RStore:基于BigTable的关系数据模型存储系统*
2018-10-12鲁鹏凯江大伟寿黎但
鲁鹏凯,江大伟,陈 珂,寿黎但,陈 刚
浙江大学 计算机科学与技术学院,杭州 310027
1 引言
随着互联网、移动互联网、物联网应用的普及,人们正在以前所未有的速度产生大数据[1-2]。互联网数据中心(Internet Data Center,IDC)的研究显示,2011年全球共产生1800 EB数据,且每年产生的数据量还在以60%的速度增长,到2020年,全球每年将产生35 ZB数据[2]。大数据为数据管理技术带来了数据量大、数据产生速度快、数据类型复杂三重挑战。
为应对大数据所带来的挑战,更好地支持大数据应用开发,近年来,工业界和学术界掀起了一股研发新型大数据管理系统的热潮。理想的大数据管理系统应该支持两个重要特性:(1)快速应用开发。大数据管理系统应能允许应用开发人员仅使用业务数据的逻辑数据模型就可以开发大数据应用,而无须关心大数据的实际物理存储结构、索引结构等实现细节。(2)高伸缩及高效数据存取。大数据管理系统必须具有极高的系统伸缩性和高速的数据存取能力,以满足大数据应用的对大数据访问实时性的需求。
然而,目前主流的两种大数据管理系统(关系数据库系统和NoSQL数据库系统)都未能同时满足上述两个需求。关系数据库采用关系数据模型作为应用开发接口[3-4]。开发人员只需将业务数据建模为由行和列组成的二维表格,并将需要快速检索的列申明为索引列,就可以开发应用。数据的物理存储和索引结构由系统自动完成,无需应用开发人员干预。因此,关系数据库系统支持快速应用开发。不幸的是,越来越多的实践表明关系数据库在系统伸缩性和数据存储性能方面不能满足大数据应用的要求[5]。原因主要有两条:首先,关系数据库普遍采用集中式架构和主从式架构。该架构只允许垂直扩容,即通过升级单台计算机的处理能力来处理更大规模的数据集。垂直扩容的代价高昂,无法在有限的经济条件下满足大数据应用对不断增长的大数据的处理需求。其次,关系数据库系统采用范式模型来存储数据。单一实体的信息可能被分散到多个物理表格中存储。例如,在TPC-C数据模式中,一条客户订单的信息就分散存储在Order、OrderLine、Item 3张表中。范式模型的优点是数据无冗余,但是当需要检索记录时,需要进行表格连接操作,因此检索性能低下。
为解决关系数据库系统在系统伸缩性和数据存取性能方面的问题,谷歌公司开发出BigTable数据库[6]。BigTable从两方面做出改进。首先,使用计算机集群架构替代集中式结构和主从架构,集群中的任何一台机器都可以提供数据存取服务。因此,Big-Table可以进行水平扩容,即通过增加集群节点(而非升级单个节点)的方式处理更大的数据集。与垂直扩容相比,水平扩容在有限的经济条件下,极大地增强了系统的伸缩性。其次,BigTable完全放弃了关系数据模型,引入BigTable数据模型。该数据模型的特点是允许应用开发人员精确地控制数据的存储结构。使用BigTable,应用开发人员可以通过特定的数据存储格式设计,将单一实体的全部信息存储在单一表格的单一行下,从而消除数据检索时的表格连接操作。虽然BigTable提供了优越的数据存取性能,但是性能的提升是以开发人员设计出高效的数据存储格式为前提。当开发复杂的应用时,数据存储格式的优化过程往往花费开发人员大量心力,降低了开发效率[7-8]。
综上所述,关系数据库支持快捷的开发体验,但是性能不佳。BigTable支持高效数据存取,但开发效率不高。因此,主流的两种大数据管理系统都未能同时提供大数据应用开发所需的快速应用开发和高效数据存取这两项需求。
