基于ARM架构的滤波函数优化
2018-09-26陈思润顾乃杰苏俊杰贺爱香
陈思润 顾乃杰* 苏俊杰 贺爱香
1(中国科学技术大学计算机科学技术学院 安徽 合肥 230027)2(中国科学技术大学安徽省计算与通信软件重点实验室 安徽 合肥 230027)3(中国科学技术大学先进技术研究院 安徽 合肥 230027)4(安徽新华学院信息工程学院 安徽 合肥 230088)
0 引 言
近年来,移动终端数量爆炸式增长[1],且随着人们对移动设备图像视觉的追求日益提高,Android设备的图像处理速度难以满足移动客户端的海量应用发展需求。而OpenCV作为一款从PC端到嵌入式开发领域的免费的开源跨平台计算机视觉库,可提供从影像过滤及转换到特性抽象与机器学习等几十个不同类别的数百种算法[2]。它已被成千上万的开发人员所使用,而且仍在不断发展之中。
传统的嵌入式平台依赖于CPU的串行计算方案,难以处理这类大量的计算密集型问题[3]。针对ARM架构,OpenCV源码使用了SIMD(Single Instruction Multiple Data)指令[4]做了部分改写,实验分析其仍然存在优化的空间。NEON技术通过对数据并行处理,能够很好地处理矩阵运算等存在大量数据相关性低的计算操作,因此适用于视频转码、语音处理、图像处理等场景。例如文献[3]使用了NEON技术以及GPGPU对Jpeg静态图像编码技术、Mpeg4动态图像编码技术进行了优化,其编解码性能提升了四倍左右。文献[5]使用了NEON技术在ARM Cortex-A系列的架构上实现了AVS多媒体视频文件解码工具的加速,实验证明NEON技术加速效果明显。文献[11]同样在Cortex-A8处理器架构上实现VC-1视频编解码软件的SIMD指令优化,解码性能提升30%以上。
考虑到移动终端用户对图像视觉质量要求日益提高,本文针对Android平台的ARM架构,使用NEON技术对OpenCV库中的滤波函数进行了优化,滤波效率提升明显。
1 ARMv8架构以及NEON
1.1 ARMv8架构
