基于Lasso和支持向量机的上市公司信用评价
2018-10-17滕树军刘丽平刘柏森
滕树军 刘丽平 刘柏森

摘要:随着经济的全球化,作为市场经济交易基础的公司信用研究,已趋于社会化、普遍化。信用关系或者债券关系已经成为一种非常基本的经济关系。而在公司交易规模不断壮大的同时,信用风险也随之而来。本文首先采用Lasso方法从可能影响上市公司信用评价的众多财务指标中挑选出现金比率、资产负债率、长期资本负债率、固定资产比率等17个重要影响因素,然后再运用支持向量机方法对上市公司信用评价进行预测。实际研究结果表明本文所提出的Lasso与SVM相结合的新方法的拟合预测效果要优于单纯SVM方法的预测效果。
关键词:Lasso;支持向量机;信用评价
中图分类号:F830.91 文献识别码:A 文章编号:1001-828X(2018)018-0022-03
一、引言及文献综述
随着经济的全球化,作为市场经济交易基础的公司信用问题,已日渐趋于社会化、普遍化。现代市场经济是建立在信用基础上的经济,从某种意义上说市场经济就是信用经济。在资本市场快速发展的过程中,上市公司在我国经济发展中起着重要作用,已经成为我国国民经济发展的中坚力量。截至2016年12月,我国沪市和深市上市公司总数量达到3025家,总市值达到508245亿元,与2016年我国GDP的比值为68%。上市公司是我国信贷市场中商业银行的主要授信主体,也是我国资本市场上股票和债券的主要融资主体。商业银行已经把信用风险列为经营管理中所面临风险中的首要风险,同样,作为资本市场上十分重要的融资主体,上市公司如果发生失信事件,将会在资本市场中产生更加剧烈与重大的影响。所以对上市公司进行信用评价,可以使投资主体能够更准确地评价被授信公司的信用状况,有效地减少投资者所面临的投资风险,从而做出准确的判断。
国外很早就对公司信用风险评定展开了研究,并将其研究结果广泛应用于银行、企业及投资机构等。从最开始的借助于专家的经验来评判公司信用情况,到20世纪70-80年代,发展到以公司财务指标为基础来进行公司信用风险的评定。Beaver(1967)将判别分析方法引入到信用风险分析中,美国学者Altman(1968)将一元判别模型扩展为多元判别模型。随着不断的研究,Altman、Haldeman和Narayanan(1977)将Z-score模型进行优化,最终建立了Zeta判别分析模型。亚洲金融风暴之后,全世界又兴起了打破旧的信用风险分析方法,随着计算机的快速发展,机器学习理论被广泛应用到企业风险评估当中,主要方法有神经网络、支持向量机(SVM)等。