为解决主流大数据管理系统中存在的问题,本文提出RBase大数据管理系统。RBase系统的基本思想是在BigTable系统的基础上提供一个关系数据模型编程接口。应用开发人员使用关系数据模型开发大数据应用,RBase系统选择数据存储格式和索引结构,并将数据存入BigTable,从而达到同时提供快速应用开发和高效数据存取的双重目标。RBase系统结构如图1所示,包含以下模块:SQL解析器负责解析SQL语句,元数据管理器管理元数据,事务管理器负责事务处理,查询处理器处理SQL SELECT查询,RStore关系数据存储系统负责索引关系元组,并将其存入BigTable。由于篇幅所限,本文只介绍RStore关系数据存储系统的设计与实现。事务管理器和查询处理器将在后续的文章中详细讨论。RStore系统的主要贡献点如下:
(1)提出了一种基表存储结构,将关系数据库中的所有表格存储在同一张BigTable中,提供基于主键的数据存取。
Fig.1 RBase architecture图1 RBase架构
(2)提出了跨表索引结构,将与基表元组存在引用关系的外表元组索引在该元组的列键下,消除了多表查询时的连接操作。
2 BigTable数据库系统简介
BigTable是一个分布式稀疏多维键值数据库。与传统的一维键值数据库系统(如BerkeleyDB)不同,BigTable的键有3个维度:行键(row key)、列键(column key)、时间戳(row:string,column:string,time:int64)→string。
共享相同行键的键值对组成一行,行内的列组成列族。整个数据库按照行键、列键、时间戳的顺序排序。表1显示一个存储网页的BigTable。BigTable支持用行键、列键两种方式查找值。给定行键范围,BigTable可以返回所有满足行键搜索条件的值。给定单一行键以及列键范围,BigTable可以返回该行内所有满足列键搜索条件的值。与关系数据模型和一维键值对数据模型相比较,BigTable提供的多维键值数据模型在搜索机制上更为灵活、高效。每个列族(理论上)可以包含无限多个列。用户可以在运行时动态地向列族中添加和删除列。

Table 1 BigTable for storing Web data表1 存储网页数据的BigTable
3 RStore关系数据模型存储系统
RStore是RBase大数据管理系统的存储模块。给定如图2所示的TPC-C关系数据模式,RStore将符合该数据模式的关系元组存储于BigTable中,向上层的事务管理器和查询处理器提供高效元组存取服务。RStore由Java开发,建立在BigTable的开源实现HBase之上[9-10]。本章以TPC-C数据模式为例,详细介绍RStore的设计与实现细节。
对于上层应用,RBase支持关系编程范式。应用开发前,用户使用标准的SQL DDL语句声明业务数据的表格结构。建立一个TPC-C数据库和Customer表,分别用CREATE DATABASE tpcc以及CREATE TABLE tpcc.customer(
Fig.2 TPC-C entity relationship diagram图2 TPC-C中的实体关系图
3.1 基表存储结构
在系统实现上,RStore根据用户提供的表格定义和查询申明,将数据存入BigTable中。RStore提供两种数据存取策略:(1)基表存储结构;(2)跨表查询索引。
在基表存储结构中,RStore将基表中的每一条元组存为BigTable中的一行,并将主键编码进BigTable的行键,为应用提供基于主键的高效数据存取。在跨表查询索引中,RStore根据主外键约束关系,将与基表元组存在引用关系的外表元组索引至该元组的列键下,利用BigTable的列键搜索机制,提供跨表元组存取。
基表在BigTable中的存储结构如表2所示。每一条元组存为一行。其中,DataFamily存储主键之外的其他属性数据,IndexFamily存储该元组的跨表查询索引。整个元组由行键(row key)索引,行键编码表名和主键(即,
