基于TextRank的文本情感摘要提取方法
2018-10-24杨玉珍
荀 静 杨玉珍
1(西安工业大学图书馆 陕西 西安 710021)2(荷泽学院计算机学院 山东 荷泽 274015)
0 引 言
文本情感摘要技术是文本情感分析在自动摘要技术领域的应用。该技术是从给定的评论文本中提取带有情感信息并且能够表达文章主旨的内容,有助于用户快速有效地把握评论文本的全局情感倾向,获取主题信息。
近年来,针对汉语特点的中文文本自动摘要技术取得大量研究成果。文献[1]将文本中句子的出现看成一个随机变量,应用主题模型与信息熵抽取中文文本的摘要。文献[2]提出了一种基于云计算的分布式多文本自动摘要技术,通过MapReduce框架抽取文本的主题句。文献[3]采用基于回归的有监督技术对提取的熵和相关度两组特征进行权衡,进而提取文本的摘要。文献[4]将文本情感摘要看成是一个二元分类问题,利用有监督学习方法抽取能够代表评论广泛意见的句子构建文本情感摘要。文献[3-4]的两种方法属于有监督的自动摘要技术,准确度较高,但易受训练语料的影响。
图排序算法是当前主流的无监督方法之一,能够充分考虑文本图的全局信息,不需要人工标注训练集,目前已被广泛应用到信息检索、关键词提取和自动文摘等领域[5]。熊娇等[6]融合词项权重信息和文本信息,提出了一种基于词项-句子-文本的三层图模型,进行多文本自动摘要提取。余珊珊等[7]结合篇章结构和句子的上下文信息提出基于改进的TextRank自动摘要提取方法,但未考虑情感信息。林莉媛等[8]针对同一产品的多个评论,提出一种基于情感信息的PageRank算法。通过构建一个基于主题和情感的双层图模型来抽取最有代表性的句子作为某个产品评论的情感摘要。刘志明等[9]通过主题收敛,融合句子语义相似度和情感相似度,提出一种基于主题的SE-TextRank情感摘要方法。王玮等[10]在LexRank算法中加入情感信息,提出融合句子情感和主题相似性的中文新闻文本情感摘要方法。这些方法在生成文本的情感摘要时引入了情感信息,能够有效地识别文本中的情感关键句,但未考虑句子的情感强度和位置、线索词、句式、长度等句子自身特征对生成情感摘要的影响。
基于TextRank算法,综合考虑主题信息、情感信息和句子自身特征等影响因素,本文提出一种融合多特征的文本情感摘要提取方法。实验结果表明,该方法能够有效地提取文本中的情感主题句,实现评论文本的浓缩和提炼。
1 TextRank算法
TextRank算法来源于PageRank,是一种基于图排序的文本处理模型[11]。它的基本思想是将文本中的句子看成图中的一个节点,若两个句子之间存在相似性,则认为对应的两个节点之间有一条无向有权边,权值是句子间的相似度。通过TextRank算法计算得到的权重排序靠前的若干句子可作为文本的摘要。