ARMv8是ARM公司在2011年发布的首款支持64位指令集的处理器架构。ARMv8保存了ARMv7架构的特性,支持Thumb-2、针对浮点FPU的VFP硬件扩展、DSP 扩展、Thumb指令集、主流的嵌入式OS(Linux、Android、Windows Mobile、Windows Phone、Symbian)、以及支持分支预测等技术。除此之外ARMv8还进行了一些功能扩展,支持TrustZone、虚拟化技术以及NEON advanced SIMD技术。
本文实验使用的ARM Cortex-A72处理器是基于ARMv8-A 架构,支持最新的64位指令集AArch64。AArch64相较于AArch32使用了更少的条件指令,删除了LDM/STM等实现复杂的指令,且AArch64指令集对32位和64位指令分别解码,简化了解码表,允许更多先进的分支预测技术。此外,ARMv8针对AArch64指令集支持的SIMD指令集做了更多的改进,支持双精度的浮点运算,在支持NEON指令集扩展的同时,其ARM核和NEON核的执行流水线分开执行,能够在16FF+的处理器技术中实现3 GHz以上的频率。
1.2 NEON技术
SIMD(Single Instruction Multiple Data)意思就是指一条指令能够同时处理多个数据的数据级并行计算技术,其执行机制如图1所示。
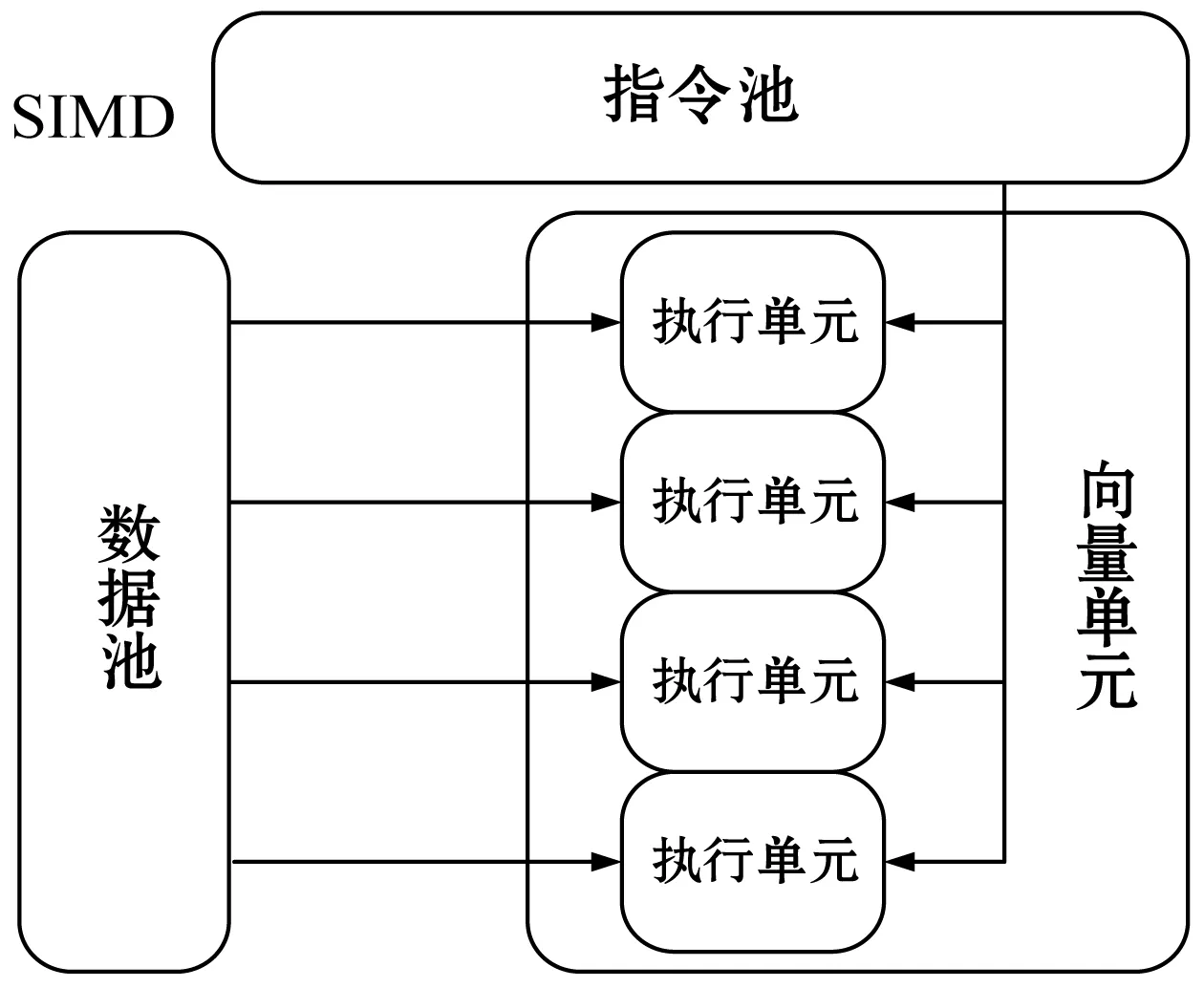
图1 SIMD指令机制示意图
NEON是一种基于SIMD思想的数据级并行技术,它旨在加速信号处理算法,能够加速音频和视频处理、语音和面部识别、计算机视觉和深度学习等应用技术。NEON技术从ARMv7版本开始被采用,目前可以在ARM Cortex-A和Cortex-R系列处理器中使用。NEON结合了64位和128位的SIMD指令集,ARMv8 NEON 指令集架构具有16个128位的四字寄存器,命名为 Q0-Q15,这16个寄存器又可以拆分成 32个64 双字寄存器,命名为 D0-D31。图2描述了NEON寄存器在多通道内同时进行多数据并行计算的过程。