给定表3中的TPC-C Customer关系表实例,该表在BigTable中的存储结构如表4所示。其中,“Customer:001”为001号元组的行键,编码关系表名与主键值(以冒号分隔)。DataFamily列族下有3列,列名为 CustomerName、CustomerPhone 和 CustomerCredit。列名采取关系表名加属性名的格式,列中分别存储关系表中对应的属性数据。这条记录的外键数据被存储在IndexFamily列族下,列名的格式为“该条记录所属关系表名连接该条记录的主键值-该条记录中外键引用的属性所属关系表名连接该条记录中引用的属性值”,列中存储单个字母S或者B。当插入第一条包含外键关系的数据时,元数据管理器会记录下“Customer-District”作为索引的元数据信息,以提高系统检查数据库中是否已经存在对应索引的速度。查询时,用户使用标准SQL SELECT语言,RStore根据关系表和BigTable之间的结构映射,从BigTable中检索指定数据。

Table 2 BigTable data layout表2 BigTable的数据布局

Table 3 TPC-C Cusomer relational table表3 关系模型下的TPC-C Customer表
3.2 跨表查询索引
上节提出的基表存储结构能够满足应用在单个基表上基于主键的高效数据存取。然而,实际的应用往往涉及多表查询。经典的关系数据库管理系统采用表格连接操作处理多表查询,但表格连接操作代价高昂,无法满足大数据应用对数据访问性能的要求。RStore提供跨表查询索引机制,消除多表查询所需的连接操作。OLTP应用中,多表查询具有以下模式:查询涉及的多表格元组之间存在主外键约束所表示的“一对多”或者“多对多”关系,且查询总是从一个基表的元组开始,逐步扩散至其他表格元组。例如,搜索客户001最近购买的10件商品。该查询涉及Customer、Order、OrderLine、Item 4张表。查询从Customer表格出发,首先搜索001用户的信息,然后根据主外键关系搜索其他表格直至找到全部元组RStore利用OLTP应用的上述数据访问模式,将与起始基表元组(示例中001号客户)存在引用关系的外表元组索引至该元组(即,001元组)的列键下,从而消除了查询处理中表格连接。RStore中,应用开发人员可以使用CREATE INDEX q1idx Customer,on Order,OrderLine,Item from customer in tpcc来建立一个跨表查询索引。缺省情况下,RStore只将外表中的主键索引至基表元组中,如果开发人员希望索引更多的外表属性,可以将所需属性置于表格名称后的可选属性列表中。

Table 4 TPC-C Customer record in BigTable data model表4 BigTable数据模型下的TPC-C Customer记录
TPC-C的模型中District和Customer是一对具有一对多关系的实体,在每个街区中住着许多客户。在关系型数据库中,用Customer表存储客户的信息,用District表存储街区的信息。再在Customer表中添加一列,用来存储街区数据记录的主键,代表这两个实体间一对多的关系。TPC-C数据库中的District表和Customer表如表5所示。
