基于高斯混合模型与CNN的奶牛个体识别方法研究
2018-10-24刘杰鑫何东健宋怀波
刘杰鑫 姜 波 何东健 宋怀波
(西北农林科技大学机械与电子工程学院 陕西 杨凌 712100) (农业部农业物联网重点实验室 陕西 杨凌 712100)(陕西省农业信息感知与智能服务重点实验室 陕西 杨凌 712100)
0 引 言
随着信息技术的飞速发展,奶牛养殖体系逐步呈现出规模化和智能化的特点。奶牛个体识别作为个性化、精细化管理的基础已成为当前研究的热点,受到了越来越多的关注。传统的奶牛养殖中,通常采用为每头奶牛佩戴标签的方式进行管理,耗费人力,工作繁琐。目前国内畜牧业比较流行的识别方式主要基于无线射频识别技术[1-2],但是该技术无法实现远距离识别,且整套设备成本高,具有较大的局限性。奶牛视频中包含奶牛个体的身份信息,运用视频分析和图像处理技术进行奶牛的个体识别,可以进一步提高奶牛的智能化养殖水平并降低成本。
随着计算机视觉的发展,利用图像处理算法实现奶牛个体识别引起了国内外相关学者的关注。Cai等[3]提出了一种基于牛脸局部二值模式(Local Binary Pattern)纹理特征的识别方法,当选取90%的数据训练时,结合图像的稀疏低秩分解方法识别准确率达到95.30%。Santosh等[4]提出了一种基于牛口鼻处纹理特征提取的方法,在500头牛每头10幅图像进行实验的条件下,识别率为93.87%。Kumar等[5]提出利用Fisher线性保留映射FLPP(Fisher Linear Preserving Projection)的方法来提取牛口鼻特征,通过SVM训练预测达到96.87%的准确率。赵凯旋等[6]设计了一种基于CNN网络的奶牛个体身份识别方法,运用帧间差值法、二值图像跨度分析和Meanshift算法很好地进行了奶牛个体躯干的定位和跟踪,选择LeNet-5网络结构进行训练和预测,识别率为90.55%。张满囤等[7]基于对小波变换和改进核主成分分析KPCA(Kernel Principal Component Analysis)算法的研究,采集20头奶牛个体的20 000幅奶牛图像,通过多次对比实验设定参数,结果表明识别率为96.31%。
