes, "After the typhoon, many trees were blown down and many cars were smashed." The text contains disaster loss information about the destruction of trees and cars and we divided these information into different categories of disaster losses.Below we provide a classification example according to the type of reported damage caused by the disaster.The raw data in this classification example are all from "Sina-Weibo" microblogs related to typhoon "Hato" in Zhuhai.Users can classify the rest of the data in the dataset by referring to the classification example or according to their specific needs in research.The seven large categories include social effects,forestry, fisheries, traffic, electric power, communication and infrastructure damage.One large category contains several small categories, as shown in Figure 4.For example, the category of social effects contains injuries and deaths, water shortage,building damage, and market shutdown.The classification example is shown in Table 3.

Figure 4 Category of disaster loss

Table 3 An example of disaster classification
3.Sample description
Data fields for "Sina-Weibo" includes ID, keyword, province, city, content,picture, location, release time, platform, number of forwards, comments, number of likes, as shown in Table 4.Each column has a limit of no more than 140 characters.The topics of the dataset include property loss, traffic impact, casualties, power supply, communication impact, rescue arrangements, response measures, and public attitudes toward the typhoon, among others.

Table 4 Data from "Sina-Weibo"

scratched by the branches.How can I go to work tomorrow, since Hengqin is so far away? The last picture, as a tribute to our soldiers!http://ww2.sinaimg.cn/square/005WuHsBgy1fiu0v3h5b8j30qo0zkdvg.jpg;Picture http://ww4.sinaimg.cn/square/005WuHsBgy1fiu0ul1m9aj30qo0zktks.jpg;http://ww3.sinaimg.cn/square/005WuHsBgy1fiu0wqzd5nj30qo0zk4ap.jpg;http://ww4.sinaimg.cn/square/005WuHsBgy1fiu0y2re2bj30qo0z Location Zhuhai Release time 2017-08-23 22:25 Platform iPhone 7 Number of forwards -Comments -Number of likes 1
Data fields for "Baidu" news include ID, title, link, source, release time, and keyword, as shown in Table 5.The fields for "WeChat" Subscription include ID, title,content, source, release time, and keyword, as shown in Table 6.The themes of the data include typhoon tracks, disaster loss statistics, government announcements,emergency measures, etc.

Table 6 Data from "WeChat" Subscription
4.Quality control and assessment
Keywords related to the designated typhoon event were diversified and optimized to ensure maximum retrieval of related information from each social media platform.After data collection was completed, we manually checked the validity of the data, and removed incomplete entries as well as entries irrelevant to the typhoon disaster.In addition, we established a database index system to avoid duplicate data.For disaster classification, three colleagues were arranged to classify these original data to ensure the accuracy of the final classification results.Prior to this, classification standards had been set up to minimize possible discrepancies.Finally, we randomly sampled 500 data entries from each platform and found an accuracy rate of nearly 100%.
5.Value and significance
To our knowledge, there were no social media-based datasets for these typhoons before, and our dataset effectively fills up this gap.The data in our dataset can be analyzed to meet different needs of disaster research.For example, the disaster loss data presented here can be re-classified into different categories to support real-time evaluations of disaster losses.The data can also be used for further analysis of typhoon disasters such as victims’ sentiment analysis in the typhoon area, the extraction of buzzwords during typhoon transits, etc.In follow-up studies, we have used the texts in this dataset to train the corpus for automatic identification of typhoon disaster information, which achieved satisfactory results.