表6展示了将表5中District和Customer记录由RStore处理后存入BigTable中的数据布局。BigTable中Customer记录里索引列族下作为索引的列名如前文介绍,是在插入该条数据时,由系统将记录中外键的值按照“表名连接上主键值-外键所在表名连接上外键值”的格式作为列名插入到列族索引下的,列中的值“B”代表这是一个双向的索引,即在Customer和District的列族索引中存储着关于对方的索引。“S”则代表只在本表的索引列族中存储有关于对方表的索引。当在插入一对多关系中的“一”方时,系统所建立的以索引为列名的列的值仅设置为“S”。除了在一对多的关系中,“一”方的索引是在插入数据时完成的,多对多关系也是在插入数据时由系统完成的。系统将主外键相同的表标记为多对多的关系表。假设A和B为多对多关系,当向A和B的关系表插入每条数据时,完成如下两步。(1)向A记录的索引列族中插入列名为“AKeyA-BKeyB”的列,值为“B”。(2)向B记录的索引列族中插入列名为“BKeyBAKeyA”的列,值为“B”。KeyA、KeyB分别为插入数据中A表的主键值和B表的主键值,这两个值既是A和B关系表的联合主键也是外键。在插入第一条包含外键关系的数据后,元数据管理器记录下“A-B”和“B-A”作为多对多关系的索引元数据。
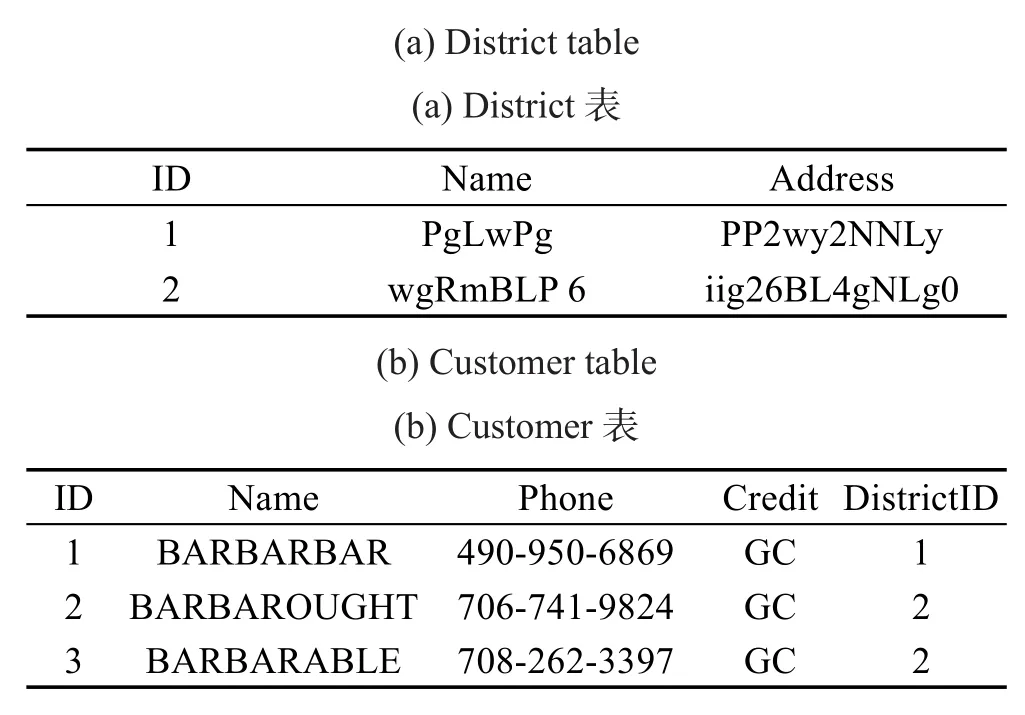
Table 5 TPC-C District table and Customer table表5 TPC-C中District表和Customer表
TPC-C测试数据模型中Warehouse和Item是具有多对多关系的一对实体,当向以Warehouse和Item的主键为联合主键的逻辑表插入数据时,系统按照多对多索引的创建方法,向Warehouse记录的索引列族中插入列名为“WarehouseKeyWarehouse-ItemKeyItem”格式的列,向Item记录的索引列族中插入“ItemKeyItem-WarehouseKeywarehouse”格式的列,如表7所示。元数据管理器记录下“Warehuose-Item”、“Item-Warehouse”作为创建的索引的元数据。
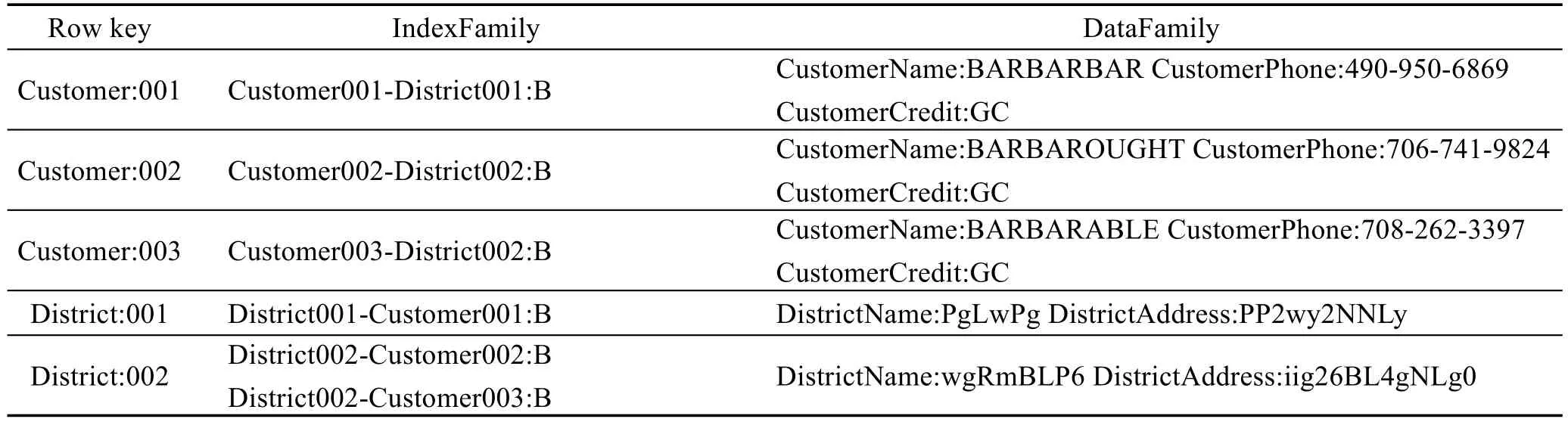
Table 6 One-to-many records in BigTable data model processed by RBase表6 经RBase处理后存储在BigTable数据模型中的一对多关系记录
以上两种情况都是在未事先声明索引的条件下插入数据时完成的,而District记录里索引列族下作为索引的列名并不会在向表中插入数据时由系统完成创建,需要用户使用提供的索引声明创建语句。之所以这种情况需要用户手动声明创建,是因为表示两表记录间关系的外键在向“多”方表插入数据时就已存在。如果用户并不需要在查询“一”方记录的同时获得相关的“多”方数据,系统为这种情况而建立的索引就不会被查询引擎所使用,并且还要占据一定的物理存储空间,降低数据库的性能。
当在两个有主外键关系的表A和表B间声明创建索引时,因为两者有一对多的关系,所以必然在某一方的索引列族下存在着“表名连接上主键值-外键所在表名连接上外键值”格式的列名。假设A是一对多关系中的“多”方,则A记录的索引列族下存在“AKeyA-BKeyB”格式的列名,系统按如下方式建立索引。
1.for column inA.IndexFamily
2.if column.name like“AKeyA-BKeyB”
3. insert into(B:KeyB,IndexFamily:BKeyB-AKeyA)values“B”;
4.end if
5.end for
6.MetadataManager.recordIndex(“B-A”);
当需要在查询TableA表中记录的同时获得其他表中与其相关的记录时,使用“CREATE INDEX
1.Queue Q;/*声明一个栈*/
2.Set UnvisitedSet=TableSet;/*新建一个集合保存未被访问的表*/

Table 7 Many-to-many records in BigTable data model processed by RBase表7 BigTable中具有多对多关系的数据经RBase处理后的结果
