基于虚拟样本生成技术的多组分机械信号建模
2018-10-15汤健乔俊飞柴天佑刘卓吴志伟
汤健 乔俊飞 柴天佑 刘卓 吴志伟
工业过程的优化运行控制[1]需要准确检测与生产过程的质量、产量、能耗等指标密切相关的难以检测的过程参数[2−3],如磨矿过程广泛使用的大型机械设备球磨机内部的料球比、磨矿浓度、充填率等[4−5].这些过程参数的实时准确检测一直是工业界亟待解决的难题[6].由于流程工业过程的综合复杂特性,以及机械设备连续旋转和封闭运行的特点,其内部过程参数难以通过直接检测方式和建立机理模型计算得到[7].虽然运行专家可以依据多源信息和多年工作经验对所熟悉的机械设备内部的过程参数进行较为准确的估计,但专家经验的差异性和精力的有限性难以保证工业过程长期运行在优化状态.基于这些设备工作中产生的机械振动和振声信号构建数据驱动软测量模型,是目前该领域重点关注的热点和难点问题[8].下文分别从多组分机械信号建模、建模样本非完备和本文研究动机等3方面予以描述.
0.1 多组分机械信号建模
机械振动和振声信号通常具有较强的多组分、非线性和非平稳等特性.基于这些信号进行难以检测过程参数软测量的首要难点问题是:如何从机械信号中提取模型的输入特征.这通常包括信号处理和维数约简两个子问题.通常,机械信号中蕴含的有价值信息被隐含在宽带随机噪声中[9].以磨矿过程的关键设备球磨机为例,磨机负荷参数与磨机筒体振动和振声信号的功率谱密度(Power spectral density,PSD)密切相关[10].研究表明,快速傅里叶变换(Fast Fourier transform,FFT)并不适合于具有非平稳特性的振动信号的处理[11].离散小波变换(Discrete wavelet transform,DWT)、连续小波变换(Continuous wavelet transform,CWT)、小波包变换等时频分析方法已经被广泛应用于基于机械振动信号的故障诊断[12−15],但这些方法不能自适应分解这些多组分机械信号,如面对任何一个具体实际应用问题需要为CWT选择合适的母小波.经验模态分解(Empirical mode decomposition,EMD)技术突破上述局限,通过自适应分解获取具有不同时间尺度和物理含义的内禀模态函数(Intrinsic mode function,IMF)[16],广泛用于处理多组分机械信号[17−19].文献[20−21]采用EMD 对磨矿过程的球磨机筒体振动信号进行处理,分解得到系列具有不同物理含义和不同时间尺度的子信号.研究表明,EMD算法存在频谱分辨率低、虚假组分易造成模态混叠、低能量成分不可分等问题.集成EMD(Ensemble EMD,EEMD)技术克服了EMD的模态混合问题[22],但仍存在蕴含有价值信息的子信号数量有限及其时频特征难以选择等问题.
因机械振动和振声的频域特征明显,将其进行时频变换是通常采用的处理手段之一.文献[23]提出:将机械信号直接变换至频域的数据称为单尺度频谱,而将经多组分信号技术分解得到的不同时间尺度子信号变换至频域的数据称为多尺度频谱.显然,当频率分辨率较高(如1Hz)时,单/多尺度频谱的维数均高达数千维并且谱特征间具有较强的共线性.因此,维数约简成为基于机械信号构建软测量模型需要面对的又一问题[24].常用的基于遗传算法(Genetic algorithm,GA)的频谱数据特征选择算法存在运行时间长和效率低等问题[25].针对机械振动频谱,文献[26]提出基于互信息(Mutual information,MI)和潜结构模型的IMF及其多类谱特征的自适应选择方法.研究表明,MI能有效描述输入和输出数据间的映射关系,并且更易于理解[27];但存在寻优耗时等问题.
我们认为,构建基于机械频谱特征的难以检测过程参数软测量模型应尽可能地模拟运行专家选择多维度有价值信息进行过程参数认知的机制.通常,机械振动/振声信号的多源多尺度频谱是由具有不同物理含义和时间尺度的子信号经时频变换获得.基于这些谱数据构建选择性集成(Selective ensemble,SEN)软测量模型的过程在本质上是选择性的信息融合过程[6].文献[21,23]基于这样的思路,构建了基于分支定界(Branch and bound,BB)优化算法和自适应加权融合(Adaptive weighted fusion,AWF)算法的SEN核潜结构映射或核偏最小二乘(Kernel partial least squares,KPLS)算法的软测量模型.从集成学习理论的视角出发,这些方法均属于“操纵输入特征”的集成构造策略进行模型构建,所优化选择的是“有价值的多源信息”.工业实际中,运行专家识别难以检测过程参数不仅需要选择有价值的多源信息进行融合,还需要利用自身积累的历史经验,即也要选择有价值样本进行认知.基于遗传算法的选择性集成(GA-based selective ensemble,GASEN)[28].采用“操纵训练样本”策略构造集成、采用误差反向传播神经网络(Back propagation neural networks,BPNN)构建候选子模型、采用GA优选集成子模型和简单加权平均组合集成子模型;针对BPNN训练时间长、容易过拟合和GASEN难以采用高维小样本数据直接建模等缺点,文献[26]提出了基于“操纵训练样本”集成构造策略的改进选择性集成核偏最小二乘(Selective ensemble kernel partial least squares,SENKPLS)算法;文献[29]提出了采用双层GA优化改进SENKPLS的建模参数;文献[30]提出基于稀疏非线性特征的KPLS.显然,我们需要合适的软测量策略模拟运行专家融合多维度信息的认知机制.
0.2 建模样本非完备
在实际工业应用过程中,难以检测过程参数建模经常遇到的更为棘手的难点是:如何获得能够覆盖多种工况和充足完备的建模样本.研究表明,充足完备的建模样本对于构建有效的学习模型非常重要.通常,流程工业中难以检测过程参数的建模样本仅能在实验设计阶段或工业过程停产重新运行的起始阶段获得;否则,需要以牺牲企业的经济效益或较长周期的时间等待为代价.如何基于短缺、非完备样本构建鲁棒的面向工业应用的数据驱动模型,一直以来都是个开放性的难题.
为提高模型的泛化性能,图像识别领域首次提出了基于先验知识从给定小规模真实训练样本产生虚拟训练样本的方法[31−33],即虚拟样本产生(Virtual sample generation,VSG)技术.目前的已有研究包括:利用BPNN和巨型趋势分散技术[34]、利用运行专家知识[35]、利用噪声构造[36]、利用原始样本分布函数[37]等.对面向高维小样本数据的分类问题,文献[38]提出了基于分组的VSG用于脱氧核糖核酸(Deoxyribonucleic acid,DNA)微阵列数据建模.上述研究中的VSG多面向分类问题[37,39].本文主要关注如何利用VSG辅助构建基于多源多尺度谱数据的软测量模型,即面向回归问题的VSG.
针对回归建模问题,文献[40]提出基于多层感知器网络的VSG技术,即虚拟样本输入通过选择真实样本输入附近的点产生,虚拟样本输出通过平均多层感知器网络的不同输出数据获得;文献[41]提出用分散神经网络(Decentralized neural networks,DNN)产生虚拟样本和建模小数据集,表明DNN比BPNN具有更强的预测性能;文献[42−44]提出基于遗传算法(GA)、粒子群优化(Particle swarm optimization,PSO)算法以及蒙特卡洛与PSO相结合的VSG;文献[45]提出一种的产生通用结构数据的采样方法;但上述这些方法多采用传统的单模型产生虚拟样本.针对具有复杂分布的建模数据或高维小样本数据,传统的单模型难以有效解决模式识别或回归建模等问题.文献[46]提出的VSG难以直接面对高维谱数据建模.
针对真实数据与虚拟数据混合利用问题,文献[47]提出将基于原始数据的特定小数据和虚拟的人工数据相结合,然后对机器学习模型进行更新的策略;文献[48]提出平行学习的概念,并将其作为机器学习研究方向的一个新型理论框架,在该框架中提出通过混合人工数据和原始数据进行基于计算实验的预测学习和集成学习.可见,将VSG结合具体的工业背景进行研究具有重要的理论和现实意义.
0.3 本文研究动机
综上可知,面对基于多组分机械振动/振声信号的流程工业难以检测过程参数的软测量问题,有以下问题需要解决:1)如何将蕴含着丰富难以检测过程参数信息的多组分机械振动/振声信号自适应地分解为具有不同物理含义的不同组成成分,为构建寓意明确的软测量模型和探究旋转机械设备内部的工作机理与振动产生机理奠定基础;2)如何基于确定性的先验知识和非充足完备的真实训练样本提出适合于高维谱数据的VSG技术;3)针对基于多组分机械信号,在利用VSG构建虚拟样本输出时需要解决:如何依据不同时间尺度子信号的谱特征所构建的集成子模型对软测量模型预测输出的贡献率,对集成子模型的虚拟样本输出进行加权组合以获得统一的虚拟样本输出;4)如何选择有价值子信号及其高维频域特征,以及如何选择性融合多源多尺度谱特征和多工况样本,以便更有效地模拟工业现场运行专家的认知机制.因此,基于多组分机械信号的软测量建模可以归结为一类针对多源多尺度高维谱数据的小样本建模问题.
针对上述需要解决的问题,综合之前的研究成果,本文首先提出了一种面向多源多尺度高维谱数据的VSG技术用以解决建模样本的短缺非完备问题;再以混合训练样本结合MI自适应特征选择技术获取多源输入特征,并基于改进的SENKPLS算法从操纵训练样本集成构造视角构建软测量模型;最后采用近红外谱(Near infrared spectrum,NIR)数据和磨矿过程实验球磨机筒体振动与振声信号构建的软测量模型验证本文所提出的VSG技术和面向多组分机械信号建模方法的合理性和有效性.
1 相关知识
此处主要对本文所采用算法和技术的相关基础知识进行简短描述.
1.1 面向多组分机械信号的建模
1.1.1 多组分机械信号自适应分解
满足特定假设条件的多组分、非线性、非平稳机械信号采用EMD可以分解为若干个不同时间尺度的IMF和残差之和.这些理论上均有其物理含义的IMF子信号按照频率由高到低排列.多组分机械信号与IMF信号间的关系可表示为
EMD在处理机械振动和振声等多组分信号较传统FFT和小波变换具有明显优势,但也存在虚假人工成分导致的模态混叠、分解端点效应、子信号非严格正交、有效子信号数量有限等问题.基于白噪声统计属性的EEMD可以有效克服EMD的模态混叠问题,其基本思路是加入影响整个时频空间的白噪声Anoise,重复进行整个EMD分解过程M次后进行平均.EEMD和EMD之间的关系表示为
显然,EEMD的计算消耗与EMD相比成倍增长.针对EMD的缺点,已有研究包括小波包EMD(Wavelet packet decompsition(WPT)-EMD)、在线EMD及各种基于预测模型的端点延拓算法等.研究表明:不同算法具有各自的优缺点,需要结合应用背景确定;有价值子信号的数量也是有限的,需要进行优选.
1.1.2 高维谱数据的维数约简
特征提取和特征选择技术均可有效处理高维谱数据的维数约简问题.特征提取采用线性或是非线性的方式确定合适的低维潜在特征替代原始高维特征,优点是考虑了全部特征的多数变化信息,缺点是所提取特征较难解释,并且所丢弃的残差因含有全部输入变量的信息而可能具有更高的建模贡献率.常用的基于主成分分析(Principal component analysis,PCA)的特征提取以低维潜在特征表征原始高维数据,但未考虑输入和输出间的相关性[49].基于潜结构映射或偏最小二乘(Projection to latent structure or partial least squares,PLS)的特征提取可克服这一缺陷,可逐层提取同时表征输入输出间变化的潜在变量[50].文献[51]提出了基于PLS的通用特征提取框架.面向多尺度频谱,文献[52]提出了基于球域准则和PLS的多尺度频谱特征选择方法.工业过程的非线性本质使得为输入数据扩展非线性项而进行非线性特性提取的核方法广泛应用[53−57],如核PCA(Kernel PCA,KPCA)、核独立主元分析(Kernel independent principal component analysis,KICA)、核费舍尔判别分析(Kernel Fisher discriminant analysis,KFDA)和KPLS[58−59]等.特征选择技术依据某种准则优选重要特征,其优点是所选择的特征易于解释,缺点是未被选择的特征可能会降低软测量模型的泛化性能[60].研究表明,相对于其他方法,基于MI的特征选择更易于理解和更有效.文献[61]提出基于MI的潜在特征度量方法,对特征提取与特征选择技术进行了有效组合.
因此,结合不同的应用需求,研究不同的维数约简算法是面对实际应用问题的有效策略之一.
1.1.3 基于改进SENKPLS的高维谱数据建模
PLS/KPLS算法除用于提取与输入输出均相关的潜在特征外,也可直接构建潜结构模型,类似于人脑逐层进行特征抽取进行认知的机制.面对多源机械振动/振声信号特征子集,基于“操纵输入特征”的集成构造策略,文献[24]从选择性信息融合的视角构建SENKPLS模型.
此处重点描述基于“操纵训练样本”集成策略的改进SENKPLS算法;与GASEN对比,该方法可以直接构建基于小样本高维谱数据的软测量模型.另,除非特别说明,本文中的输出均为单变量输出.
集成构造的过程是采用Bootstrap算法基于有放回的抽样原则在原始训练样本中产生J个训练子样本,其中J也是候选子模型数量和GA优化种群数量.下文以第jth个训练子样本为例对候选子模型的构建过程进行描述.
首先将训练子样本映射到高维空间:

其中,Kj采用下式中心化:
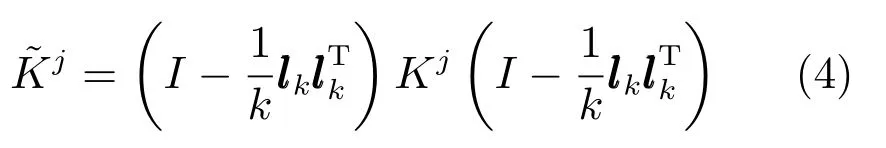
其中,I是单位阵,lk是值为1,长度为k的向量.
此处,为所有候选子模型选择相同的核参数Kpara和核潜变量 (Kernel latent variable,KLV)数量hKLV,并将全部候选子模型的集合标记为.验证样本基于第jth个候选子模型的预测输出为
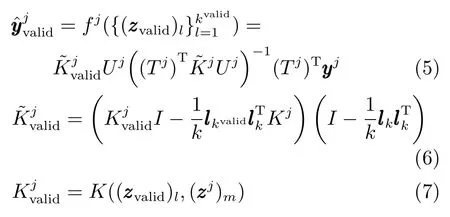
其中,kvalid是验证样本的数量.验证样本的预测误差采用下式计算:

第jth个和第sth个候选子模型的相关系数为
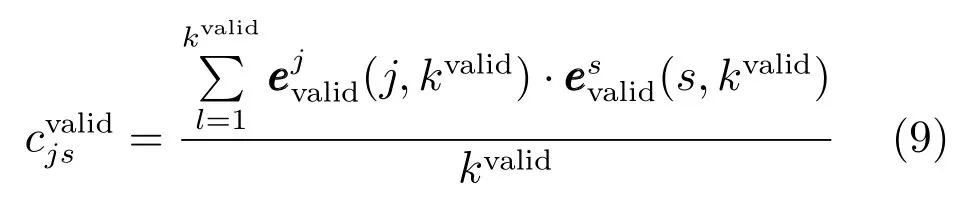
构建如下的相关系数矩阵:

基于Cvalid采用GA优化工具箱(GAOT)优化候选子模型的随机向量,并将优化结果记为.采用如下准则选择集成子模型:

其中,λ是集成子模型的选择阈值.
将ξj=1的候选子模型选择为集成子模型,并将其数量记为J∗,即SEN模型的集成尺寸.将第j∗th 集成子模型记为fj∗(·),其输出为

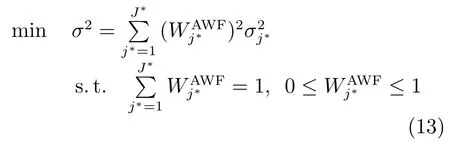
其中,σ是SEN模型预测值的方差,σj∗是集成子模型预测值的方差.
集成子模型的权重采用下式计算:
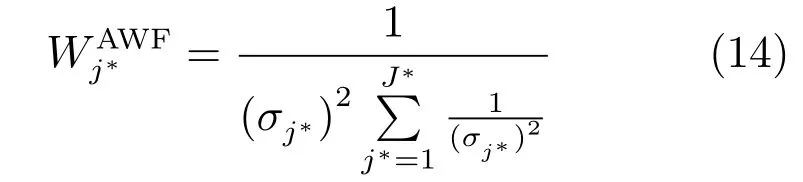
基于上述建模算法,单个测试样本的输出为

1.2 面向建模样本非完备的VSG技术
1.2.1 小样本数据集概述
在多数工业过程中,数据采集与存储系统所带来的多是模型输入维数和低价值训练样本的增加,这使得输入特征高维、训练样本不完备等问题仍然较为突出[62].研究表明,数量充足、覆盖工况完备的建模样本对构建有效的软测量模型非常重要.目前,关于小样本数据的定义具有较大的相对性和主观性[62].
为了确定获得必要的预测性能而需要的最小训练样本的数量,研究人员提出了概率近似正确、训练样本和输入特征比率等指标[63−64].在模式识别领域,通常认为训练样本数量与输入特征之比应该足够大,其相互关系可表示为

其中,nsample和pfeature分别表示训练样本和输入特征的数量.通常,α的取值为2,5或10.
文献[65]面向分类问题,研究了分类误差、训练样本数量、输入特征维数和分类算法复杂性间的相互关系.针对一些典型的分类器,文献[66]描述需要充足完备训练样本的内在原因,并着重研究在α≤1时的分类器性能,即研究nsample小于pfeature时线性分类器泛化性能.此处,记维数约简后的特征为pfeatureredu,并定义如下指标:

若经维数约简后的αredu值仍然难以满足构建具有鲁棒预测性能的学习模型的要求,必须采用其他方法解决训练样本的短缺问题.
1.2.2 虚拟样本的定义
虚拟样本的定义源于图像识别领域:基于先验知识从物体的3D视角出发,将通过数学变换产生的新图像称为虚拟样本.文献[67]对虚拟样本给出了如下较为通用的定义:
定义1.将记为真实样本,其中,是真实样本数量;基于先验知识Know,采用变换产生新样本,即:
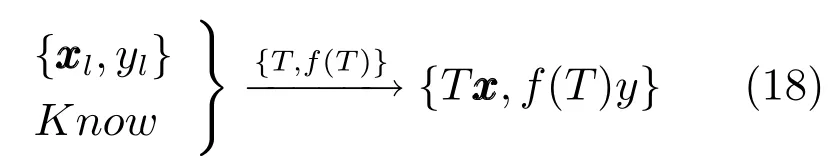
基于上述定义,本文给出如下推论:
推论.给定真实样本数据集,通过适当的变换可产生虚拟样本数据集.该过程可用如下公式表示:
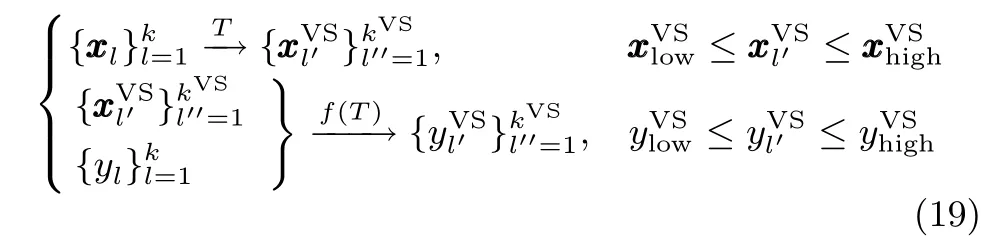
1.2.3 VSG的关注问题
通常,若要产生合理的虚拟样本,需要关注至少如下4个问题:
1)确定虚拟样本产生策略.方法包括:利用先验知识、扰动原始样本、对输入数据添加噪声等[67];
2)确定虚拟样本输入.方法包括:先验知识[31]、在真实样本输入点的超域内随机选取[40]、函数化虚拟群体[68]、基于真实样本输入间隔的信息分散技术[41]、间隔核密度估计[37]、Mega趋势分散(MTD)函数[34]、基于模糊数据集的成员函数[69]、组虚拟样本产生[38]、基于模糊理论的产生趋势分散(GTD)[70]、基于高斯分布[67]、基于GA 和BPNN[42];
3)确定虚拟样本输出.方法包括:平均神经网络的输出[40]、基于实际样本输出间隔的信息分散技术[41]和基于GA和BPNN的方法[42]等;
4)确定虚拟样本数量.目前,最优化虚拟样本数量的确定主要基于实验数据确定.如何在理论上指导或确定优化的虚拟样本数量还是个开放性难题.
另外,对于分类模型和回归模型,VSG所关注的问题是具有差异性的,原因在于:分类问题的类标是固定的,变换f(T)也许是不必要的;回归问题的每个输入均需要唯一对应一个输出,这增大了VSG的难度.笔者认为,这也是当前关于回归问题的VSG研究要远少于分类问题的原因之一.
综上,结合具体的应用背景进行VSG回归问题的实用化研究将更具有挑战性和现实意义,也是目前研究中的难点之一.
2 基于VSG的多组分机械信号建模策略
本文提出的基于VSG的多组分机械信号建模策略主要由:多尺度谱数据获取、虚拟样本产生、谱特征自适应选择和软测量模型构建共4个模块组成,如图1所示.
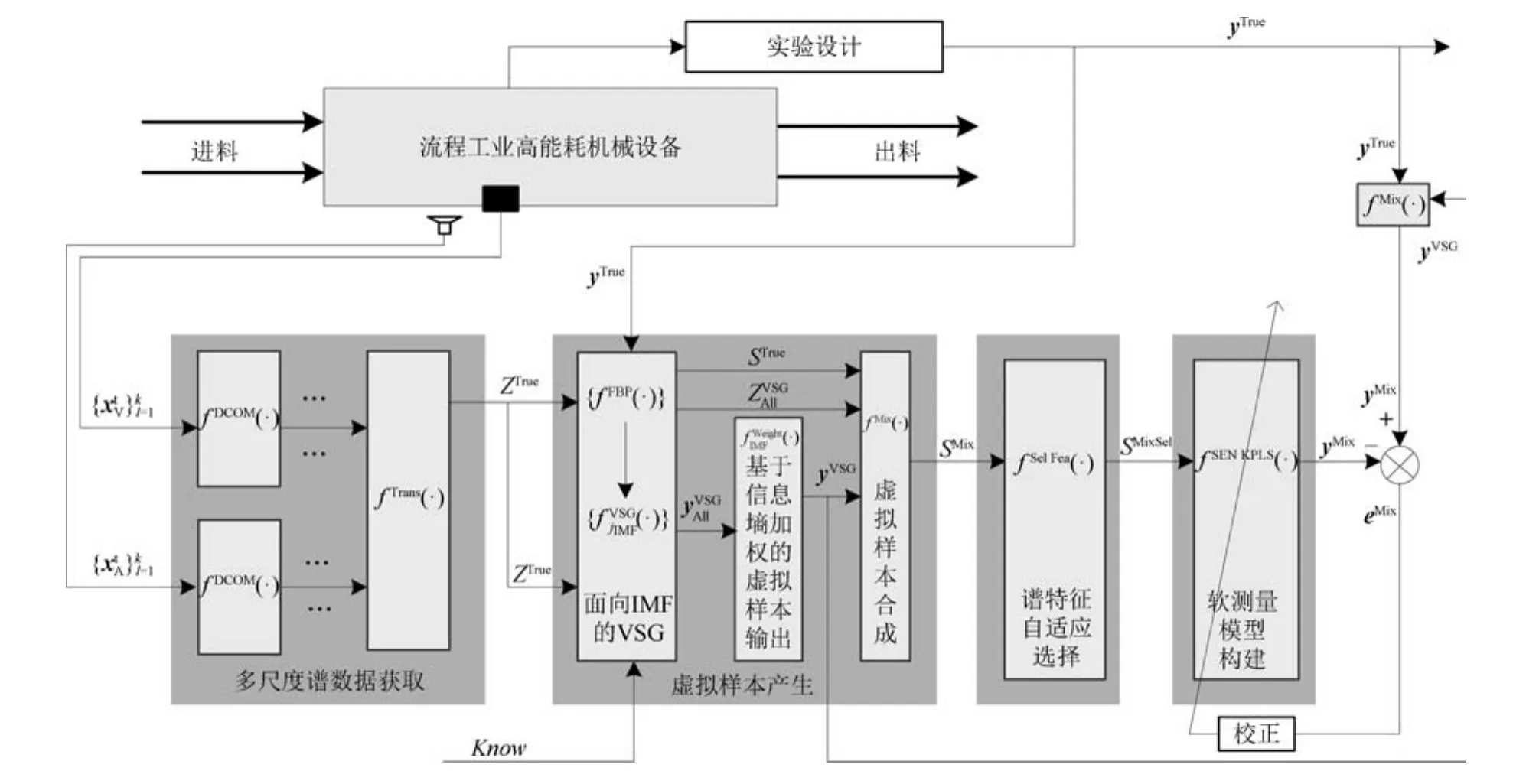
图1 基于VSG的多组分机械信号建模策略Fig.1 Multi-component mechanical signal modeling strategy based on VSG
图1中不同模块的功能描述如下:
1)多尺度谱数据获取模块:其输入为真实的时域机械振动/振声信号,输出为真实的频域多尺度训练样本;主要功能是将包含若干数据点的多组分时域信号经自适应分解和时频域转换得到多源多尺度高维谱数据.
2)虚拟样本产生模块:是本文所提方法的核心模块,其输入为真实的训练样本和先验知识,输出为混合训练样本;主要功能包括:面向IMF的VSG,基于信息墒加权IMF虚拟样本输出,以及虚拟样本合成.
3)谱特征自适应选择:其输入为混合训练样本,输出为经特征选择的约简混合训练样本;主要功能是自适应地选择有价值的多源多尺度子信号及其谱特征.
4)软测量模型构建:其输入为约简混合样本,输出为难以检测过程参数的预测值;主要功能是构建基于“操纵训练样本”策略的适合于高维谱数据的SENKPLS模型.
因此,上述不同模块分别实现了多组分信号的自适应分解、基于先验知识和真实训练数据的虚拟样本产生、多组分机械信号不同IMF集成子模型虚拟样本输出加权融合、多源多尺度特征的自适应选择以及仿运行专家综合多源特征和多工况样本认知机制的建模.其中,虚拟样本产生模块是本文所提方法的核心.
3 基于VSG的多组分机械信号建模实现
3.1 多尺度谱数据获取模块
以包含N个数据点的单个建模样本为例,EEMD可将机械振动和振声信号分解为

用于构建软测量模型的IMF的最大数量依据空载时机械设备振动分解结果和先验知识确定.本文将构建软测量模型的机械振动和振声IMF的数量标记为JA和JV,并将IMF重新编号,如下式所示:

其中,JIMF=JA+JV,表示全部IMF的数量.
从机械振动和振声IMF可提取至少三类三类特征:基于Hilbert变换(Hilbert transform,HT)的多尺度边际谱 (Multi-scale HT,MSHT)、HT变换的多尺度瞬时幅值和频率的均值及方差(Multi-scale amplitude and frequency,MSAF)和基于FFT的多尺度功率谱密度(Multi-scale PSD,MSPSD).这三类特征均有各自特性,且均已成功应用在不同领域中[71].这些谱特征可视为来自不同视角的多源信息,其转换过程为

在实际过程中,可依据工业实际选择其中的一类或几类特征或全部特征.本文中以MSHT特征为例进行描述.此处,将基于不同IMF的谱特征统一表示为下式:

3.2 虚拟样本产生(VSG)模块
3.2.1 VSG模块的结构与功能
该模块由面向IMF的VSG、基于信息墒加权的虚拟样本输出和虚拟样本合成共3个子模块组成,其相互之间的输入输出关系如图2所示.
由图2可知,“面向IMF的VSG”子模块包含JIMF个面向高维谱数据的相对独立的二级子模块,其功能是基于真实的多尺度频谱和先验知识得到多个基于不同IMF的虚拟样本输入和输出;“基于信息墒加权的虚拟样本输出”子模块将多个不同IMF的虚拟样本输出加权以获得统一虚拟样本输出;“虚拟样本合成”子模块是组合真实和虚拟训练样本得到混合虚拟样本.
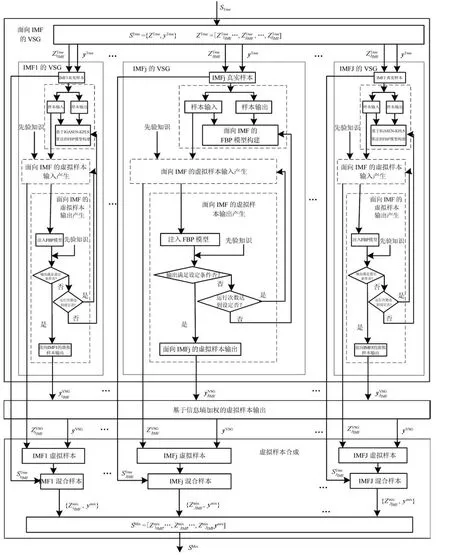
图2 虚拟样本产生(VSG)模块的结构Fig.2 Structure of the virtual sample generation(VSG)module
3.2.2 VSG模块的算法实现
1)面向IMF的VSG子模块
将多源多尺度的真实训练样本表示为以不同IMF的频谱为输入和待建模过程参数为输出的训练样本子集.面对实际工业过程,所具备的先验知识Know是:构建过程参数软测量模型的真实训练样本均具有实际物理含义,即针对采用实验设计方案产生训练样本的先验知识是已知的.

此处,将基于两个相邻真实训练样本输入之间间产生的虚拟样本输入记为再假定针对k个真实训练样本共存在kVSG个间隔利用,则可产生的虚拟样本输入的总数量为
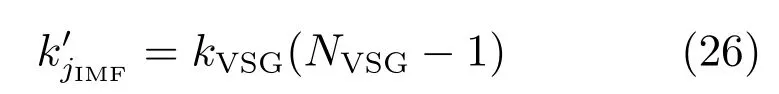
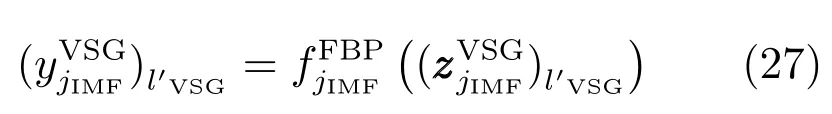

若不满足式(28),则重复式(27)和(28)表示的过程;若重复后,上式仍然无法满足,重新构建FBP模型,直至满足上述条件;若满足式(28),则获得一个完整的虚拟样本输入输出对,如下式所示:
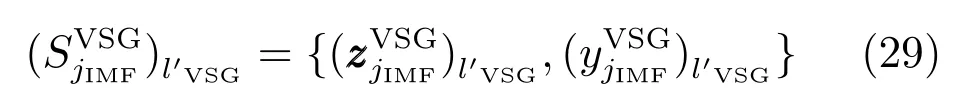
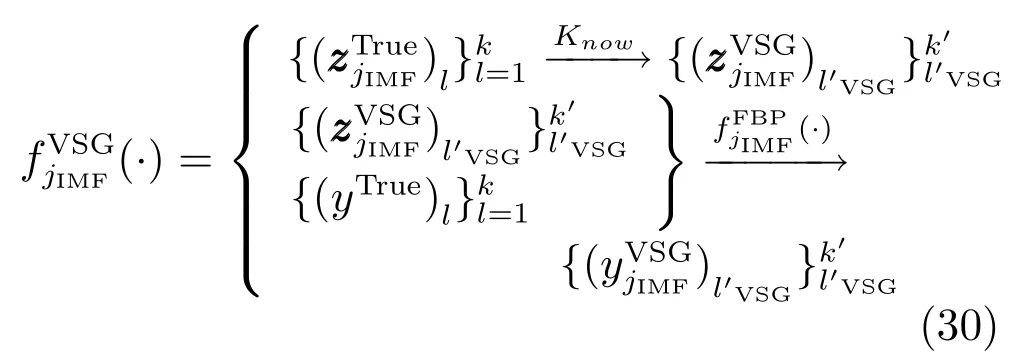
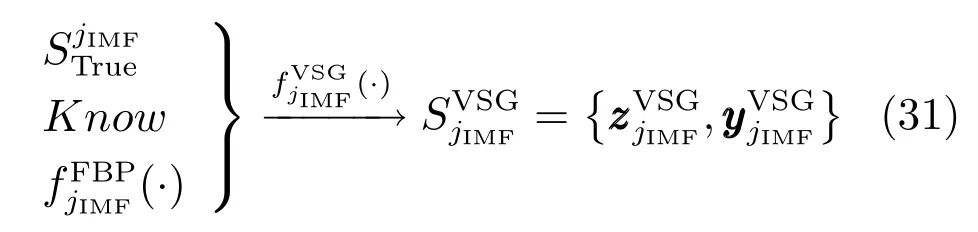

