基于词的关联特征的中文分词方法*
2018-10-15李康康
李康康,龙 华
(昆明理工大学 信息工程与自动化学院,云南 昆明 650000)
0 引 言
中文分词是中文自然语言处理中最基本的一个步骤。对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词。但是,如何让计算机也能理解呢?处理过程就是分词算法。现在已有的计算机自动切分词算法大致可分为三类:基于理解的分词方法、基于字符串匹配的分词方法和基于传统词频统计的分词方法
基于理解的分词方法[1],是通过让计算机模拟人对句子的理解,达到识别词的效果。它在分词的同时进行句法、语义分析,利用句法信息和语义信息处理歧义现象。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
基于字符串匹配的分词方法[2],是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配。最大匹配法的优点是原理简单,易于实现;缺点是最大匹配长度不易确定,若太大则时间复杂度上升,太小则有些超过该长度的词无法匹配,降低了分词的准确率。
基于传统词频统计的分词方法[3],从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,越有可能构成一个词。因此,字与字相邻共现的频率或概率能够较好地反映成词的可信度。可以统计语料中相邻共现的各个字的组合频度,计算它们的互现信息。定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。这种方法也有一定的局限性,会经常抽出一些共现频度高但并不是词的常用字组,如“这一”“之一”“有的”“我的”“许多的”等,且对常用词的识别精度差、时空开销大。
因此,本文提供一种基于词的关联特征的中文分词方法,用以解决现有技术中无法从大规模语料中有效识别并提取词的缺陷,实现计算机系统在大规模语料中的有效识别并提取词。
1 相关概念
定义1 前后拼接词的分词方法:设字符串S={A1A2…Ai…An}{i≤n,n∈N+,N+表示自然数集}。其中,Ai表示字符串S中第i个字符,令S的子串为Si={Ai…Ai+m},依次统计出当m=1、2、3时出现的所有子串。
定义2 自由度:当一个文本片段出现在各种不同的文本集中,且具有左邻字集合和右邻字集合时(左邻字集合是指出现在文本片段左边相邻的字符的集合;右邻字集合是指出现在文本片段右边相邻的字符的集合),假如文本片段{Aij+1Aij+2}在文本集合{AijAij+1Aij+2Aij+3Aij+4Aij+4…Aij-1+nAij+n}中,则左邻字集合为{Aij},右邻字集合为{Aij+3},其中i指代文本片段集合中元素的序号,j指代构成一个文本片段的序号。通过计算左邻字集合和右邻字集合的信息熵[4]获取一个文本片段的信息熵,取左邻字集合和右邻字集合中较小信息熵作为自由度。
定义3 凝合度:是指在一个文本S={A1A2…Ai…An}{i≤n,n∈N+,N+表示自然数集}中,一个候选词词Si={Ai…Ai+m}单独出现的概率高于组合其每一部分{Ai+m}的概率的乘积,即P(S)>P(Ai)Ai+mP(Ai+m)。令,取最小的m为凝合度,其中表示一个新词,P(Si)表示一个词在文本中出现的概率,Ai和Ai+m指代组合候选词的两部分,P(Ai)和P(Ai+m)分别代表候选词每一部分在文本中出现的概率。
定义4 三元候选词的过滤方法:对于三元候选词,若后两个字符存在于二元候选词库中,判断第一个字是否与左邻接字构成一个词,若前两个字符存在于二元候选词库中,判断最后一个字是否与右邻接字构成一个词,确定三元候选词是否是三元词。若:

则(Ai-1AiAi+1)属于三元词。其中,(Ai-1AiAi+1)属于三元候选词,Ai-2是三元候选词的左邻字,Ai+2是三元候选词的右邻接字,{A0…Ai…AN}是语料库中的字符集合,{(A0,A1)…(Ai,Ai+1)…(Ai-2,Ai-1)}是二元候选词集合。
定义5 四元后选词的过滤方法:对可能成词的四元候选词,首先进行分割,前两个字为一个分词片段,后两个字为另一个分词片段,并分别对分词片段与已分好的二元词库进行匹配。成功匹配的,则作为预选词。然后,在对四元词的中间两个字进行分割,并与已分好的二元词库进行匹配。匹配不成功的,则作为预选词。如果两个条件都满足,则作为分词的结果。
2 基于词的关联特征的分词算法
2.1 算法流程图
为了便于理解和描述本文使用的算法,采用常规的流程图,如图1所示,包括11个模块,最终实现了分词效果。
2.2 改进的中文算法步骤
2.2.1 构建语料库
为了能够使改进的分词算法在效率、分词的长度限制甚至歧义处理上得到提高,必须要有一个语料库。首先需要对其进行预处理,包括去符号,然后将各个段落连接成一条语句,构建语料库[5]。

图1 算法流程
2.2.2 构建候选词库
采用前后拼接词的分词方法,对语料库进行分词,形成二元候选词库、三元候选词库和四元候选词库。假设中文文本的内容为S=A1A2…Ai…An{i≤n,n∈N+,N+表示自然数集}。其中,Ai表示为文本中的一个字符。当文本A被切分为所有{Ai,Ai+1}的组合的集合,称其为二元候选词库,其中i∈N。当文本A被切分为所有{Ai,Ai+1Ai+2}的组合的集合,称其为三元候选词库。当文本A被切分为{Ai,Ai+1Ai+2Ai+3}的组合的集合,称其为四元候选词库。
2.2.3 新词库的构建
新词库由候选词和词频组成。根据传统的统计模式,本文通过正则表达式对文本进行词频统计。定义TF为候选词的词频,TF0为词频门限。如果存在TF>TF0,则将候选词作为构建新词库的一部分;如果不满足此条件,则不考虑。
2.2.4 基于自由度和拟合度的词的判决
(1)自由度
自由度是通过计算并选择候选词左右邻字集信息熵小者得到的:

其中,H表示候选词的自由度,s´表示候选词的右熵,n表示左邻字集合元素总数。

其中,{bi|i<K}属于候选词的右邻字集,nAi表示Ai出现在候选词右边的频数,K表示候选词的右邻字集中字元素个数,s´´为候选词的左熵;

其中,{mi|i<M}属于候选词的左邻字集,nmi表示mi出现在候选词左边的频数,M表示候选词的左邻字集中字元素个数,n表示右邻字集合元素的总数。
(2)凝合度
凝合度是通过计算语料中候选词的独立概率和联合概率的比值得到,具体步骤如下。
①由候选词的概率和候选词的组合概率的比值得到两元候选词凝合度M2:

其中,M2表示候选词的凝合度,Si表示两元候选词的第一个字在语料库中出现的概率,Si+1表示两元候选词第二个字在语料库中出现的概率,p(i,i+1)表示两元候选词语在语料中出现的概率。
②由候选词的概率和候选词的组合概率的比值得到三元候选词凝合度M3:

其中,M3表示候选词的凝合度,Si表示三元候选词的第一个字在语料库中出现的概率,Si+1,Si+2表示三元候选词的后两个字同时在语料库中出现的概率,Si,i+1表示三元候选词的前两个字同时在语料库中出现的概率,Si+2表示三元候选词的最后一个字在语料库中出现的概率,P(i,i+1,i+2)表示三元候选词语在语料中出现的概率。
③由候选词的概率和候选词的组合概率的比值得到四元候选词凝合度M4:

其中,M4表示候选词的凝合度,Si表示四元候选词的第一个字在语料库中出现的概率,Si+1,Si+2,Si+3表示四元候选词的后三个字同时在语料库中出现的概率,Si,Si+1,Si+2表示四元候选词的前三个字同时在语料库中出现的概率,Si,i+1表示四元候选词的前两个字在语料库中出现的概率,Si+2,i+3表示四元候选词的后两个字在语料库中出现的概率,P(i,i+1,i+2,i+3)表示四元候选词在语料库中出现的概率。
2.2.5 采用三元和四元分词过滤方法
采用分词过滤方法对筛选出来的三元候选词和四元候选词进行进一步过滤,形成最终的词库。
3 基于特征的分词算法在对《西游记》分词中的应用
3.1 建立语料库
步骤1:利用While(sequence=br.readLine())读取语料库中的每一句。
步骤2:利用Link(Delete(sequene.contains(chat)))删除语句中的标点符号并连成一句话。部分《西游记》[6]经过文本处理的结果如图2所示。

