基于数据挖掘的攻击场景提取方法研究
2018-10-24彭梦停胡建伟崔艳鹏
彭梦停 胡建伟 崔艳鹏
(西安电子科技大学网络与信息安全学院 陕西 西安 710000)
0 引 言
尽管IDS在提高计算机网络安全性方面起着关键作用,但也存在一些缺陷,包括警报泛滥、误报、产生不相关的警报有限的可扩展性、缺乏互操作性,以及无法关联并发现原始警报之间的因果关系,无法检测到多步骤攻击[1]。
基于上述缺点,需要一种主动报警关联系统,来从海量的原始警报中,提取重要的攻击场景,清晰地识别攻击者的意图[2]。本文结合文献[1]的研究成果将提取攻击场景的方法分为三组:基于相似度[3-4]、基于序列[5-7]和基于案例的方法[8-9]。
基于相似性的技术旨在通过属性或时间相似性来聚合警报。主要的理论基础是类似的警报有相同的起因或者对监视的系统具有类似的影响。如何为每个属性定义一个合适的相似度函数是关键问题。它们的算法基于简单的逻辑比较,比其他类别的复杂度小。这类方法也可以一定程度上减少警报总数。但是他们只是在属性级别工作,并且无法检测警报之间的因果关系,发现问题的根本原因。比如文献[10]提出了一个基于模糊推理规则的提取多步攻击场景的自适应框架。他们的模型由两个主要部分组成,即在线模糊聚类和模糊事件间模式匹配。第一个组件的作用是使用相似性分数将生成的低级警报聚类到模糊事件中。下一个组件通过发现其中的模糊模式来为第一个组件提供历史低级警报的关联性。由于它们使用了相似性的方法工作,所以不能检测到未知的攻击模式。
基于案例的关联方法依赖于表示场景的知识库。这种类型的许多关联技术已经实现,其中大多数都试图根据已知的场景模板来关联警报。这些模板通过使用定义的专家规则或关联语言表达,或者使用机器学习、数据挖掘技术来推断。比如一些研究工作试图设计和实现一种用于描述已知攻击场景的语言[11]。尽管这些语言提供了描述攻击场景的标准方法,但它们限制了用户只能识别特定和已知的场景。