2)基于信息墒加权的虚拟样本输出子模块
由式(32)可知,针对不同的多源多尺度真实训练样本子集产生了JIMF个虚拟样本输出值,原因在于构建了JIMF个FBP模型.显然,需要加权这些不同IMF的虚拟样本输出以获得统一的输出值.第个虚拟样本的输出为
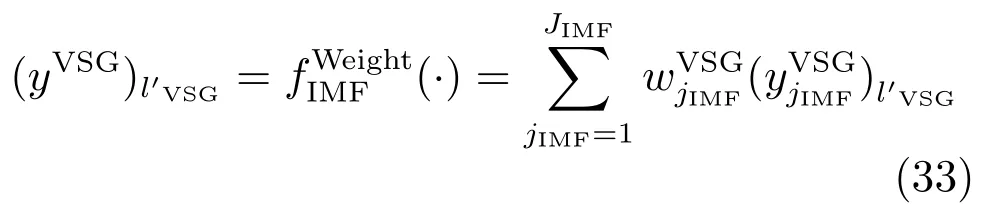
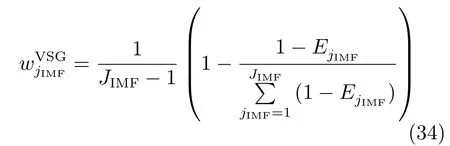
其中
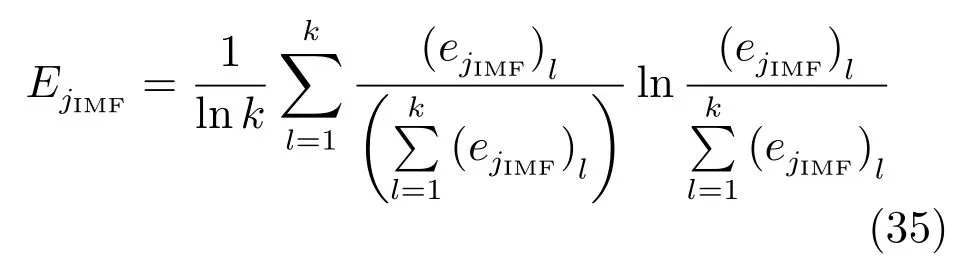


3)虚拟样本合成子模块
经上述过程产生的虚拟样本集可表示为
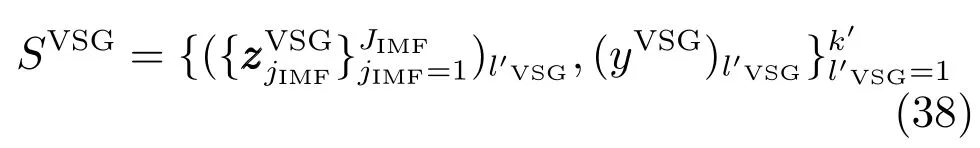
组合真实和虚拟训练样本可获得构建软测量模型的混合样本SMix.为便于理解,将其重新描述,其改写过程可表示为
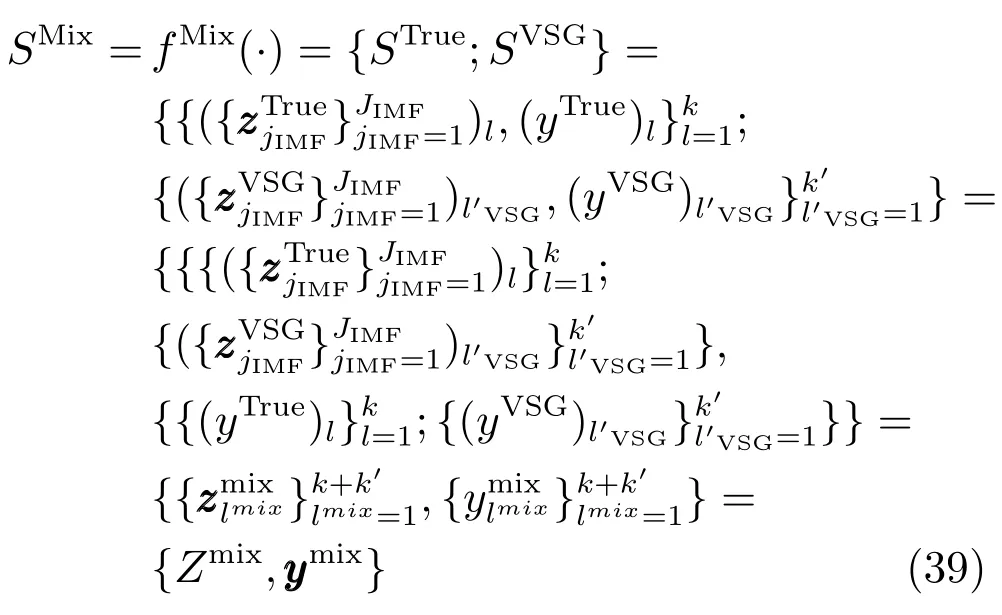
由上式可知,混合样本的数量为(k+k′).
3.2.3 VSG模块的准确性分析与适应性讨论
VSG模块是保证本文所提多组分机械信号建模方法的准确性并具有良好预测性能的关键环节.此处针对产生虚拟样本过程中的关键环节进行准确性分析和适用性讨论.
1)面向IMF构建的FBP模型:此处采用的建模方法是适合于小样本高维数据的SENKPLS算法.KPLS算法是PLS的核版本,能够有效地处理输入变量间的共线性问题,其用于构建内层模型的潜在变量远远小于原始输入特征数量,进而能够保证基于IMF的高维谱数据构建的FBP模型的泛化性能.另外,基于“操纵训练样本”集成构造策略的SEN算法选择有价值训练样本构造软测量模型,其与KPLS算法的结合,进一步增强了FBP模型的泛化性能.
2)面向IMF的虚拟样本输入:基于多源多尺度IMF的真实训练样本子集是基于机械振动/振声信号经自适应分解和时频变换获得;虽然这些高维谱变量难以得到合理的具体解释,但原始的机械振动/振声样本均有明确的物理含义;在产生虚拟样本输入值时,两个真实训练样本间所划分间隔的大小也是依据先验知识确定的;并且式(25)保证了其合理的取值范围.这些约束保证了虚拟样本输入值的准确性.
3)面向IMF的虚拟样本输出产生的准确性:这些不同的IMF基于各自的FBP模型所产生的虚拟输出值的范围由式(28)及其相应的策略予以保证,由图2所给出的“面向IMF的VSG”中的算法流程给出了更为清晰的描述,进而保证了虚拟样本输出值的准确性.
4)基于信息墒加权的虚拟样本输出:这些多源多尺度IMF均是由原始的机械振动/振声信号分解得到的,显然这些IMF的虚拟样本输入应该对应统一且唯一的虚拟样本输出值,需要将不同IMF的虚拟样本输出值进行加权,式(33)~(36)采用信息墒加权,由FBP模型的预测误差得到不同IMF虚拟样本输出值的权系数,从而保证了最终的虚拟样本输出值的准确性.
5)VSG模块的适用性讨论:在VSG过程中,FBP模型的准确性比较重要,这就要求真实的训练样本虽然稀少,但尽量保证较宽的工况覆盖范围;VSG模块的所描述的算法适用于已经将原始多组分信号分解为多个不同的子信号,并且这些子信号的输入变量间具有较强的共线性的情况;同时,“面向IMF的VSG子模块”中所描述的算法适用于具有高维共线性特性的真实训练数据产生虚拟样本.
因此,本文此处所提出VSG技术能够保证所产生虚拟样本的准确性.另外,本文所提VSG技术虽然是面向多组分机械信号建模这类问题提出的,具有较强的针对性;同时,“面向IMF的VSG子模块”所描述的VSG技术针对高维谱数据也具有较好的普适性.
3.3 谱特征自适应选择模块
为便于特征选择,此处将不同IMF的输入变量特征进行合并和重新编号,如下式所示:
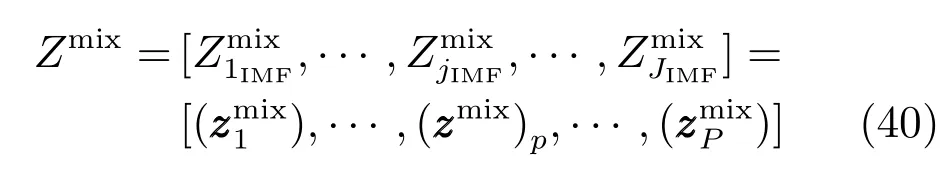
采用密度估计方法计算第pth谱变量和难以检测过程参数之间的MI值:
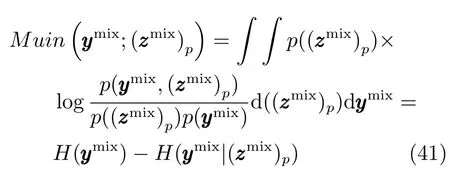
基于下式对谱特征进行选择:
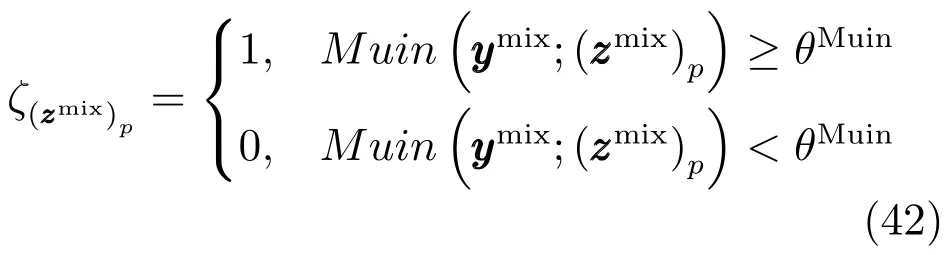
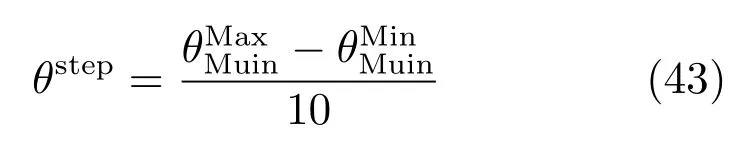
此处简化基于MI的特征选择过程是考虑到后续基于SENKPLS的软测量模型可以消谱特征间的共线性.采用如下过程进行有价值IMF及其特征的自适应选择:首先,将的谱特征进行串行组合并构建潜结构模型;接着,以步长θstep增加MI阈值并重复上述过程;最终,具有最小预测误差的阈值被选定为最终阈值,以此阈值基于式(42)完成有价值子信号及其谱特征的选择.
将约简后的多源多尺度谱特征记为Zmixsel,相应的混合样本可标记为
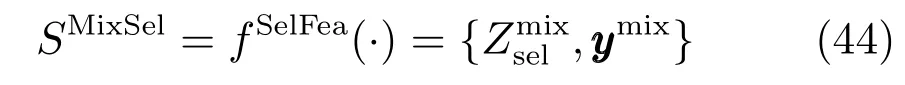
3.4 软测量模型构建模块
采用第1.1.3节的SENKPLS算法,基于约简后的混合样本SMixSel构建过程参数软测量模型,其输出可表示为

