基于极大频繁项集的粒关联规则方法
2018-11-06李山山张正炳付青青
李山山, 张正炳,付青青
(长江大学电子信息学院,湖北 荆州 434023)
数据挖掘广泛应用于零售、网络日志、生物、化工、医药等领域,在日常生活中扮演着越来越重要的角色。粒关联规则(GR)[1,2]是一种结合粒计算[3]和粗糙集[4]的相关知识,通过源覆盖、目标覆盖、源置信度和目标置信度来寻找多元关系数据表中隐藏模式的新方法。在恰当设置4个指标的阈值后,就可以得到一些语义比关联规则挖掘更加丰富的规则。粒关联规则适用于推荐系统[5,6]的冷启动问题[7],但粒关联规则挖掘结果存在冗余等问题。为解决这一问题,笔者利用极大频繁项集可以紧凑地表示频繁项集的特点,提出了基于极大频繁项集的粒关联规则方法(MGR算法)。
1 基本概念
针对粒关联规则挖掘所得规则存在冗余的问题,类比频繁项集[8]和极大频繁项集[8]的定义,笔者给出源频繁粒、目标频繁粒、源极大频繁粒和目标极大频繁粒的定义(见定义1和定义2),并证明根据极大频繁粒集的源覆盖和目标覆盖可以表示其子集的源覆盖和目标覆盖的范围(见性质1),为基于极大频繁项集的粒关联规则方法(MGR算法)解决上述问题奠定基础。
引理1[2]假定S=(U,A)为一个信息系统,其中,U=(x1,x2…,xn)表示所有对象集合,A={a1,a2,…,am}表示所有属性集合,若A′⊆A,则(A′,x)决定信息系统的一个粒。

引理3[2]若(U,A)和(V,B)为2个信息系统,R⊆U×V是从U到V的二元关系,则ES=(U,A,V,B,R)表示一个多对多实体关系系统。
定义1对于A′⊆A,B′⊆B,A′和B′构成粒关联规则GR,给定源覆盖和目标覆盖分别为ms,mt,若scov(GR)≥ms,则称(A′,x)决定的粒为源频繁粒;同理,若tcov(GR)≥mt,则称(B′,y)决定的粒为目标频繁粒。

根据文献[1]和定义2,笔者给出MGR的基本形式:

(1)
MGR中源覆盖、目标覆盖、源置信度和目标置信度的定义如下:
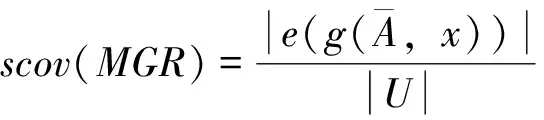
(2)

(3)
因为源置信度和目标置信度之间存在相互制约的关系,计算任意一个需要确定另外一个的值[1]。在给定目标置信度tc的条件下,源置信度的定义式为:
(4)

