结合图挖掘和支持向量机的错误定位*
2018-10-12姜淑娟王兴亚
陆 凯,姜淑娟,2+,王兴亚
1.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116
2.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004
1 引言
现代工业中软件的可靠性已经越来越得到人们的重视,而为此花费的代价约占软件开发和维护成本的50%~75%[1]。自动化错误定位技术可以有效减少软件调试的时间和人力消耗,提高软件质量。
目前的软件错误定位方法按照定位过程是否需要运行软件划分为两大类,分别是基于静态分析的故障定位和基于测试的故障定位[2]。静态分析能够及早地发现和定位软件错误,减少维护成本,而且基于静态分析的方法理论知识完备,已经开发了一些商用或开源静态分析工具(如JLINT、PMD、FindBugs等)。基于测试的故障定位方法主要通过运行测试用例得到程序的执行信息,对程序的执行过程和结果进行跟踪和分析,从而进行错误定位。这类方法主要有 Tarantula方法[3]、SOBER方法[4-5]、Delta Debugging方法[6]等。通常软件错误定位的方法有3种定位精度,分别是类、方法和语句级别。上述大多数方法具有良好覆盖的测试用例,通过对测试结果和程序行为特征进行分析最终得出一个按照可疑值降序排列的语句排序结果,指导开发人员对错误进行修复。然而最终的可疑语句列表缺少相关的上下文信息,开发人员不了解其中关联性,给错误定位造成一定困难。
本文在方法粒度上,通过对一定数量的执行轨迹和执行结果进行分析,提供可能包含错误的方法集合,从而完成错误定位。本文结合机器学习,对加权的软件调用图进行研究。
2 相关工作
在软件故障定位技术中,近年来研究人员利用图挖掘技术提出了很多错误定位方法。Baah等人[7]对执行程序的控制依赖和数据依赖进行分析,在程序依赖图的基础上通过执行测试得到概率程序依赖图,从而对错误进行定位和理解。Cheng等人[8]提出了LEAP方法,该方法首先获得程序执行路径构造加权软件行为图,再通过LEAP图挖掘算法,使用信息增益作为目标函数,从所有软件行为图中挖掘出Top-K个在失败执行中频繁出现,而在正确执行中较少出现的子图,作为可疑语句序列。该方法能够挖掘出与错误相关的上下文信息,帮助开发人员定位和理解软件错误。然而存在的不足之处是软件行为图中所有控制流路径具有相同的重要程度,未考虑执行次数对软件行为图的影响。Eichinger等人[9]采用图挖掘技术,提出了一种基于权重的错误定位方法,该方法在方法级别进行错误定位,按照可疑度从高到低给出可疑方法序列,可以解决较为复杂的错误定位问题。该方法使用信息增益作为方法怀疑度排名的度量标准,但没有考虑信息增益的内在偏置,同时未考虑方法之间的关联性。Liu等人[10]应用支持向量机以封闭子图为特征对所有执行分类,并通过分类精度的变化度量方法的可疑度,最终生成一个可疑方法集合帮助开发人员判断错误位置,然而未考虑程序中频繁执行方法的影响。针对这些问题,本文利用加权的软件调用图,运用支持向量机进行错误定位。
3 技术背景
3.1 图挖掘技术
图是最常用的数据结构之一,描述事物之间的复杂关系,对其进行挖掘能够得到很多潜在信息,将图挖掘技术与错误定位结合已经成为研究热点。
频繁子图挖掘是图挖掘中一个研究热点,它是从大量的图中挖掘出一些满足给定支持度的频繁图,当一个子图在整个图集合中出现的比率满足指定的支持度,那么这个子图就是频繁子图。传统的频繁子图挖掘算法有 AGM(Apriori-based graph mining)[11]、FSG(frequent subgraph)[12]、gSpan[13]和 CloseGraph[14]。