3.UnvisitedSet=UnvisitedSet.remove(StartTable);/*将出发表设为已访问*/
4.Q.push(StartTable);
5.while!isEmpty(Q)
6. p=Q.front();/*取队首表对象*/
7. Q.pop();
8. for(table in UnvisitedSet)
9. if MetadataManager.existIndex(table,p)/*如果未被访问的表集合中有表的索引列族中存在关于p的索引,通过查询索引元数据即可判断*/
10. if!MetadataManager.existIndex(p,table)
11. buildIndex(p,table);
12. MetadataManager.recordIndex(p.name+“-”+table.name);
13. end if
14. end if
15.end for
16.for(tableIndex in p.indexFamily)
17. q=parseIndexToTable(tableIndex);/*解析p记录索引列族中列名索引得到对应的表*/
18. UnvisitedSet=UnvisitedSet.remove(q);
19. Q.push(q);
20.end for
21.end while
这样,当有新的数据插入时,所有元数据管理器中记录的已创建索引(包括原先由系统在插入数据时自动创建的索引和手动声明创建的索引)都会根据新插入的值创建列名索引进行更新。
当用户需要删除一条记录时,删除之前,系统会自动对索引进行处理。当删除的是表6中row key为District:002的记录时,系统先从元数据管理器中获取所有关于District的索引元数据。对于“District-TableName”格式的索引,系统遍历District的每一条记录,检索索引列族下列名为“Distric002-TableName KeyTableName”的列并删除。同样对于“TableName-District”格式的索引,系统遍历TableName的记录,检索列族索引下列名为“TableNameKeyTableName-District002”格式的列并删除。
假设要被删除的记录是row key为“TableA:ID”,删除数据前关于索引的操作如下。
1.Set LocalIndexTableSet;/*和本记录的实体有主外键关系,且将索引存储在本实体记录的索引列族下的实体名集合*/
2.Set UnlocalIndexTableSet;/*和本记录的实体有主外键关系,且将索引存储在自身索引列族下的实体名集合*/
3.LocalIndexTableSet=MetaManager.queryLocalIndex(“TableA”);/*从元数据管理器中查询“TableA-TableName”格式索引的TableName集合*/
4.UnlocalIndexTableSet=MetaManager.queryUnlocalIndex(“TableA”);/*从元数据管理器中查询“TableName-TableA”格式索引的TableName集合*/
5.for table in LocalIndexTableSet
6. for column inA.IndexFamily.
7. if column.name.startWith(TableA.name+ID+“-”TableName);
8. A.IndexFamily.remove(column);
9. end if
10. end for
11.end for
12.for table in UnLocalIndexTableSet
13. for column in table.IndexFamily.
