视频人脸图像质量评估及其在课堂点名系统中的应用
2018-10-24方冠男胡骞鹤方书雅刘守印
方冠男 胡骞鹤 方书雅 刘守印
(华中师范大学物理科学与技术学院 湖北 武汉 430079)
0 引 言
大学生课堂考勤制度作为校园制度文化建设的重要环节,其所实施的效果将直接影响着学校的规范管理和人才培养质量[1]。上课点名的目的是统计学生人数,督促学生按时上课,进而提高教学质量[2]。传统的课堂考勤由任课教师通过花名册进行点名实现[3],但这种传统的课堂考勤方式通常会占用很多课堂时间,降低了课堂教学质量[4]。
当然,近年来指纹签到、虹膜识别等手段也相继出现并被应用,但是考虑到人脸信息特征相比于指纹、虹膜等生物特征,更具有易于获得、直观友好、易于区分等优点,因此本文选用人脸特征作为识别对象。
目前,人脸检测的主流方式包含两大类别:基于统计模型的方法与基于深度学习的方法。基于统计的人脸检测方法有:支持向量机、haar[5-6]分类器、隐马尔可夫模型HMM(Hidden Markov Models)[7];支持向量机SVM(Support Vector Machine)的方法[8-9]由于它基于结构风险最小化原理,因而表现出很多优良的性能。但使用SVM方法训练需要大量的存储空间,并且训练速度很慢。Nefian等[10]利用隐马尔可夫模型,这种方法鲁棒性较好,适用于对不同角度和不同光照条件的人脸识别。haar分类器,实现了实时人脸检测。缺点是当人脸在非约束环境下,该算法检测效果极差。基于深度学习的人脸检测在非约束环境下性能远胜于上述检测方法,目前常用的有Cascade-CNN[11]与MTCNN级联式神经网络的方法[12]等。
人脸识别技术的主要工作是分析人脸图像并提取特征信息,将特征信息与存储在人脸库中的信息进行比较,得到最终的识别结果。早期由Turk和Pentland首次提出“特征脸”方法[13-14]是人脸识别的里程碑,但这种方法的识别效果过度依赖特征定位算法的准确性,实用难度较大。随后Brunelli和Poggio[15]通过实验发现模板匹配的方法优于基于特征的方法,其优点在于光照不变性,但其算法不能摒除人脸面部表情变化的影响。Belhumeur等[16]提出的Fisherface人脸识别方法首先采用主成分分析PCA对图像表观特征进行降维,然后根据降维特征计算与目标特征的欧氏距离以辨别身份。另一种弹性图匹配技术提取人脸Jet特征[17](Gabor变换12特征),得到输入图像的属性图。然而,这些方法对光线、年龄、表情等条件变化较为敏感,当某些条件发生变化时,识别效果并不理想。深度学习[19]在人脸特征提取方面取得了巨大成就,减弱了外部因素的影响,提高了人脸识别的可靠性,从而促进了人脸识别技术的实用化。
针对人脸识别在课堂点名的应用,文献[2]提出了基于Android移动平台的课堂人脸识别系统,通过haar人脸检测方法与VGG人脸特征提取网络方法对手机摄像机采集到的学生人脸进行身份识别。但由于该系统拍摄区域有限,并未起到教室点名的作用。文献[19]提出了一种结合AdaBoost的人脸检测算法和主成分分析PCA算法的课堂人脸识别系统,但PCA算法对光线、年龄、表情等条件较为敏感,不能保证提取到的人脸特征信息的一致性,识别效果不佳。
从已有文献资料看,大部分论文虽然能在实验环境下取得较好的效果,但并未考虑到实际课堂环境中的问题:1)由于摄像机设置在教室前方,因为不同座位与摄像机的相对位置不同,造成课堂后排人脸尺寸过小,人脸图像质量不能满足识别的要求。2)在摄像机所获取的视频中,被采集的人脸大多处于非约束状态,人脸区域图像常常呈现像素低、运动模糊不清和姿态偏差较大的问题。
