基于改进的n-gram模型的URL分类算法研究
2018-09-22骆聪,周城
骆 聪,周 城
(江南计算技术研究所,江苏 无锡 214083)
0 引 言
随着互联网的快速发展,网络上的信息量获得了爆炸性增长[1]。为了方便用户从海量网页中快速找到感兴趣的信息,准确的网页分类成为越来越棘手的问题。网页分类在构建主题爬虫、搜索引擎个性化排序和搜索引擎的目录导航等方面发挥着至关重要的作用[2]。
文中提出将改进的n-gram模型用于网页分类。首先简要介绍了国内外的相关研究,然后介绍了URL和n-gram模型,接着提出了基于改进n-gram模型的URL分类算法,最后通过实验进行了相关验证。
1 URL分类研究现状
传统的网页分类技术大都参考文本分类技术,从网页正文、超链接结构和锚文本等网页内容中抽取有效的特征用于网页分类[3]。但是在主题爬虫中,在下载网页之前就需要判断该URL代表的网页所属的主题。此外当网页内容隐藏在图片中,网页内容信息就无法获取[4]。在这些情况下,基于内容分析的网页分类技术作用十分有限,于是基于URL分析的网页分类技术逐渐成为了研究热点。
Kan M Y等[5]将URL划分为有意义的块,提取成分特征、序列特征和正交特征,然后使用最大熵模型进行分类,在某些场景下该方法的性能接近当前最新的基于内容分析的网页分类方法。Rajalakshmi R等[6]提出仅从网页URL中提取基于n-gram模型的字符特征,然后使用支持向量机和最大熵分类器进行分类,取得了较好的效果。Inma Hernández等[7]提出了CALA算法,该算法基于Patricia树结构,树的每个节点表示前缀,对其使用通配符泛化后,从根节点到叶子节点就可以得到一条URL模式。在建立一系列URL模式之后,只需要将网页URL与模式匹配来进行分类。
2 URL和n-gram模型
2.1 URL
URL(uniform resource locator,统一资源定位符)是每个网络资源统一的并且在网上唯一的地址。URL的语法格式为:protocol://hostname[:port]/path[;parameters][?query][#fragment]。其中带方括号[]的为可选项。Protocol(协议)用于指定使用的传输协议。Hostname(主机名)指存放资源的服务器的域名系统DNS主机名或者IP地址。Port(端口号)为整数,省略时使用方案的默认端口。Path(路径)由零或多个/符号隔开的字符串,表示主机上一个目录或文件地址。Parameters(参数)用于指定特殊参数的可选项。Query(查询)可选,用于给动态网页传递参数。Fragment(信息片段)用于指定网络资源中的片断。
网页URL虽然只是一串相对较短的文本,但是它也携带了一些和网页内容相关的有效信息,目前已经广泛应用于Web挖掘的众多领域,所以有必要充分利用网页URL信息来进行网页分类。
2.2 n-gram模型
n-gram模型[8]是自然语言处理中常用的一种语言模型,该模型基于这样一种假设,第n个词的出现只与前面n-1个词相关,而与其他任何词都不相关,整个句子的概率就是各个词出现的概率的乘积。对于句子S=W1W2…Wk,它的概率可以表示为:
P(S)=P(W1W2…Wk)=P(W1)·P(W2|W1)·…·P(Wk|Wk-n+1…Wk-1)=
(1)
其中,C(Wi-n+1…Wi-1Wi)表示n元对Wi-n+1…Wi-1Wi在训练集中出现的次数。
n-gram模型中存在数据稀疏问题[9],即部分n元对在训练集中没有出现过,导致较多参数为0。这个问题可以通过数据平滑技术来解决,典型的数据平滑算法有加法平滑、Good-Turing平滑、Katz平滑、插值平滑等等[10]。文中采用最简单的加一平滑算法,保证每个n元对至少出现一次,使用加一平滑算法后,概率就可以表示为:
(2)
其中,V为训练集中所有n元对的个数。
进行网页分类时,特征选取是一个极其重要的环节[11]。进行URL特征提取时,传统的URL切分方法是遇到非字母数字字符时把URL进行分割。显然这种分割方法过于粗略,对于字符串内部的关键词就无法提取出来,所以最后网页分类的准确性往往不理想。文中借鉴n-gram模型的思想进行URL的特征提取,但与一般自然语言处理过程将词作为基本单位不同,文中将字符作为基本单位,对URL进行了进一步的分割。