在基于序列的方法中,警报基于因果关系相互关联。序列相关性可以细分为几个主要类别[1],取决于如何表示建模的场景。数据挖掘、前提/后果条件、图形、马尔可夫模型、贝叶斯网络、神经网络和其他技术,这些方法的主要优点是它们能够检测复杂的攻击场景,发现新的未知攻击场景,以及它们对异构资源的可扩展性和可用性。但是,这些方法中的大多数都会出现关联误报,有两个可能的原因:处理逻辑不当和传感器警报的质量不足。比如文献[12]使用贝叶斯网络来训练警报之间的关联概率,并构造攻击场景ET库。在实时处理警报时,使用和构造ET树一样的方法来构造攻击场景树AT。将实时警报流中没有构成AT树的警报作为训练数据重新用贝叶斯网络进行训练,加入到ET库中,这完成了对未知攻击的学习。但缺点是构造ET树的算法复杂,资源消耗高,且对未知攻击的处理不够准确。文献[13]将警报因果关联图作为知识库,线下构建因果关联树,线上实时接收新警报,在因果关联树中搜索相关的前一个警报。这个方法的优点是系统对每个警报都能高效地处理,随着警报数量的增加,处理时间并没有增多。不足之处在于提取攻击场景的准确率不够高,攻击者试图隐藏攻击步骤时,检测结果不是很完整。而且这个系统不能提取未知的攻击场景。文献[14]提出了一种用于提取攻击场景的数据挖掘框架,由三部分组成:挖掘关联规则、查找频繁项集和聚类。但其中Apriori算法提取频繁项集的情节耗时太大。文献[15]提出了一个集成的智能安全事件关联分析系统KGBIAC,使用知识图来表示和存储网络安全信息,包括CVE漏洞、警报、硬件资源等。这个系统的优点是能整合所有的上下文信息来进行关联,信息来源更加全面。但是需要事先构建知识库。
另外,以上的方法基本在减少警报数量方面做的工作很少,但这是关联攻击阶段前非常重要的一步。他们在实验中没有将同一阶段的警报全部聚类,而是只选取了一个警报。这样与真实的情况不太相符。
本文针对上述各种技术存在的不足,考虑到基于序列方法的优点,研究了警报内部的各种冗余关系以及数据挖掘模型来解决上述的问题。具体提出的算法包括:挖掘强关联规则生成因果关联概率表、多步骤关联。本文算法能有效地压缩警报数量、聚类同一阶段的警报。在不依靠专家知识的情况下,能实时提取单线攻击场景、识别复杂的批量攻击和跳板攻击,实时学习未知的攻击路线。
1 提取攻击场景的方法
本文提取攻击场景最主要的步骤如图1所示。(1)训练已知和未知的攻击场景得到关联概率表,由组件1完成;(2)实时聚类同一个阶段的警报,提取复杂的攻击场景,由组件2完成。
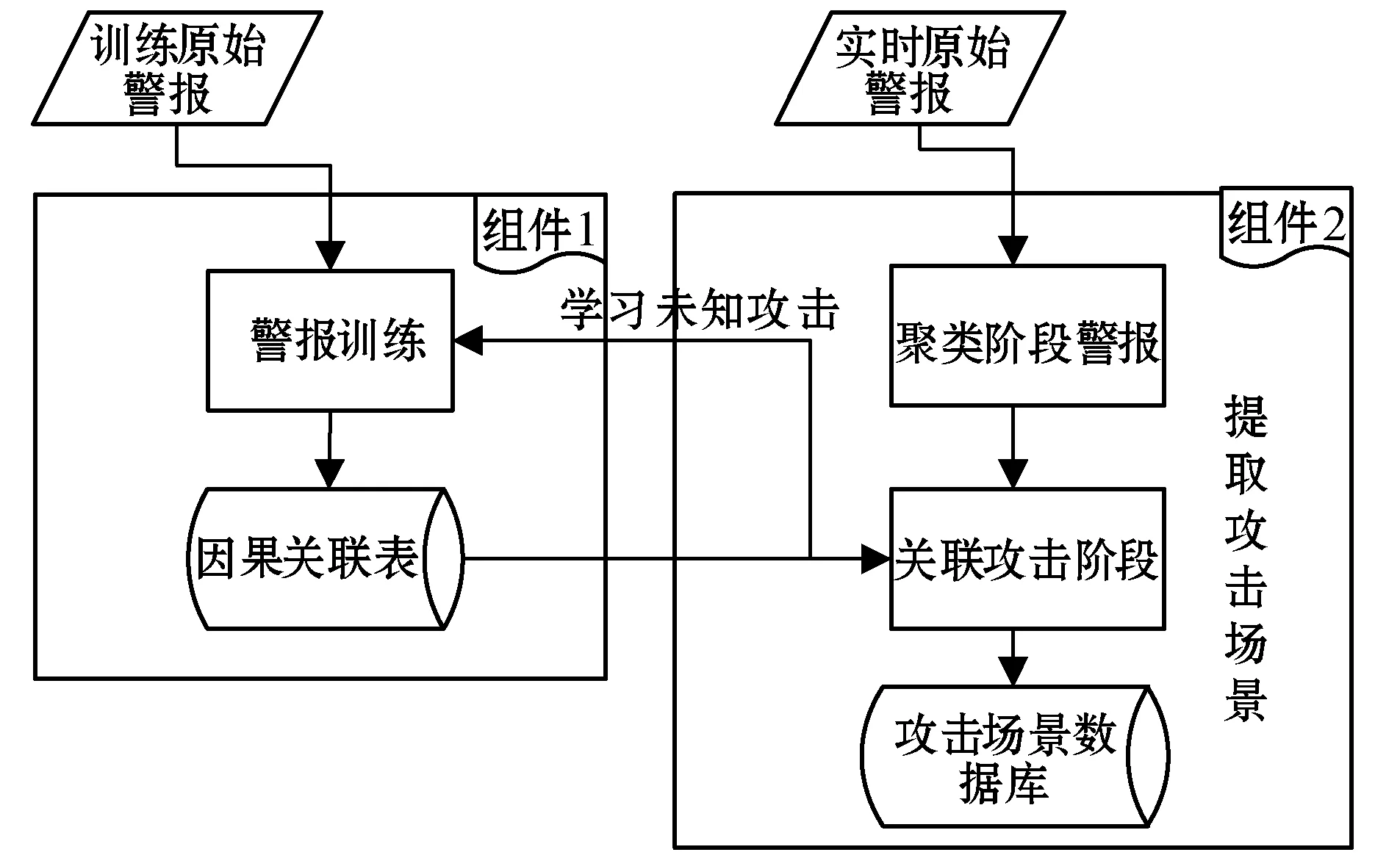