14. if column.name.endWith(TableA.name+ID);
15. table.IndexFamily.remove(column);
16. end if
17. end for
18.end for
当用户更新外键数据时,系统首先依照删除数据前删除索引的方法,删除本条记录对应的在其他表中的索引,然后按照插入新值时建立索引的方法,在其他记录的索引列族中插入新列。
3.3 性能分析
当用户在如表5所示关系型数据库下查询ID为1的街区的信息和其中住着的顾客信息时,输入“SELECT*FROM District JOIN Customer ON District.ID=Customer.DistrictID WHERE District.ID=1”,数据库查询引擎先读取ID为1的District表中的记录,然后遍历Customer表,找出Customer表中每条满足District-ID列中的值等于1的记录,返回查询结果给用户。
如果是在如表6所示的BigTable中,执行相同查询请求时,当查询引擎根据ID为1取得District的一条记录后,再解析该条记录中的IndexFamily中的列名,寻找以“District001-Customer”为前缀的列名,列名剩下的部分便是和该条District记录有一对多关系的Customer记录的主键值。查询引擎根据这些主键值就能够获取到相应的Customer记录。
对比这两种情况,假设Customer中一共有M位客户的记录,其中ID为1的街区中住着N位客户,第一种方式通过遍历寻找相应的记录,时间复杂度为(N×M)。第二种方式直接根据Customer记录的主键号获取相应记录,时间复杂度为(N×lgM)。尤其是当M很大,即系统中存储的客户记录很多时(这也符合大数据应用中的实际情况),查询速度的差异会越加明显。
4 实验结果
当用户在如表5所示关系型数据库下查询ID为1的街区的信息和其中住着的顾客信息时,输入“SELECT*FROM District JOIN Customer ON District.ID=Customer.DistrictID WHERE District.ID=1”,数据库查询引擎先读取ID为1的District表中的记录,然后遍历Customer表,找出Customer表中每条满足DistrictID列中的值等于1的记录,返回查询结果给用户。
如果是在如表6所示的BigTable中,执行相同查询请求时,当查询引擎根据ID为1取得District的一条记录后,再解析该条记录中的IndexFamily中的列名,寻找以“District001-Customer”为前缀的列名,列名剩下的部分便是和该条District记录有一对多关系的Customer记录的主键值,查询引擎根据这些主键值就能够获取到相应的Customer记录。
4.1 实验设置
