基于违约状态判别的小企业债信评级
2018-10-25迟国泰
孟 斌,迟国泰
(大连理工大学管理与经济学部,辽宁大连116024)
1 引 言
债信评级是对具体的一笔贷款或公司债券等进行的评级,以确定这笔贷款或债券回收本息的概率.债信评级的本质是违约风险评级,衡量客户或一笔贷款违约的可能性.因此,不论是大中型企业还是小企业,它的评级体系必须符合债信等级越高、违约损失率越低的标准.同时,遴选出的评级指标也必须对违约状态有鉴别能力.不管这个指标来自于教科书还是流行文献,即使在实际体系中应用频率很高,被人们使用的次数很多,只要它对区分企业的违约与否状态不显著,都不应该纳入评级指标体系.
小企业是国民经济中最活跃的经济成分之一.据统计,占中国企业数量98%以上的小企业,对GDP贡献率超过60%,对收税的贡献率超过50%,提供了85%的中国新增就业岗位,创造了75%的新产品,发明专利占比65%,在就业和创新等方面都发挥着重要作用.但是,小企业由于财务信息不健全、抵质押品欠缺等特点,普遍存在贷款融资难的问题[1].如何解决好小企业融资难的问题,成为迫切需要解决的难题之一.建立合理的小企业债信评级体系有利于解决小企业贷款融资难的现状,为银行对小企业的信用状况进行科学评估提供依据.
1)企业信用风险评级指标体系研究现状
业界流行的5C原则是企业信用评级指标体系的主要标准之一.5C原则的评级指标体系从资本(capital)、品德(character)、能力(capacity)、环境(condition)、担保(collateral)五个方面对客户的还款能力和还款意愿进行评价[2].作为美国信用评价先驱的标普、穆迪和邓白氏通过流动比率、速动比率和资产报酬率等反映企业真实清偿能力的重要财务指标进行企业信用评价[3].加拿大皇家银行主要通过企业的财务状况对企业进行信用评级[4].中国建设银行通过金融财务风险评价指标、账户行为评价指标和定性评价指标三个方面进行小企业信用风险评级[5].中国工商银行通过企业的偿债能力、经营情况、发展前景、管理层现状等方面对企业进行信用评级[6].上海浦东发展银行主要通过财务报表中的财务信息对小企业的信用风险进行评定[7].中国邮政储蓄银行的评价体系增加了宏观环境准则层的影响[8].
标普、穆迪、邓白氏等国外典型金融机构评级指标体系的共同特点是:评级对象都是针对大中型企业,并不适合财务信息不完善的中国小企业信用评级研究.中国建设银行、中国工商银行等国内典型金融机构评级指标体系的共同特点是:债信等级的划分结果仅仅是根据客户信用得分的高低对客户进行不同等级的分类,并不能确定每个债信等级的年违约损失率.
2)企业信用风险评级方法研究现状
一是评级指标筛选方法的研究现状.Vytautas等通过判别分析、logistic回归和神经网络三种方法对评价指标进行筛选[9].Chen通过粗糙集进行指标筛选,建立了亚洲银行信用评价体系[10].Peter等通过逻辑回归方程进行指标筛选,进而对银行的财务实力进行评定[11].二是信用评分模型的研究现状.陈雄华等建立了基于神经网络的企业债信等级评定方法[12].唐振鹏提出一种基于藤copula的信用测度模型[13].赵亦军等利用CFaR构建企业信用风险评估模型构建[14].徐超设计了一个根据专家判断法和定量模型法的混合型贷款信用评分模型[15].三是债信等级划分的研究现状.Kai等通过DEA模型对中国商业银行的债信等级进行划分[16].Morningstar公司将客户分为AAA、AA+、AA、AA-、A+、…、CC共14个债信等级,并设定了每个等级的信用得分[17].Moon等把客户分为10个等级,90分以上的客户为AAA级、85分~89分的客户为AA级、…、50分以下的客户为D级[18].
现有研究的不足:一是评级指标的筛选标准并不根据指标是否对违约状态具有显著的判别能力,这就明显地有悖于信用风险(credit risk)评价即违约风险(default risk)评价这个根本目的,难免导致这种评级体系不能有效地区分违约企业和非违约企业,也难免导致在这种评级体系下,债信等级高的客户、违约率反而不低的现象.二是现有的评级体系并不根据违约鉴别能力的大小删除反应信息重复的指标,这会导致指标的重叠与信息冗余,或导致违约鉴别能力强的指标反而被误删.三是现有债信等级的指标权重并不能保证对违约状态鉴别能力越强的指标、权重越大.
本文以中国某一区域性商业银行的京、津、沪、渝等地区14个分行的1 231笔小企业贷款数据为样本,从企业内部财务因素、企业外部宏观环境、抵质押担保等七个准则建立小企业债信评级体系.根据指标对违约状态鉴别精度的影响程度进行第一次筛选,保证遴选出的指标对违约状态鉴别能力都有显著影响;根据准则内R聚类进行第二次筛选,避免遴选出的指标反映信息重复,构建了一套能显著区分小企业违约状态的评级体系.实证结果表明:速动比率、法人代表信用卡记录等21个指标构成的指标体系不但可以显著区分小企业的违约状态、而且避免了重复反映信息的指标重叠和冗余.
2 小企业债信评级的原理
小企业债信评级有三个特点:一是财务信息不完善.相当多的小企业财务制度过于简单,缺少可信的财务报表,影响了对其信用风险的判断.二是受环境影响大,抗风险能力弱.由于小企业规模不大,抗风险能力相对薄弱,商业银行难以准确把握企业的市场风险和自身风险,无法满足银行的授信标准.三是合格抵质押品欠缺.小企业的主要抵押物是房地产.据统计,60%以上的小企业没有取得土地使用证、房屋所有权证[1].甚至不少企业的厂房是租用的,严重制约了小企业的贷款.
小企业债信评级存在三个难点.难点一:如何筛选出能够显著区分违约和非违约客户的指标.理论与实践中流行的指标不一定对违约状态有较强的鉴别能力.难点二:如何避免评级体系中指标反映信息的重复、指标重叠或指标冗余;如何避免在反映信息重复的指标中、误删对违约状态鉴别能力强的指标.难点三:如何保证指标对违约状态鉴别能力越强,指标的权重越大.