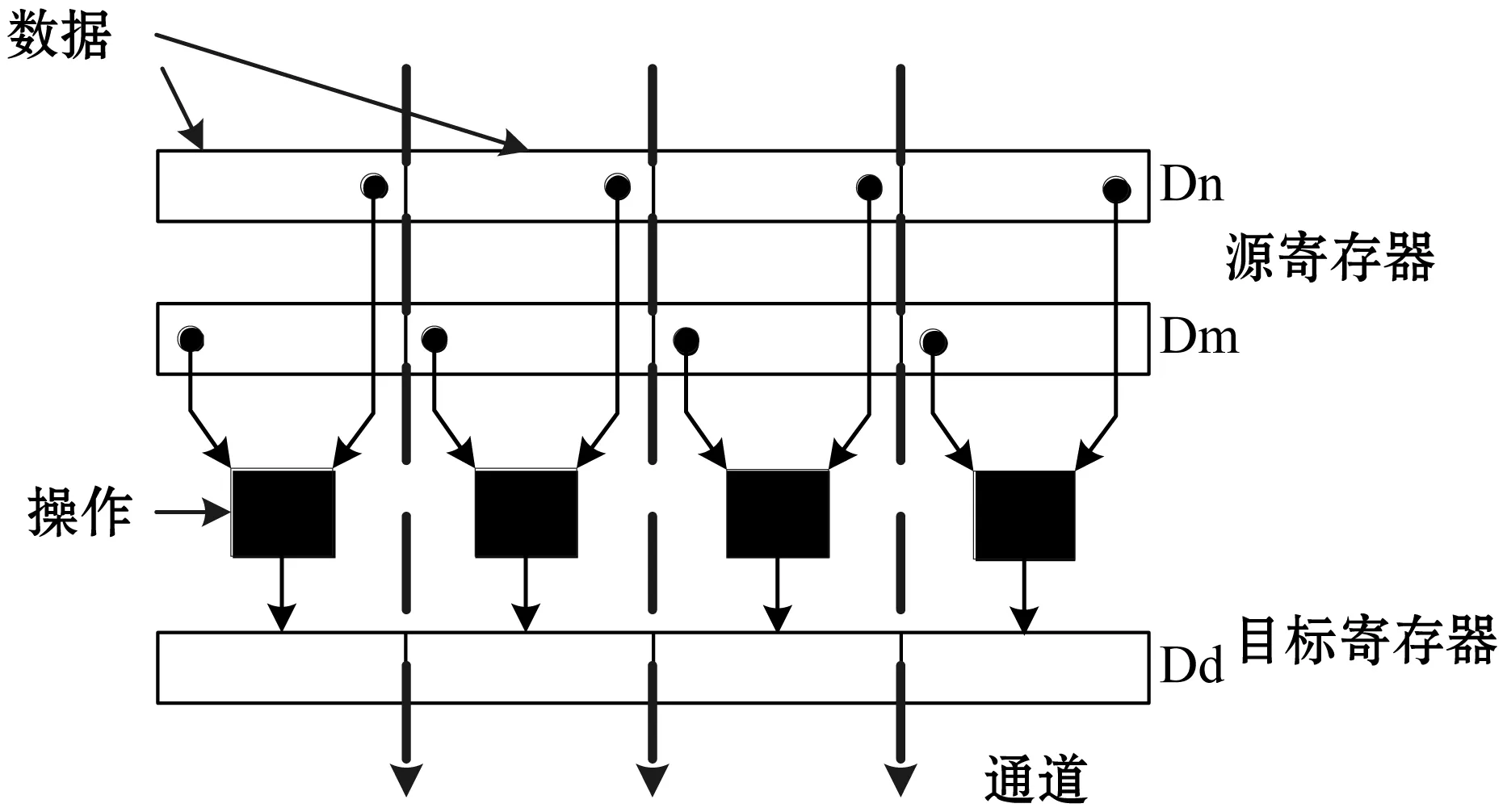
图2 NEON指令并行计算
2 NEON优化
研究人员使用NEON技术进行优化主要有四种方法,具体包括汇编优化、内联函数(intrinsic)、自动向量化以及NEON优化库。
2.1 汇编优化
使用手写汇编的形式,理论上可以达到NEON指令最高的优化效果,但是由于需要跟底层寄存器流水线打交道,所以在几种方法中难度最高,优化过程更复杂。手写汇编对开发者要求颇高,要想写出高效的汇编代码必须要有一定的汇编基础,以及体系结构相关的知识。使用不当,则会适得其反影响其性能。
2.2 内联函数
ARM为Cortex-A系列处理器生成NEON代码定义了一组新的数据类型以及C语言形式的内联函数接口。在开发人员进行C/C++语言开发时形同普通的函数调用,且ARMv8版本的NEON指令集支持64位的双精度浮点运算,拥有更多的指令操作。
调用ARM官方定义的内联函数时,程序需要在代码中包含头文件“arm_neon.h”,内敛函数具体数据格式以及函数原型使用方法举例如下:
#include
uint32x4_t example_func(uint32x4_t input)
{
return(vaddq_u32(input, input));
}
其中uint32x4_t数据类型表示使用了128位Q寄存器,并且数据类型为无符号的32位整型数。函数vaddq_u32完成对两个寄存器中各个32位无符号整型数据的加法操作。
使用内联函数相比较于手写汇编的形式要简单,对开发人员而言是一种比较友好的开发方式,并且大多数时候优化效果接近或者达到手工编写汇编代码的形式。
2.3 自动向量化
自动向量化是由ARM向量化编译器提供,需要在编译时加上相关的命令参数,如:gcc编译器使用“-ftree-vectorize”、armcc编译器使用“-vectorize”来开启自动向量化功能。这种方法的优势是使用简单,不需要太多额外工作,且跨平台移植方便,缺点是该种方式优化的效果较差。