针对上述的第一个问题,本文通过PTZ(平移(Pan)、倾斜(Tilt)、变焦(Zoom)的缩写)摄像机预置巡航功能对教室中的每一个座位设置巡航点,通过此方式完成了对单个学生目标图像的采集,保证了人脸尺寸的一致性。
本文在基于人脸识别的课堂点名系统中融合了图像质量评估方法解决了上述的第二个问题。图像质量客观评价方法可分为全参考FR、部分参考RR和无参考NR。
全参考评价需要选择一副理想图像作为参考对象,与待评价图像进行对比得出待参考图像的图像质量,由于该理想图像难以选择,不适用于本文的应用场景。半参考评价依赖于理想图像的部分特征,同全参考评价图像一样需提供一幅“理想图像”的部分信息做参考,同样不适用于本文的应用场景。因此,完全脱离对理想参考图像依赖的无参考质量评价方法是本文解决问题的关键。
传统的无参考评价方法一般都是基于图像的统计特性(均值、标准差、平均梯度等)进行图像评价,然而影像图像失真的因素往往不止一个,图像的统计特性可能无法系统地表达多种失真因素。所以本文使用的图像质量评估方法采用深度卷积神经网络模型对图像的失真特征提取,并在文献[20]的基础上进一步改进,经测试,模型性能得到了进一步提升,能有效地检测并舍弃图像质量较差的人脸区域图像。
通过在基于视频流人脸识别的课堂点名系统应用人脸图像质量评估方法,不仅提升了人脸识别的准确率,同时也提升了点名效率,为实现好的课堂质量奠定了基础。
1 系统总体设计
本文是一种基于视频流的人脸识别课堂点名系统。系统整体设计框图如图1所示,其主要由摄像机与服务端两部分组成。
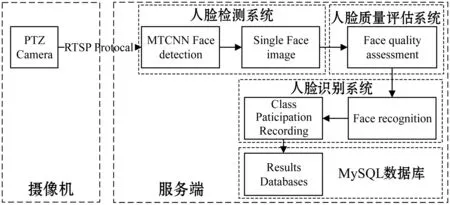
图1 系统整体设计框图
摄像机的主要功能是收集课堂上的实时视频流,将视频流通过RTSP协议传给服务端。
服务端主要由人脸检测系统、人脸质量评估系统、人脸识别系统和MySQL数据库四部分组成。本文采用MTCNN级联式神经网络进行人脸检测,然后将检测的单人脸区域图像输入到人脸质量评估方法中进行分类,把图像质量符合识别要求的人脸区域图像通过FaceNet[21]人脸特征提取网络进行高维特征提取;最后通过SVC分类器[22]对学生人脸进行识别。对图像质量达不到要求的人脸图像进行舍弃,直到获取合格的人脸图像,从而完成教室全部学生的识别。人脸识别完成后,对学生出勤状况进行登记,并将信息存入数据库。数据库中存储有根据各班级学生人脸预训练完成的SVC分类器、学生信息及学生签到情况。
1.1 人脸检测和人脸识别
文献[23]使用Viola jones级联式人脸检测器,而MTCNN是该级联式结构与深度卷积神经网络的结合。Viola jones级联式人脸检测器主要通过Haar特征作为分类依据,但其特征对角度极为敏感,当人脸角度偏移较大时,将无法检测到人脸。而基于深度学习的MTCNN人脸检测器是通过WiderFace数据集和FDDB数据集训练而来,并在其验证集模型上达到了95%的准确率。MTCNN通过深度卷积神经网络提取的特征对自然环境中的光线、角度和人脸表情都具有较好的鲁棒性,因此本文选择采用基于深度学习的MTCNN级联式神经网络人脸检测方法。MTCNN采用三级网络结构组成(P-Net,R-Net,O-Net),如图2所示。P-Net网络主要获得人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。R-Net网络依然通过边界框回归和NMS来进一步筛选false-positive区域。最后使用O-Net输出最终的人脸框和特征点位置。