给定一篇文本D,对文本进行分句后得到句子集合D={s1,s2,…,sN},1≤i≤N。基于TextRank模型,构建句子的无向加权网络图G=(V,E,W),其中:V是节点的集合,E是节点间各个边的非空有限集合,W是各边上权重的集合。
图G节点间的概率转移矩阵SDn×n是一个n×n的对称相似度矩阵,对角线上元素的取值为1。
(1)
根据构建的网络图G和SDn×n可迭代计算每个节点的权重,具体公式如下:
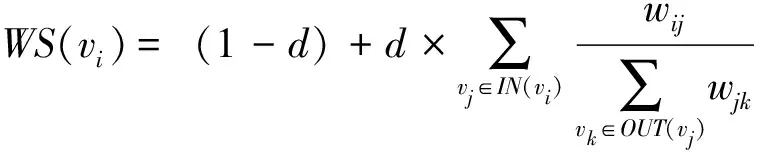
(2)
式中:d为阻尼系数,一般设定为0.85;对于一个节点vi,WS(vi)代表节点的权重,IN(vi)代表指向vi的节点集合,OUT(vi)代表vi指向的其他节点集合,WS(vj)表示上次迭代后节点vj的权重,wij表示节点vi和节点vj间的相似度值。
计算节点的权重首次迭代时要用到节点初始权重,即自身的权重。由于经过多次迭代后,每个节点的权重趋于稳定,因此节点的最终权重与初始权重无关,设定每个节点自身权重为1/|V|,即B0=(1/|V|,…,1/|V|)T,经过多次迭代计算后可得到收敛结果:
Bi=SDn×n·Bi-1
(3)
当两次迭代的结果Bi和Bi-1取值差别非常小并接近于零时计算结束,得到包含各个节点权重值的向量,然后可根据权重值的大小进行排序,获取节点相应排名。
2 文本网络图构造
2.1 特征选择
文本的情感摘要不仅包含文本的全局情感信息,还要涵盖文本的主题内容,因此本文综合提取文本的主题特征词和情感特征词组成文本最终的特征向量。首先将输入的文本划分为句子,得到句子集合,并对文本中的句子进行结构标记,例如如果一个句子的结构标记值为[1,2,6],则表示该句子为第1自然段的第2个句子,第1自然段共包含6个句子;其次对每个句子进行切词处理,去除停用词和敏感词,归并同义词和近义词;最后对预处理后的特征词条进行判定,若该词为情感词,则直接划分到情感特征词类别中,否则,通过IF-IDF方法评估特征词条,将排名靠前的一定数量的特征词划分到主题特征词类别中。文本特征向量提取流程如图1所示。
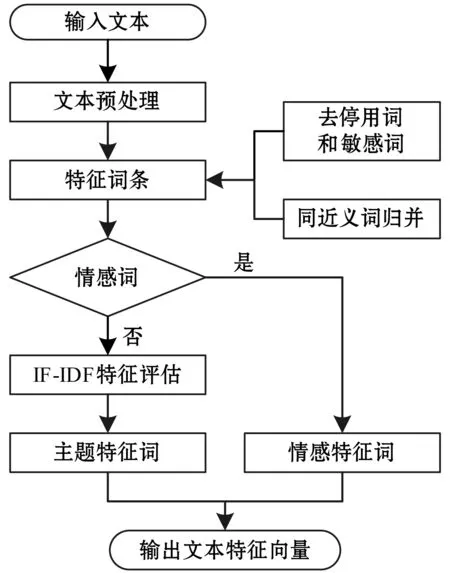
图1 文本特征向量提取流程图
根据图1处理结果,可以得到包含p个情感特征词和q个主题特征词的特征向量:
1) 文本D的特征向量,记为Dkey={key1:tf1,key2:tf2,…,keyp:tfp,…,keyq:tfq},1≤i≤p+q。其中:p+q为文本中所有特征词的数量;tfi为特征词keyi在文本D中出现的词频。
2) 句子sj的特征向量,记为sjkey={keyi1:stfi1,keyi2:stfi2,…,keyip:stfip,…,keyiq:stfiq},1≤i≤p+q。如果特征词keyi在句子sj中出现,则stfi为词频,否则取值为0。
2.2 TextRank文本网络图