国内对公司信用风险评价的研究要晚一些,应用的方法主要有Logistic回归、KMV与Logistic模型的结合、多元自适应回归样条(MARs)和支持向量机。胡安冉和孙云(2012)利用2010年股票市场上6家ST公司以及4家已經上市并正常运转的公司财务报表的数据为研究素材,建立了Logistic模型,评价了上市公司的信用风险,并验证了其模型的适用性,总体预测准确率为88%。梁琪(2005)运用主成分分析法与logistic回归分析相结合的方法,对我国沪深两市上市公司的经营失败进行了实证研究,结果表明该方法在模型解释和预测准确率等方面均优于简单的Logistic模型分析。孙森和王玲(201 4)利用KMV模型计算得到违约距离(DD),并将DD值与Z-score模型中的五个参数作为自变量引入Logit模型中,实现KMV模型与Logit模型的结合,得到了能够评估企业违约可能性的二元选择Logit模型,在沪市制造业违约可能性的评估中得到了较为理想的结果。彭颖(2012)在研究企业信用评估模型研究中,利用上市企业的财务数据,设计了信用分析的指标体系,利用多元自适应回归样条(MARs)方法对企业的信用状况建立信用评估模型,依据上市公司2008年的财务数据建立MARS模型,并与Logistic模型进行对比,发现MARS模型拟合精度及预测能力均强于Logistic模型。
近些年来,SVM方法已被广泛应用于上市公司财务信用评价预测方法研究中,石秀福(2008)利用高斯核函数的SVM建立上市公司财务风险评价模型,从上市公司13个主要财务资料中选出部分指标,建立了42种财务风险评价预测模型,并利用这42种模型对评估预测精度进行比较研究,说明了基于高斯核函数的SVM在上市公司进行财务风险评价预测的优越性。还有其它文献也利用SVM方法研究中国上市公司的风险,通过对上市公司的财务比率进行建模和仿真研究,发现SVM方法对所选取的样本具有很好的分类效果,在上市公司的风险预测方面具有很强的准确性和可行性。
虽然SVM方法比较适合处理具有非线性关系的小样本数据,但当解释变量较多时,SVM的预测精度不高,因而本文提出Lasso方法与SVM相结合的方法。首先利用Lasso方法对上市公司信用评价的影响因素进行变量选择,剔除对上市公司信用评价不显著的财务指标,从而实现降低数据维度的目的;然后利用支持向量机的非线性运算能力,完成对上市公司信用评价的拟合和预测。实际研究结果表明,这种新的Lasso-SVM方法的预测能力要高于直接运用SVM方法的预测能力,对于上市公司信用评价问题,有着较好的预测效果。
二、理论准备
1.基于Lasso方法的变量选择
变量选择主要是通过统计方法从繁多的变量中选出对响应变量有很大影响的解释变量,变量选择的结果的好坏严重地影响着所建模型的质量,进而对统计预测精度产生较大的影响。传统的变量选择方法有逐步回归法、AIC准则、BIC准则、准则等,其本质上是子集选择法,其特点是无序性和离散性,在选择的过程中,有一些变量被模型剔除,有一些变量被模型选择,当解释变量较多时,子集选择方法的方差通常较高,不能达到降低模型预测误差的目的。