图1 提取攻击场景
1.1 算法相关概念
在本文算法中用到的概念有窗口、支持度、关联规则、因果关联概率、原始警报、攻击阶段、超级警报,下面将介绍这些概念。
滑动窗口:win_size是窗口大小,如果[Ai,Ai+1,…,Ai+win_size-1]是某一个窗口,则下一个窗口会在警报序列中与这个窗口共享win_sub个警报,也就是向后滑动Δ=win_size-win_sub个警报,为[Ai+Δ,Ai+Δ+1,…,Ai+Δ+win_size-1]。
一般在多步骤攻击中,上一阶段的攻击结果是下一阶段攻击的原因,这就叫作警报之间的因果关系,两者相关的概率为因果关联概率。关联规则是数据挖掘方法之一,关联规则的可信度可以被视为因果关联概率。我们定义以下概念:
顺序集:数据流中警报的有序列表,如A=[A1,A2,…,An]。每个窗口都是一个顺序集。
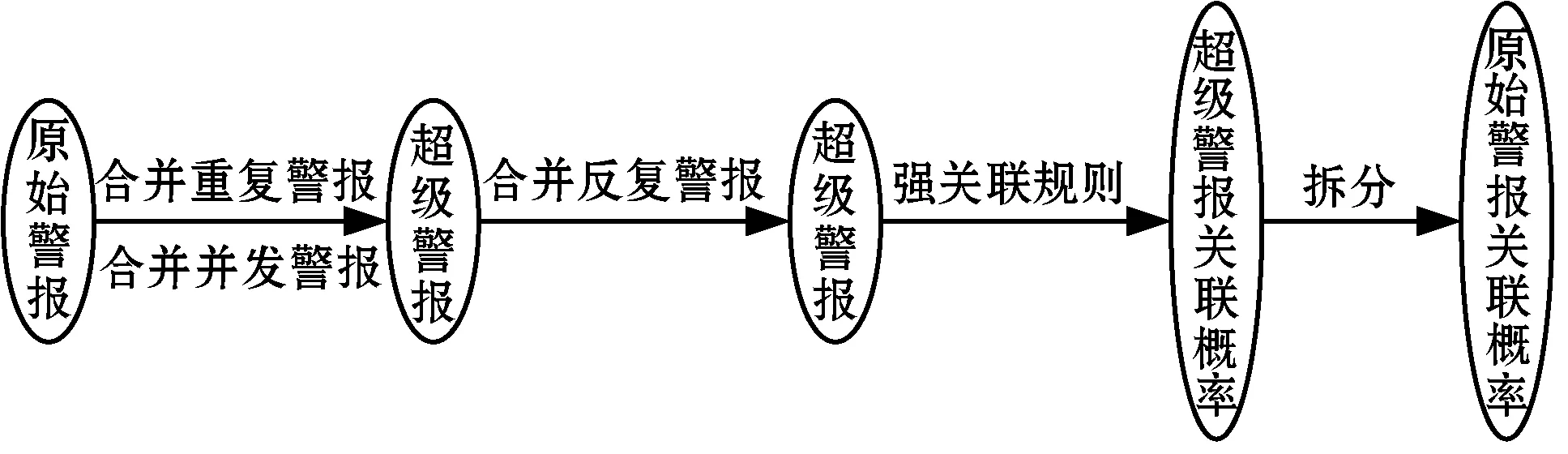
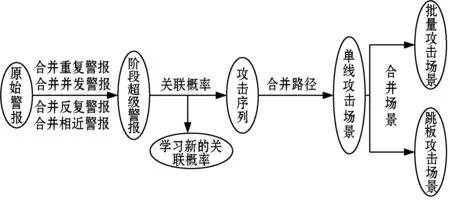
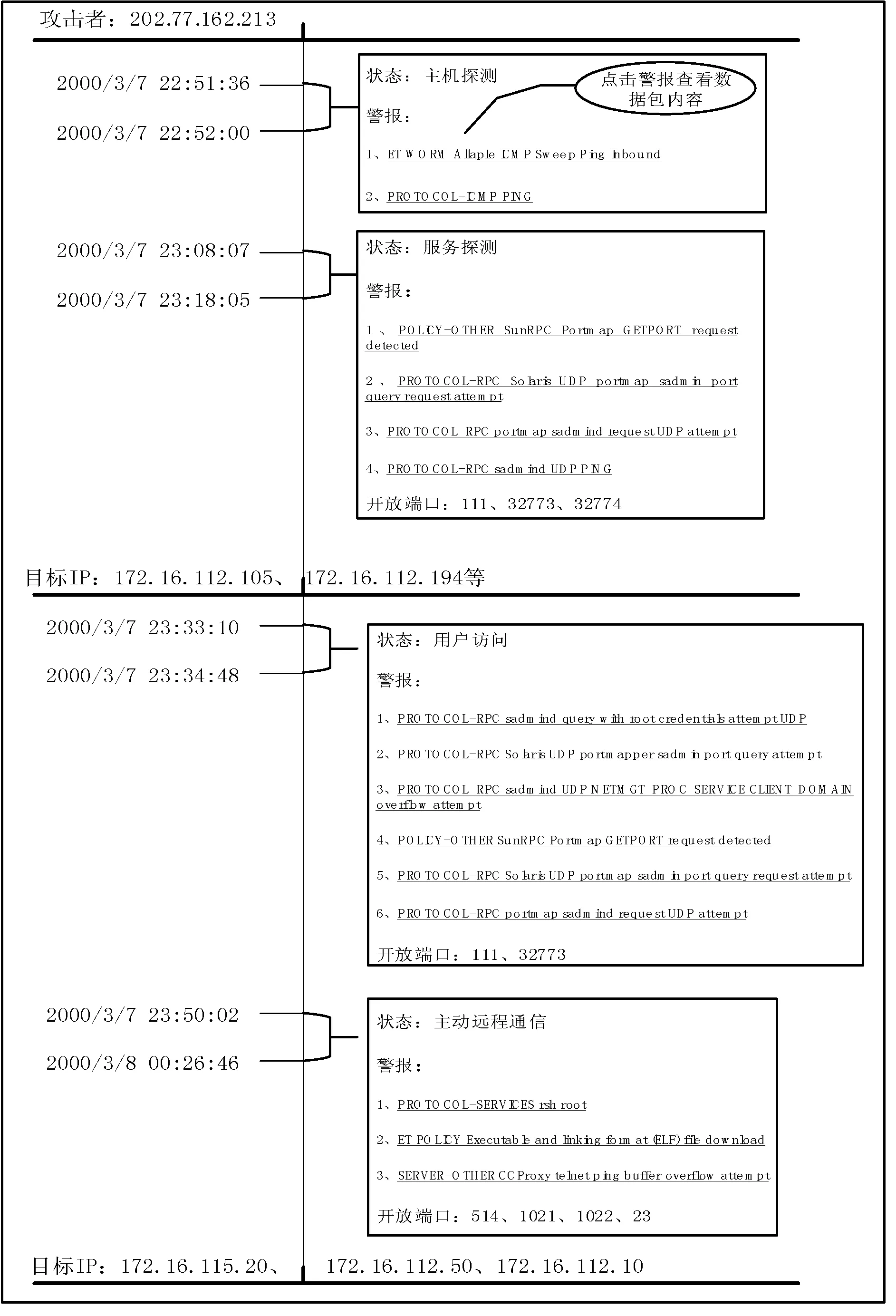
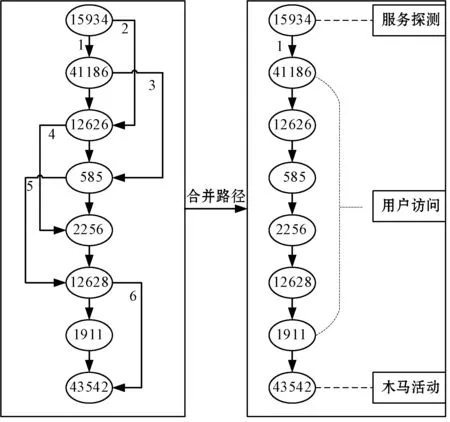
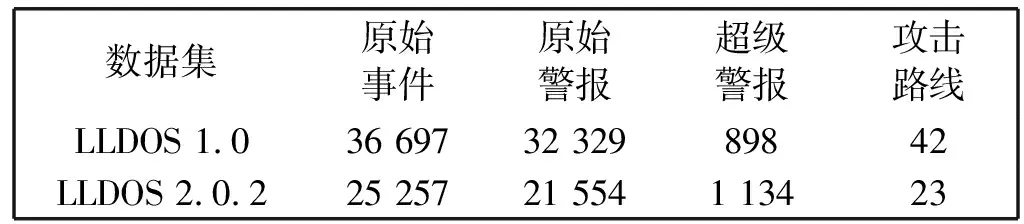
项目集:顺序集的子集t=[t1,t2,…,tm],设1≤t1 支持度sup:顺序集中项目集出现的次数。 最小支持度min_sup:顺序集中项目集最少出现的次数。 关联规则:是形如Ai=>Aj的蕴含式,其中Ai和Aj是顺序集A中的项,且Ai∩Aj=∅。 强关联规则:满足最小支持度和关联概率阈值T的关联规则。 原始警报:每个数据源生成的事件日志格式不一样。对于同一种攻击手段,不同的数据源会产生不同的警报类型,容易误判。因此需要标准化原始警报,存储以下属性:时间戳、警报类型、源IP、目的IP、源端口、目的端口、数据包内容、优先级、攻击阶段。 攻击阶段:一般数据源不会记录攻击阶段这一属性。我们定义了警报类型与攻击阶段的对应表。实际上不同的攻击者使用的攻击手段有很大的主观性,每个类型的警报可能会出现在一个或多个阶段,因此警报类型与攻击阶段设定为一对多的关系。