针对上述三个难点,一方面,将所有客户第i个指标的数据分为违约和非违约两类样本,根据违约样本均值偏离全部样本均值程度越大、则违约样本均值偏离非违约样本均值也大、这个指标越能显著区分违约与否状态的思路,遴选通过方差齐性检验的指标,建立了能显著区分违约状态与否的信用评级指标体系.另一方面,在通过R聚类聚成的同类指标中,根据违约样本均值偏离全部样本均值程度越大、这个指标区分违约状态能力越强的思路保留方差齐性检验值最大、即对违约状态影响最大的指标,剔除其余指标,避免了现有研究在剔除冗余指标时、对违约状态影响大的指标可能被误删的不足.最后,根据违约样本均值偏离全部样本均值程度越大、这个指标区分违约状态能力越强、权重越大的思路对指标进行赋权,使指标权重的大小反映指标鉴别违约状态能力的大小,弥补了现有研究的指标赋权与违约状态鉴别能力无关的弊端.小企业债信评级的原理如图1所示.
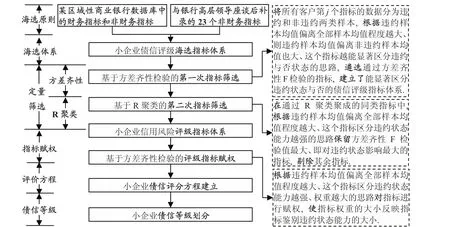
图1 小企业债信评级的原理Fig.1 Principle of debt rating for small enterprises
3 小企业债信评级体系建立的方法
3.1 指标数据的标准化方法
指标数据标准化的目的是将指标数值转化为[0,1]之间的数,消除单位和量纲的不一致,为小企业信用评价指标筛选提供数据基础.指标可以分为正向、负向、区间型和定性指标四类.正向指标是指数值越大、小企业信用状况越好的指标,例如“净利润”等指标.负向指标是指数值越小、小企业信用状况越好的指标,例如“全部资本化率”等指标.设xij为第i个指标第j个企业的标准化得分;vij为第i个指标第j个企业的原始数值;n为样本总数.根据正向指标和负向指标的标准化公式,则有[19]
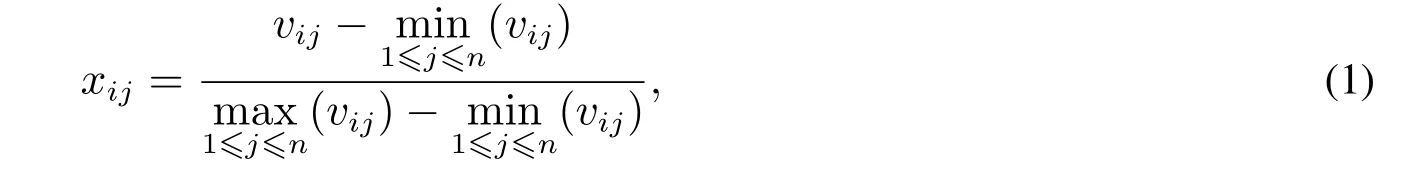
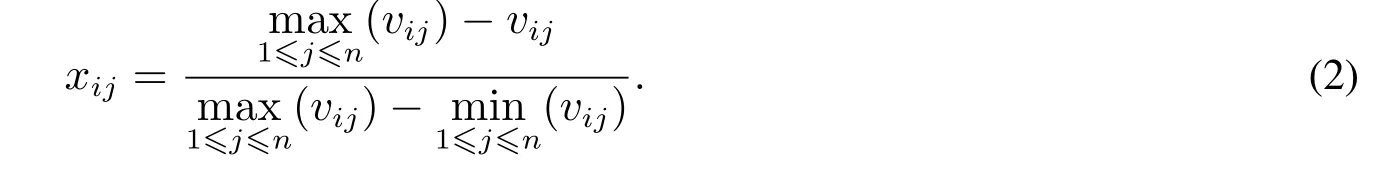
区间型指标是数值越接近某一特定区间、小企业信用状况越好,并且在这个特定区间内、信用状况最好的指标.本文涉及两个区间型指标:“居民消费价格指数”和“年龄”.“居民消费价格指数”的理想区间是[101,105][7].数值处于该区间表明既不通货膨胀又不通货紧缩;越低于该区间,表明通货越紧缩,这种环境越不好;越高于该区间,表明通货越膨胀,这种环境也越不好.“年龄”的理想区间是[31,45][7].处于该年龄段的企业法人的还款能力和还款意愿最强;越偏离这个年龄段,企业法人的还款能力越差.设q1为指标最佳区间左边界;q2为指标最佳区间右边界.根据最佳区间指标的打分公式,有[19]
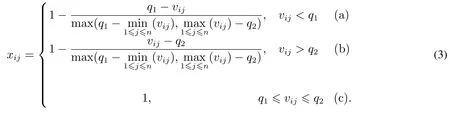
对所有定性指标制定出适合小企业的打分标准,将指标转化为[0,1]区间的数.定性指标的打分标准如表1所示.定性指标打分后的数据已经是[0,1]区间的数,不需要通过式(1)~式(3)进行标准化处理.
现有研究比较常用的缺失值插补方法包括:均值插补法[20]、最差值插补法[19]、最大值插补法[12]和回归插补法[19]等.本文选取最差值插补法,即将数据缺失值设为0,原因是:在银行的实地调研中发现,数据缺失的原因往往是因为小企业该项指标较差甚至是没有统计口径,说明企业在该项指标的水平很低,用最差值代替比较合理.如果用均值或者最大值进行插补往往容易拉高该企业的整体水平,导致债信评级失准.而回归插补法往往要求变量具备一定的线性关系,不适合定性指标的缺失数据插补.