通过研究分析发现,在TextRank网络图中,迭代计算的结果主要受两个节点间权重的影响,而节点间权重是通过计算句子间相似度得到的,因此,如何计算句子间相似度成为摘要提取的关键。根据特征选择结果,本文分别在主题层面和情感层面上计算句子间的相似度,综合句子主题和情感两者间的相似度作为句子间的权重,计算公式如下:
Sim(si,sj)=μ×Simt(si,sj)+ω×Simr(si,sj)
(4)
式中:μ、ω是调节参数,并且μ+ω=1,通过多次测试确定最后的取值。Simr(si,sj)代表句子间基于情感的相似度,Simt(si,sj)代表句子间基于主题的相似度。
1) 基于情感的相似度 在文本情感分析研究中,句子的情感信息是通过其包含的情感词表达的[12]。本文采用《知网》词语语义相似度计算方法来计算选择出情感特征词的相似度,进而得到句子间的情感相似度[13]。《知网》中的词语相似度是通过词语的义原相似度体现的,对两个情感词w1和w2,假定w1含有n个义原X1,X2,…,Xn,w2含有m个义原Y1,Y2,…,Ym,则w1和w2的相似度如下:
(5)
式中:Sim(Xi,Yj)代表两个义原间的相似度。对于句子sp={w1,w2,…,wa}和sq={w1,w2,…,wb},sp中包含a个情感词,sq中包含b个情感词。对两个句子中的情感词两两进行相似度计算,将计算过程中获得的最大值作为本词汇的相似度权重[9]。参照文献[9]得到句子间的情感相似度,计算公式如下:
(6)
2) 基于主题的相似度 句子基于主题的相似度通过计算特征向量中主题特征词的相似度来实现,本文采用余弦相似度方法,参照文献[7],计算公式如下:
(7)
式中:h=|Dkey|为句子特征向量中主题特征词的数量。
根据得到的句子间相似度构建一个无向加权TextRank网络图如下:以文本D中的句子sj为节点,句子间相似关系为边,相似度为边的权重,其中各节点的权重计算如下:
(8)
每个节点的初始权重设定为1/|D|,即B0=(1/|D|,…,1/|D|)T,则经过多次迭代计算后可得到收敛结果:
Bi=SDn×n·Bi-1
(9)
计算结束后可得到包含各个节点权重值的向量Bi,然后可根据权重值的大小进行排序。按照句子权重大小抽取情感主题句,并结合在文中的顺序生成情感摘要。
3 融合多特征的TextRank文本情感摘要提取
3.1 情感特征
在传统的情感倾向分析中认为一个句子中包含的情感词数量越多,句子的情感倾向程度越大。本文在此基础上考虑了情感词的情感强度,通过情感词的极性强度值累加来确定句子的情感强度。鉴于当前没有统一标准的情感词典,本文首先将收集到的HowNet词典和大连理工大学词典合并去重;然后以小学反义词典为范本,添加情感分析COAE的领域情感词;最后和课题组已有的极性词典[13]合并去重,进而得到一个较为完善的情感词典。基于情感强度的句子权重调整系数为:
(10)
式中:emotion(wi,k)是句子si中第k个情感词wi,k的情感强度值;m是句子si中的情感词个数。