本文在不脱离PTES渗透流程[16]的基础上,提出了更加细化、更易理解的13个攻击阶段:枚举、主机探测、服务探测、漏洞探测、用户访问、系统或管理员访问、系统妥协、敏感信息获取、主动远程通信、木马活动、破坏可用性、破坏完整性、破坏保密性。 超级警报:超级警报由原始警报或超级警报合并而成,具有以下属性:警报类型ID的集合、开始时间、结束时间、攻击阶段、源IP、目的IP、端口。合并时需要更新类型、端口、源IP、目的IP为警报流中相应属性的非重复合集,取开始时间为警报流的最小时间,结束时间为警报流的最大时间,取攻击阶段为警报流中出现频率最高的阶段。为了节省内存,训练关联概率时只需要记录超级警报的类型。 在分析了大量典型的攻击数据包后,我们发现同一秒内发生在同一攻击者和受害者之间的警报有两种情况:(1) 所有警报的类型完全一样,称为重复警报。原因是攻击者在很短的时间内使用了同样的手段但尝试了不同的参数,进行了同一类型的攻击,或者同一个攻击的多个数据包触发了多条相同的警报。(2) 警报类型不一样,称为并发警报。原因是IDS检测引擎使用了多条规则匹配到了同一时刻的同一攻击行为,或者多个检测引擎对单个事件产生了多个警报。 本文基于以下几个理论来聚类同一阶段的警报: 1) 重复警报和并发警报属于同一攻击阶段。 2) 超级警报序列中连续且类型相同的警报可以认定属于同一攻击阶段,称为反复警报。 3) 如果序列中相邻的超级警报经常同时且无序出现,这就说明二者属于同一攻击阶段,我们称为相近警报。 我们将单一攻击者和受害者之间的攻击场景称为单线攻击场景。使用关联概率表来连接属于同一单线攻击场景的攻击阶段,这里一个超级警报代表一个攻击阶段。设置回溯因子p,如果第i个超级警报与第i+n(1≤n≤p)个超级警报之间关联概率大于等于T,则认定两者为同一场景中的警报。 一般文献提出的方法只能做到提取单线攻击的程度。我们另外提出了识别跳板攻击场景和批量攻击场景的方法。如果两条单线攻击路线有相同的攻击者和受害者,攻击的前面阶段使用的手段类似,且发生的时间非常相近,则认为二者属于同一个批量攻击场景。如果两条单线攻击路线满足以下2个条件,则说明二者是同一个跳板攻击场景: 1) 原始攻击者渗透肉鸡(A->B)的手段与肉鸡渗透其他主机(B->C,B->D)的手段一样。 