针对上述部分研究采用传统机器学习方法提取特征不充足和采用CNN的研究中深度学习网络识别率不高的问题,本文提出一种利用视频中每一帧图像建立高斯混合模型的奶牛定位跟踪算法。在此基础上生成奶牛个体侧身的彩色图像,利用迁移学习进行CNN深度网络的微调和训练,最终实现较高准确率的奶牛个体识别。
1 实验条件
1.1 视频采集
实验视频源自陕西杨凌科元克隆股份有限公司的规模奶牛养殖场,拍摄时间为2013 年7月至8月每天的7:00-18:00 时段,拍摄对象为健康的美国荷斯坦奶牛。摄像机能够拍摄到奶牛从左侧移动到右侧的躯干图像,其视野宽度大于2个牛身长度。通过采集和筛选获得35头奶牛共计210段视频,每段视频持续时长10 s左右。采集到的视频经过MPEG-4转码得到avi格式的视频,帧率为25 fps,码率为512 kbps,分辨率为320×240(单位:像素)。
本研究所使用的视频信息如表1所示,由于受到奶牛成群行走、工人作业等客观因素的影响,视频信息受干扰较为频繁,在数量有限的视频资源中不易实现奶牛个体的识别。
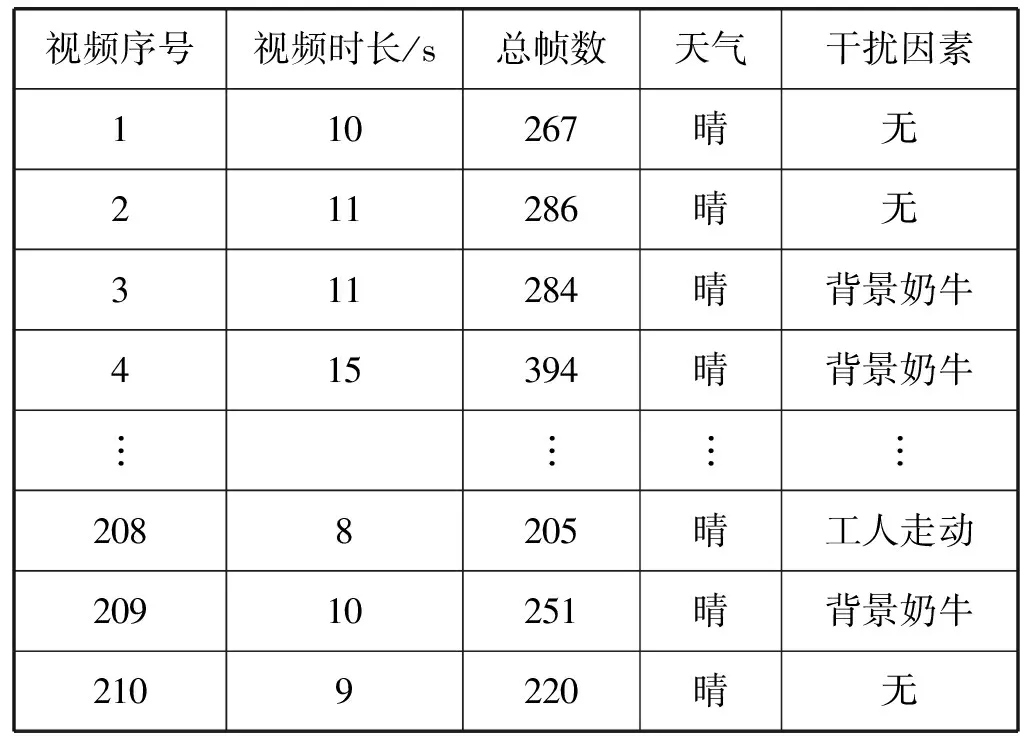
表1 奶牛个体识别视频信息统计
1.2 实验平台
视频处理平台为MATLAB R2017a,处理器为英特尔Core i5-6300HQ,主频2.4 GHz,内存8 GB,显卡为英伟达GeForce GTX 960M,操作系统为64位Windows 10 系统。在训练深度学习网络时使用GPU并行运算,加快收敛速度。
2 实验方法
2.1 算法流程
为了便于实验方法的分析与阐述,给出本研究使用的算法流程,示意图如图1所示。首先采集和处理奶牛个体视频,通过视频中的帧序列图像建立高斯混合模型,对提取出的前景模型进行最大化连通域、规定像素占比的处理,得到奶牛个体图像。其次将所得到的图像输入深度学习网络进行训练,Softmax 和SVM分类器分别学习网络输出的特征值。最后对分类器的分类效果进行了实验对比。
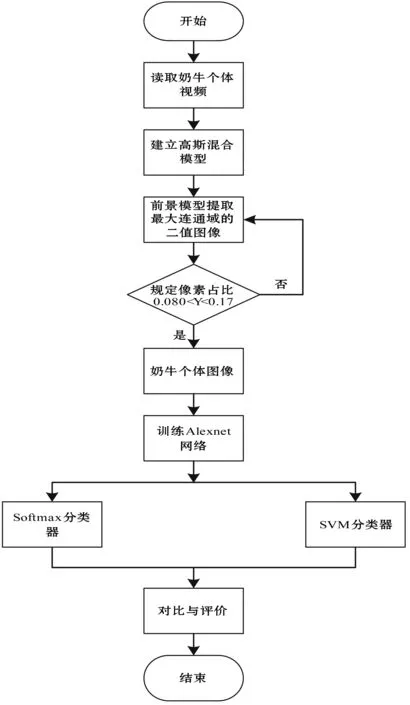
图1 算法流程示意图
2.2 高斯混合模型
视频序列图像中每个像素点的灰度值短时间内基本上是围绕某一中心值在一定距离内呈规律分布[8-11],中心值可用均值代替,距离可用方差代替。在样本量充足的条件下,分布规律呈正态分布,也称为高斯分布。高斯混合模型指像素点灰度值在场景变化的情况下存在多个中心位置,每个位置产生一个单高斯分布,多个单高斯分布组成高斯混合模型。高斯混合模型适合于检测缓慢移动的物体,也能适应光照变化缓慢的场景。
