一种基于标签谱聚类的协同过滤推荐算法研究
2018-10-15张震雷崔苹杨新凯
张震雷,崔苹,杨新凯
(上海师范大学信息与机电工程学院,上海200234)
0 引言
日新月异的互联网技术使信息爆炸式地增长。与此同时,信息过载(Information Overload)的问题日益突出,用户如何在互联网浩如烟海的资源中快速有效地获取高质量的信息就成为了亟待解决的问题。搜索引擎的出现,在一定程度上满足了用户查找信息的需求。然而,很多时候用户找不到精确的关键词来描述目标信息,无论是信息的生产者还是消费者,都需要让“信息智能地去找人”。于是,推荐系统(Recommenda⁃tion System)应运而生,近几年来该技术在电子商务、音乐视频、新闻旅游等领域均有广泛应用。但是在如今动辄数以TB的互联网环境中,数据的稀疏性和复杂性对推荐系统的精度提出了新的挑战。
1 相关研究现状
协同过滤(Collaborative Filtering)是推荐领域较为成熟的技术之一。当前,这种方法存在两个主要问题:第一,数据稀疏性致使构建近邻集合的开销增大,影响推荐的效率;第二,仅仅通过用户评分计算出的相似度精度不够,致使推荐准确度遇到瓶颈。
为了克服数据稀疏性,降低近邻搜索空间,聚类是一个不错的选择。Li等人提出了一种基于用户模糊聚类的推荐策略[1],Ren等人提出了一种基于项目聚类的协同过滤方案[2]。为了进一步缩小近邻搜索空间,Gong SJ提出了一种基于用户和物品的联合聚类协同过滤算法。这些方法在一定程度上改善了数据稀疏性,但是传统的聚类方法在数据剧增时因计算而产生的开销巨大。
针对用户相似性计算精度的问题,现有的方法往往使用人口统计学信息。但是随着用户对隐私意识的加强,系统通常无法获取足够的人口统计学信息。标签(Tag)作为组织管理信息的一种方式,已经成为大型网站的标配。Hotho等人把用户、资源、标签之间的关系作为无向三部图来研究[3];Rendle等人提出了一种基于用户-资源-标签的张量分解方法,并使用梯度下降法对该方法做出了优化[4];Reyn等人利用标签相似度,构建一种基于情景的协同过滤推荐。这些方法都考虑了标签在挖掘用户兴趣时的作用,但是忽略了最终的推荐效率。
2 基于标签谱聚类的协同过滤推荐策略
鉴于以上问题,本文从实际出发提出一种基于标签谱聚类的协同过滤推荐算法(Tag Spectral-cluster based Collaborative Filtering,TSCF)。该方法首先使用谱聚类技术把UGC标签聚合成若干簇,然后根据用户基于标签簇的信任度,把用户分成若干用户组,同时在用户组内利用基于标签的用户信任度修正用户相似度,进而改善推荐系统的整体性能。这种方法大体可以分为三大步。
2.1 标签谱聚类
UGC标签是用户产生的内容(User Generated Con⁃tent),它描述了资源的特征,又代表了用户对资源的主观感受。由于UGC标签的开放性,其一词多义会影响最终的推荐精度[5]。本文采用谱聚类(SpectralCluster)算法对UGC标签降维去噪。相较于别的聚类算法,谱聚类算法具有适应性强,计算量小,易于实现,聚类效果好等优点。本文通过对标签的个体相似度(Individu⁃al Similarity)和群体相似度(Group Similarity)线性加权后得到标签的共现相似度(Common Similarity):
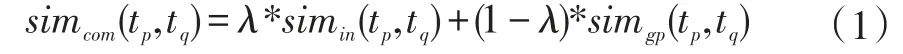
最终得到一个共现相似度矩阵[6]。
2.2 基于标签簇的用户分组
标签谱聚类之后,就得到了k个标签簇,不同的标签簇代表不同的用户兴趣。基于k个标签簇,可以把所有用户划分成k个用户组,d(ua)表示用户ua使用标签的次数,d(ua,Cj)表示用户ua使用Cj标签簇中标签的次数,故此可以定义用户ua的对标签簇Cj的兴趣度In⁃tcj(ua):

然后把Ua归入Intcj最大的用户组。当然同一用户可能对不同标签簇的偏好相同,则把该用户同时归入不同的用户组。这样,按照“人以群分”的原则就把用户划归到k个用户组中。
2.3 组内用户相似度
使用用户u,v之间基于标签的信任度来修正二者之间的相似度,修正之后如下:
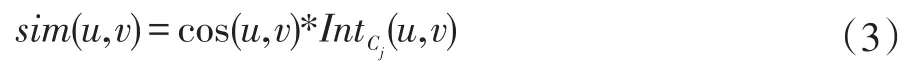
其中,cos(u,v)是协同过滤中基于用户(二值化)评分的余弦相似度,可以用式(4)来计算:
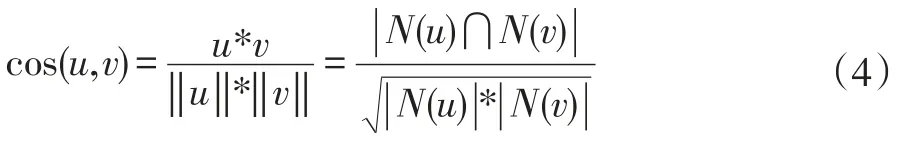
其中N(u)表示用户u评价过的物品。接着,我们可以构建目标用户ua的近邻集合,并完成top N推荐。针对同时属于多个用户组的用户,可以综合该用户在各用户组中的top N列表,票选出得分最高的物品作为推荐,这种做法在一定程度上可以提升推荐的多样性。
由于标签簇数k太大太小都会对最终的推荐结果造成影响。结合社区划分理论本文设计一个模块度函数[7],通过一次实验就可以自动确定合适的标签簇数,模块度函数定义如式(5):