2.4 NEON优化库
Ne10[4]是一个单独的开源库,可以把它直接嵌入到项目里面去(目前支持平台有linux,android,ios)。Ne10已实现了部分功能接口,具体有4个模块:dsp、math、imgproc、physics。目前Ne10提供的API功能有限,数据类型相较于ARM官方的定义也有差异,研究人员使用需要改动甚至重新编写部分功能函数,容易破坏平台间的可移植性。
对以上介绍的四种方法,权衡优化效果与使用复杂程度的关系,本文选择使用内联函数的方式对OpenCV库中的滤波函数进行优化,部分热点代码使用手写汇编代码的方式实现进一步的细致优化。
3 滤波函数优化
本文针对2.4.13版本的开源代码OpenCV库,对滤波函数进行优化,具体使用ARM Cortex-A系列处理器支持的NEON技术对图像处理模块的滤波函数进行了优化。OpenCV主要包含imgproc、features2d、highgui、core、calib3d等模块。由于OpenCV滤波函数较多,本文仅以中值滤波函数为例,说明NEON优化思路以及具体实现方式。
3.1 中值滤波函数
中值滤波是由Tukey提出的一个非线性滤波器,对于中值的计算传统方法是使用排序实现,标准的一维中值滤波器定义如下:
yi=med{xi-r,xi-r+1,…,xi,…,xi+r}
(1)
式中:med表示取中值操作,具体实现如算法1所示。
算法1传统中值滤波算法
输入: imageXsize ism×n,kernel radiusr
输出:medvalueY
(1) for i=r to m-r do
(2) for j=r to n-r do
(3) initialize list A[r2]
(4) for a = i-r to i+r
(5) for b = j-r to j+r
(6) add X(a, b) to A[r2]
(7) end
(8) end