实验在一个11个节点的计算机集群上进行,其中1个节点为主节点,运行HDFS的NameNode和HBase的HMaster。其他节点为从节点,运行HDFS的DataNode和HBase的RegionServer。集群中每个节点配置单颗12核英特尔至强E5-2650 v4处理器2.2 GHz,128 GB DDR4内存,2 TB硬盘,hdparm显示硬盘的顺利扫描速度约为每秒120 MB。整个集群由千兆以太网连接。对于HDFS,设定文件块大小为128 MB。对于HBase,设定RegionServer最大可使用100 GB内存。系统其他参数采用HDFS和HBase的缺省设定。
4.2 工作负载
本实验使用TPC-C测试基准中的5张数据表Customer、Order、OrderLine、Item以及Stock。本实验没有使用TPC-C评测负载。这是因为TPC-C测试基准中的5个事务主要用来测试数据管理系统的事务处理能力,而RBase是存储系统并无事务处理器。因此,本实验遵循谷歌对BigTable存储系统的评测原则,仅测试系统的读写性能。本实验设计了2个查询评测用例和1个写入评测用例。查询用例1返回给定客户最近购买的10件商品。查询用例2取自TPCC的StockLevel事务,返回低于指定库存的商品数目。写入用例1向Order表中添加一笔新的订单。
4.3 查询1及实验结果
查询1(Q1)的SQL语句如下:

其中,(:c_w_id,:c_d_id,:c_id)为输入参数确定待查询用户。为运行查询,对RBase系统建立如下的跨表查询索引:CREATE INDEX q1idx on Customer,Order,OrderLine,Item from Customer in tpcc。对MegaStore,将Customer和Order作为父子表存储在一张Big-Table中,OrderLine存储于另一个BigTable中,再额外用一张BigTable在OrderLine表的(ol_w_id,ol_d_id,ol_o_id)上建立次级索引。实验中,变换集群大小,测试当从节点数目增加时,系统的吞吐率(即,系统CPU满载时,每秒处理的查询总数)和查询响应时间。图3(a)和图3(b)显示了实验结果。可以看到,Rstore的吞吐率和平均响应时间明显优于MegaStore,这主要是由于跨表查询索引消除了耗时的表格连接操作。
4.4 查询2及实验结果
查询2(Q2)的SQL语句如下:

为运行查询,对RBase系统建立跨表查询索引CREATE INDEX q2idx on OrderLine,Stock from Stock in tpcc。对MegaStore,将Stock和OrderLine存为父子表。图4(a)和图4(b)分别显示了两个系统的吞吐率和平均响应时间。本查询中两个系统之间的差距显著缩小,这是因为查询2只涉及两张表格,因此表格连接并未产生较大开销。
4.5 写入1及实验结果
写入用例1向Order表中插入一条订单记录,较为简单,故此处略去相关的SQL语句。图5(a)和图5(b)显示了两个系统的实验结果。虽然两个系统的吞吐率大致相当,但是MegaStore的平均响应时间优于RStore。这是因为RStore在插入订单记录时,会更新跨表查询索引,因此引入了额外的I/O操作。