2.2.1 高斯混合模型定义
假设图像是单通道,定义K(3~5)个高斯函数来表示每一个像素点的像素值。对于每一个采样点,均服从高斯混合分布,如下所示:
(1)
(2)
|xt-μi,t-1|≤2.5σi,t-1
(3)
式中:η(xi,μi,t,σi,t)为t时刻第i个高斯分布,ωi,t为t时刻第i个高斯分布的权重。式(2)中μi,t、σi,t分别为其均值和方差。将每一个新像素值xt与该点已存在的K个高斯分布依次比对,直到与其中的某个分布匹配。若满足式(3),则称xt与第i个分布匹配。
2.2.2 模型参数更新
若该像素值符合匹配要求,则该像素属于背景,各参数更新公式如下所示:
ωi,t=(1-α)×ωi,t-1+α×M
(4)
ρ=α×η(xt,μi,t,σi,t)
(5)
μt=(1-ρ)×μt-1+ρ×xt
(6)
(7)

2.2.3 产生新分布
若该像素不与任一个高斯分布匹配,则将权重最小的高斯分布用一个新分布替换。新分布的均值即为当前像素值,方差初始化为较大的方差。
2.2.4 生成背景模型
将K个分布按照ω/σ2的值从大到小排列,选取前B个分布构成新背景模型,T为背景像素所占的比例。B值按下式计算:
(8)
2.3 奶牛个体检测
获取奶牛个体大样本数据是奶牛个体识别的基础。本研究在利用高斯混合模型进行运动奶牛目标检测时,通过将视频中当前帧未匹配的像素赋值为255,其余赋值为0作为背景点,使用模板大小为7×7、强度为1的高斯滤波器进行滤波,即可实现前景目标的初步检测。通过读取帧图像中的所有连通区域,并提取像素点数量最多的连通区域即可得到前景区域的检测结果,同时可以避免数量多且面积小的噪声区域对目标区域提取的干扰。示例结果如图2所示。由图2可以看出,根据视频中的帧序列图像建立高斯混合模型,二值化提取奶牛运动的模糊轮廓,利用最大连通域的方式将帧图像中的奶牛定位,根据定位矩形框的坐标信息与尺寸信息即可截取奶牛个体图像。

(a) 原始图像 (b) 前景提取

(c) 视频定位 (d) 定位结果图2 定位过程示意图