图2 文本处理结果
3.2 构建候选词库
本文通过采用正则表达式[7],对文本进行词频统计。
(1)While((line=br.readLine())!=null)读取文本集合中的每一行;
(2)Matcher m=p.matcher(line)通过引入正则表达式对每一行进行处理;
(3)如果if(map.containsKey(data))满足正则表达式;
(4)map.put(data,count+1)加 1;
(5)重复以上步骤,分别统计文本集合中的二元候选词、三元候选词和四元候选词。判别二元候选词正则表达式为[u4e00-u9fa5]{2},判别三元候选词正则表达式为[u4e00-u9fa5]{3},判别四元候选词正则表达式为[u4e00-u9fa5]{4}。
对文本进行词频统计的部分结果,如图3所示。

图3 词频统计结果
3.3 构建新词库
定义TF为候选词的词频,TP0为词频门限,如果存在TF≤TF0,则将候选词作为构建新词库的一部分;如果不满足此条件,则不考虑。
(1)While(word=br.readline())读取候选语料库的每一行;
(2)If(TF=word.value()>TP0)大于门限值;
(3)yList.add(word),存到列表中。
统计的部分结果如图4所示。

图4 统计的部分结果
3.4 计算自由度和凝合度并进行判决
3.4.1 计算自由度实现过程及部分最后结果
(1)If(i=str,contains(sequence))在一个句子中存在候选词,将其所在位置返回i;
(2)List.add(i-1)统计与其左边相邻的字;
(3)List2.add(i+1)统计与其右边相邻的字;
(4)Sum( List.get()/Sum(List))计算其左熵;
(5)Sum(List.get()/Sum(List2))计算其右熵;
(6)Min(Sum( List.get()/Sum(List)),Sum( List.get()/Sum(List2)))。
图5为自由度部分的最后结果。
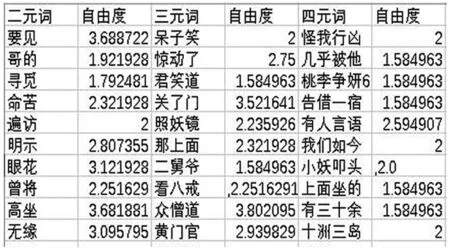
图5 自由度部分最后结果
3.4.2 计算凝合度实现过程及部分最后结果
(1)While(word=br.readline())读取新词库的每一个词;
(2)number1=count(Word.get())计算构成词的第一部分在语料库中出现的次数;
(3)number2=count(Word.other())计算构成词的另外一部分在语料库中出现的次数;
(4)number3=count(Word)计算构完整词在语料库中出现的次数;
(5)number4=count(text)计算整个语料库字符出现的个数。Min((number1/number4)/(number2/number4))/(number3/number4),计算凝合度。
图6为凝合度部分的最后结果。
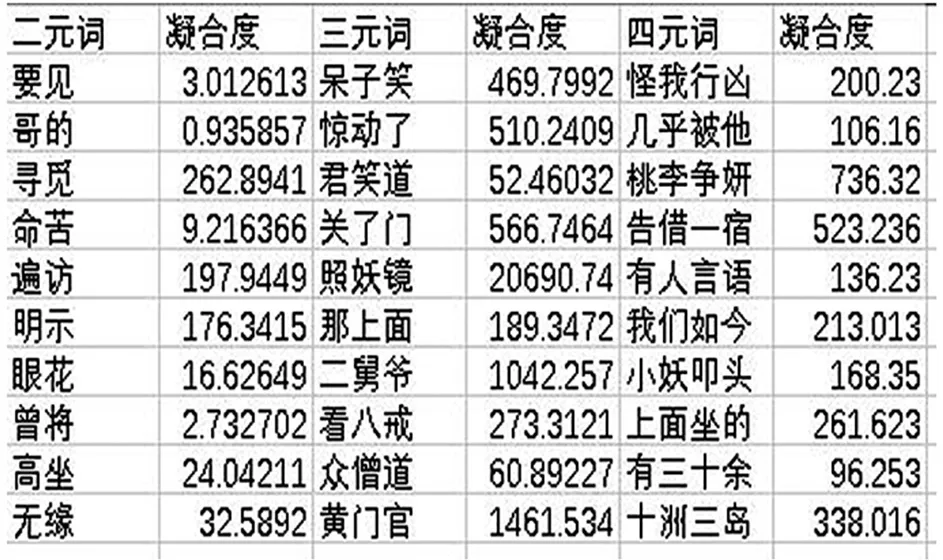
图6 凝合度部分最后结果
3.4.3 分别给自由度和凝合度一个门限,满足条件的作为新词库
自由度和凝合度的门限是动态获取的。针对不同的语料库给出的自由度和凝合度门限值是不同的,本文采用的语料库是四大名著之一《西游记》。通过多次进行实验比较,选出了效果最好的自由度和凝合度门限值。