其中S(Cj,Cj)表示第j个簇内的所有标签综合共现相似度之和,S(C,C)则表示相似性矩阵所有元素之和,S(Cj,C)则表示Cj簇中的所有标签到其他簇中标签的权重之和。
2.4 TSCF算法描述
改进后的算法过程如图1:
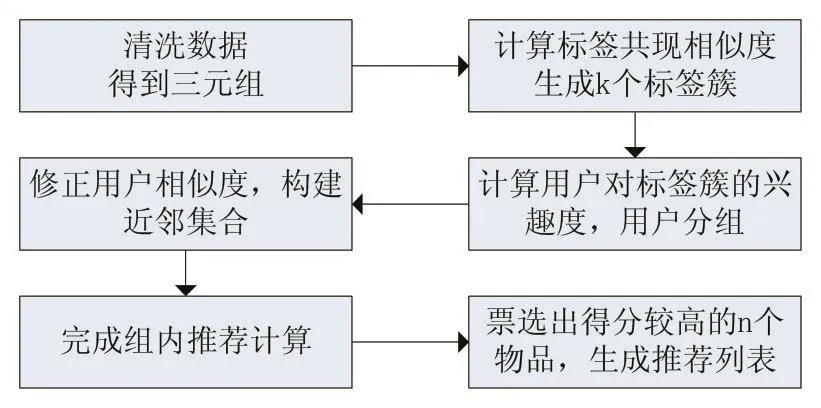
图1 改进算法流程图
3 实验及分析
本文选用ACM第五届推荐大会(RecSys2011)公布的Last.fm数据集(网址:http://recsys.acm.org/2011),这个数据集包含了1892名注册用户,17632名歌手,11946个标签以及186479个标签标注行为,此外还有12717对双向好友关系,数据较为完整,具有较高的学术科研价值。
首先剔除活跃度较低的用户以及流行度较低的歌手,过滤掉明显虚假的信息,得到一个高质量的核心数据子集,然后使用一次模块度函数,对标签谱聚类。
当k=1时,Q(k)最小,说明聚类效果最差,因为相当于没有进行聚类,这和实际相符。在Last.fm的核心数据集上,当k=2时,模块度最大,所以本文把标签聚成两簇。
为了验证TSCF算法的有效性,将与基于用户的协同过滤(UserCF)和基于用户聚类(KmeansCF)的推荐算法,从准确率、召回率、覆盖率、多样性、流行度以及计算时间等六个方面对比说明。依次取近邻集合大小为k=5,10,15,20,25,30,35,标签簇数为K=2,推荐列表长度为20。

图2 不同标签簇时的模块度值
(1)准确率和召回率
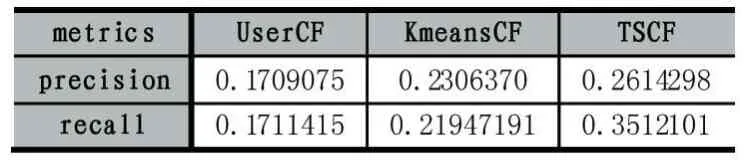
表1 准确率、召回率
由于使用了基于标签簇的用户信任度对原有用户相似度进行修正。如表1所示,本文提出的TSCF算法的准确率和召回率,相较于UserCF算法和KmeansCF算法都有了明显提升。
(2)多样性、覆盖率和平均流行度
基于标签簇对用户分组之后,有些用户有可能会被同时分到若干个组中。这与实际情况相符,标签簇描述的是用户的兴趣,而有些用户的兴趣是多样的。观察图2,可以发现,TSCF方法可以提高系统的多样性和覆盖率,相较于KmeansCF聚类,多样性提升不是非常明显。
(3)运行效率
谱聚类算法对大型稀疏矩阵划分时只需要求出前k个特征值即可,所以计算效率较为高效。由下面的time折线图可以看出,TSCF算法的效率比UserKmeans方法的效率提高了将近一倍。往往为了取得较好的聚类效果,K-means的迭代次数远远要大于上述设定的10次,由此可见,KmeansCF算法是相对耗时间的。
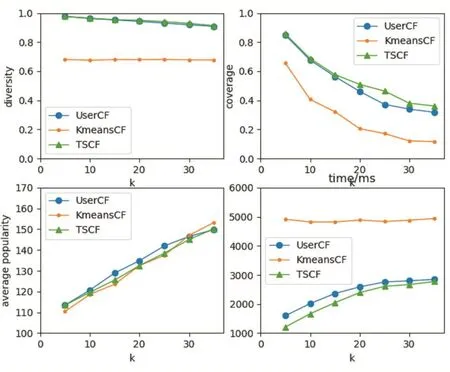
图3 多样性、覆盖率、流行度、运行时间
4 结语
本文提出了一种基于标签谱聚类的协同过滤推荐策略(TSCF)。首先,该方法结合用户UGC标签来挖掘用户兴趣,提高了推荐精度;其次,把关联度较高的用户分到同一组,在组内完成推荐,可以缩减近邻搜索空间,提升推荐效率和多样性,缓解数据稀疏性带来的弊端。最后,在仿真环境中,通过对比试验验证了TSCF推荐策略的有效性。本文下一步计划,准备在不影响推荐性能的同时,结合评价指标设计一个更为合理的评价函数,确定用户组数k。