2)A->B攻击场景发生时间在前,B->C(或B->D)攻击场景发生时间在后,且时间间隔在一定阈值内。 组件2接收到实时的警报流,其中会有部分警报不满足关联条件,不能被指定到任一条攻击路线中。如果这个警报的优先级比较高,则以该警报为中心,取包含该警报的三个窗口大小的警报流送入关联概率训练组件进行训练,如果得到新的关联警报对,则更新关联概率数据库。这种做法不会忽略威胁程度比较高的攻击手段。取三个窗口大小的序列,是为了满足训练关联算法中的回溯条件,以便得到比较正确的关联警报对。 训练关联概率的过程如图2所示,本文基于数据挖掘的方式,将已知攻击阶段的原始警报流作为输入,合并重复警报、并发警报、反复警报,找出超级警报的强关联规则,最后得到原始警报之间的关联概率。其中合并警报的过程可以有效减少警报的数量,提升计算关联概率的效率。 图2 训练关联概率 下面是训练算法的步骤。 步骤1原始警报流按时间排序。 步骤2以整1秒的警报流为一个窗口,合并重复警报和并发警报为超级警报Ai。具体处理如下: 1) 遇到n个重复的警报,取超级警报Ai的类型为其中任一警报的类型。如果n≥min_sup,记录min_sup个Ai,否则记录n个Ai。 2) 遇到并发警报,取超级警报Ai的类型为警报流所有类型的并集,记录Ai。 步骤3将超级警报按照时间排序,如果连续且类型相同的警报Ai(反复警报)数量大于等于min_sup,则合并为min_sup个警报Ai。 步骤4将超级警报序列按照1.1节中滑动窗口的规则分为多个窗口。每个窗口中找出超级警报之间的强关联规则,计算相应的关联概率。假设Ai在前Aj在后,计算超级警报Ai和Aj之间的关联概率时: 1) 如果Ai是Aj的子集,则记录关联概率为conf(Ai=>(Aj-Ai))=probability。 2) 如果Aj是Ai的子集,则略过不记录。 步骤5将每个超级警报中的原始警报a分离出来,生成原始警报类型之间的关联概率表,形如conf(ai=>aj)=probability。如果遇到相同的警报对,数据库中对应的概率值会被覆盖。 识别攻击场景的过程如图3所示。将实时的原始警报流作为输入,通过合并重复警报、并发警报、反复警报、相近警报来生成超级警报,这也是聚类初步的攻击阶段以及压缩警报的过程。