AGM[11]和FSG[12]挖掘算法都是基于Apriori思想的频繁结构挖掘方法,AGM[11]采用宽度优先搜索(breadth first search,BFS),逐步增加节点扩展子结构逐层产生候选子图。FSG[12]改进了AGM[11]每次添加边加强剪枝,采取优化措施计算支持度,提高执行效率。然而这两种挖掘算法系统开销大,不够灵活。
gSpan[13]和CloseGraph[14]都是基于模式增长的频繁结构挖掘算法,采用深度优先搜索策略,逐步生成扩展图,与gSpan[13]算法相比,CloseGraph[14]算法减少了不必要的子图生成,避免了子图同构,挖掘出封闭子图,有效减少冗余,效率更高。
3.2 支持向量机
支持向量机(SVM)是AT&TBell实验室的Vapnik等人提出的一种全新机器学习算法。到目前为止,支持向量机广泛应用于性别分类、基因分类、数据挖掘、非线性系统控制等各个领域的实际问题中。
SVM的主要思想是针对两类分类问题,把训练数据集非线性映射到一个高维特征空间,随后在特征空间寻找一个最优分隔超平面。在线性可分的情况下,存在一个或多个超平面使得训练样本完全分开,SVM的目标是找到其中的最优超平面,最优超平面是使得每一类数据与超平面距离最近的向量与超平面之间的距离最大的平面。
支持向量机能够对有限样本进行分类,将其与错误定位结合提出一种错误定位方法有一定的研究意义。
4 本文方法
4.1 方法概述
为待测程序插桩,运行相应测试用例监控程序执行,获取正确和错误用例的执行轨迹,将其作为下一步错误定位的基础。本文方法框架如图1所示。
(1)加权行为图构建。将收集的程序执行轨迹建模成程序调用关系图,对初始调用图集合进行约简,得到加权调用图集合。
(2)封闭子图挖掘。对调用图集合进行封闭子图挖掘,提取封闭子图或者频繁边作为特征,记录每个调用图包含的频繁边信息。
(3)以频繁边或封闭子图作为特征,训练建立支持向量机对所有执行分类,记录每个方法的分类结果。
(4)分析分类结果,当加入某个方法精度明显提升时把该方法加入可疑方法集合。
(5)将可疑方法集合提供给开发人员判断错误位置并修复。
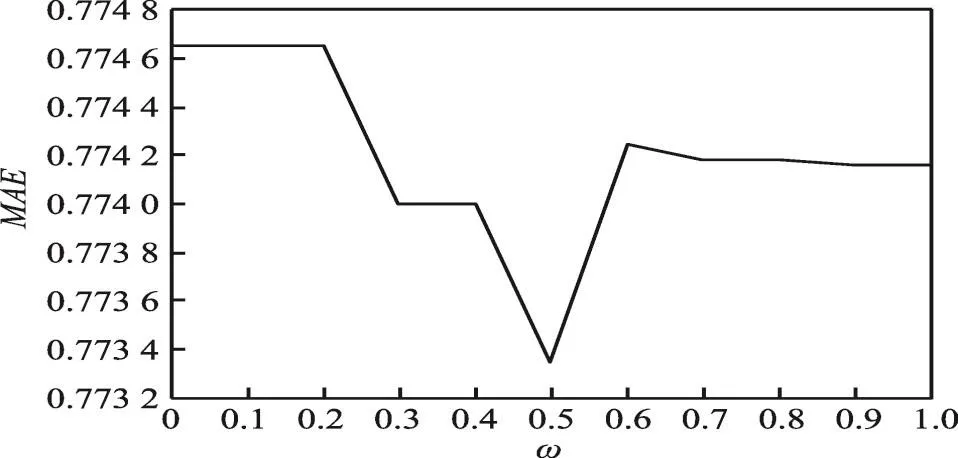
Fig.1 Framework of fault localization of combining graph mining and SVM图1 结合图挖掘和支持向量机的错误定位框架
4.2 加权行为图构建
本文首先实现方法级别的程序插桩,跟踪执行程序中方法的执行信息,通过获取程序的执行路径得到进行图挖掘的原始图集合,对图集合进行约简去除冗余的数据,然后在图集合中挖掘封闭子图提取频繁边,为下一步以频繁边为特征训练SVM分类器做准备。最初得到的软件调用图只包含了方法的调用信息,而忽视了程序执行的统计信息,因而在此基础上,需要约简图集合,将无权的图转化为带权值的图。Liu等人[10]采用了总约简方法,删去了图的所有重边,使得整个图更加简单,然而忽略了方法的调用次数,对图压缩过于严重,失去了大量信息。Di Fatta等人[15]提出了无序迭代约简方法,保留了多次执行的图的子结构,与总约简方法相比包含了更多的信息,但会出现图重构,图的尺寸也更加庞大。Eichinger等人[16]提出了子树约简方法,只保留图中一个执行的子结构,在边上记录相同的同构子结构调用次数作为权值,将无权图转化为带权图,与无序迭代约简相比,得到的图尺寸更小。综上所述本文采用子树约简方法对图集合进行约简,获得更加简洁的带权值的调用图。