为了进一步消除因光照突变或背景晃动等因素造成噪声连通域扩大从而误提取的影响,本研究采用规定像素占比的方式,即观察每段视频每帧图像中最大连通域的像素个数占整个图像的比例确定最佳占比,从而实现奶牛个体的定位。通过实验,最佳占比为0.08至0.17。从图3可以看到,当选取帧间差为2时,以示例视频为例,定位的奶牛个体最大占比为0.13,最小占比为0.095,分别出现在视频的第61帧和第73帧。控制比例范围还可以确保截取到的图像包含奶牛的整体特征以提高识别准确率。

图3 视频中定位图像占比示意图
最终,通过高斯混合模型的定位截取方式总计获得35头奶牛的15 300幅测试图像,每一类样本数情况如图4所示。受到如表1所示干扰因素的影响,每头奶牛的测试图像数量最少为300幅,最多为609幅。为了防止不同样本数量对识别结果的影响,在识别时随机选择每类300幅,共计10 500幅图像组成样本库,随机选取每一类的70%作为训练集,30%作为测试集进行验证。

图4 每头奶牛样本数示意图
2.4 深度学习网络构建
2.4.1 Alexnet网络
CNN提取的特征是从大数据中自动学习得到,避免了传统方法手工设计的局限性。由于CNN良好的性能在图像识别领域得到广泛应用[12-16]。AlexNet是CNN领域内具有重要意义的一个网络模型,证明了CNN在复杂模型下的有效性。AlexNet的网络层数共有八层,前5层为卷积层,后3层为全连接层,最后一个全连接层具有1 000个输出节点。输入图像大小为227×227×3,经过卷积、激活、局部响应归一化、池化等操作,得到6×6×256大小的特征图,再使用全连接神经网络和Softmax分类器[17]进行训练和预测,最终输出1 000个分类值[18-19]。
2.4.2 网络的迁移学习
针对样本数量不充足导致深度学习网络准确率偏低的问题,本研究采用迁移学习的方式[20],即获取已利用大数据训练好的Alexnet,通过微调,以适应奶牛个体的识别。Image-caffe-alex是在Caffe平台上经过大量数据训练得到的1 000类别的识别网络,该网络的Top-5错误率为19.60%。考虑到实验中奶牛的种类数为35,将网络的最后一层全连接层‘fc8’输出由1 000改为35,在GPU上进行训练,批处理大小为64,训练5代,迭代次数为575次时,耗费的时间为495.42 s,代价函数收敛至0.002 4,测试集识别率为98.91%。
2.4.3 SVM分类器