Tibshirani(1996)于1996年给出了基于惩罚函数思想的Lass0方法,通过给模型参数增加范数的惩罚函数,对系数进行压缩。因为该模型是通过调整参数来选择变量,因此变量的收缩是连续的。该方法的特点是既通过参数估计来进行变量选择,又通过参数连续变化来调整变量连续收缩,自动地选择变量,因而被广泛应用于高维数据的回归分析中。
2.支持向量机方法
支持向量机是数据挖掘中的一项新技术,是借助于最优化方法来解决机器学习问题的新工具,在解决小样本、非线性及高维度模式识别中表现出许多优势。它的核心是引入该映射的思想与结构风险的概念,通过寻求结构化风险最小来提高学习机的泛化能力,实现经验风险和置信范围的最小化,从而在样本数量较少的情况下,仍能获得良好统计规律的目的,目前该方法已经广泛应用于经济、金融、工程等领域。
三、建模与实证分析
1.样本数据的选取与处理
本文选择上市公司财务指标来研究企业信用风险,并用被特殊标记(ST)的公司作为信用不佳的公司,未被标记sT的公司作为信用良好的公司。本文从国泰安数据库中搜集到的数据为2016年1月份至12月份我国沪市和深市中所有上市公司的财务指标数据,其中信用不佳的公司有130家,信用良好的公司有2895家。对于信用良好的公司,因为其公司数量非常多,而存在缺失值的观测相对较少,因此在对信用良好公司的数据集进行缺失值处理时,本文选择剔除存在缺失值的观测以保证数据的完整性;对于信用不佳的公司,因其数据量有限,本文在处理缺失值时,除删除无任何记录的公司外,其余缺失值选择用信用不佳的公司去除缺失值后的平均值来代替。经处理后的数据集有113家信用不佳的公司,有2664家信用良好的公司。为了保证数据的平衡性,本文按照1:1的比例随机抽选信用良好和信用不佳的上市公司,共选择226家公司,并从中随机选取了80家信用良好的公司与80家信用不佳的公司作为试验集,用于建立模型,剩下的33对公司作为测试集,用来检验模型效果。
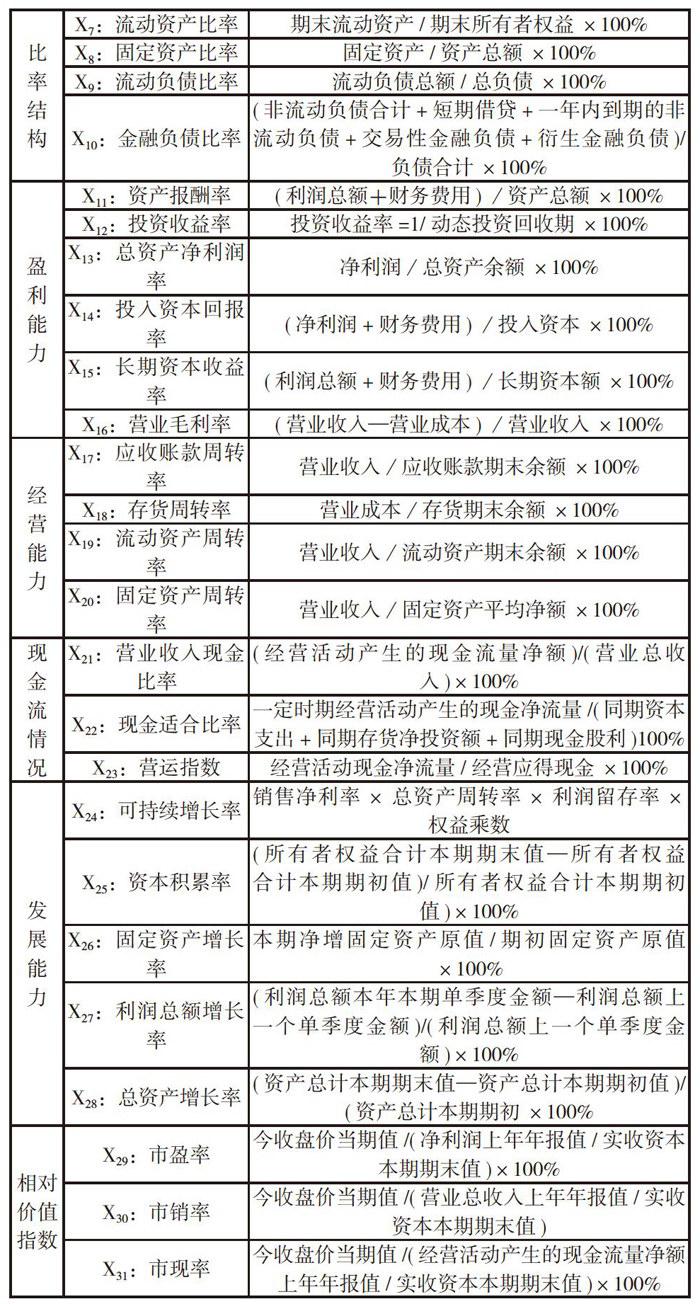
一般而言,企业财务状况与企业信用风险之间存在密切的联系,财务状况的每一个微小的变化都可能对公司产生影响。当公司财务状况良好时,其现金流量控制良好,资本运营通畅,这时公司信用风险相对较小,按时还款的可能性较大。反过来,如果公司财务状况不佳,企业运作、经营都处于不佳状态,很可能出现失信行为。本文研究企业信用风险以及构建模型预测信用风险,选择有代表性的、全面的财务指标作为分析对象。因此,本文选择了涵盖偿债能力、比率结构、盈利能力、经营能力、现金流情况、发展能力以及相对价值这七方面的财务指标作为分析对象(见表1)。
2.基于Lasso回归的变量选择与预测
我们拟使用统计中常用的一类精度,二类精度和总精度三个评价规则来度量各个模型的最终判别效果和预测能力,这三个评价规则定义如下:
一类精度=信用良好公司被模型正确判为信用良好公司的数量/实际信用良好公司数量;