4 应用验证
此处的应用验证分为两部分:首先,采用近红外谱(NIR)数据对本文所提方法的关键部分“面向IMF的VSG”技术进行验证;接着,采用磨矿过程实验球磨机的筒体振动/振声信号验证本文所提出的基于VSG的多组分机械信号建模方法.
4.1 基于近红外(NIR)谱的VSG技术验证
4.1.1 数据描述及预处理
近红外(Near infrared,NIR)谱数据用于估计橙汁的含糖水平.该数据集可在http://www.ucl.ac.be下载,其包含的训练和测试数据集的大小分别是150×700和68×700.本文采用间隔取样原始训练数据方式获取1/10(15个样本)作为真实的训练样本,其输入特征变量和待预测的输出如图3所示.
采用PLS提取真实训练样本的潜在特征(LV),其中前5个LV的贡献率如表1所示.
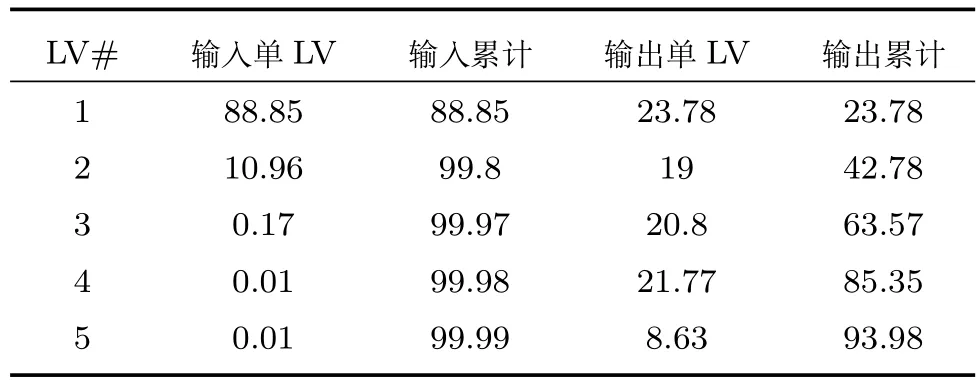
表1 基于PLS提取的潜在特征的贡献率Table 1 Contribution of the latent features extracted based on PLS
由表1可知:在NIR谱数据的700个输入变量中提取的第1个潜在特征可以表征输入数据88.85%的变化,却只能提取输出数据的23.78%的变化;相应的,前5个LV的累计贡献率可以达到99.99%和93.98%.这些结果表明了NIR数据具有较强的共线性,也表明了基于潜在变量的建模方法比较适合该类高维数据.
4.1.2 谱数据的VSG结果
采用第1.1.3节所描述的SENKPLS算法构建真实训练样本的FBP模型.其中,设定候选子模型的数量(即GA种群数量)为20,集成子模型的选择阈值为0.05,KPLS采用径向基函核函数(Radial basis function,RBF);核半径和核潜在变量(KLV)数量采用网格寻优法,它们与均均方根误差(Root mean square error,RMSE)的关系如图4和图5示.

图3 NIR真实训练样本输入和输出Fig.3 Inputs and outputs of NIR training samples
依据图4和图5可知,KLV取10,核半径取600.为克服GA算法的随机性,采用上述建模参数运行20次,测试数据RMSE的均值、最大值、最小值和方差分别为7.1880,9.0742,5.6867和0.9779基于上述FBP模型,采用第3.2.2节“1)面向IMF的VSG子模块”部分描述的VSG算法生成虚拟样本.此处,选择在两个相邻的真实训练样本之间产生虚拟样本;这样,在NVSG=2,3,···,10时,对应的虚拟样本的数量分别是14,28,···,126.NVSG=8时所生成的虚拟样本输入和输出如图6所示.
对比图6和图3可知,虚拟样本的输入和输出在趋势上与真实训练样本是一致的.
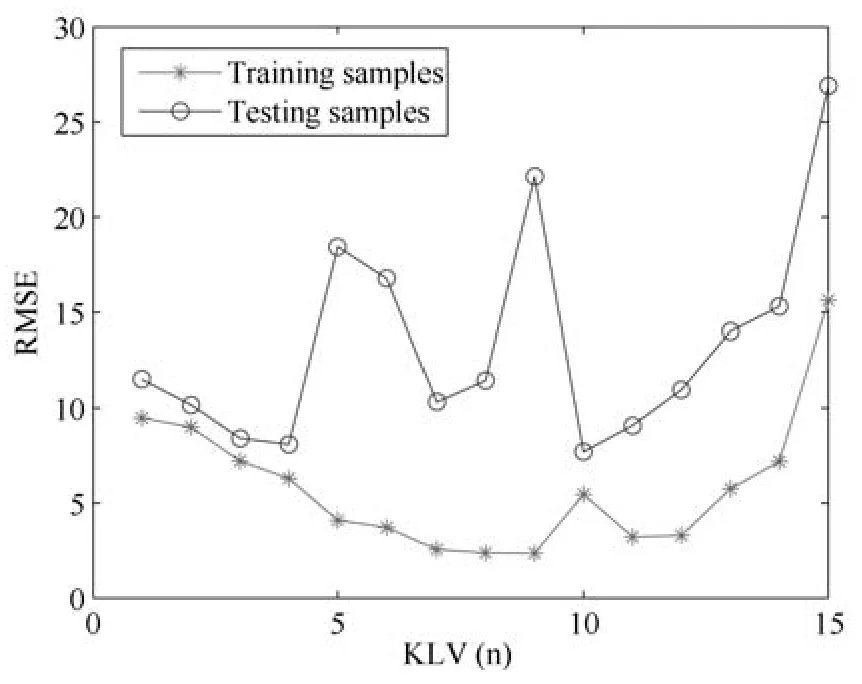
图4 KLVs数量与RMSE的关系Fig.4 Relationships between KLVs′number and RMSE
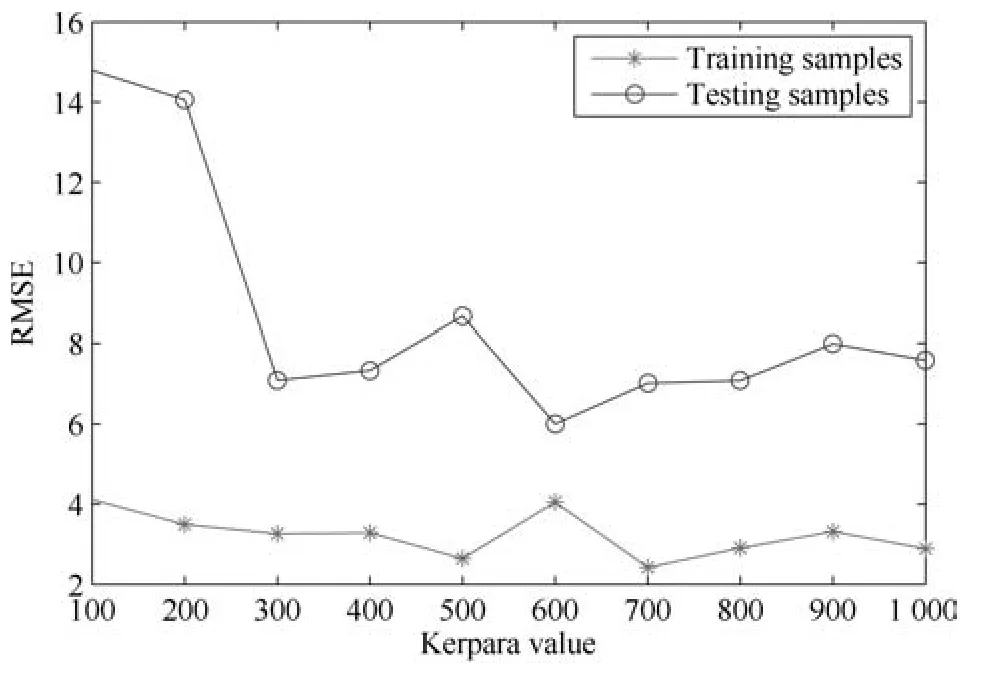
图5 核半径与RMSE的关系Fig.5 Relationships between kernel radiu and RMSE
4.1.3 基于VSG的模型性能比较结果
将虚拟与真实样本相混合,采用第1.1.3节的方法构建NVSG=2,3,···,10时的混合样本软测量模型.本文此处主要基于NIR谱数据验证VSG技术的合理性,故未对谱特征进行选择.建模参数的选择过程和所采用的测试样本均与FBP模型相同.采用不同数量的混合样本建立的软测量模型的测试数据统计结果如表2所示.
如表2所示,在NVSG=9(即虚拟训练样本数量为112)时,基于混合样本所构建的软测量模型具有最佳的平均、最大和最小RMSE,分别为6.0723,6.8627和5.8029,并且方差也只有FBP模型的1/4.可见,本文所提VSG技术同时提高了软测量模型的预测精度和预测稳定性.基于其他数量的混合样本所构建的模型的预测性能也多强于FBP模型,模型预测的稳定性均得到提高.因此,选择合适的虚拟样本数量对构建有效的软测量模型非常重要.
表2只是从测试数据预测性能的视角给出统计结果,未考虑训练数据.图7给出采用不同值(即不同数量的虚拟样本)建模时的训练误差的统计曲线.