子树约简方法采用的策略是自底向上逐层约简该层的相同边,如算法1所示,该算法以未约简的n层调用图为输入,以约简后的调用图作为输出。该算法主要分两步:第1步,删除该层重边,仅仅保留一条边,同时将重边的数目作为边的权值。当某一条边的数目只有一条时,该边的权值设为1。第2步,对边进行约简的同时,删除相同的子节点。不断重复直到约简到顶层。图2为子树约简方法的实例,(a)为未约简图,(b)为子树约简后的图。
算法1子树约简算法
输入:n层调用图。
输出:加权调用图。
1.for level=n-1to 1 do
2.for each node in level do
3. merge all identical child-suntrees of node,sum up corresponding edge weights
4.end for
5.end for
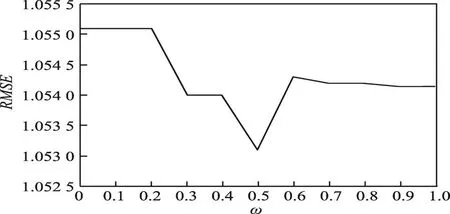
Fig.2 Subtree reduction example图2 子树约简实例
4.3 封闭子图挖掘
对于大型的程序,将调用图约简之后,程序行为图仍具有较大的规模,难以对这些边进行逐一计算和分析,并且存在一些边代表的方法没有考虑价值。通常情况下,仅考虑在所有的图中出现次数较多的边,因此有必要对图集合进行特征选择,取出出现次数较高的边进行分析,错误往往包含在这些边中。
频繁子图挖掘是从图集合中挖掘满足支持度的频繁图,存在多种频繁子图挖掘算法[11-14],考虑到CloseGraph[14]挖掘效率高且避免了子图同构,本文选择CloseGraph[14]进行子图挖掘,CloseGraph[14]算法以DFS编码、图集合和最小支持度为输入,以封闭子图集合为输出。该算法主要分为3步:第1步,生成一个频繁子图。第2步,封闭子图判断。根据是否存在与生成子图有相同支持度的超图检查第1步生成子图是否为封闭子图。第3步,剪枝扩展。检查提前终止的条件和任何可能导致提前终止失败的情况,依此决定是否扩展生成子图。如算法2所示。
算法2CloseGraph
输入:A DFS codes,its parent’sp,a graph datasetD,andmin_sup.
输出:The closed frequent graph setS.
1.ifs≠min(s),then
2.return;
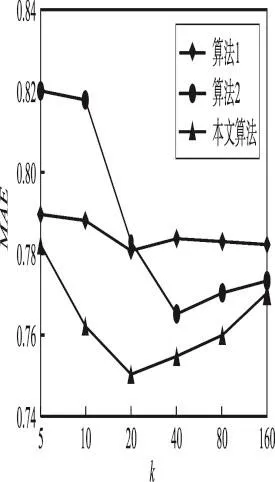
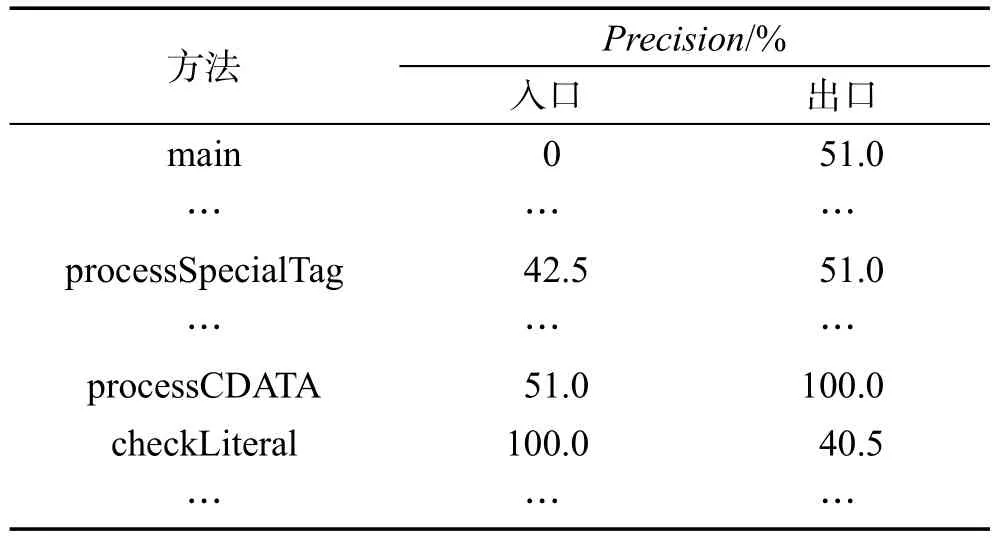
3.if ∃e′,g′=gp◊xe′andg′ 4.return; 5.setC=Null 6.ScanDonce,finding every edgeesuch thatscan be extended to frequents◊xe;Inserts◊xeintoC; 7.detect any possible failure of early termination ins; 8.if¬∃s◊xe∈C,support(s)support(s◊xe)then; 9.insertsintoS; 10.removes◊xefromCwhich cannot be right-most extended forms; 11.sortCin DFS lexicographic order; 12.for eachs◊reinCdo 13.CloseGraph(s◊re,s,D,min_sup,S) 14.return 在封闭子图挖掘时,由于图集合中图都带有权重,而在不同的图中如果一条边拥有不同的权值,则会被认为是不同边,得到大量的频繁子图。因此在进行挖掘时排除权值的干扰,挖掘出最大的频繁子图,得到频繁边。得到频繁边之后将其对应到每一个调用图中,每个调用图代表一次程序执行。