再利用2.1节训练得到的关联概率表连接相关的攻击阶段,得到单线攻击场景。最后判断是否满足跳板攻击和批量攻击的特征,合并攻击路线。 图3 识别攻击场景算法 本文取35 000个实时的原始警报为一个批次,下面是提取批次内攻击场景的算法步骤: 步骤1将一个批次内实时的警报流按照源IP和目的IP分类,每一类按照时间排序,进行下面的步骤。 步骤2和2.1节算法的步骤2一样合并重复警报和并发警报。 步骤3将超级警报序列中的反复警报合并为一个超级警报。 步骤4对相邻的超级警报Ai和Ai+1,做如下处理: 1) 如果Ai[type]是Ai+1[type]的子集,令Ai+1[type]=Ai+1[type]-Ai[type]。 2) 如果Ai+1[type]是Ai[type]的子集,令Ai[type]=Ai[type]-Ai+1[type]。 3) 否则令Ai[type]=Ai[type]-Ai+1[type],Ai+1[type]=Ai+1[type]-Ai[type]。 经过上述3个处理后,如果Ai中任一警报ai与Ai+1中任一警报aj的相互关联概率满足: ccm[(ai,aj)]≥T&&ccm[(aj,ai)]≥T (其中ccm是关联概率表),则认为Ai和Ai+1为相近警报,可以合并为一个超级警报。 步骤5遍历超级警报序列,如果第k个超级警报与第k+n(1≤n≤p)个超级警报相关(p是回溯因子),即两者取任一原始警报ai和aj,如果ccm[(ai,aj)]≥T,则将二者连接为二元序列。将所有二元序列按先后顺序首尾相连,得到完整的关联序列。对于序列中不满足关联条件的超级警报,如果其优先级比较高,则以该警报为中心,取包含该警报的三个窗口大小的原始警报流送入组件一进行训练,更新关联概率数据库。 步骤6合并路径,处理以下特殊情况: 1) 去掉子集序列。有些序列是别的序列的子集,反映出来的场景只是全部攻击过程中的一个片段。 2) 合并环路。有些序列内部会有路径成环的情况,比如A->B->C->A。 步骤7查找数据库中同类的攻击序列(源IP和目的IP相同),如果其最后一个超级警报与当前序列的第一个超级警报相关(判断方法同步骤5),则将两个序列合并成一个。 步骤8对得到的每一个攻击序列,按照步骤9-步骤10合并批量攻击序列。按照步骤11合并跳板攻击序列。 