图6 NIR虚拟训练样本的输入和输出Fig.6 Inputs and outputs of NIR virtual training samples
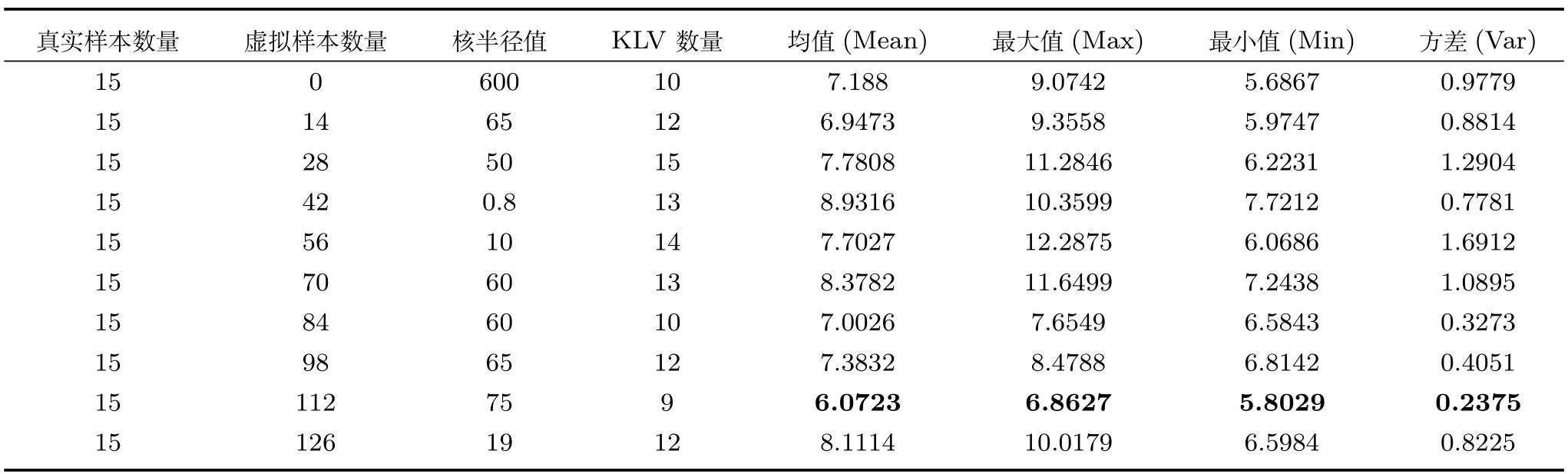
表2 基于混合样本建立的NIR模型统计结果Table 2 Statistical results of NIR model based on mixed samples
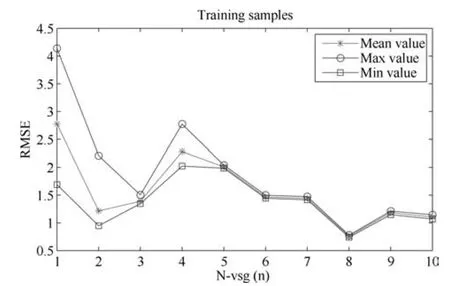
图7 基于不同数量的虚拟样本构建模型的训练误差Fig.7 Training errors of the constructed model based on virtual samples with different numbers
由图7可知:FBP模型(NVSG=1)具有最大的预测性能波动范围;NVSG=5以后,混合训练数据构建的软测量模型的预测稳定性较好,同时训练误差也进一步降低.
综合表2和图7可知,本文所提VSG技术适合于对小样本高维谱数据,将其结合具体工业过程进行研究将更具有实际意义.
4.2 基于球磨机机械信号的建模方法验证
4.2.1 磨矿过程及磨机实验描述
1)磨矿工艺与磨机负荷参数磨矿过程是整个选矿流程中最为重要的作业环节.国内选矿行业广泛应用两段式闭式磨矿回路(Grinding circuit,GC)工艺.其中一段GA(GC I)的工艺流程如图8所示.
如图8所示,原矿通过振动给料机给到运输皮带,然后输送到湿式预选机,通过磁力选择有用矿石,抛尾矿;然后混合来自旋流器的沉砂以及周期性添加的钢球,通过给矿器进入球磨机;球磨机依靠筒体旋转带动钢球对矿石进行冲击破碎,形成矿浆;矿浆依靠自身的流动性排出磨机后进入泵池,与泵池内的新加水混合后被泵入旋流器;旋流器将矿浆分为粒度较细的溢流和较粗的沉砂,其中,后者进入球磨机再磨构成球磨的闭路循环,前者进入磁选机进行选别的沉砂将进入二段磨矿回路(GC II).
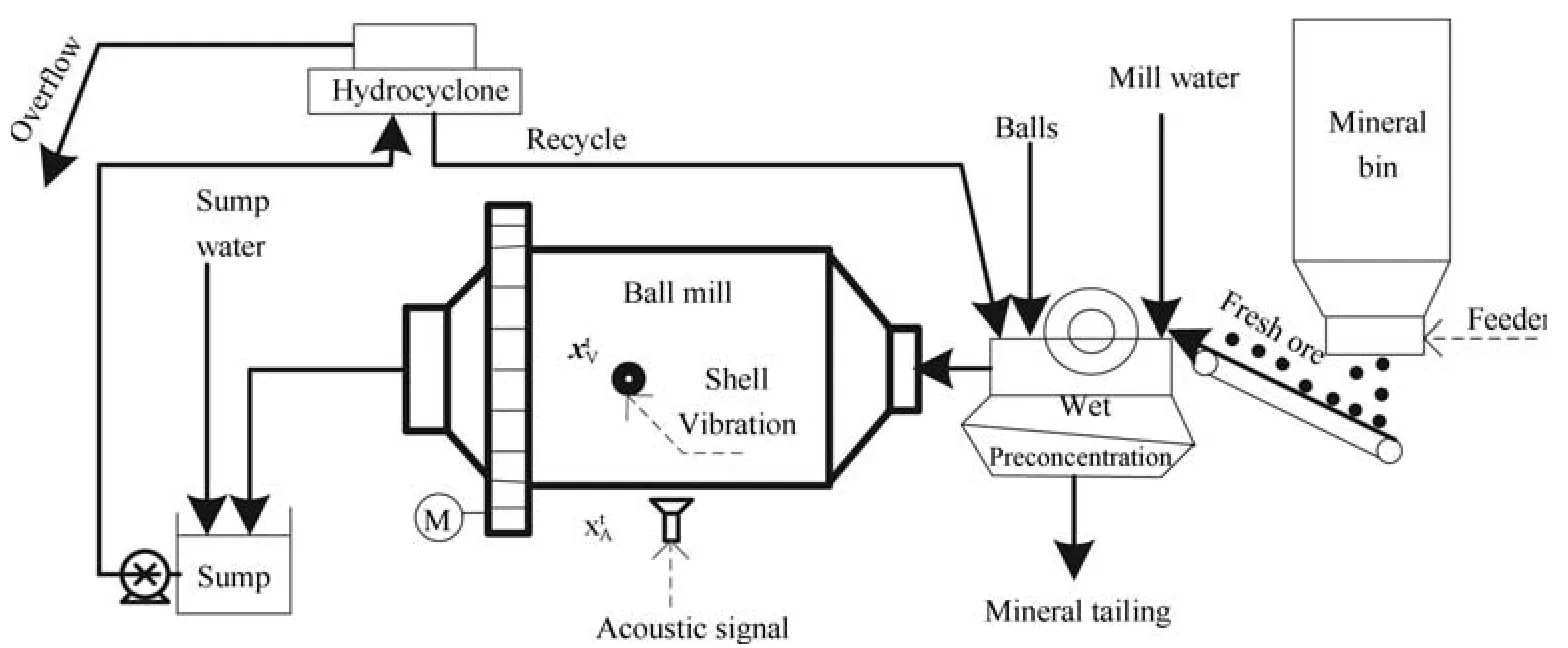
图8 某选矿厂一段磨矿回路(GC I)工艺流程Fig.8 Flow chart of the grinding circuit I(GC I)of some mineral grinding process
磨矿过程的目标是以最大化的经济效率解离和获得有价值矿物.通常情况下,磨矿过程的目标是通过设定固定的产品粒度获得最大化的磨矿生产率(Grinding production rate,GPR);最大化GPR通常是通过最优化磨矿回路负荷决定的,而后者通常由GC I的球磨机负荷确定.球磨机是磨矿过程使用的关键重型旋转机械设备,其内部料球比(Material to ball volume ratio,MBVR)、磨矿浓度(Pulp density,PD)、充填率(Charge volume ratio,CVR)等磨机负荷参数的异常变化(如MBVR过大、PD和CVR过高等)均会导致磨机过负荷.这些磨机负荷参数与磨机研磨产生的机械振动和振声信号的映射机理复杂.在时域内,有价值信息被隐含在随机噪声中,难以提取;但其频域特征较为明显.
2)实验球磨机筒体振动/振声数据采集与描述
实验在XMQL420×450球磨机上进行,其滚筒外径和长度均为460mm.该磨机由功率为2.12kW的三相电机驱动,最大钢球装载量为80kg,设计磨粉能力为10kg/小时,转速为57转/分钟.磨机中部开口,用于添加钢球、物料和水负荷.实验中采用的物料为铜矿石,直径均小于6mm,密度为4.2t/m3.采用直径30、20和15mm的钢球作为研磨介质,配比为3:4:3.磨机筒体振动和振声信号的采样频率为51200 Hz和8000Hz.
考虑到实际磨矿过程的建模和磨机负荷的控制等研究中常把24或48小时内的钢球负荷当做常量处理[6],本文进行了球负荷保持不变的4组磨机实验:第一组:料负荷为10kg,水负荷从5kg增加到40kg;第二组:料负荷为20kg,水负荷从2kg增加到20kg;第三组:水负荷为2kg,料负荷从10kg增加到20kg;第四组:水负荷为10kg,料负荷从22kg增加到50kg
4.2.2 多尺度IMF获取结果
文献[23]给出了零负荷时的筒体振动原始信号和经EMD分解为具有不同时间尺度的IMF子信号的时频曲线,结果表明:不同尺度IMF频谱代表单尺度频谱的不同部分.特别指出的是,第13个IMF子信号为4周期正弦曲线,与所处理数据包含的磨机4个旋转周期相一致;通过对频谱的幅值进行比较可知,第13个IMF的幅值至少是其他的100倍,表明磨机自身旋转引起的振动很大;第1个IMF到第15个IMF的时频特性表明,子信号的时间尺度是逐渐增大.因此,这些多尺度频谱蕴含着极为不同的磨机负荷参数信息.
本文中,选择Anoise=0.1和M=10将磨机旋转4个周期的信号进行EEMD分解,并将筒体振动和振声信号的IMF标记为振动IMF(Vibration VIMF)和振声IMF(Acoustic IMF).对全部IMF后进行HT变换,计算得到IMF边际谱.部分筒体振动和振声多尺度子信号的谱数据(VIMF1~VIMF10)如图9和图10所示.
由图9和图10可知,这些磨机筒体振动和振声信号的谱数据的时间尺度是逐渐增大的,表明了这些机械信号组成成分的复杂性和可分解特性.
4.2.3 多尺度IMF的VSG结果
采用不同的多源多尺度谱数据构造FBP模型的过程与第4.1.2节相同,此处不在赘述.
依据第4.2.1节所描述的实验过程,可知4种工况下真实训练样本的分布如表3所示.