(9) sort A[r2] then Y(i,j) = A[r2/2]
(10) end
(11) end
3.2 数据相关性分析
根据中值滤波函数源码的实现可知,定义两个向量X、Y,由于X[i]与Y[i]之间的操作结果并不影响X[i+1]与Y[i+1]之间的操作结果,数据之间没有关联,理论上可以同时进行而不会改变最终结果。本文通过使用objdump反汇编工具分析OpenCV中值滤波源码,发现未优化前每次执行完一次加法指令需要额外增加一条cmp和jmp指令,不仅增加了额外的指令开销也不利于指令流水。而NEON技术一条指令最大支持8次操作同时并行执行,不仅大大减少了条件判断指令开销,而且充分利用了ARM处理的多级流水线功能。Cortex-A系列处理器拥有两级 Cache,且L2级Cache跟NEON有直接相连的接口,方便数据交互,这种特性使得数据并行能够顺利进行大大减少因cache失效而产生的额外访存开销。
3.3 存储结构优化
根据分析,中值滤波函数核心代码不存在复杂的逻辑控制语句,且代码所用的数据结构ushort,为16位无符号整数类型,而NEON的Q寄存器结构支持16x8 bit的数据格式,满足NEON指令集的数据对齐的要求。输入数据类型为ushort,刚好可以通过对齐转化到uint16x8_t从而方便NEON处理器的使用。具体转换以定义一个ushort向量HT[16][8]为例,HT[0][0]~HT[15][7]存储地址连续,根据C++数组内存为行优先的存放规则可知该二维数组在内存中的存放顺序为:HT[0][0],HT[0][1],…,HT[15][7]。通过数据类型转换为uint16x8_t类型的RT[16],具体对应关系如图3所示。

图3 数据类型映射关系
3.4 汇编优化
NEON指令VADD.I16 Q0、Q1、Q2使用Q寄存器实现8路16位无符号整数的并行加法操作,对比原来的16位无符号整数的循环叠加操作,减少了大量时间开销,8路并行加法具体操作过程如图4所示。
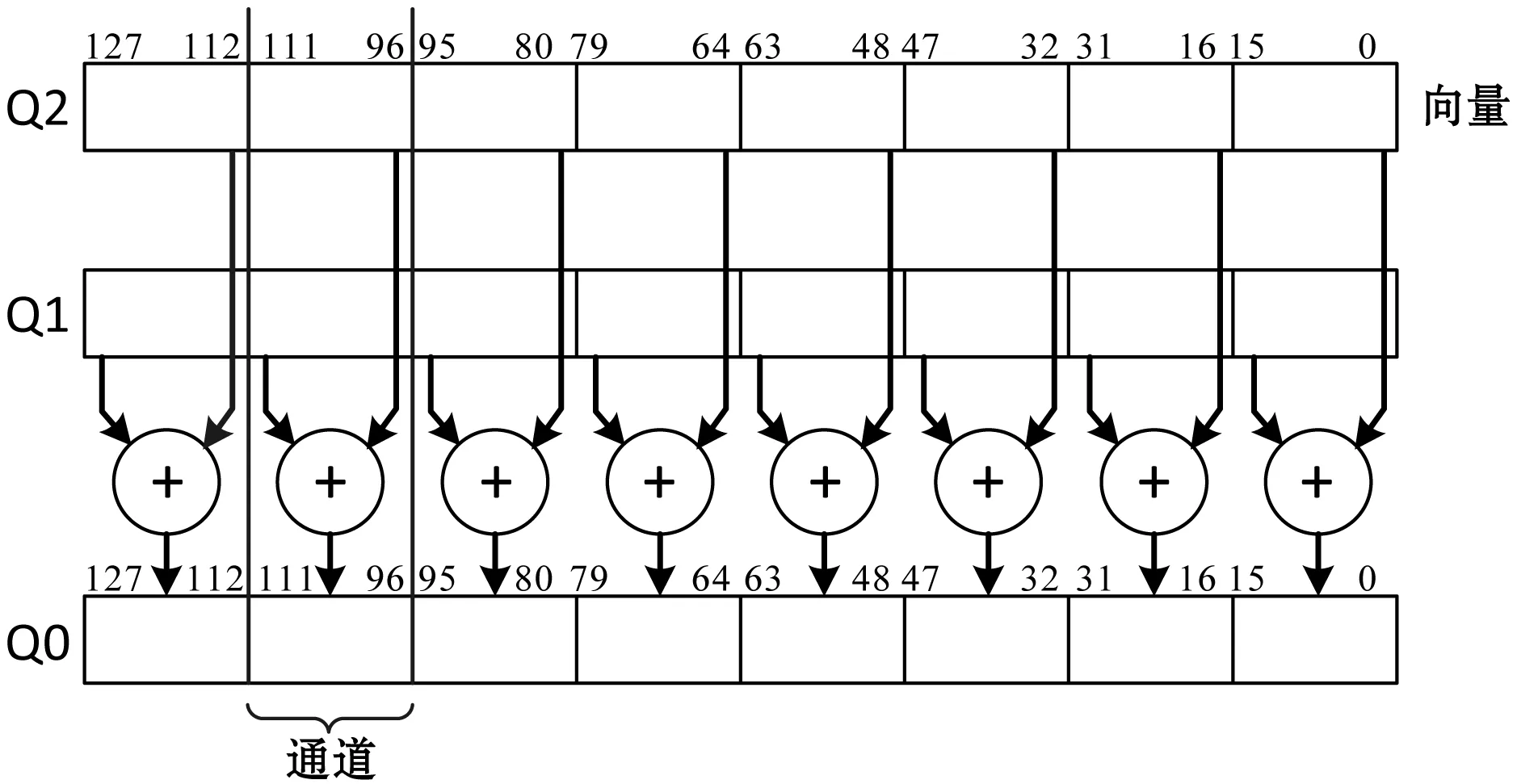