图2 MTCNN的级联网络结构图
文献[23]中使用了基于稀疏表示的人脸特征提取方法,但其方法提取的人脸特征对于人脸表情变化、姿态角度变化较为敏感,将其应用于课堂环境下,提取的人脸特征一致性较差。同时该方法也会给后续基于学生社交关系推理的人脸识别工作带来一定影响。
最近深度学习在人脸识别领域逐渐崭露头角,其方法大多已经克服了自然客观因素的影响,其中FaceNet[20]模型在人脸识别方面中取得了优秀效果,因此本文借用了FaceNet网络模型结构进行人脸特征的提取。原始的FaceNet模型结构主要由inception深度卷积神经网络结构与tripleLet loss损失函数组成。但在2016年,Szegedy等[24]结合了resnet以及inception,提出了inception-resnet模型,该模型进一步降低了在ImageNet分类任务中top-1以及top-5的错误率,因此本文选择inception-resnet-v1模型作为深度卷积神经网络结构,其模型结构如图3所示。

图3 inception-resnet-v1模型结构图
在模型训练方面,Wen等[25]提出使用softmax loss和central loss作为损失函数和训练模型,其方法可以得到更好的人脸特征提取模型。其中,softmax loss定义如下:
(1)
式中:xi∈d为提取的表征属于yi类的第i维特征,特征维度为d;W∈d×n表示最后的全连层的网络参数,WJ∈d则表示参数的第j列;b∈n为偏置项。m为每批次里训练样本的个数;n为分类中类的个数。
Central loss可以减小被提取的特征在类间的距离,Central loss的定义如下:
(2)
式中:cyi∈d表示属于yi类的特征的中心。cyi在每批训练需要使用整个数据集时更新计算,计算量过大。在训练时,只更新当前用于训练的该批数据所涉及的类中心。最后损失函数为:
(3)
因子λ用以平衡Ls和Lc。本文通过式(3)作为损失函数进行训练,由此可得更为一致的人脸特征。而更改后的网络模型结构如图4所示。

图4 更改后的FaceNet网络模型结构图
在本文中,首先将使用inception-Resnet-v1模型结构与softmax loss和center loss作为损失函数相结合的方法在LFW数据集[26]上训练得到的预训练模型对单张人脸进行特征提取。然后将提取的128维特征作为输入,将其作为SVC分类器的训练集,对SVC分类器进行有监督训练。最后将SVC分类器模型存入数据库。当进行班级点名时,本文通过预训练模型提取人脸图像的128维特征,然后将特征矩阵输入至预训练的SVC分类器,即可得到最终的识别结果。
1.2 人脸图像质量评估方法
文献[23]中提到在课堂环境下拍摄的面部照片大小不一、分辨率不同,甚至还会严重扭曲。因此,为了避免恶劣环境对人脸图像的影响,其提出了基于地理位置推理式的人脸识别方法。该方法有较强的创新意识,但仍旧不能完全摆脱因图像失真造成准确率下降的问题。
因此本文采用PTZ摄像机的预置位方式,解决了课堂后排人脸图像尺寸过小的问题。实验结果如图5所示。

(a) 全景帧

(b) 调整至预置位后的区域帧图5 实验结果
图5(a)为覆盖了课堂全场景视频帧,可见后排人脸尺寸偏小,人脸辨识度极低。(b)为摄像机调整至预置位,变焦放大后的图像结果,由图中可看出人脸细节丰满,辨识度较高。
虽然基于深度学习的人脸特征提取网络解决了光照、表情、姿态等大部分难题,但在实际的课堂环境下,仍有如下问题:在摄像机所获取的视频流中,被采集的单人脸大多处于非约束状态,单人脸区域图像常常呈现像素低、模糊不清和姿态偏差较大的特点。如图6所示为视频中通过人脸检测方法提取的人脸区域图像。若直接使用这些提取的人脸图像进行人脸识别,会对人脸识别系统的准确率造成较大影响,无法保证系统的正确性和鲁棒性。

图6 非约束状态人脸图
我们将以上这类问题归结为人脸区域图像质量评估问题,那么如何对视频关键帧中的人脸区域图像质量进行量化评估,便成为了本文主要研究内容之一。本文借鉴了图像质量评估领域的无参考图像质量评估方法,根据失真图像的自身特征来估计图像质量。
本文选择了VGG19网络体系结构[27]作为图像特征提取器,但在实践中,由于训练CNN神经网络需要足够大的数据集,而通常这些数据很难得到,完整训练大数据集对硬件要求也颇高,因此很少有人从零开始训练整个CNN神经网络。相反,采用在不同的开源大型数据集(例如ImageNet[28])上的预训练模型,并将其作为特征提取器或用作进一步学习过程的初始化(即转移学习,也称为微调[29])是常见的。因此我们将在ImageNet数据集上预训练后得到的VGG19模型的最后一个全连接层用随机值初始化的方法进行了权值替换,新的全连接层是从零开始训练的,其他层的权重是通过反向传播算法[30]和可用的LFW-IQA图像质量评估数据集来进行更新的,以此方法完成了对图像质量评估模型的微调。在这个体系之上,最后从CNN提取出的图像特征到MOS(平均主观质量分数)的映射函数将由带有线性内核的SVR(支持向量机回归算法)学习得到。
人脸图像质量评估结构如图7所示。图像将通过以上预训练的CNN模型与SVR模型,得到平均主观质量分数(即MOS)。根据5个MOS分数段落,可将人脸图像质量分为5个等级:差、较差、一般、好、优质。

图7 人脸图像质量评估结构图
通过该评估方法得到MOS分数,本文将MOS分数小于60的人脸区域舍弃,即合理地从视频流中选取符合识别质量要求的人脸区域图像。
由图8所示结果可明显看出,从左至右图像质量依次对应上述的5个等级,差[0~20]、较差[20~40]、一般[40~60]、好[60~80]、优质[80~100]。