图9 磨机筒体振动的VIMF1~10子信号的真实谱数据Fig.9 True spectra data of VIMF1~10 sub-signals from mill shell vibration signal
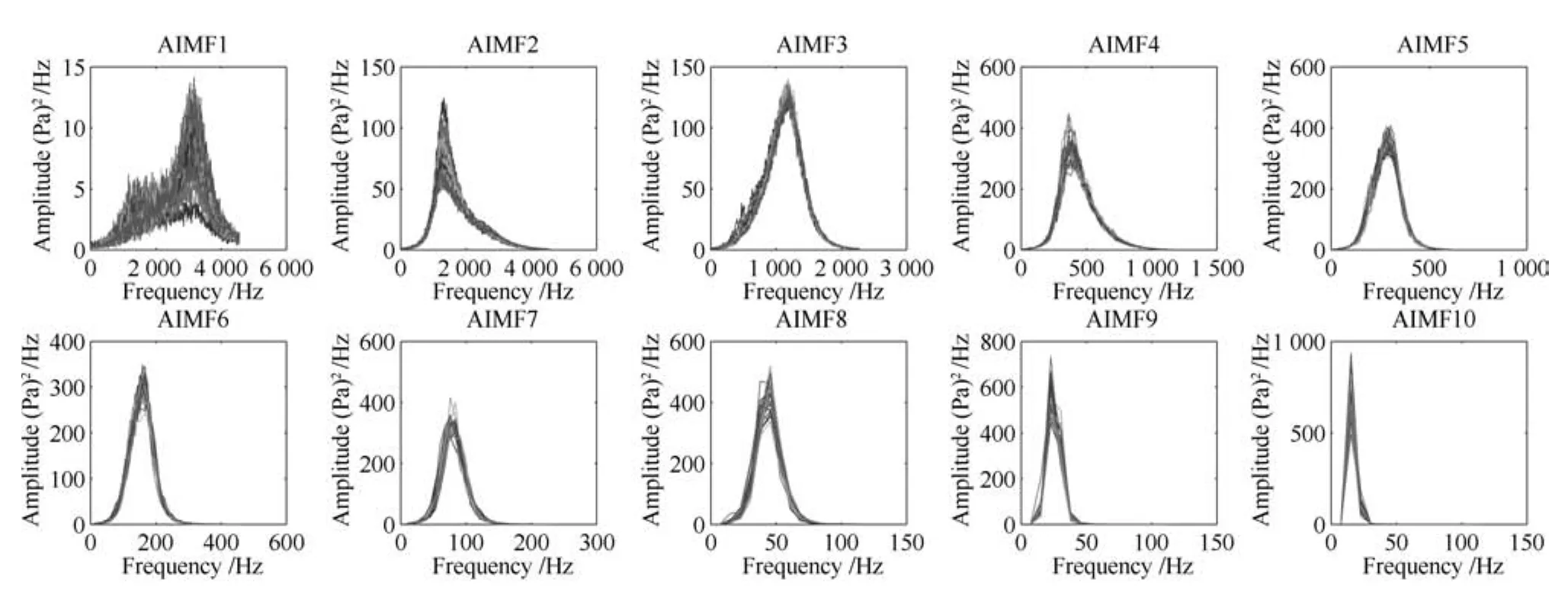
图10 磨机振声AIMF1~10子信号的真实谱数据Fig.10 True spectra data of VIMF1~10 sub-signals from mill acoustic signal