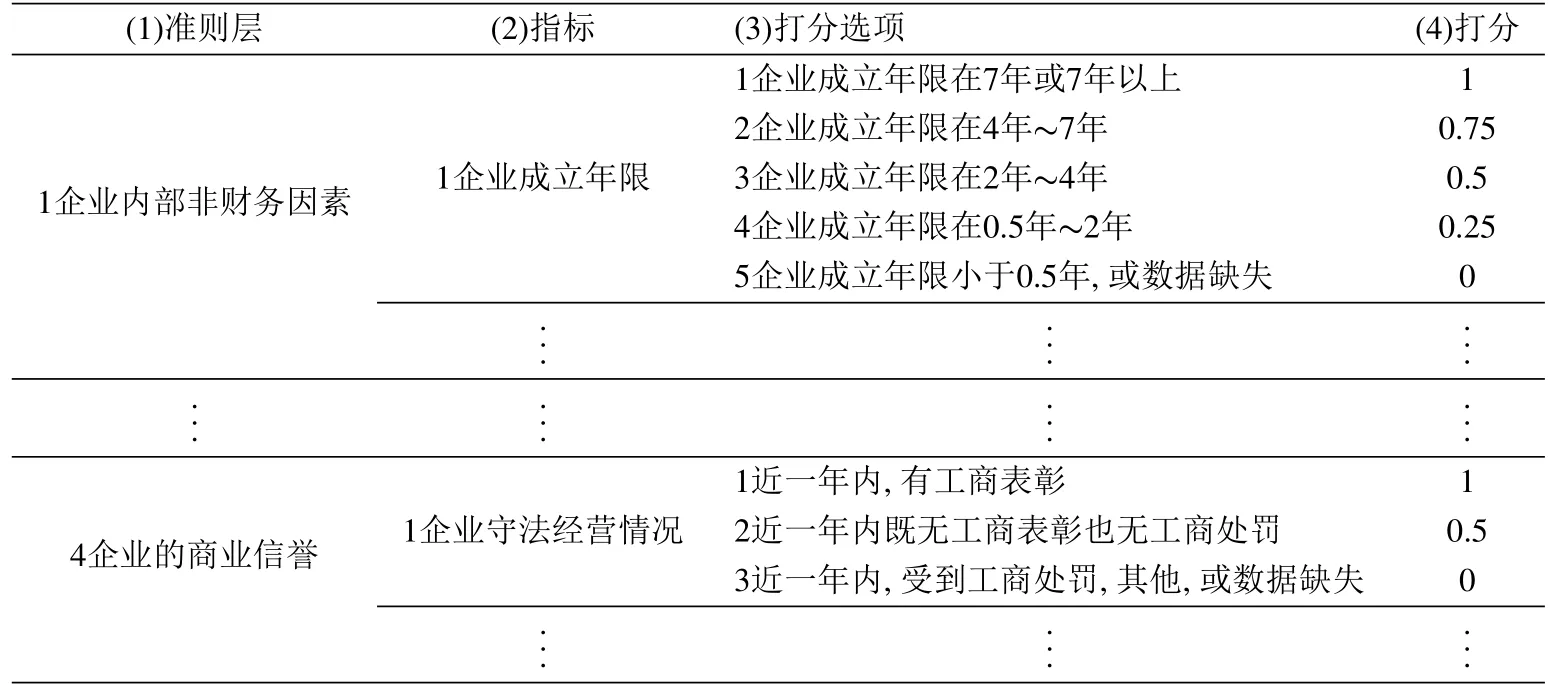
表1 定性指标打分标准Table 1 Standard of qualitative indicators
3.2 显著判别违约状态的指标筛选方法
通过违约样本均值偏离全部样本均值程度越大、这个指标区分违约状态能力越强的思路,构造每个指标的方差齐性F检验的统计量.若检验通过,说明违约样本与非违约样本能被明显的区分出来,则该指标对区分违约状态有显著影响,应该保留;反之,说明该指标对区分违约状态没有显著影响,应该删除.
方差齐性F检验的统计量服从自由度为(k-1,n-2)的F–分布,即F~(k-1,n-2)分布,k为分组数,n为样本数.设n1为违约样本个数,n2为非违约样本个数;n为全部样本数.x(k)ij为第i个指标第j个借据的标准化值(k=1代表违约借据,k=2代表非违约借据,下同),为第i个指标的平均值,即.为第i个指标第j个借据的数值与第i个指标平均值的绝对偏差,即为第i个指标绝对偏差的平均值,即为全部借据第i个指标绝对偏差的平均值,即.则有[20]
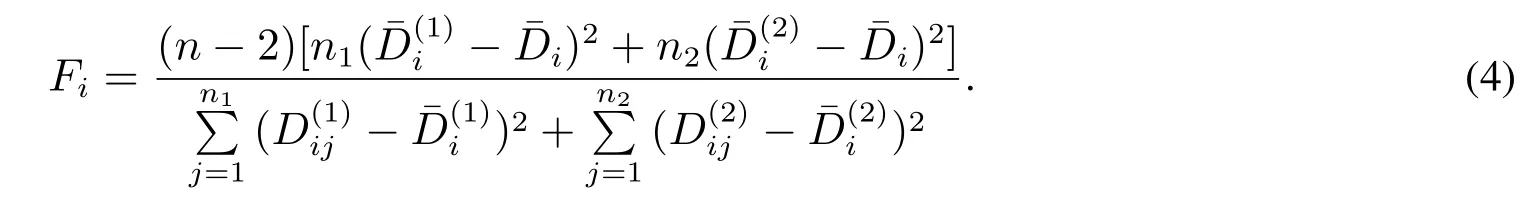
式(4)筛选指标的特色:将所有客户第i个指标的数据分为违约和非违约两类样本,根据违约样本均值偏离全部样本均值程度越大、则违约样本均值偏离非违约样本均值也大、这个指标越能显著区分违约与否状态的思路,遴选通过方差齐性F检验的指标,建立了能显著区分违约状态与否的信用评级指标体系.弥补了现有研究遴选指标的标准与违约状态无关的弊端,开拓了信用评级的新思路.
3.3 剔除信息冗余的指标筛选方法
同一准则层内通过R聚类将反映信息重复的指标聚成一类,保留同类指标中方差齐性F检验值最大、对违约状态影响最大的指标,删除其余指标,避免重复反映信息的指标重叠和冗余.R聚类步骤如下[21]:
步骤1人为确定聚类数目l,即人为确定将m个评价指标最终要分成l类.若下文的检验通过,则说明这个聚类的数目合理,否则就重新确定.