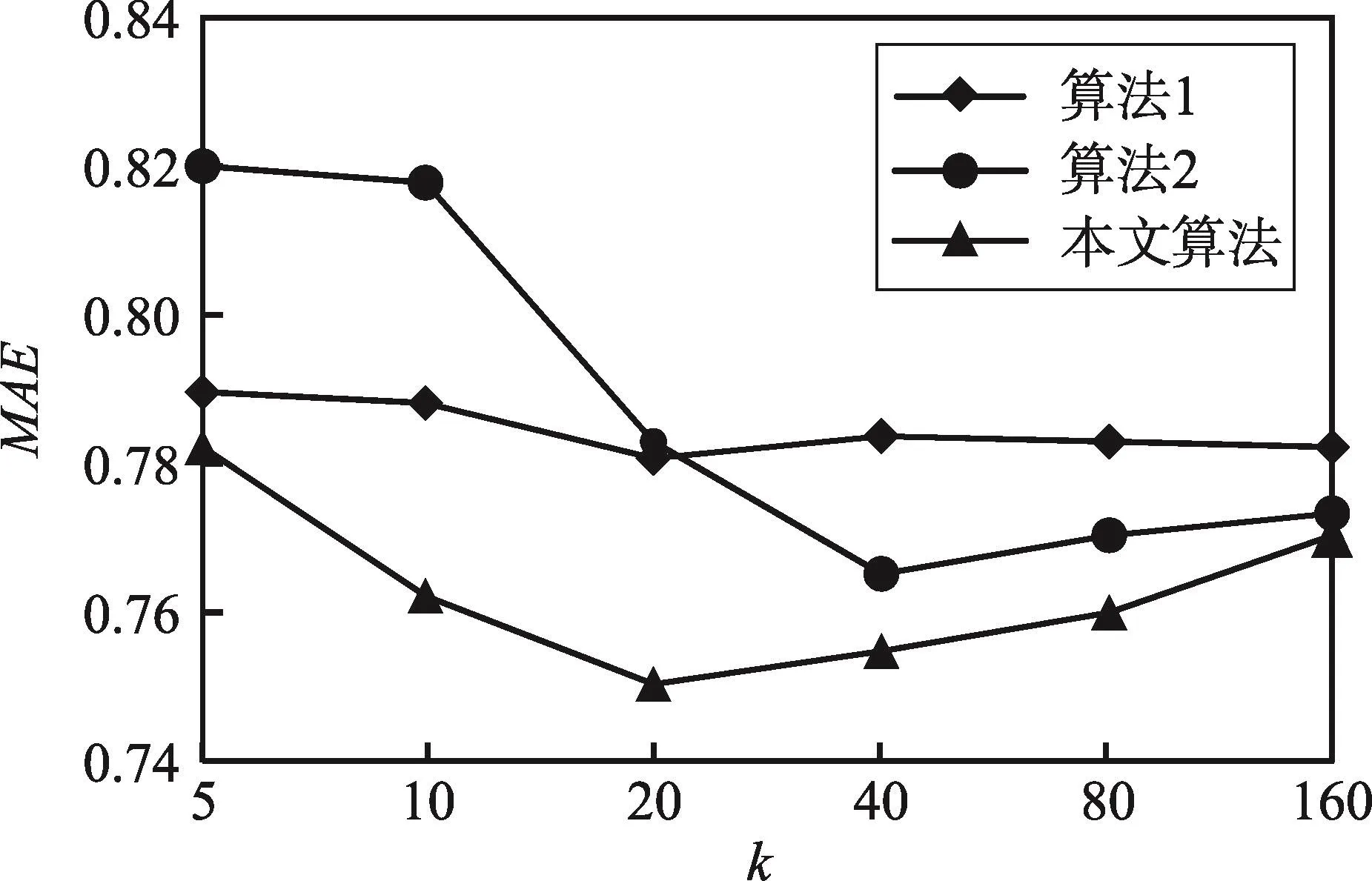
Fig.3 Q1 throughput results and avg.latency results图3 查询1的系统吞吐率和平均响应时间
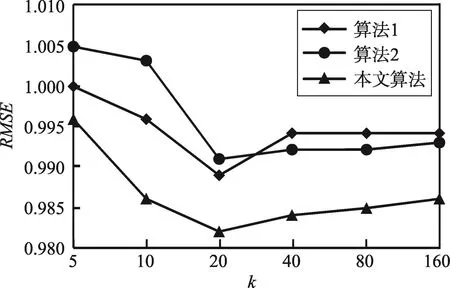
Fig.4 Q2 throughput results and avg.latency results图4 查询2的系统吞吐率和平均响应时间
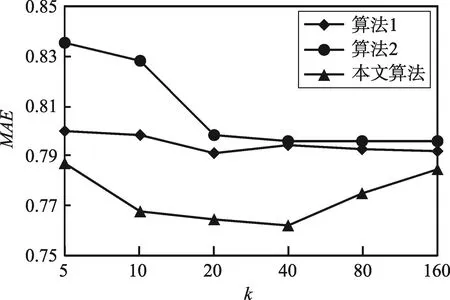
Fig.5 Order insertion throughput results and avg.latency results图5 插入记录时系统的吞吐率和平均响应时间
5 相关工作
与本文相关的工作分为3类:NoSQL数据库系统、基于NoSQL的关系数据库系统、数据库性能调优。
NoSQL数据库系统研究如何开发高效、分布式键值存储系统。文献[11]综述了此类工作。已提出的NoSQL数据库分为一维键值数据库,如Dynamo[12-13]和PNUTS[14],以及多维键值数据库,如BigTable[6]。本文工作是对这些工作的扩展。即,在NoSQL数据库之上提供关系数据模型,提升大数据应用开发效率。
基于NoSQL的关系数据库系统研究如何在NoSQL数据库的基础上提供关系数据模型。此类工作与本文工作高度相关,但在应用场景和实现技术方面与本文工作存在区别。文献[15-19]研究如何在分布式文件系统的基础上提供SQL查询接口。这些工作针对OLAP类大数据应用,优化目标为批量读写。而本文工作针对OLTP类大数据应用,优化目标为少数元组的读写。MegaStore[7]和Spanner[8]是建立在BigTable基础之上的OLTP数据库,设计目标与本文相同。区别在于,MegaStore和Spanner需要用户自行设计如何将多个关系表存储在同一个BigTable中,以提高查询性能,并非完整地支持关系数据模型的申明式编程范式。而本文工作仅需用户申明数据表结构和跨表查询索引,无需用户关心底层存储实现细节,属于标准的关系编程范式。
数据库性能调优研究如何根据给定的查询负载选择存储和索引结构。文献[20]和文献[21]综述了相关工作。文献[22]和文献[23]分别研究了如何选择数据切分、物化视图、索引结构以自适应地提升数据库性能。本文工作受到这些工作的启发,但实现技术与这些工作完全不同。原因在于,已有工作主要针对“热启动”场景,即数据库已经运行给定负载一段时间,再进行性能调优,而本文工作主要针对“冷启动”场景,即数据库尚未运行给定负载就需要决定存储格式和索引结构。
6 结论
本文提出了RStore,一个基于BigTable的关系数据存储系统。对于应用开发,RStore支持关系编程范式,用户只需申明业务数据的表格结构,无需关心数据的存储细节。对于系统实现,RStore自动将关系数据存入BigTable,支持高伸缩和高效的数据访问。RStore同时满足了大数据应用对数据管理系统快速应用开发和高效数据访问的需求。