图4 8路16位整数并行加法
vld1.16 {d18-d19}, [r3]
add r3, sp, #36
vld1.16 {d22-d23}, [r3]
add r3, sp, #20
vld1.16 {d16-d17}, [r3]
add r3, sp, #52
vld1.16 {d20-d21}, [r3
四是创新人才匮乏,人才结构性矛盾突出。目前,东营市拥有各类科技人员18.6万人,但大多数分布在油田、石油大学以及教育、卫生系统,而企业自有一线研发人员不能充分满足技术创新需要,具有特殊专业技能的高层次人才匮乏,科技创新后劲需进一步加强。
vadd.i16 q9, q9, q11
vadd.i16 q8, q8, q10
ldr r2, [sp, #68
ldr r3, [r4]
add r1, sp, #36
cmp r2, r3
add r3, sp, #52
vst1.16 {d18-d19}, [r1]
vst1.16 {d16-d17}, [r3]
3.5 快速中值滤波函数
算法2对输入图像像素每一列维护一个大小固定的一维列数组Hist,使用一维列数组对滤波窗口像素值进行更新,极大地减少了比较操作,快速高效地得到中值。将数组更新的实现方式移植到ARM平台,且利用ARM Cortex-A系列支持的NEON技术,使用SIMD单指令多数据流的并行计算方法,改进中值滤波算法,具体实现如算法2所示。
算法2优化中值滤波算法
输入: imageXsize ism×n,kernel radiusr
输出:medvalueY
(1) 初始化列数组Hist1…n,kernelH,左右图片边界添加m/2个像素点,上下边界添加n/2个像素点;
(2) for i=1 to m do
(3) for j=1 to n step 8 do
(4) Remove Xi-r-1,j+r from Histj+r
(5) //NEON 并行计算
(6) SIMD_add Xi+r,j+r<- Histj+r