2 MGR算法
笔者将以定义1、定义2、性质1和式(1)为基础,介绍MGR算法。算法包含2个部分,即MaxApriori算法(算法1)和MSandwich算法(算法2),其中算法1用于挖掘出所有的极大频繁粒集,该结果作为算法2的输入,算法2用于生成规则。
2.1 算法1
输入为多对多实体关系系统[1,2]、源覆盖和目标覆盖阈值,输出为源极大频繁粒集MSG和目标极大频繁粒集MTG。算法第1步利用式(2)、式(3)分别获得的1-频繁粒集,该步需要扫描数据库一次;第2步利用粒的定义[3]求得1-频繁粒集的外延,该过程需要扫描数据库一次;第3步针对每个1-频繁粒集利用Apriori性质求得k-频繁粒集和其对应的粒的外延;第4步利用定义2和粒的外延求得k-1-极大频繁粒集;第5步将k-频繁粒集添加到极大频繁粒集。
算法1求出所有的极大频繁粒集的过程只需要2次扫描数据库。
2.2 算法2
算法2的输入为算法1输出结果MSG和MTG,输出为一组规则集。算法2首先分别取出MSG和MTG中对应的源极大频繁粒g和目标极大频繁粒g′,然后利用二元关系R得到候补规则集,最后输出满足tconf(MGR)≥tc,sconf(MGR)≥sc的规则集。
2.3 算法时间复杂度问题
MGR算法时间复杂度与GR算法时间复杂度[2]相似,都可以用公式表述为:
O(|MSG(ms)|×|MTG(mt)|×|U|×|V|)
(5)
3 试验
试验数据来自MovieLens数据集,目前已被广泛的应用于推荐系统。采用的数据表为一个含有943个用户的用户信息表、一个含有1682部电影的电影信息表和一个用户对电影的100000条评分记录表。为避免无用数据,这100000条评分记录中每个用户至少评价了20部电影。考虑到挖掘过程中用户和电影之间的二元关系,忽略评分记录表中的5个等级评分对试验结果产生的影响,采用“1”和“0”区分评分和未评分重构评分记录表。由于原始用户信息表中用户年龄范围介于7~73岁,电影信息表中电影上映年份介于1922~1998,为了更好地挖掘规则,对这2个数据表中的数据采用离散预处理。将用户年龄划分为6个区间:[7,22),[22,27),[27,31),[31,39),[39,48)和[48,73),并用0~5表示这6个区间;将电影上映时间划分为7个区间[1922,1980),[1980,1993),[1993,1994),[1994,1995),[1996,1996),[1996,1997)和[1997,1998),并用0~6表示这7个区间。针对电影类型的多值属性问题,利用多值属性方法进行处理。

图1 规则数量

图2 运行时间
3.1 不同阈值下算法的规则数量和运行时间
设置sc=tc=0.2,ms=mt,随着ms(mt)变化时可以得到不同阈值条件下MGR算法和GR算法的规则数量和运行时间,分别对应图1和图2。
3.2 MGR算法获得的规则是否存在损失