步骤2将每个指标看成一类,m个指标就划分成m类.
步骤3为叙述方便这里给出合并的定义,将两类指标人为的看成同一类别叫做合并.在步骤2的m类指标中,将任意两类合成一类,根据排列组合的原理,共有Cm2=m(m-1)/2种合并方案.通过式(6)计算每个合并方案的总离差平方和S,根据离差平方和最小确定合并方案.这样,m类指标就分成了m-1类.设把m个评价指标分成l类;Sh为第h类的离差平方和;mh为第h类的指标数;Xih为第h类中的第i个指标标准化数值向量;Xh为第h类指标的样本平均值向量,则第h类的离差平方和Sh和l个类的总离差平方和S分别为[21]

步骤4重复步骤3,直到最后的分类数目为步骤1里确定的l.
步骤5聚类结果的合理性检验.对聚类后的每一类指标进行K-W检验[19],判断聚类数目l是否合理.K-W检验的原假设是不同的指标在数据特征上无显著差异.若每一类指标的显著性水平Sig>0.01,则接受原假设[19],表明这一类指标之间无显著差异,可以聚成一类,聚类结果合理;否则,拒绝原假设,表明这一类指标之间有显著差异,不能聚为一类,返回步骤1重新确定聚类数目.
步骤6指标的剔除.在步骤5中聚为一类的指标中,保留F值最大的指标,删除其余指标.
通过F值剔除冗余指标的特色:在通过R聚类聚成的同类指标中,根据违约样本均值偏离全部样本均值程度越大、这个指标区分违约状态能力越强的思路保留方差齐性F值最大、即对违约状态影响最大的指标,剔除其余指标,避免了现有研究在剔除冗余指标时、对违约状态影响大的指标可能被误删的不足.
3.4 债信评分模型的构建和检验方法
1)显著判别违约状态的指标赋权思路
设wi为第i个指标的权重,则

式(7)将Fi值转化为[0,1]之间的数,保证权重之和是1.通过Fi值对指标进行赋权,Fi值越大,权重wi越大,满足对违约状态影响越显著、指标权重越大的思路.根据违约样本均值偏离全部样本均值程度越大、这个指标区分违约状态能力越强、权重越大的思路对指标进行赋权,使指标权重wi的大小反映指标鉴别违约状态能力的大小,改变了现有研究的指标赋权与违约状态鉴别能力无关的弊端.
2)债信得分的测算方法
设sj为第j个客户的债信得分,wi为第i个指标的权重,xij为第i个指标第j个客户的标准化得分,则[19]

评价得分sj越高,客户的信用状况越好.由于式(8)计算的债信得分是[0,1]区间的数值,且得分之间的区分度不大.在债信等级划分时,为了使得分区间有足够的区分度,需要将式(8)计算的债信得分通过式(9)进行标准化处理,将债信得分转化为[0,100]之间的数值.设Sj为第j个样本的债信标准化得分,smin为所有样本债信得分的最小值,smax为所有样本债信得分的最大值,则[19]
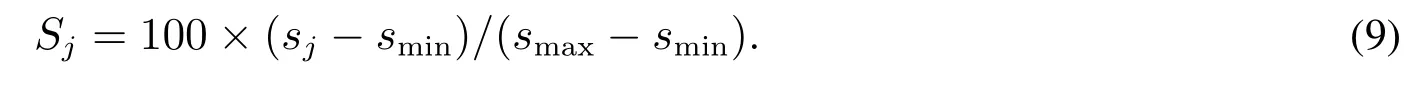
3)基于ROC的债信评分模型的检验方法
通过ROC曲线的AUC值,检验债信评分模型的违约预测能力是否显著,同时也可以证明债信评级指标体系整体是否合理.ROC(receiver operating characteristic)曲线,也称为感受型曲线.ROC曲线作图时需要用到两个指标:灵敏度(sensitivity)、特异度(specificity).灵敏度,是用正确判定为违约的个数除以实际所有的违约数,指实际违约的样本被正确判定为违约的比率.特异度,是用正确判定为非违约的个数除以所有的非违约数,指实际非违约的样本被准确判定为非违约的比率.
ROC曲线下边包围的面积就是AUC值.ROC曲线越远离对角线、越靠近右上方时,债信得分判断违约状态的正确率越高,该债信评分模型越合理;也就是说AUC值(area under curve)越大、该债信评分模型越合理.当AUC=1时为理想值,其判别效果最好.AUC在0.8及其以上时,违约判别效果较好.当AUC在0.7∼0.8之间违约判别效果中等.AUC在0.5∼0.7之间违约判别效果较差.当AUC在0∼0.5之间违约判别效果极差.
3.5 债信等级划分的方法
本文将小企业债信划分为AAA、AA、A、BBB、BB、B、CCC、CC和C共9个债信等级,原因如下:在国际三大权威信用评级机构中,穆迪的企业信用等级包括AAA、AA、…、C共9个等级[3],标普在穆迪的基础上又增加了一个D级[3],共10个等级,惠誉对于1年左右的企业短期贷款也是9级划分[2].同时,中国邮政储蓄银行[8]、中国工商银行[6]等国内权威机构对于小企业信用等级的划分都是9个等级.综上,本文借鉴国际和国内比较流行的9级标准对小企业债信等级进行划分.当然了,即使是借鉴标普的10级标准、中国建设银行的5级标准,甚至是主权信用评级的21级标准,本文的等级划分方法依然可以实现.
年应收未收本息是指贷款逾期第90天时客户拖欠银行的本金与利息之和除以贷款期限.年应收本息是指贷款逾期第90天时客户应该向银行缴纳的所有本金与利息之和除以贷款期限.债信等级的年违约损失率是指该债信等级下所有客户的年应收未收本息与所有客户年应收本息的比值.这种年违约损失率的测算方法可以准确反映客户贷款给银行造成的真实损失,解决了现有研究的违约损失率无法真实反映银行损失的问题.