(7) SIMD_sub Histj+r<- Histj-r-1
(8) SIMD_add H <- Histj+r
(9) //更新滤波中值结果
(10) Y(i,j) <- median(H)
(11) end
(12) end
算法2的核心思想是对输入图像的每一列维护一个一维列数组Hist,逐行遍历图像像素点,以每次遍历的当前像素为窗口中心像素,建立滤波窗口,提取窗口内所有像素值(N=m×n),获取拥有N个像素点的一维数组Hist。累加数组Hist中的每个像素点数。将步骤(8)更新后的数组H的中值赋值给窗口中心元素,完成中值滤波操作。分析可知,每次操作的空间只是对一维数组Hist进行更新,且算法2中第(6)、(7)、(8)步定义的SIMD_add以及SIMD_sub操作均是使用NEON数据并行技术实现,具体实现方式为3.4节介绍的汇编形式,且在3.4节给出了SIMD_add的详细汇编指令序列。
对算法2时间复杂度进行分析,Hist的更新操作可在常数时间完成,每次求中值操作,只是对大小固定的数组Hist进行操作,其复杂度为O(1)时间,对于m×n的图片,时间复杂度约为O(mn),相较于传统方法复杂度大大降低。
4 实验测试与分析
本文实验所用平台为ARM,系统使用linux kernel 3.4.35版本,具体CPU型号为Cortex-A72,GPU为maliT880。
实验使用arm-linux-gcc交叉编译器,首先通过修改OpenCV目录的cmake文件设置好编译环境,然后在linux平台交叉编译OpenCV源码,最后通过adb shell工具连接ARM开发板将生成的可执行文件发送到开发板进行相关性能测试。
4.1 滤波效果分析
针对中值滤波函数,分别使用3×3、5×5的采集窗口对所选测试用例进行算法正确性测试。给出256×256像素的带椒盐噪声的图片用例,观察滤波函数优化后的滤波效果。
图5为不同窗口的中值滤波效果图,其中(a)为带椒盐噪声的测试用例图片,(b)、(c)分别为3×3、5×5的中值滤波后的图片,可以看出优化后滤波效果明显,说明优化后去噪性能并没有降低。