图8 人脸质量评估结果
2 实验与分析
2.1 图像数据集介绍
本文的学生人脸数据集是通过摄像机获取2个班的学生(分别为15人和21人)个体图像,并对图像进行人脸检测和人脸对齐以获取单人脸区域图像。一共采集了36名学生的3 600张单人脸区域图像(每名学生100张)作为SVC分类器的数据集,部分数据集如图9所示。将数据集随机分为80%训练集和20%测试集。为了检验训练集样本数量对训练出的SVC分类器性能的影响,依次增大训练集的图像数量(从5~80,每次增加5张图像)训练出不同的SVC分类器并在同一测试集上验证准确度。

图9 部分数据集示例
实验结果如图10所示,横坐标代表训练SVC分类器所使用的图像样本数量,纵坐标代表SVC分类器在测试集上的平均准确率。(例:通过每人5张图像作为训练集训练的分类器在测试集上的平均准确率在0.86左右。通过每人80张图像作为训练集训练的分类器在测试集上的平均准确率在0.98左右)。因此本文系统中使用的预训练SVC分类器是通过每名学生80张图像训练完成的。
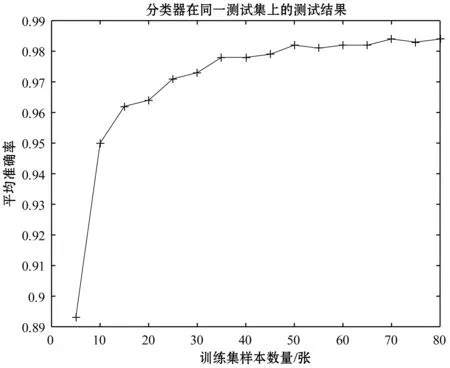
图10 分类器在同一测试集上的测试结果
2.2 图像质量评估模型性能评估结果
为了验证不同的人脸图像质量对人脸识别系统准确率的影响。本文选择了36个学生在视频流中出现的归一化后的单人脸区域图像作为测试集,并将此测试集通过本文的人脸质量评估系统评价得出MOS(平均主观质量分数)。本文将MOS分数大于60的作为人脸图像质量较高的一类,即测试集H;其余的作为人脸图像质量较差的一类,即测试集L。每个测试集中都含有36个学生个体的20张单人脸区域图像,测试结果如图11所示。