(1)Zthreshold=10;//初始化自由度门限值Mthreshold=20;//初始化拟合度门限值
(2)If(text(Zthreshold,Mthresold).getWords())
LastText(Zthresold,Mthresold).getwords()&&words.accuracy()>lastwords.accuracy())
{Zthresold++;Mthreshold++;}//如果根据当前的自由度和凝合度的门限值所获取的词库和正确率大于前一个门限值所获取的词库和正确率,将自由度和凝合度进行自加,直至不满足条件,结束。
3.5 采用三元和四元分词过滤方法对新词库进行过滤
3.5.1 三元分词方法
(1)While(word=br.readLine())读取三元词库的每一个词;
(2)arr= Word.split(i)将三元词分成两部分,第一部分为第一个字,第二部分为末尾两个字;
(3)if(arr[1].exist(2-gram)&&arr[1]+arr[0]not word)第二部分存在二元新词库,且第一部分与其前一个字符不存在二元语料库,则判定为一个词。
3.5.2 四元分词方法
(1)While(word=br.readLine())读取四元词库的每一个词;
(2)arr=Word.split()将四元词分成两部分,第一部分为前两个字符,第二部分为后两个字符;
(3)If(arr[0].exist(2-gram)&&arr[1]exist(2-gram)&&(arr[0][2]+arr[1][1])not in 2-gram),四元词的第一部分存在于二元新词库,且第二部分也存在二元词库,但四元词的中间两个字构成的词不存在二元新词库,则将其作为新词库。
3.6 采用基于词的关联特征的分词方法所取得的分词结果
通过采用本文提出的基于词的关联特征的分词算法,对四大名著《西游记》进行了分词处理,部分结果如图7所示。
3.7 采用基于词频统计的分词方法所取得的分词结果
传统的基于词频统计的中文分词方法步骤由本文提出方法的前三步组成,所以这里不再重复。图8为基于词频统计的中文分词方法对四大名著《西游记》进行了分词后,部分分词结果。

图7 基于词的关联特征的分词方法所取得的分词结果

图8 基于词频统计的中文分词方法所取得的分词结果
4 实验结果分析
为了比较几种分词方法在中文分词中的效果,本文提出了相对准确率[8]作为比较指标。
相对准确率按照如下方法计算:
准确率=识别出的词语总数出现在标准结果中的词语数/标准结果中的词语总数×100% (8)
其中标准结果是指海量分词的结果,实验数据如表1所示。

表1 几种中文分词分词方法实验结果
从表1可以看出,文章提出的分词算法相对于基于词频统计的分词方法具有较高的相对正确率,能够在一定程上解决中文分词的问题,但是分词的准确度依然不高。因为文章提出的算法是基于大规模语料库的,即语料库规模越大,分词的准确率越高。
5 结 语
在进行中文文本分词的研究工作中,本文提出了一种基于词的关联特征的中文算法。首先计算出可能成词的文本片段的词频、自由度和凝合度,然后采用阈值过滤的方法,过滤掉不满足条件的文本片段。之后,对三元词和四元次采用过滤方法,过滤掉不可靠的三元词和四元词,以提高分词算法的正确率。