图5 中值滤波效果图
4.2 时间性能分析
使用OpenCV自带python脚本对中值滤波优化前后性能进行对比测试,表1给出了中值滤波函数分别使用3×3、5×5两种采集窗口在127×61、320×240、640×480、1 280×720这四种不同尺寸的图片上的对比优化效果。分析表中数据可以得知,采用NEON技术优化后的中值滤波函数,在不同尺寸图像以及不同的采集窗口均有很好的优化效果,平均加速比均超过了18倍,最高加速比达35倍多,优化效果显著。
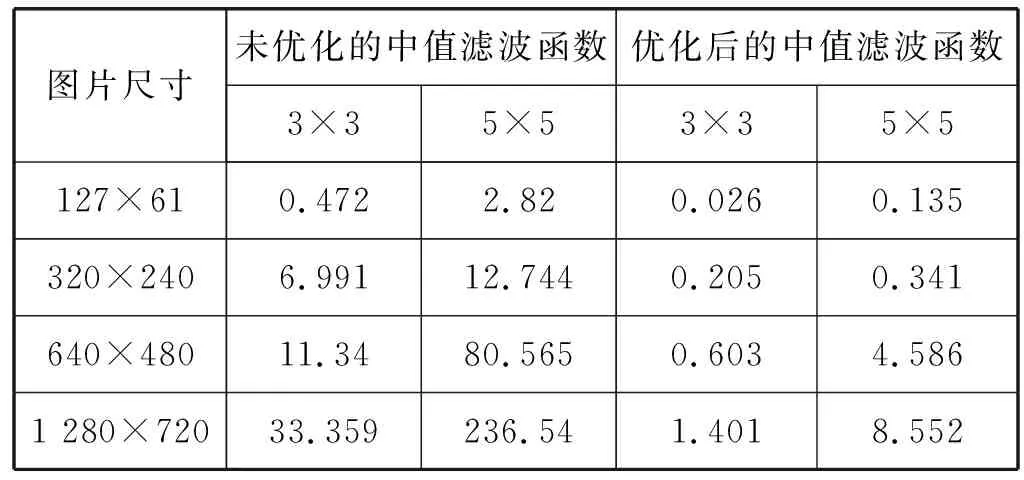
表1 中值滤波测试结果 ms
同时本文对OpenCV库的其他滤波函数进行了同样的加速比测试。由于各类滤波函数均存在大量矩阵运算操作,数据相关性低,且存在大量重复计算操作,采用NEON SIMD数据级并行技术对各滤波函数进行优化,效果均表现良好。
测试用例统一使用256×256尺寸的图片。通过python脚本测试各滤波函数,多次测试分别得出的各滤波函数滤波时间,经过计算得出各函数对应的加速比的平均值。
图6给出了优化后的各滤波函数分别在3×3以及5×5两种窗口下的加速比数据。从图中可以看出NEON优化加速效果明显,各函数加速比均超过两倍,其中中值滤波函数优化加速比达17倍之多,且随着滤波窗口的增大,加速比也随之增大,对应其优化效果越好。
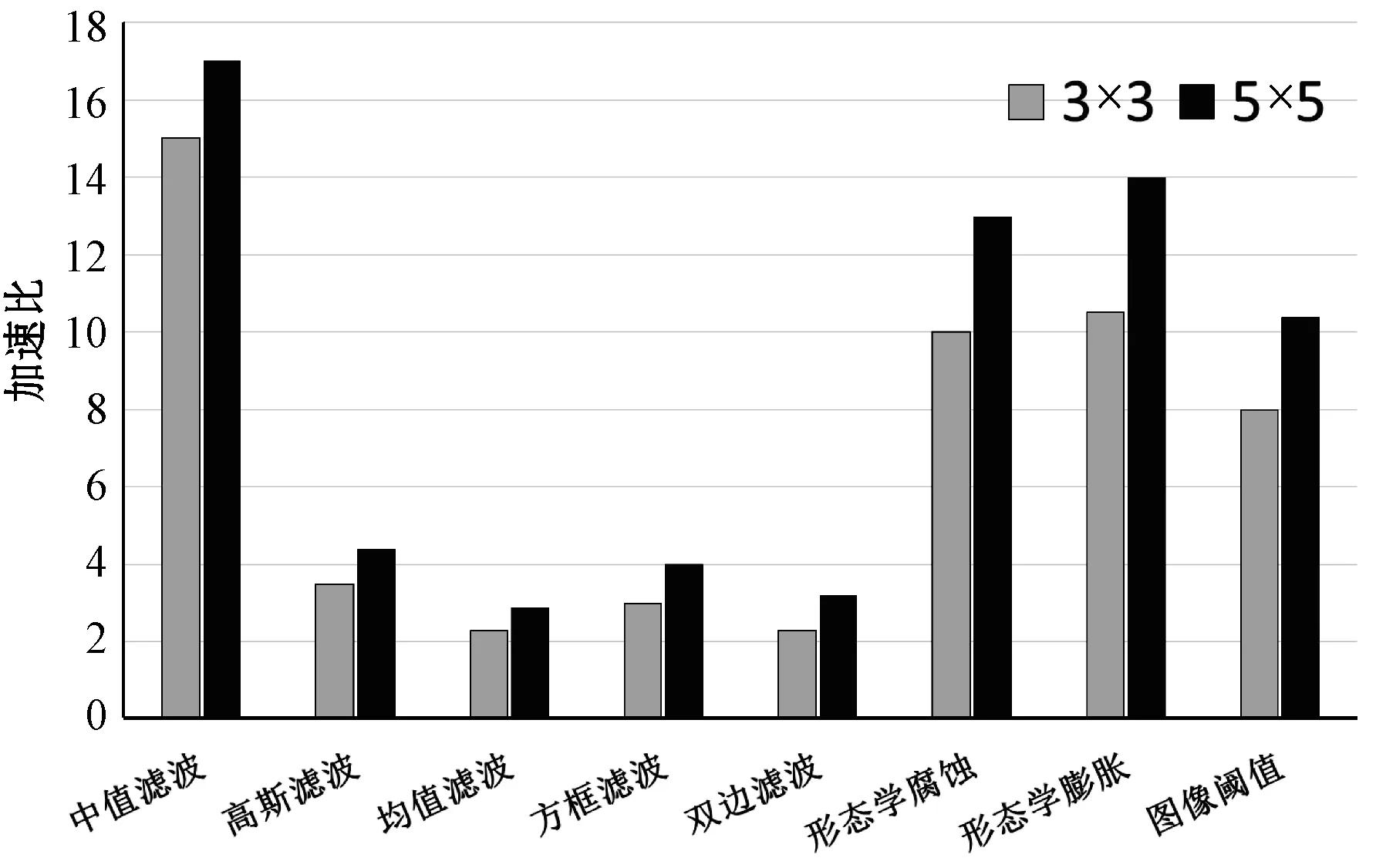
图6 滤波函数加速比
5 结 语
本文针对ARM架构,根据OpenCV函数库的性能提升需求,使用了NEON数据并行技术对滤波函数进行了优化。实验证明NEON技术在OpenCV源码中优化效果显著,SIMD数据级并行优化方法能较好地提高滤波函数的时间性能。
针对ARM架构,除了NEON技术可用于优化,还可以考虑利用GPU优化,以及利用ARM多线程进行相关优化。下一步将着重从GPU、多线程技术展开进一步的优化工作。