经计算可得到基于情感特征的句子权重调整系数转移矩阵TRh×1=[we(s1),we(s2),…,we(sh)]T,通过矩阵相乘Bi+1=Bi·TRh×1可对2.2节给出的句子最终权重进行调整。
3.2 句子自身特征
在提取摘要时,句子位置、线索词、句式和长度等自身特征对摘要的准确度也有一定的影响,因此本文通过句子自身特征对收敛后的句子权重进行调整。
1) 位置特征 专家研究结果表明,80%以上文本的主题句出现在段落首句或尾句。因此,段落首句或尾句应该被赋予更高的权重,而越靠近段首和段尾的句子其权重相应地越高。基于位置的句子权重调整系数为:
(11)
式中:j为段落中句子所在的位置;H为段落中句子si的总数,并且j={1,2,…,H}。
2) 线索词特征 句子是由词组成的序列,而句子中包含的线索词对作者表达的情感和观点具有很大的提示作用。比如,指示性词语,“因此”、“应该”等;总结性词语,“综上所述”、“总而言之”等;第一人称代词,“我认为”、“我建议”等。如果一个句子包含一个或多个线索词,则该句子成为情感主题句的可能性越大。
基于线索词的调整规则为:若句子中包含线索词,则将该句子权重增加1倍;否则,句子权重保持不变。
3) 句式特征 句子的类型不同,对摘要提取的影响效果也不同。按照不同的表达方式,句子可分为4种类型:陈述句、疑问句、感叹句和祈使句。疑问句和感叹句常被用来表达主观情感信息,因此有更大的可能成为摘要句。
基于句式的调整规则为:若句子为疑问句或感叹句,则将该句子权重增加1倍;若句子为陈述句,则将该句子权重增加0.5倍;其他情况下,句子权重保持不变。
4) 长度特征 为了避免文本最终提取的情感摘要受句子过短或过长的影响,在此对文本中句子长度做归一化处理,并过滤掉少于5个特征词的句子。基于长度的句子权重调整系数为:
(12)
式中:L为句子的长度,length为文本中句子的平均长度。
3.3 情感摘要提取方法
融合多特征的TextRank文本情感摘要提取方法可分以下4个部分:文本预处理和特征选择、TextRank网络图构建、句子权重修正和摘要句提取。
1) 文本预处理和特征选择 每个句子进行切词处理,去除停用词,归并同义词。
2) TextRank网络图构建 通过TextRank算法构建文本网络图,然后进行迭代计算,直至收敛,输出句子权重。
3) 句子权重修正 融合句子情感强度、位置、线索词、句式和长度等特征,修正计算出的句子权重,得到句子的最终权重。
4) 摘要句提取 根据修正后得到的权重对句子进行排序,生成粗文摘,然后利用最大边缘相关(MRR)消除冗余算法依次提取摘要句。
4 实验设置与结果分析
4.1 实验数据及评价指标
本文的实验数据是从国内各大新闻网站中搜集的评论性的新闻报道。按照主题可分为文化、科技、时事、财经、体育等几类的文章,经过预处理后各选取500篇文本作为本文的实验语料,并人工抽取这些文本中的句子形成基准情感摘要。