通过表格记录挖掘到的所有频繁边,依此训练以频繁边为特征的支持向量机,如表1所示。 Table 1 Frequent sides record table表1 频繁边记录表 表1记录了封闭子图挖掘得到的频繁边信息,第1列是每次程序执行构建的程序行为图,最后1列是该次执行所属的分类,用Class表示。其余列是封闭子图具有的频繁边,对应的值为该频繁边代表的方法执行的次数。 支持向量机是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析。本文利用SVM对拥有标签的调用图进行分类,当程序中某个方法执行后,分类器对错误执行和正确执行的分类精度提升很大,这个方法就属于可疑方法,可能与错误相关。基于这个原理,在方法的返回处训练一个分类器,检测分类精度。分类步骤主要分为3步:(1)从调用图集合中提取特征;(2)使用特征训练SVM分类器;(3)对调用图进行分类。 为了在调用图分类中使用SVM,把所有调用图转化为特征向量,一般以频繁边或封闭子图作为特征,每个调用图作为特征向量。向量有0、1这两个值,如果一个调用图包含某个特征,那么该位的值为1,否则为0。 Liu等人[10]提出了利用SVM分类的方法,以封闭子图为特征,对所有执行进行分类,当获得越来越多的执行信息时,分类的精度不会减小,特别当执行包含错误的程序后,分类的精度会提升。如图3所示。 程序中方法A、B、C按照顺序执行,方法B中包含错误,在方法A的返回处训练分类器A,对正确执行和失败执行进行分类,此时分类精度不会有大的变化。在方法B的返回处训练分类器B,对正确执行和失败执行进行分类,因为执行了包含错误的方法B,所以分类器B分类的精度比分类器A得到的精度高,因为分类精度提升,所以错误更加可能在方法B中。 Fig.3 Classification principle图3 分类原理 因此,对程序中的所有方法,在方法的入口和出口设置监测点,利用上文提出的分类方法在每个监测点训练分类器,记录每个监测点的分类精度。当某个方法使得精度明显提升时,将这个方法加入错误相关方法的集合,把整个集合提供给开发人员进行错误定位和修复。本文以频繁边为特征建立支持向量机,对所有执行分类获取精度对其分析,从而进行错误定位。 本文采用NanoXML数据集作为测试数据,NanoXML是一个包括7646行代码的XML文件解析器,包括V0至V5共6个不同的版本,实验使用V5版本。同时在该版本中每次植入一个错误,这些错误由software-artifact infrastructure repository(SIR)提供,本文从总共9个错误中选择4个不同类型与实际贴切的错误植入,如表2所示。 为了验证本文方法的有效性,以将封闭子图作为特征分类后的结果作为实验对比对象。NanoXML包含了141个测试用例,由于相似的输入可能会得出相同的程序调用图,为了保证分类效果,本文去除了图集合中重复的程序调用图,对删去重复调用图的图集合进行图挖掘获取封闭子图。 实验使用LibSVM[17]进行分类,由于其具有简单易使用,且快速高效的特点,广泛用于解决通用的分类问题。在进行分类时,实验选择使用频繁边和封闭子图作为特征,然后训练支持向量机进行分类,最终得到各个方法的精度。实验的运行环境是CPU Intel®Duo 2-Core 2.94 GHz;内存 2 GB;Windows 732位操作系统。 Table 2 Description of implanted faults表2 植入错误说明 Fig.4 Classification accuracy comparison of single fault图4 单个错误分类精度比较 实验采用查准率(Precision)和查全率(Recall)评价将频繁边与封闭子图作为特征,训练支持向量机进行分类的结果。