SVM是机器学习领域的经典分类器,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势。结合深度学习网络,经迁移学习后的Alexnet,删除最后一层全连接层‘fc8’,图像数据通过网络前向传播至‘fc7’全连接层,输出4 096个特征值。由于训练样本数为7 350,与特征数差距不大,可以利用线性SVM以获得较好分类效果。将7 350×4 096的训练集按属性列归一化至[0,1]区间,输入至SVM分类器中训练,对比方式为“一对多”,经过10折交叉验证得到SVM分类器的训练集分类错误率为0.006 0。
3 实验对比
3.1 实验结果
针对建立的Softmax和SVM分类器的识别方法,通过对测试集准确率的计算进行了分类器鲁棒性检验。为了增大数据的随机性,训练集和测试集随机在样本库每一类中按7∶3的比例分配,进行了10组深度学习网络的训练和测试,测试结果如图5所示。
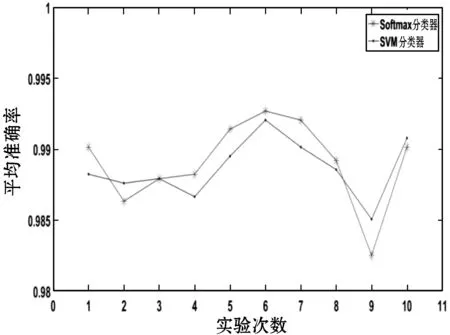
图5 Softmax和SVM分类器准确率对比图
可见Softmax分类器测试准确率的均值为98.91%,SVM分类器为98.87%,两者相差0.04%,分类效果相近,均可取得较好的奶牛个体识别结果。
为了验证算法的抗噪性,在加入噪声的每一类图像中随机选取10幅作为测试图像,拟定在每一个噪声密度条件下做10组实验,将分类器的准确率取平均值,加噪声效果如图6所示。选取第10组(Softmax和SVM分类器准确率分别为99.02%、99.08%)训练好的深度学习网络和分类器进行分类器准确率检验,测试结果如图7所示,可以看到随着噪声密度的增加,Softmax和SVM分类器准确率的变化情况有所差异。结果显示,在噪声密度为0时,Softmax分类器的平均准确率为99.52%,SVM分类器的平均准确率为99.81%。当D为0~0.075时,SVM分类器准确率高于Softmax,当D为0.075~0.17时,Softmax分类效果更明显,而当D大于0.17时,Softmax和SVM分类平均准确率基本持平,D=0.17时分别为4.63%和4.73%。

(a) 原始图像 (b) 加噪声图像图6 加噪声前后对比图
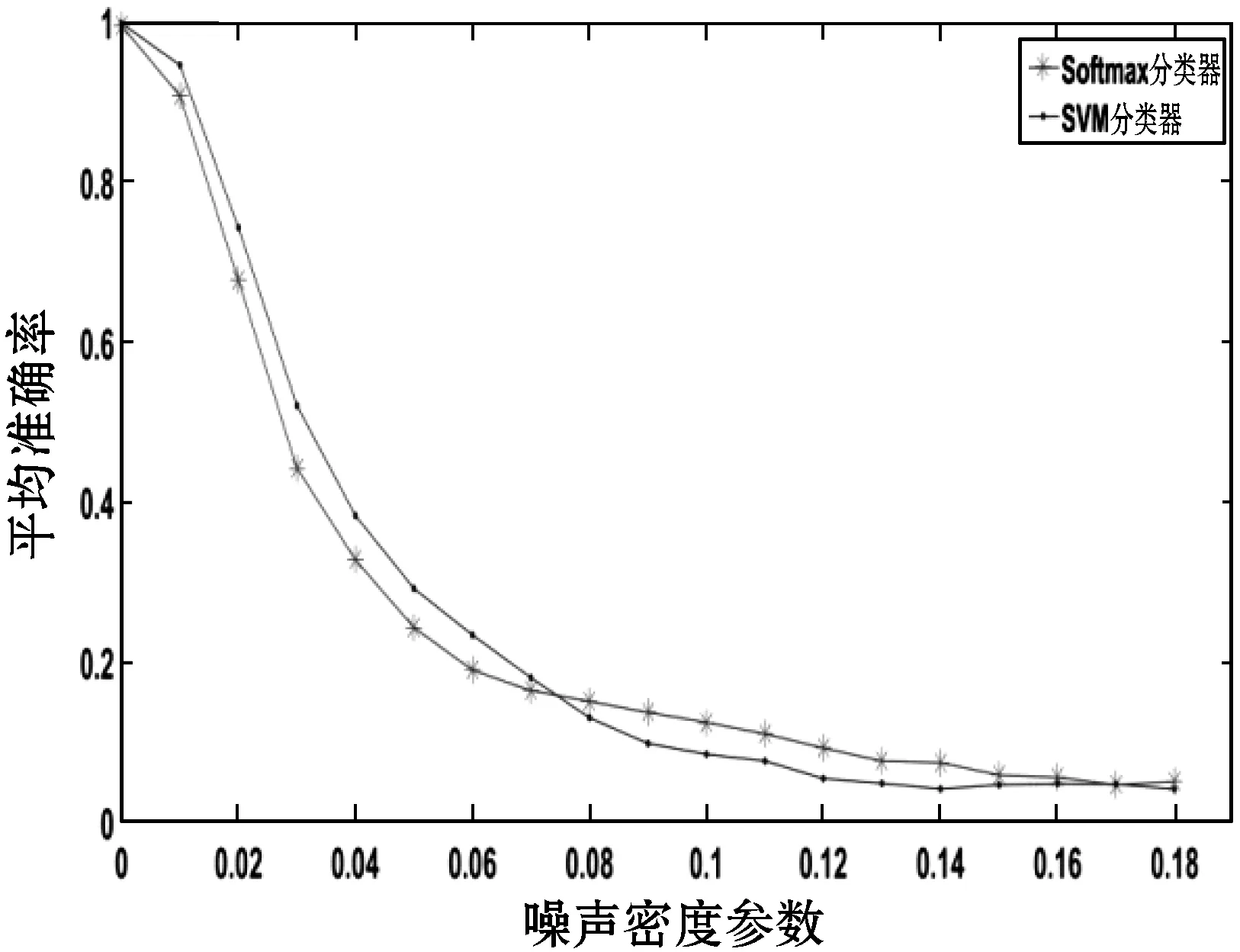