造成规则损失是因为MGR算法是建立在2个论域上的规则,通过多对多实体关系系统来实现。在多对多实体关系系统中,利用MGR算法中的算法1得到的极大频繁粒集的子集包含了粒关联规则算法中的全部频繁粒集,这说明算法1得到极大频繁粒集的过程是无信息损失的,在算法2建立规则过程中,存在少量的极大频繁粒的真子集满足二元关系R而生成对应的规则,这个过程在MGR算法中未能体现出来,从而造成少量的规则损失。
3.3 不同阈值条件下算法的准确率
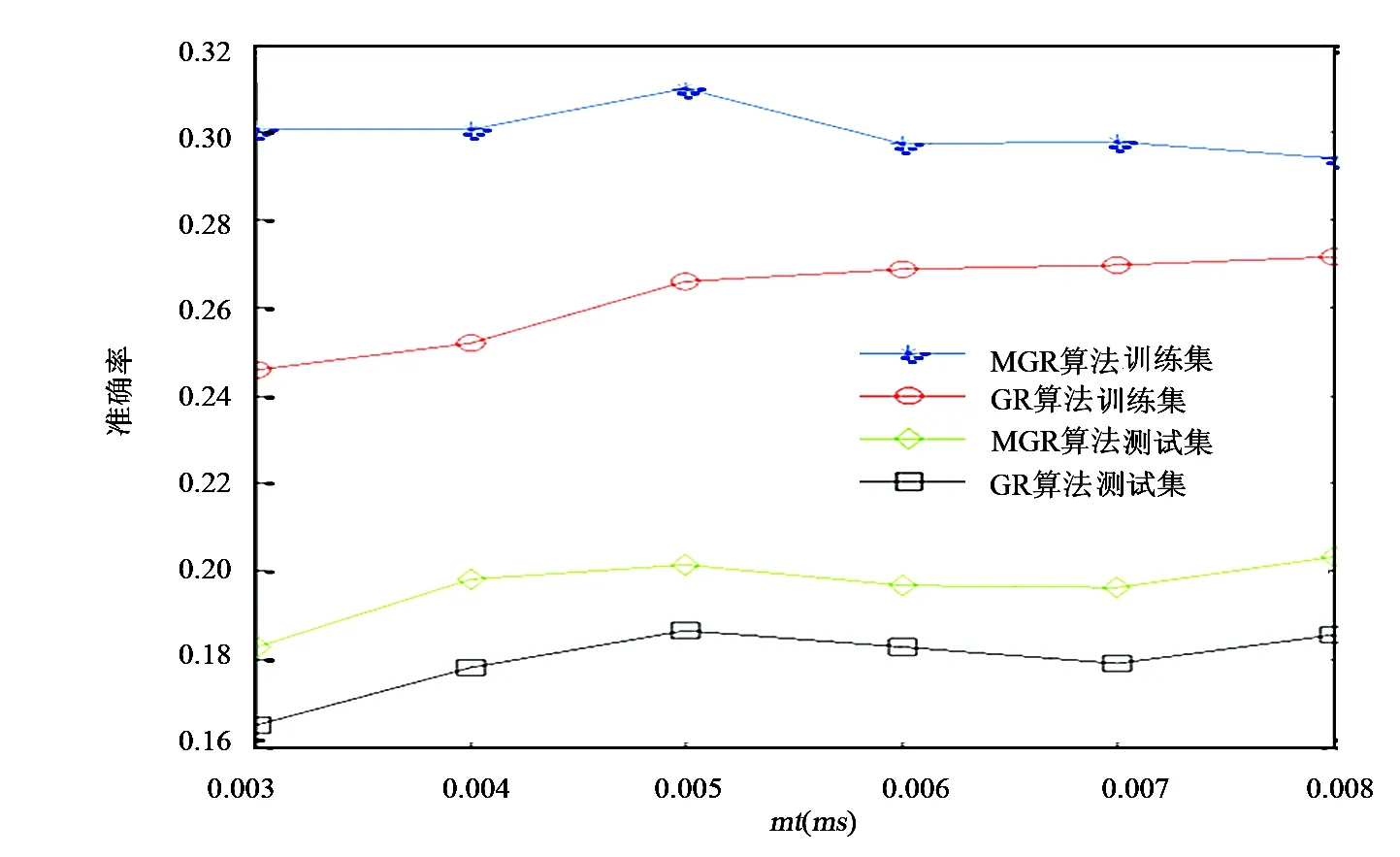
图3 不同阈值条件下训练集和测试集的准确率
由于利用MGR算法在得到规则时存在规则损失,为评价这个损失对推荐系统造成的影响,下面就冷启动问题利用MGR算法和GR算法进行推荐,推荐的效果用准确率[1]来衡量。在试验过程中,对冷启动问题采用60%的训练集和40%的测试集的划分比率,为使试验得到的结果更加准确,每个阈值下的试验都进行30次,求得30次试验的平均值。设置sc=tc=0.4,ms=mt,随着ms(mt)变化得到不同阈值下的结果,如图3所示。
由图3可以看出,2种算法在训练集的推荐准确率比测试集推荐准确率高,且在训练集和测试集上MGR算法的推荐准确率比GR算法的准确率高。由此可以看出在利用MGR算法的过程中虽然会造成少量的规则损失,但在推荐准确率方面却有所提升。这说明利用MGR算法可以在降低挖掘规则冗余度的同时提高推荐的准确率。
3.4 不同划分比例训练集和测试集

图4 不同划分比例训练集和测试集的准确率
考虑到训练集和测试集的划分比例可能对冷启动问题的推荐准确率造成影响,设置sc=tc=0.4,ms=mt=0.005,将训练集和测试集的划分比例从0.3增加到0.8,得到训练集和测试集的推荐准确率如图4所示。
由图4可知,随着训练集划分比例逐渐增大,训练集和测试集在推荐准确率上基本呈现递增趋势,这说明随着训练集划分比例增大,有更多已有用户和电影的评分记录,从而可以挖掘出更适于用户的规则。此外,MGR算法的推荐准确率比GR算法推荐准确率略高,说明MGR算法具有较强的稳定性,在不同的划分比例下推荐准确率依然比GR算法高。
4 结语