Recall表示被正确分类的错误执行的比率,Precision表示被分类的错误执行是真正的错误执行的比率。查全率越高,遗漏不正确执行的概率越低,查准率越高,正确率就越高。高查全率和高查准率表示该分类特征区分正确执行和错误执行的能力越强。 本文使用频繁边作为特征训练支持向量机进行分类,与已有的使用封闭子图作为特征训练支持向量机进行分类的方法进行对比。实验设置进行5次交叉验证,并用折线图将每个方法的分类结果表示出来。在折线图中,某个方法的查全率和查准率越高,越趋于右上方,分类效果越好。 图4给出了f1、f2和f4使用本文方法将频繁边作为特征和已有方法将封闭子图作为特征的分类结果折线图。对于f1,大多数方法使用频繁边作为特征分类后的精度与使用封闭子图作为特征分类的精度相同,甚至提高了精度,查全率和查准率都有提升。对于f2,使用两种特征取得的结果相似,只有单个方法的精度变高,其他相同。f2与f3的结果相似,使用频繁边与封闭子图作为特征取得了相同的结果,只有单个方法的精度改变。对于f4,大多数方法使用频繁边作为特征分类后的精度都有提升或不变。 图4表明了与已有的使用封闭子图作为特征分类的方法相比,使用频繁边作为特征进行分类取得效果多数情况下都优于使用封闭子图作为特征分类,而且查全率和查准率都有提升,这表明使用频繁边作为特征比封闭子图更能提高分类质量,提升精度。 运行时间消耗主要是封闭子图挖掘和训练SVM。提取频繁边和封闭子图作为特征需要对图集合进行封闭子图挖掘,本文使用的图挖掘算法总时间复杂度为O(2n×2n)。由于频繁边从封闭子图中提取,因此本文方法与已有方法进行图挖掘时间消耗相同。SVM时间复杂度与训练样本和向量维数有关。在训练时间上,使用频繁边作为特征的向量维数比封闭子图特征多,因此训练时间略多于已有方法,但本文方法与已有方法训练时间消耗均在0.1 s内。 分类完成后利用上文提出的方法进行错误定位,以f2为例,以一张表记录所有方法出口与入口的分类精度,如表3所示。 Table 3 f2method classification accuracy表3 f2方法分类精度 从表3中可以看出main方法、processSpecialTag方法和processCDATA方法的分类精度明显提高,依此认为是可疑方法,最终将这些可疑方法提交开发人员进行错误定位和修复。由于main是程序的入口,main方法进行分类时包含了所有的执行信息,因此main方法始终与错误相关。源程序执行时所有失败执行都执行了processCDATA方法。源程序执行完processCDATA方法后执行checkLiteral方法,checkLiteral方法的精度会降低说明分类包含了正确的执行,由于这些方法在程序中有一定的执行顺序,因此能够提供上下文信息,更加利于开发人员找到错误所在并修复。 虽然实验结果表明本文方法在以上4种错误中均取得了较好的结果,但是不能表明本文方法对所有程序错误都有效。本文方法利用图挖掘和支持向量机以频繁边为特征对所有执行分类,最终得到可疑方法集合帮助开发人员判断错误位置,给出了上下文信息。然而本文只是提供了可疑方法集合,不能很快定位错误位置,仍然需要开发人员花费精力查看源代码判断错误位置对其修复。本文方法涉及程序插桩,仍需要人工参与。 本文结合数据挖掘和机器学习技术,改进了基于图挖掘和支持向量机的软件错误定位方法,以对程序方法调用图分类的方式进行故障定位,通过实验表明了本文方法的有效性。 未来如何将该方法运用到更大型的程序上,如何与其他软件错误定位方法结合以及如何在不同粒度上实现本文方法都值得进一步研究。
4.4 运用支持向量机错误定位
5 实验
5.1 实验建立

5.2 评价标准
5.3 实验结果分析
5.4 讨论
6 结束语