把信用得分从高到低进行排序.根据高分数对应高债信等级的规则,把债信等级划分为9个等级.通过债信等级越高、违约损失率越低的标准对债信等级进行调整.每个客户都对应着一定的债信得分,故通过对每个债信等级得分上、下限的调整,可以改变该债信等级内的客户数,也就改变了这个债信等级内年应收未收本息、年应收本息的变化,进而引起年违约损失率的变化.上述分析表明,一个债信等级得分上、下限的调整,会引起该债信等级及相邻债信等级年违约损失率的变化.因此,通过不断调整9个债信等级得分的上、下限,总可以得到满足债信等级划分标准的债信等级分布,此时对应的各个债信等级得分的上、下限,就是最终的债信等级划分界限.根据债信等级越高、违约损失率越低的债信等级划分标准,也可以开发算法和程序,由计算机完成这个过程.例如,下文实证4.4中的债信等级划分就是使用的我们团队授权的国家发明专利[22]由计算机方便地完成,它可以避免无休止的债信等级得分上、下限的调整.
4 小企业债信评级的实证分析
4.1 指标的海选
根据中国某区域性商业银行京、津、沪、渝等地区14个分行的小企业的财务指标和非财务指标,结合穆迪、标普等国外典型金融机构,中国建设银行等国内典型金融机构的小企业信用指标体系,以及国内外学术文献的小企业指标体系,建立了包含还款能力和还款意愿2个一级准则层,企业内部财务因素等7个二级准则层,偿债能力、盈利能力等10个三级准则层,资产负债率、速动比率等107个指标的海选体系.
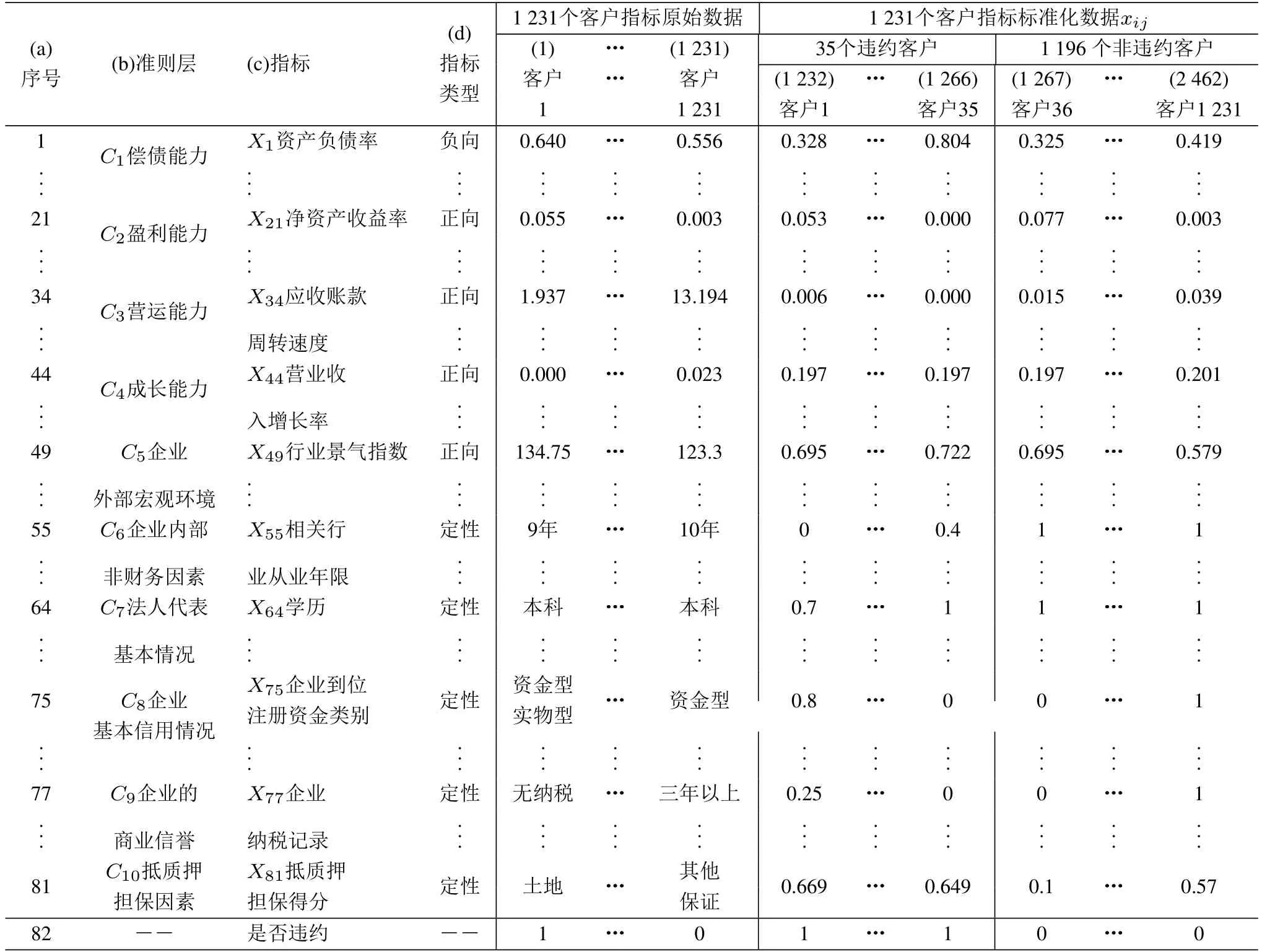
表2 小企业指标的原始数据及标准化数据Table 2 Original data and standardized date of indicators for small enterprises
根据数据可观测性原则,删除还款来源、工资福利增长率等26个数据无法获得的评价指标.删除后剩余的81个指标列于表2第c列前81行,表2第d列是相应的指标类型.为下文实证的方便,将表2第c列的81个指标通过X1~X81进行编号,将表2第b列的10个三级准则层通过C1~C10进行编号.
4.2 样本选取和数据来源
根据中华人民共和国工业和信息化部、国家统计局、国家发展和改革委员会、财政部四部委的2011年6月制定的《中小企业划型标准规定》[23],选取的样本包括批发企业、零售企业、租赁和商务服务业、仓储企业、建筑企业、交通运输企业、住宿餐饮业、房地产开发经营、信息传输业、软件和信息技术服务业、其他企业共12个行业的小企业.