本文利用ROUGE-1.5.5工具对最终摘要的结果进行评测,并使用ROUGE-1、ROUGE-2、ROUGE-W作为评价指标。其中,1与2代表1元和2元语法长度,ROUGE-1为候选摘要与基准摘要间的1元语法召回率,ROUGE-2为候选摘要与基准摘要间的2元语法召回率,ROUGE-W为最长加权公共子序列。
4.2 实验结果及分析
本文针对提出的融合多特征的TextRank情感摘要方法,共设计3组实验。首先,确定调节参数μ、ω的最优值;然后依次加入各个特征,查看情感摘要的效果;最后,对比不同方法下生成的情感摘要的结果。
4.2.1 调节参数设置(实验1)
本文首先假定TextRank图模型中节点的初始权重为1,然后通过设置不同的μ、ω的取值,观察评价指标的结果。分别测试μ为0.35、0.4、0.45、0.5、 0.55、0.6、 0.65、0.7、0.75时的评价值,相应的,ω=1-μ。实验结果如图2所示。
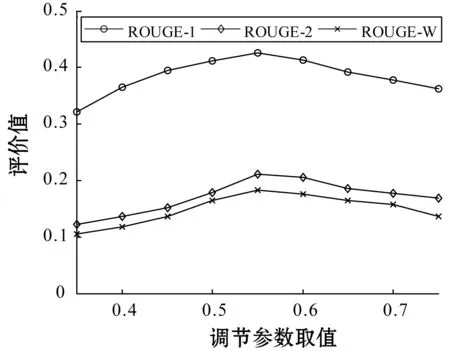
图2 评价值在调节参数μ不同取值下的变化趋势
从图2可以看出,当μ=0.55,ω=0.45时,三个评价值的取值最高。因此,取μ=0.55,ω=0.45进行后续实验。
4.2.2 各特征对情感摘要效果的影响(实验2)
为了比较各特征对摘要的影响效果,该实验分别加入每个特征,观察情感摘要的结果。具体结果如表1所示。
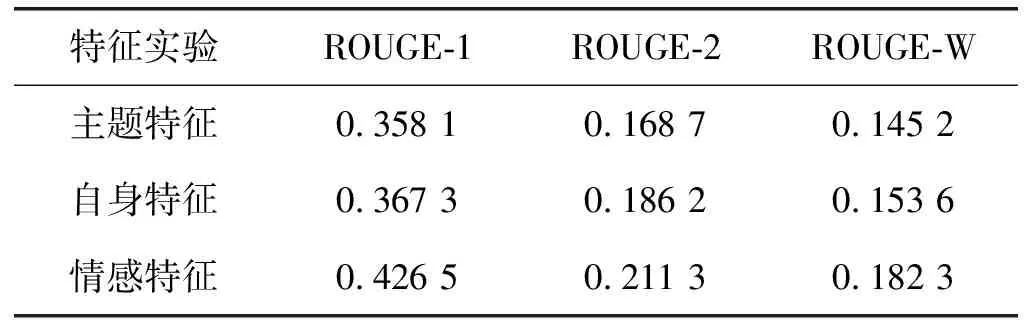
表1 特征影响效果实验
实验2首先利用主题信息提取摘要,然后加入自身特征,准确性得到提升,最后加入情感特征,准确性得到更显著的提升。可以看出,每一个特征对情感摘要都有不同程度的影响,是生成摘要的重要因素。
4.2.3 对比试验(实验3)
本文将TF-IDF方法、传统的TextRank方法和本文方法进行对比,以此验证本文方法的有效性。实验结果如表2所示。
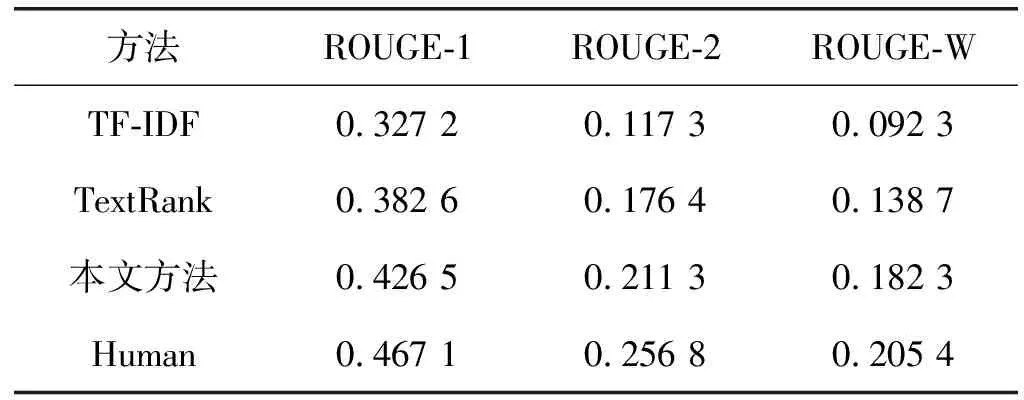
表2 对比实验
表2的统计结果表明,本文方法在ROUGE-1、ROUGE-2和ROUGE-W三个评价指标上均有明显提高。基于TF-IDF的方法只考虑了词频信息,相比其他方法效果最差。基于传统的TextRank方法考虑了文本的主题信息,效果优于IF-IDF方法。本文方法进一步考虑了文本的情感信息和句子的自身特征,效果更优于传统的TextRank方法。
5 结 语
情感摘要的生成是自然语言处理领域和文本情感倾向性分析领域的研究热点。本文的方法在传统的TextRank摘要抽取方法基础上充分考虑了主题信息、情感信息、句子位置、线索词、长度和句式等特征,有效地抽取评论文本的情感主题信息。下一步将尝试把上述研究应用到多文本情感摘要领域,同时继续完善中文情感词典,进一步提高摘要的准确率。