步骤9在步骤8得到的所有序列中查找满足源IP相同且第一个攻击阶段的开始时间相差在一定阈值t内的序列。实验中为了尽可能不漏掉任何一条可能的场景序列,取t为5分钟。 步骤10对于步骤9得到的序列,取最长的为基准序列,其他序列与其进行每个攻击阶段从前往后的比较,满足以下条件则进行阶段合并: 1) 攻击阶段的警报类型相似,即互相为子集或者相似警报的比率大于等于r,实验中r取80%。 2) 攻击阶段的警报发生时间相近,即开始时间或者结束时间的差值在一定阈值内,实验中设定为5分钟。 步骤11遍历步骤8得到的所有序列,如果两条序列的攻击阶段一样,接着比较两者同一阶段的超级警报,如果满足下面的条件,则进行序列合并: 1) 警报类型相似,即互相为子集或者相似警报比率大于等于r,实验中r取80%。 2) 警报发生时间有先后顺序,跳板路线(跳板主机渗透其他主机)时间相对在后。 步骤12将所有攻击序列存入数据库。 DARPA 2000数据集已经在提取攻击场景领域的许多研究工作中使用[3-4]。DARPA 2000数据集由LLDDoS 1.0和LLDDoS 2.0.2两个子数据集组成,与多步DDoS攻击场景相关。在本文中,我们使用它们来测试提取多步攻击场景方法。 我们使用LLDDoS 1.0和LLDDoS 2.0.2两个数据集进行了实验,其中2.2节算法步骤1-步骤7从LLDOS1.0数据集中提取了总共20条单线攻击场景。目标IP是172.16.112.50、172.16.112.10、172.16.115.20的3条攻击路线共包括主机探测、服务探测、用户访问、主动远程通信四个攻击阶段;目标IP是172.16.112.105、172.16.112.194等的17条攻击路线共包括主机探测、服务探测两个攻击阶段。这20条攻击路线在前两个阶段是有批量行为特征的。2.2节算法步骤9-步骤10对上述20条攻击路线进行关联处理,最后得到一个更加准确、更加宏观的攻击场景,更符合实际情况。可视化界面(见图4)中将展示攻击者202.77.162.213在一定时间段内对172.16.115.20等20个目标主机的详细攻击信息,包括攻击阶段、产生的警报、目标端口、相关数据包内容等,可以帮助管理员回溯攻击者的攻击路径、明白攻击者的意图并及时响应。 