样本数据来源于中国某区域性商业银行总行信贷数据库[24].样本时间序列从1994年到2012年9月1日.在这个时间序列内,有769个小企业发生了贷款行为,共有1 231个小企业贷款借据,涉及京、津、沪、渝等地区14个分行,北京、天津、上海、重庆、大连、盘锦、营口等28个城市.所有贷款样本均是采用基准利率上浮的方式,按月进行还息,最小年利率为5.6%,最大年利率为10.582 5%.在1 231个贷款样本中,有35个违约样本,1 196个非违约样本,违约比率0.827%,违约总额3亿多元.
在表2前81行中:第1列~第1 231列是指标的原始数据;第1 232列~第2 462列是原始数据的标准化打分结果,与第1列~第1 231列的顺序是一一对应.通过式(1)~式(3)对正向、负向和区间指标进行标准化打分,通过表1对定性指标进行标准化打分.表2第82行是1 231个小企业借据的违约标识,“1”代表违约,“0”代表没有违约.
4.3 债信评级指标体系的建立
1)基于方差齐性检验的第一次筛选
通过式(4)计算表2第d列的81个指标的方差齐性检验F值,这个过程可方便地通过SPSS软件实现.在81个指标中,X1等41个指标的F值均小于临界点F0.01(1,1 229)=6.64,检验不通过,说明这41个指标的违约样本和非违约样本的方差没有显著差异,指标不能显著区分违约状态,应该删除.而X2等40个指标的方差齐性F检验值均大于临界点6.64,检验通过,说明这40个指标的违约样本和非违约样本的方差有显著差异,应该保留.通过第一次筛选,在81个指标中剔除41个指标,保留了40个指标.
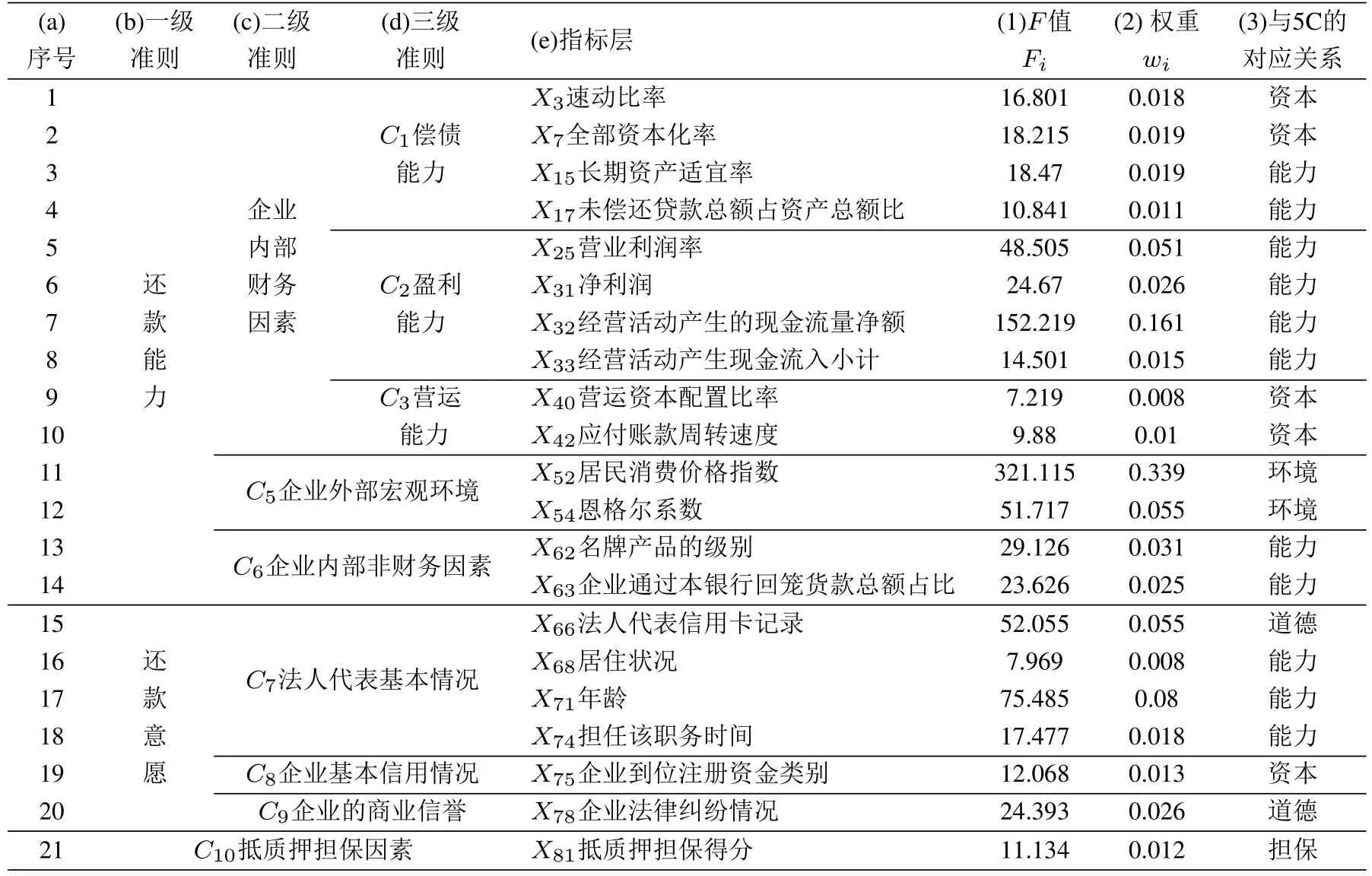
表3 小企业债信评级指标体系Table 3 Indicators system of debt rating for small enterprises
2)基于R聚类的第二次筛选
选取R聚类进行第二次筛选的原因:本文分别通过相关分析、共线性检验和R聚类三种方法进行第二次筛选.在第一次筛选剩余的40个指标中,通过相关分析只能删除7个指标,通过共线性检验删除8个指标,剩余的指标体系依然过于庞大.而通过R聚类可以删除19个指标,使得指标精简到21个,满足商业银行的评级指标不能过多的原则.最终建立的指标体系为表3第e列的21个指标.表3第1列是指标对应的F值.