表3 用于产生虚拟样本的真实训练样本分布Table 3 Distribution of the true training samples for generating virtual samples
以表4中真实训练样本1和2为例进行说明:两个样本中的料负荷固定为10kg,而水负荷从5kg增大到15kg,因此可以构造出水负荷在5~15kg间变化的虚拟样本输入.以此类推,依据表1可知能够产生虚拟样本输入的真实训练样本对包括:No.1和No.2,No.2和No.3,No.4和No.5,No.5和No.6,No.7和No.8,No.8和No.9,No.10和No.11,No.11和No.12,No.12和No.13.当NVSG=2,3,···,10时,对应的虚拟样本的数量分别是 9,18,···,81.
依据第 3.2节所述方法,当NVSG=7时针对CVR所产生的部分虚拟样本(VIMF1~10,AIMF1~10)的输入如图11和图12所示.
由图11和12可知,所提方法可以有效地产生虚拟样本.同时,图9~12也表明了不同尺度的谱数据需要进行维数约简,并选择更有价值的IMF构建软测量模型.
4.2.4 多尺度IMF的混合样本特征选择结果
以CVR为例,采用第3.3节所述方法对混合样本进行谱特征选择,统计结果如表4所示.
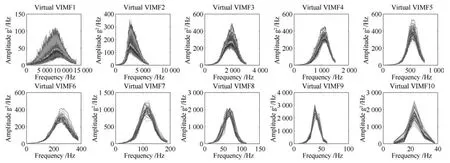
图11 磨机筒体振动VIMF1~10的虚拟谱数据Fig.11 Virtual spectra data of VIMF1~10 sub-signals from mill shell vibration signal
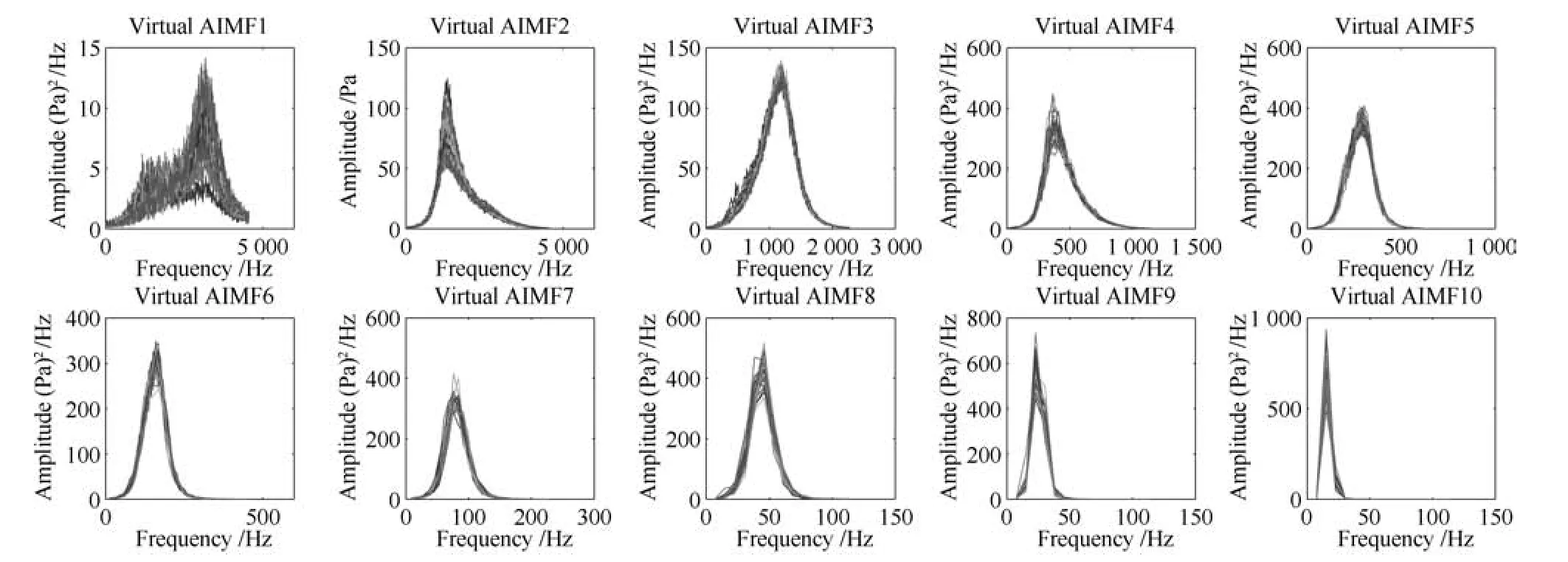
图12 磨机振声AIMF1~10的虚拟谱数据Fig.12 Virtual spectra data of AIMF1~10 sub-signals from mill acoustic signal
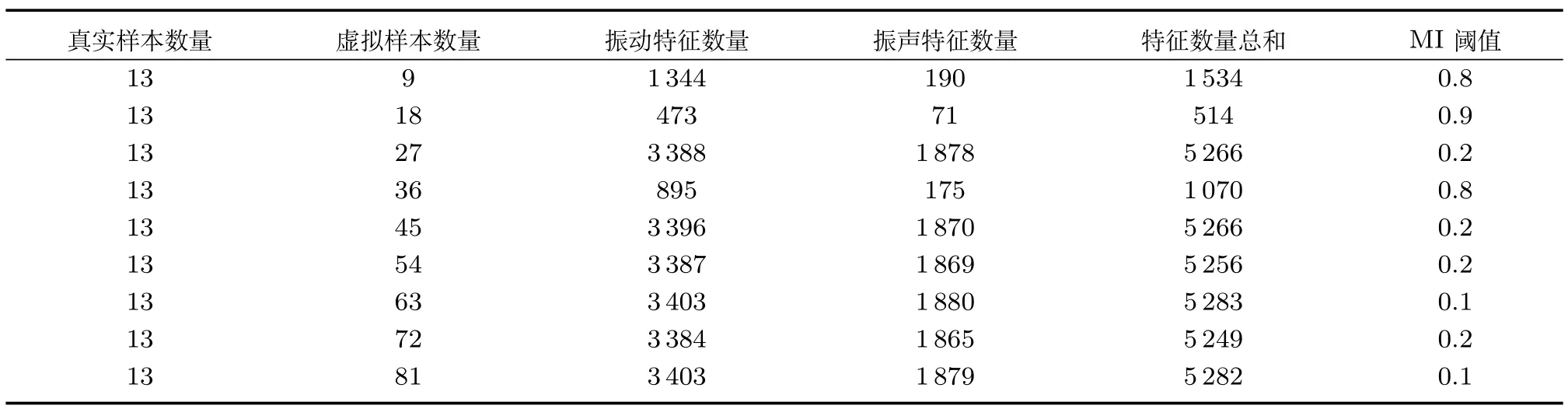
表4 面向CVR的谱特征选择的统计结果Table 4 Statistical results of spectra feature selection for CVR
表4表明:阈值与谱特征数量间的相关性较大;从AIMF选择的特征数量远小于VIMF,可能的原因除筒体振动信号的采样频率远高于声音信号外,其机理方面的原因还有待于深入的进一步分析.
4.2.5 软测量模型的性能比较结果
软测量模型的性能通常采用测试样本的RMSE进行评估.当不具备足够的大量测试样本时,训练数据也用于评估软测量模型性能.留一交叉验证、K-折交叉验证、Bootstrap及其改进等性能评估方法得到了广泛应用[72−73].针对高维小样本数据,0.632 Bootstrap和留一交叉验证评估方法可以得到较佳性能[74].
本文采用0.632 Bootstrap评估方法.假设进行了R次的Bootstrap,采用k∗r表示从训练样本抽取的样本,f∗r(·)示k∗r训练的软测量模型;定义0.632 Bootstrap的均方根相对预测误差(Root mean square relative error prediction,RMSREP)如下:
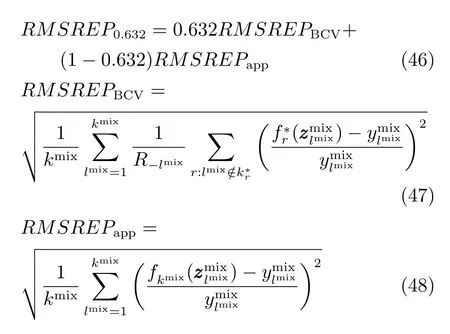
其中,r=1,···,R;R−l是不包含第lth个训练样本所抽取的样本数量;fkmix(·)表示由全部混合样本训练得到的软测量模型.
采用上述评估指标,针对文献中采用的不同方法及本文所提方法基于不同数量混合样本建立的软测量模型的统计结果如表5所示.其中:采用对原始机械振动/振声信号进行FFT变换后的单尺度频谱构建基于PLS/KPLS单模型,并作为比较的基本方法;文献[24]采用的方法表示基于单尺度频谱获得特征子集进行选择性信息融合的SEN模型;文献[20−21]是基于EMD的多尺度频谱进行选择性信息融合的SEN模型.
表5表明:
1)本文所提方法的平均预测性能随虚拟样本数量的增加而增加.本文方法在虚拟样本的数量为81时,其平均预测误差为0.1290,与文献[24]的最佳的平均预测误差0.1265接近.另外,文献[24]并未对多组分信号进行自适应分解,在提高软测量模型的可解释性和深入理解磨机研磨机理等方面弱于本文所提方法.本文方法在平均预测性能上也强于基于单尺度单模型的PLS/KPLS方法和基于多尺度频谱选择性信息融合的SENKPLS方法.
2)在所有的软测量模型中,本文所提方法具有最佳的预测稳定性,这在工业实际中具有较高的应用价值.文献[24]虽然具有预测误差性能的最小值,但该方法同时也具有预测误差的最大方差(0.0677),是本文所提建模方法的至少2倍.显然,文献[24]的预测性能的稳定性较差.本文所提方法的测试误差的方差与的关系如图13所示.
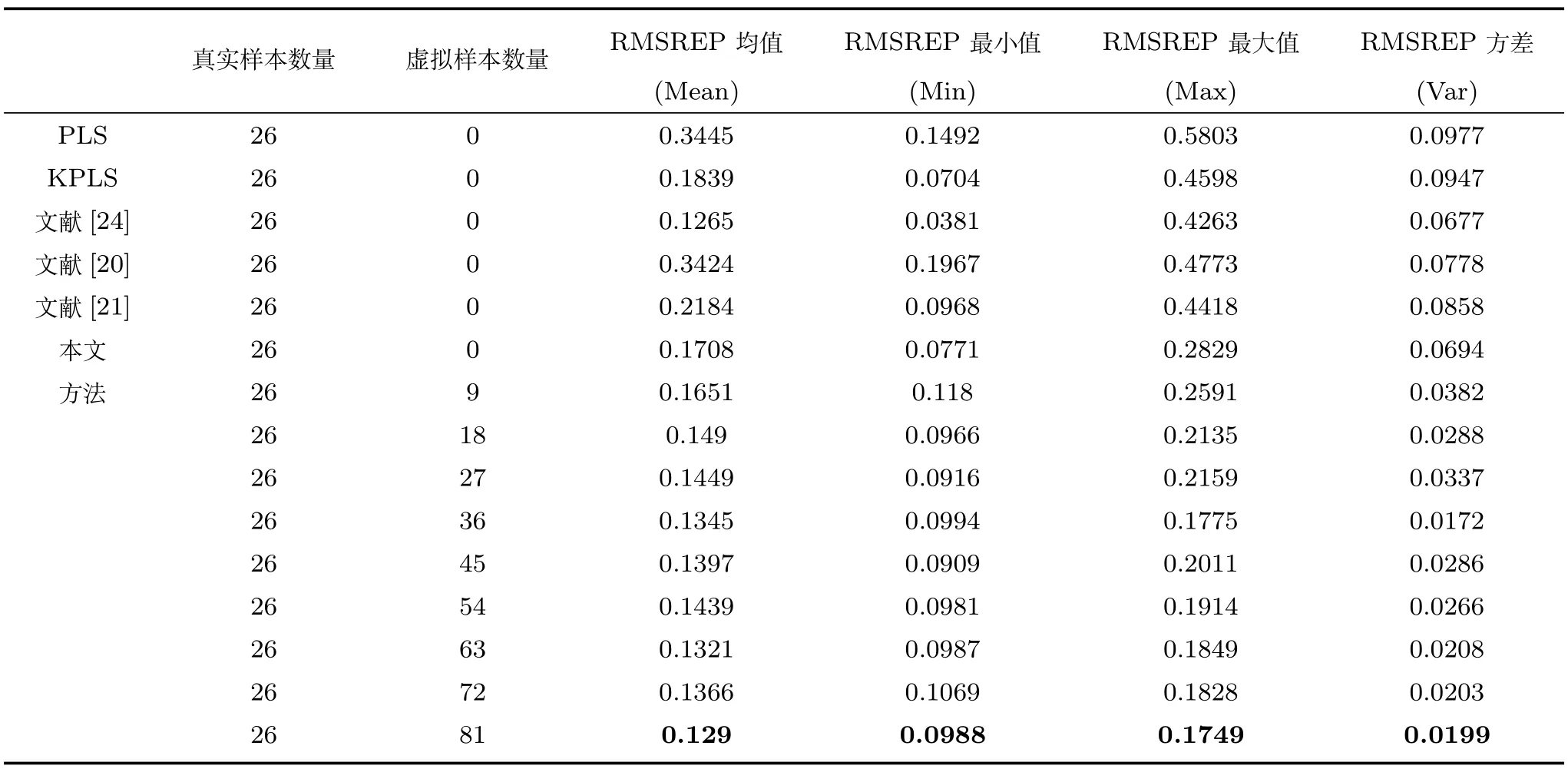
表5 基于不同数量混合样本构建的软测量模型的统计结果Table 5 Statistical results of soft sensor models based on mix samples with different number
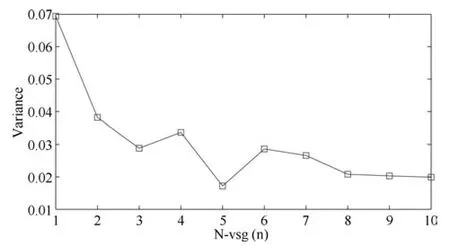
图13 基于不同NVSG值构建的软测量模型测试误差的方差Fig.13 Variance of the testing errors based on soft sensor models using differentNVSGvalues
由图13可知,本文所提方法的预测稳定性随虚拟样本数量的增加而提高.
3)本文所提方法的软测量模型预测误差的均值和最大值随着虚拟样本数量的增加而降低,如当采用81个虚拟样本时,预测误差的均值和最大值与无虚拟样本时进行比较,分别从0.1708和0.2829降低到了0.1290和0.1749.本文所提方法的测试误差与的关系如图14所示.
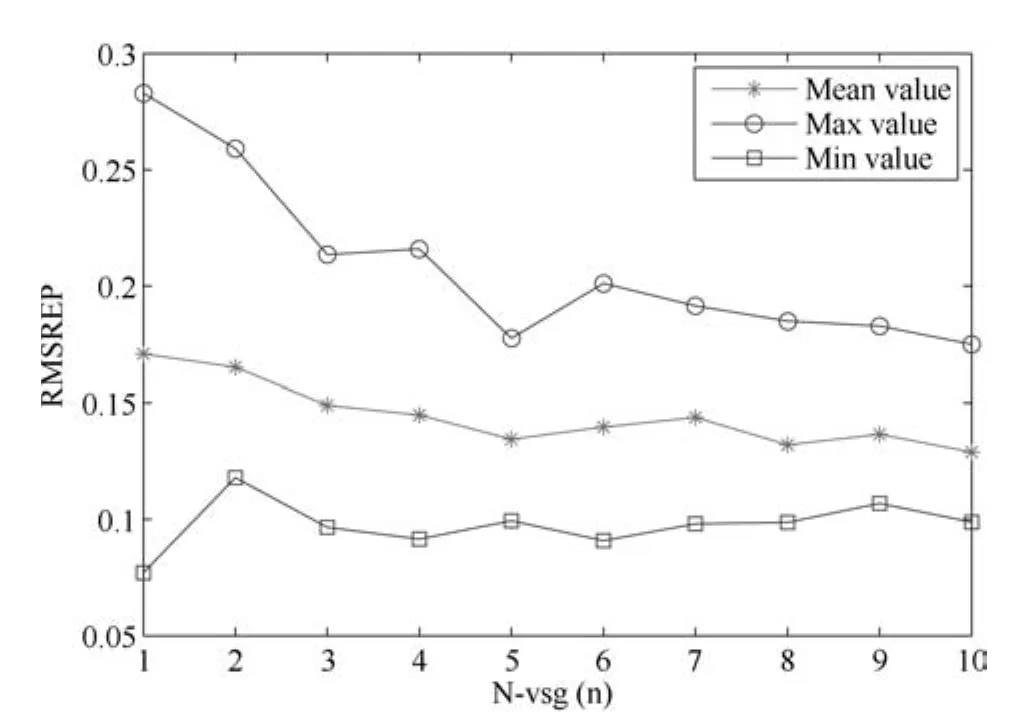
图14 基于不同NVSG值构建的软测量模型的测试误差Fig.14 Testing errors based on soft sensor models using differentNVSGvalues
显然,可依据工业实际确定较适合的虚拟样本的数量.如何从理论上指导选择合适的虚拟样本数量的研究还有待于深入进行.
综合以上分析结果可知,本文所提基于VSG的机械多组分信号建模方法可以有效提高磨机负荷参数软测量模型的可解释性和预测性能的稳定性.关于多源多尺度谱特征的具体物理含义,需要在下一步研究中结合数值仿真模型和更多实验以及运行专家知识逐步获得合理的阐释.
5 结论
本文针对流程工业中与产品质量、产量以及效率等经济指标密切相关的关键机械设备内部参数难以准确直接检测,只能依据这些设备产生的具有多组分、非平稳、非线性等特性的振动/振声信号进行间接测量,但建模样本却较为稀缺难以充足完备获取等问题,提出一种基于虚拟样本生成技术(VSG)的多组分机械信号建模方法.采用近红外谱数据和磨矿过程实验球磨机筒体振动和振声信号构建的软测量模型验证了所提VSG技术和面向多组分机械信号建模方法的合理性和有效性.
该文的主要贡献是:首次提出基于VSG结合多组分信号自适应分解的多组分机械信号软测量建模策略,使得所提方法能够贴合工业实际,其中所包含的面向小样本高维谱数据的VSG技术具有较好的普适性;综合利用了多组分信号自适应分解、基于互信息的特征选择、基于遗传算法的核潜在模型选择性集成建模等技术,可以有效地结合特征选择和样本选择策略构建软测量模型,能够有效模拟工业现场运行专家的认知机制;对构建物理阐释明确的软测量模型和有效结合复杂工业过程机械设备的虚拟人工系统进行难以检测过程参数软测量具有重要的借鉴意义.