图4 批量攻击场景 从图4中可以看出,我们的方法能很好地聚类同一阶段的警报。文献[12]使用基于相似性的预处理方法,该方法将在一定时间阈值内特征相似的警报整合为一个超级警报。我们用LLDOS 2.0.2的数据集对这个方法实验后,提取出图5的攻击场景。图中不同编号的实线代表不同的攻击路线,数字代表警报类型ID(虚线右端的不属于实验结果)。可以看到,该方法能将原始警报聚类到一个攻击场景中,但每个原始警报都可以当成一个攻击阶段,这样的聚类不够准确直观。 图5 基于相似性方法 本文通过为不同的数据源配置插件文件来标准化原始警报,配置中可以通过排除某些事件类别、事件级别,通过定义正则表达式或使用策略来丢弃噪声事件。在提取攻击场景的算法中,通过合并重复警报、并发警报、反复警报、相近警报来将原始警报聚类成超级警报,这个过程能有效压缩警报且不影响包含的安全信息。表1是对于数据集LLDOS 1.0和LLDOS 2.0.2进行提取攻击场景实验后的数据统计,着重体现警报数量的变化情况。 表1 压缩警报实验数据 提取攻击场景方法的各个阶段对数据集LLDOS 1.0和LLDOS 2.0.2压缩警报的比率见表2。文献[12]中提出的数据预处理方法对两个数据集压缩警报的比率分别为25.77%和32.61%,而本文的处理比率分别达到97.56%和95.51%,效果更好。 表2 各个阶段压缩警报的比率 针对目前IDS的缺陷,我们提出了一种高效的提取攻击场景的方法,具有以下优点: 1) 不需要专家知识,利用数据挖掘来关联警报。 2) 能有效聚类同一阶段的警报,极大地压缩警报数量,提高关联效率。 3) 算法的简单性降低内存消耗和计算开销。 4) 能提取复杂的跳板攻击和批量攻击场景。 5) 能实时学习未知的攻击场景。 本文提出的解决方案还有不少有待补充和完善之处,比如:在挖掘强关联规则时,使用恒定长度的窗口大小,可能会刚好错过关联警报对。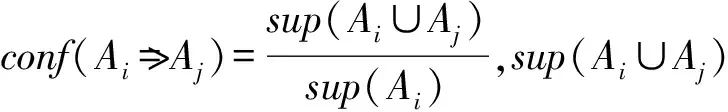
1.2 聚类阶段警报
1.3 关联攻击阶段
1.4 检测未知攻击
2 提取攻击场景算法实现
2.1 训练关联概率
2.2 识别攻击场景
3 实验和性能评估
3.1 提取攻击场景性能评估
3.2 警报压缩性能评估

4 结 语