4.4 债信评分模型的建立和债信等级的划分
1)债信评分模型的建立
将表3第1列的数代入式(7),可以得到21个指标的权重,列入表3第2列.将表3第2列的权重代入式(8),得到小企业债信评分模型为
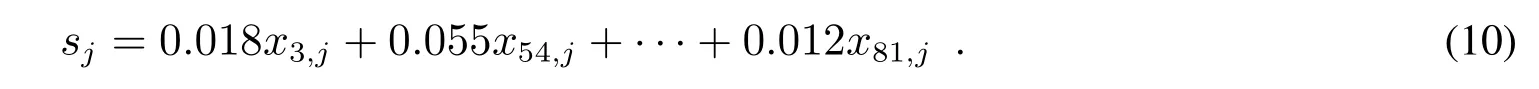
2)基于ROC的债信评分模型的检验
为了验证债信评分模型的违约预测能力,本文分别抽取全样本的30%、40%、…、80%作为检验样本,得到的AUC值如表4所示.通过表4可以看出,6类不同比例的样本的AUC值均大于0.9,说明本文建立的债信评分模型的违约判别能力比较显著.
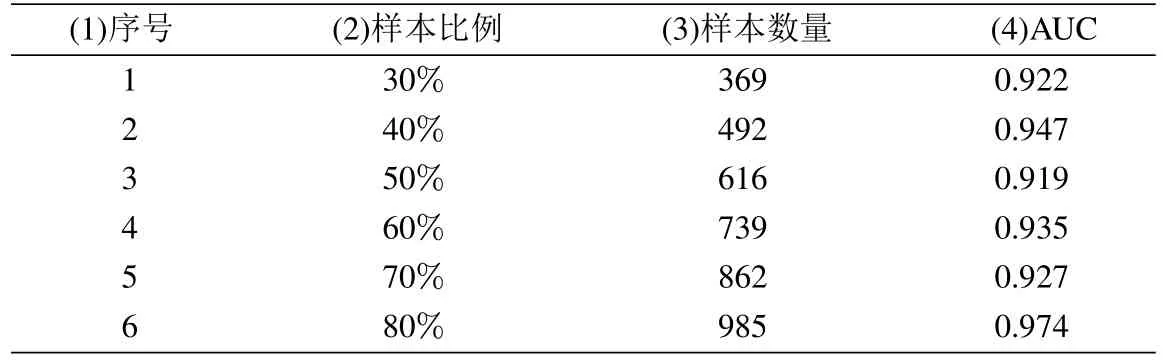
表4 不同比例样本的AUC值Table 4 AUC values of different proportions samples
3)小企业债信等级的划分
根据上文“3.5债信等级划分的方法”,通过国家发明专利[22]可以得到债信等级划分结果,如表5所示.表5第3列是每个债信等级的样本数,第4列是债信等级的年违约损失率,第5列是债信等级的得分区间.
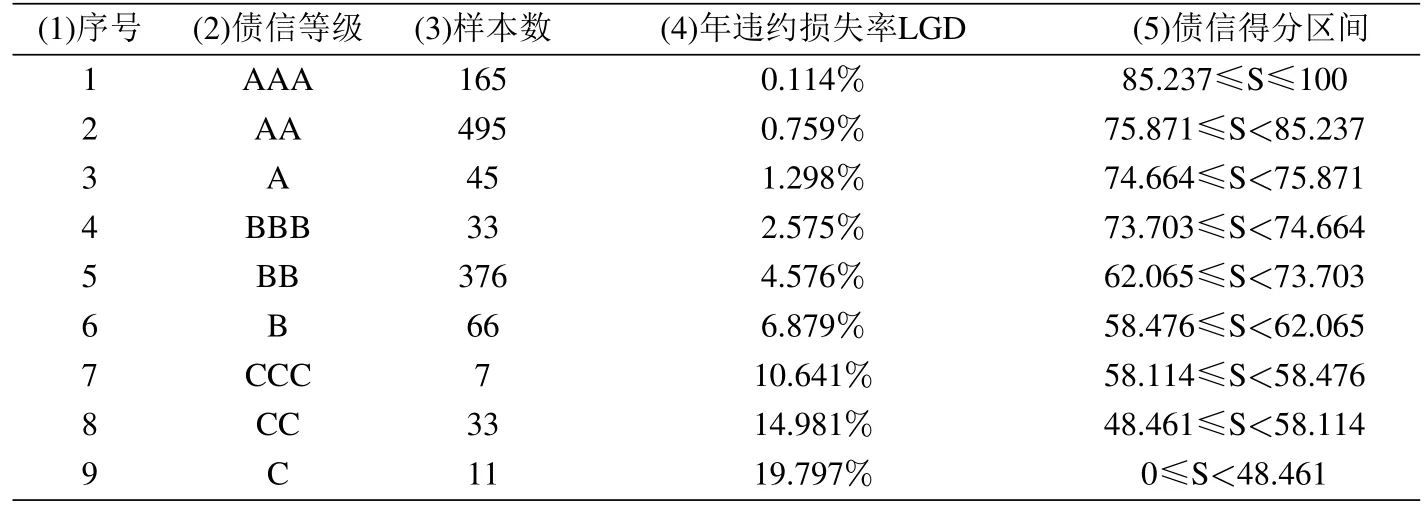
表5 小企业债信等级划分结果Table 5 Debt rating classification results of small enterprises
4.5 小企业债信评级体系的特点
1)系统反映信用评级典型的5C原则.本文建立的小企业债信评级指标体系满足金融界普遍认可的品德(character)、能力(capacity)、资本(capital)、担保(collateral)和环境(condition)等5C信用评价原则,21个指标与5C原则的对应关系如表3第3列所示.