二类精度=信用不好公司被模型正确判为信用不好公司的数量/实际信用不好公司数量;
总精度=实际信用良好或信用不好公司被模型正确判别的数量/被测样本总数量。
3.SVM支持向量机方法
我们首先运用SVM方法对上市公司的财务数据进行分析,此过程可由R软件中的e1071程序包来实现,参数自动寻优结果为:
best gamma=0.5,cost=4,R2=66.67%
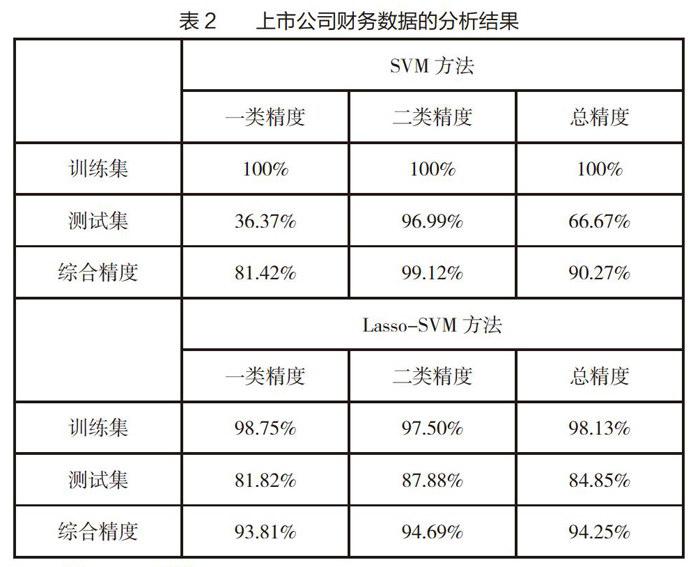
将训练集数据和测试集数据分别代入模型进行检验,最终得到结果如表2所示:从模型解释性与预测精度中,可以看出SVM方法在训练集的精度虽然都达到100%,但在测试集里的一类精度仅为36.37%,因而总体拟合效果不是很理想。
4.Lasso-SVM
本文首先把數据进行中心标准化处理,以消除不同量纲的影响,然后利用R软件的Glmnet程序包,实现通过Lasso方法对Logistic回归模型进行变量选择。运用广义交叉验证方法,可以得到惩罚参数与变量个数的关系图(图1),该图的横坐标表示惩罚参数值的变化,纵坐标表示模型误差的变化情况,并在图上方给出随着值的变化进入模型的变量个数的变化。当的取值为左侧虚线对应的值时,模型误差最小。
由图1,我们最终选取了17个财务指标:现金比率(X3)、资产负债率(X5)、长期资本负债率(X6)、固定资产比率(X8)、流动负债比率(X9)、金融负债率(X10)、投资收益率(X12)、长期资本收益率(X15)、营业毛利率(X16)、应收账款周转率(X17)、存货周转率(X18)、流动资产周转率(X19)、固定资产周转率(X20)、营业收入现金比率(X21)、总资产增长率(X28)、市盈率(X29)和市现率(X30)。
在运用支持向量机方法时,核函数选取为高斯径向基核函数,参数自动寻优结果为:
best gamma=0.5.cost=4,R2=0.8485
将训练集数据和测试集数据分别代入模型进行验证,为便于比较,将最终的分析结果亦列入表2中。从模型解释性与预测精度中,可以看出Lasso-SVM方法的所有的精度都在80%以上,综合精度在94%以上,因而Lasso-SVM方法的拟合效果要高于直接运用SVM方法的拟合效果,能够提高预测精度,拥有更好的预测性能。
四、结语
本文通过对上市公司财务比率数据进行分析,建立信用风险评定模型来预测上市公司的信用风险,分别建立了SVM和Lasso-SVM模型,通过不同模型选择对上市公司信用风险影响较强的指标,同时根据模型的解释效果和预测效果,选择出更适合评定上市公司信用风险的模型。根据全文研究,可以看出,Lasso-SVM模型的预测精度都要高于普通的SVM模型,这可以说明,在上市公司信用评价问题上,使用Lasso方法进行变量选择之后再运用支持向量机方法进行预测有一定的优势,能够提高预测精度,拥有更好的预测性能。