图7 分类器平均准确率按噪声密度梯度变化示意图
3.2 分析与讨论
(1) 在奶牛个体识别方面,本研究方法的准确率有所提升,与部分文献中的研究方法和准确率对比如表2所示。
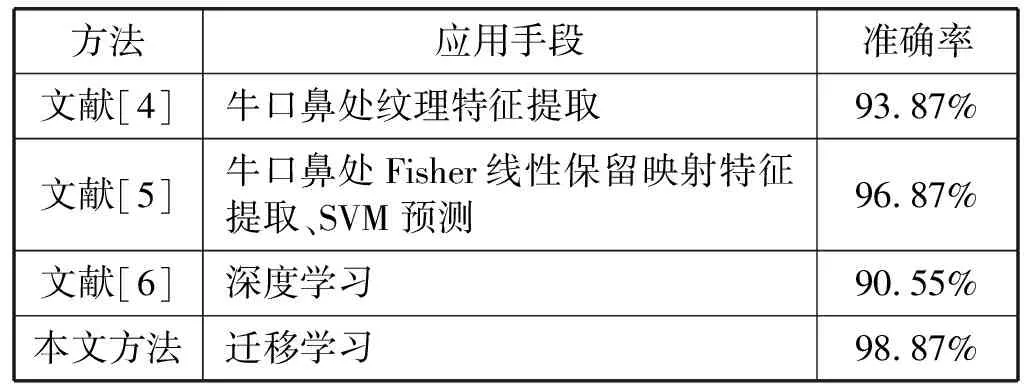
表2 方法准确率对比
与参考文献[4]所提出的基于牛口鼻纹理特征提取方法相比,识别率提高了5.04%,较参考文献[5]所提出的基于FLPP的方法提高了2.04%,表明该方法可以取得优于利用口鼻特征的传统识别方法。对比文献[6]中使用了21 730幅图像识别30头奶牛,识别率为90.55%,而本研究方法使用10 500幅图像识别35头奶牛,识别率为98.91%,是因为在深度网络的选取和训练方法上,本方法利用迁移学习训练深度网络,可以在样本数量较少的条件下获得较高准确率,识别率提升了8.36%,表明本研究所使用的深度学习网络可以较好地改善奶牛个体识别的效果。
(2) 在使用高斯混合模型建模时,是对每个像素点建立多个高斯模型,算法的计算量较大,一段10 s视频建模需要169.73 s,不利于实时处理。对于光照突变产生的前景模型中有大面积、数量多的噪声区域,影响连通域的截取。如图8所示,噪声区域大小与奶牛个体区域大小相似,会造成前景目标的误提取。

图8 前景错误提取示意图
(3) 由于训练集和测试集样本选择的随机性,每一个经过训练的网络识别率会有差异,样本数据不够充足也是使得网络识别率波动的原因。针对实验情况,在加入噪声检验的环节,Softmax分类器具有更好的抗噪能力,SVM分类器识别低噪声图片的准确率较高。
4 结 语
本文基于高斯混合模型的背景建模法检测奶牛运动的模糊区域,利用最大像素面积规定目标区域占比的方式可以有效清除噪声区域和干扰区域,从而定位和跟踪视频帧序列图像中的奶牛个体。
对已经训练好的深度学习网络进行迁移学习,微调网络结构,将全连接层‘fc8’的输出节点由1 000改为35,使用样本库中的10 500幅图像训练深度网络,结果表明,网络代价函数收敛至0.002 4,训练集样本的准确率收敛至100%,测试集样本的识别率为98.91%。而利用‘fc7’层的输出值训练的SVM分类器准确率为98.87%。
经过加噪声图像的实验,表明由Softmax分类器组成的网络抗噪能力更好,SVM分类器识别低噪声奶牛个体图像的准确率较高。