2)评级体系中的21个指标均能显著区分违约与否的状态.由表3第1列的F值可知:评级体系中21个指标的F值均大于显著性水平0.01下F分布的临界值6.64,说明这些指标对违约状态有显著影响.实证结果表明:本研究评级体系中的速动比率、企业到位注册资金类别、企业法律纠纷情况等21个指标均对区分违约状态有显著影响.
3)符合债信等级越高、违约损失率越低的金字塔原则.任何评级体系都要满足“债信等级越高、违约损失率越低”的金字塔原则,否则,无论貌似多么合理的评价方程都是不对的.表5第4列的债信等级年违约损失率严格递增,满足债信等级越高、违约损失率越低的原则.而且,不同等级之间的极差大致相同,不会出现相邻等级年违约损失率的差别过大或过小的现象.
4)恩格尔系数和居民价格消费指数能反映小企业的清偿能力.由表3第11行~第12行可知,居民消费价格指数、恩格尔系数的F值分别为321.12、51.717,高于F分布的临界值6.64,均对小企业违约状态有显著影响,应该保留.事实上,居民消费价格指数反映地区的通货膨胀,属于区间型指标.数值在[101,105]内表明既不通货膨胀又不通货紧缩,越低于该区间,表明通货越紧缩,偿还贷款的能力也越差;越高于该区间,表明通货越膨胀,偿还贷款的能力也越差.恩格尔系数是食品支出总额占个人消费支出的比重.该指标越大,说明食品支出总额的比重越大,则居民的生活水平越低,偿还贷款的能力也越差.
5)抵质押担保因素能反映小企业的清偿能力.由表3第21行可知,抵质押担保因素的F值为11.134,高于F分布的临界值6.64,表明“抵质押担保因素”对违约状态有显著影响,应该保留.实证结果表明:“抵质押担保因素”能够反映小企业的清偿能力.
4.6 几点说明
1)本文债信评级体系设计的完备性
本文的债信评级体系包括指标的遴选、权重的确定和债信等级的划分等主要内容,仅使用其中的某部分模型达不到良好的效果,原因有三:
一是指标的遴选是小企业信用评价的基础和关键,指标体系构建的不合理,无论如何进行评价都是有问题的,指标体系的合理性和准确性则决定着评价结果的可信度.
二是在小企业信用风险评价中,违约的可能性是鉴别客户的最重要的标准,必须贯穿在指标遴选、赋权、评价方程的建立等整个信用风险评价的过程中.否则,就会出现越是可能违约的坏客户,评价得分反而越高的不合理现象.合理的权重可以提高对违约客户的预测精度,减少银行的损失.
三是债信等级的划分必须满足“债信等级越高、违约损失率越低”的信用评级的本质属性,才能在贷款定价时保证不同等级债务人的违约风险得到足额补偿.否则就会出现越是可能违约的客户、债信等级反而越高的不合理现象.
2)本文债信评级体系的对比分析
一是指标体系的对比分析.标普、穆迪和邓白氏通过流动比率、速动比率和资产报酬率等反映企业真实清偿能力的财务指标进行企业信用评价[3].中国建设银行[5]、中国工商银行[6]通过股东的经济实力、管理层的从业经验建立企业评级指标体系.但是这些指标的确定标准不得而知,是否能够显著区分违约状态也是有待商榷.本文首先参考国内外的权威机构和文献梳理建立了海选指标体系,然后通过方差齐性检验遴选对违约状态有显著影响的指标,通过R聚类删除反映信息重复的指标,保证建立的指标体系能够显著的区分客户的违约状态.
二是指标权重的对比分析.标普、穆迪和邓白氏等国际权威机构[3]的信用评级是个黑匣子,仅能从文献梳理中挑选出部分指标,指标权重的确定标准更是无法获取.而中国建设银行[5]、中国工商银行[6]指标的权重是主观设定,并没有根据指标对违约状态的影响程度.本文通过区分违约状态越显著的指标、权重越大的思路进行赋权,使指标权重的大小反映指标鉴别违约状态能力的大小,弥补了现有研究的指标赋权与违约状态鉴别能力无关的弊端.
三是评级结果的对比分析.除了上述“方差齐性检验+R聚类”的方法外,本文还通过“Probit+偏相关分析”、“相关分析+显著性检验”和“支持向量机+共线性检验”等其他3种不同的方法对同一数据进行指标遴选,并通过国家发明专利[22]进行债信等级划分,本文得到的金字塔结果最符合债信等级越高、违约损失率越低的标准,效果最佳.
3)面对突发事件的解决方案
小企业的信用及其评价缺乏稳定性,尤其是受突发事件的影响过大,对此本文的处理方法有二:一是本文建立的小企业债信评级体系包含小企业的财务指标、非财务指标、外部宏观指标、抵质押担保指标等因素,几乎涵盖了影响小企业信用风险的各个方面.如果受到突发事件的影响,小企业的财务、非财务等指标会发生短期急剧恶化,对应这些指标数据进行收集后再代入模型进行评级,评级结果必然发生变化.
二是本文对应的计算机软件系统已经实践应用到中国某区域性商业银行,软件系统中包含评级调整功能,当小企业受到恶劣负面消息等突发事件的影响后,银行可以及时对该企业的评级结果进行修正,以保证银行的贷款定价能够覆盖违约风险.由于该系统涉及商业银行保密性问题,具体操作不宜展开.
5 结束语
本文以中国某一区域性商业银行的京、津、沪、渝等地区14个分行的1 231笔小企业贷款数据为样本进行实证分析,结果表明:速动比率、法人代表信用卡记录等21个指标构成的指标体系不但可以显著区分小企业的违约状态、而且避免了重复反映信息的指标重叠和冗余.同时,小企业债信评级中非财务指标的重要性较大.在21个指标中,10个财务指标的权重和为0.338,11个非财务指标的权重和为0.662,说明在小企业的评级中,单纯以财务指标为主的指标体系已不能反映小企业的信用状况,以宏观环境和定性指标为主的非财务指标扮演者越来越重要的作用.其中,指标X52居民消费价格指数和X32经营活动产生的现金流量净额的权重为0.339和0.116,均超过了0.1,在所有指标中排在前两位;指标X40营运资本配置比率和X68居住状况的权重只有0.008,重要性最低.