图11 不同质量图像的准确度
由图11的测试结果可以看出,人脸识别系统对于单人脸区域图像质量高的图像的准确率远远高于人脸图像质量低的准确率。由此可以得出,人脸图像的质量对整个人脸识别系统有较大影响。
通过文献[31-32]的数据集对本文提出的图像质量评估模型进行评估。其包含1 162张500×500像素的图像,这些图像受到各种真实失真和真实人为因素的影响,如低光噪声和模糊、运动引起的模糊、曝光过度和曝光不足、压缩错误等。该图像数据库已经收集了8 100位专业人士的超过350 000的意见分数。每幅图像的主观意见分数(MOS)是通过平均各科目的个体评分计算得到的,并将其作为真实的图像质量分数。本文比较了一些领先的无参考图像质量评估方法,由于大多数算法都是基于机器学习的训练过程,因此在所有实验中,我们将数据集随机分为80%训练集和20%测试集,使用训练数据对上述在ImageNet数据集上预训练完成的模型进行微调,并在测试集上验证它的性能。为了降低由于数据分割造成的偏差,数据集将随机分割重复10次,对于每次重复,计算预测和实际质量得分之间的皮尔逊线性相关系数(LCC)和斯皮尔曼秩相关系数(SROCC),选择10次重复试验的中位数作为最终结果。测试结果如表1所示,可以看出通过微调后的预训练模型(BIQVGG)能够将LCC和SROCC分别提高0.05和0.09。
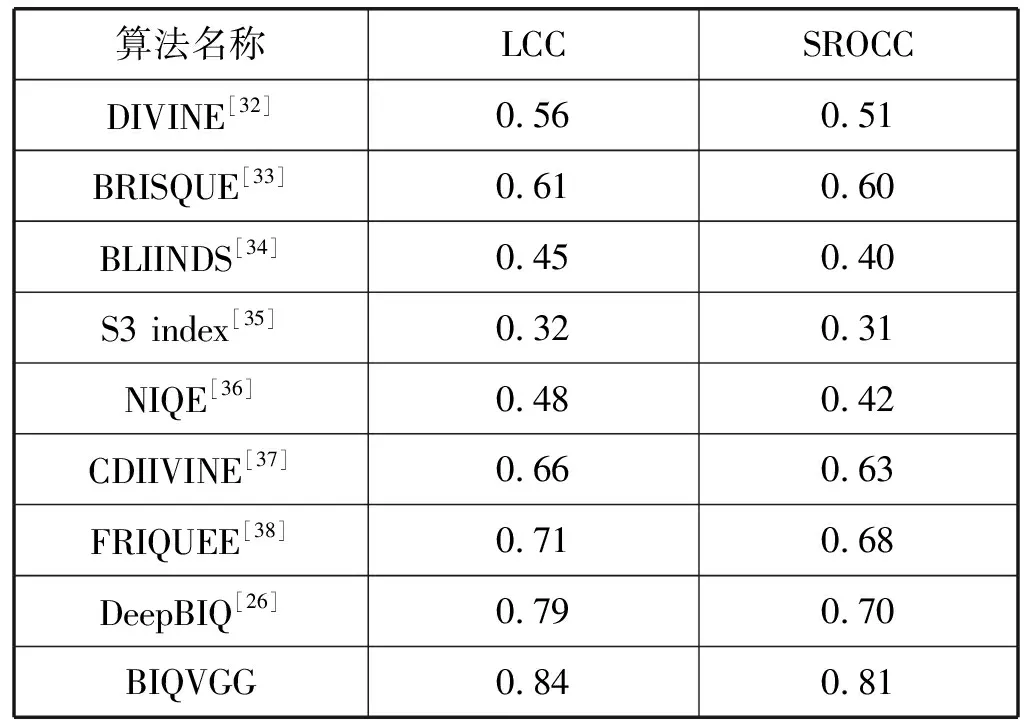
表1 各算法在LFW IQ Chall.DB.数据集中10次随机分组的LCC和SROCC中位数
通过本模型预测的MOS图像质量分数与真实的MOS图像质量分数存在11%的均方根误差(RMSE)。
2.3 人脸识别结果
本文分别在两个班级(班级A和班级B)进行了实验,对比了通过人脸质量评估与未通过人脸质量评估情况下的人脸识别准确率,结果分别如表2、表3所示。
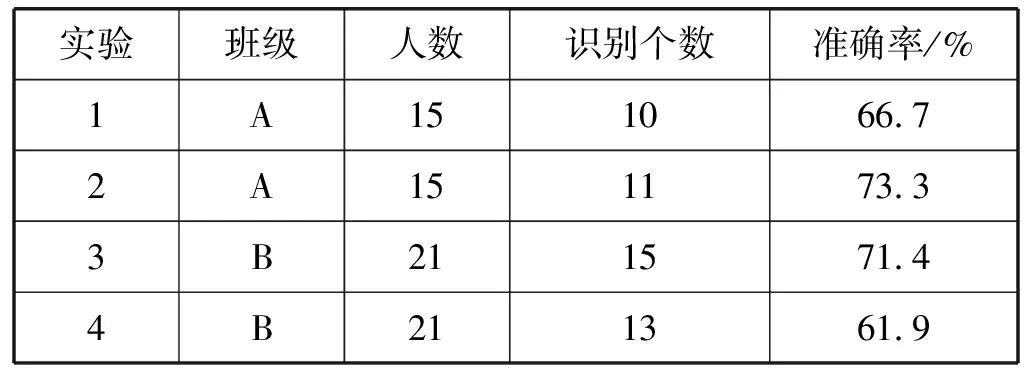
表2 未通过人脸质量评估情况下人脸识别准确率

表3 通过人脸质量评估情况下人脸识别准确率
从上述分析可知,在课堂环境下,如未通过人脸质量评估进行人脸识别,准确率大多在70%左右,准确率较低,不能满足实用级别要求。在引入了人脸质量评估环节后,准确率可以达到90%左右。
3 结 语
本文提出一种基于视频流的人脸自动识别课堂点名系统,结合机器视觉与人工智能技术改善了传统课堂点名方式,保证了上课时间,提升了上课效率,为学校未来智慧课堂建设提供了新的思路。通过引入人脸质量评估方法解决了实际课堂环境下所出现的问题。通过在实际课堂环境下的实验表明本系统在课堂环境下有较高的实用价值与鲁棒性。
该系统不仅为课堂考勤管理提供了一种智能化手段,同时可以将学生课堂的考勤情况与该课的学业成绩联系起来,有效地分析学生的课堂考勤情况与学业成绩的关系。