3 基于改进n-gram模型的URL分类
传统的基于n-gram模型的URL分类算法认为所有URL字段在进行网页分类时的区分能力相同。但通过查看网页URL格式说明,可以发现真正有区分能力的是hostname(主机名)和path(路径)这两个字段,而其他字段对于网页分类的贡献程度几乎可以忽略不计。此外,由于path字段用来表示主机上的一个目录或文件地址,而根据个人习惯可知,为了便于寻找,在存储文件时往往将存储路径命名为与文件内容或主题相关的名字。例如,由“D:游戏英雄联盟”这个路径可知,该目录下的文件与游戏主题相关。所以基于上述考虑,文中仅把URL的hostname和path这两个字段用于构建n-gram模型,并且为path字段赋予更高的权重weightpath。
黎斌[12]使用n-gram模型对URL进行分类时对每个类别分别建立一个n-gram模型,然后由所有n-gram模型共同组成分类器。在此基础上,文中对n-gram模型进行改进,在建立模型时考虑字段权重,提出基于改进的n-gram模型的URL分类算法,以提升网页分类的准确性。
训练阶段,将训练集中的URL按预先设定的类别分类,然后统计每个类别中n元子串和n-1元子串的数量。对于字符串str,若其在hostname字段和path字段出现的次数分别为counthostname(str)和countpath(str),那么在改进后的n-gram模型中,该字符串出现的总次数应为:
counttotal(str)=counthostname(str)+
countpath(str)×weightpath
(3)
其中,weightpath>1。
测试阶段,假设预先设定K个类别,提取测试集中URL的n元子串,然后根据式2并结合训练集中子串的统计情况,逐一计算测试集中的URL在各个类别下的概率P1,P2,…,PK。如果Pi(1≤i≤K)为其中的最大值,那么可以认为i对应的类别即为该URL所属的类别。
基于改进的n-gram模型在剔除大量噪声数据的同时,也为具有高区分能力的字段赋予更高的权重。将结合字段权重的n-gram模型用于URL分类,不仅可以提高算法效率,也有助于网页分类准确性的提升。
4 实验结果与分析
4.1 实验环境与数据集说明
实验是在Windows7操作系统的环境下,利用JetBrains PyCharm 2017和Microsoft Visual C++ 6.0等软件,通过Python和C++语言实现的。其中URL的预处理是通过Python编程实现的,子串数量的统计和概率的计算是通过C++编程实现的。
WebKB数据集中共包含8 282个页面,经过人工分类为以下7个类别:Course、Department、Faculty、Other、Project、Staff和Student。实验中使用了该数据集的一部分,其中Course类别共208个页面,Faculty类别共152个页面,Project类别共80个页面,Student类别共552个页面。在每个类别中,训练集的数量占四分之三,测试集的数量占四分之一。
借鉴文本分类中通常使用的评价标准查准率(precision)、查全率(recall)和F1值(F1score)对实验中网页分类的结果进行评价。
4.2 实验结果
4.2.1 weightpath的选择
在进行网页分类时,由于path字段比hostname字段更具有区分能力,所以设定weightpath>1。但是当weightpath的值太大时,会严重削弱hostname字段的分类能力,所以有必要对weightpath的值进行选取。设定n=3,然后通过调整weightpath的大小进行实验,得到每一类的查准率、查全率和F1值,如表1所示。
将在不同weightpath下得到的各项评价标准的平均值绘成折线图,如图1所示,可以发现当weightpath=1.5时更加合适,此时网页分类的准确性较高。
4.2.2 n的选择
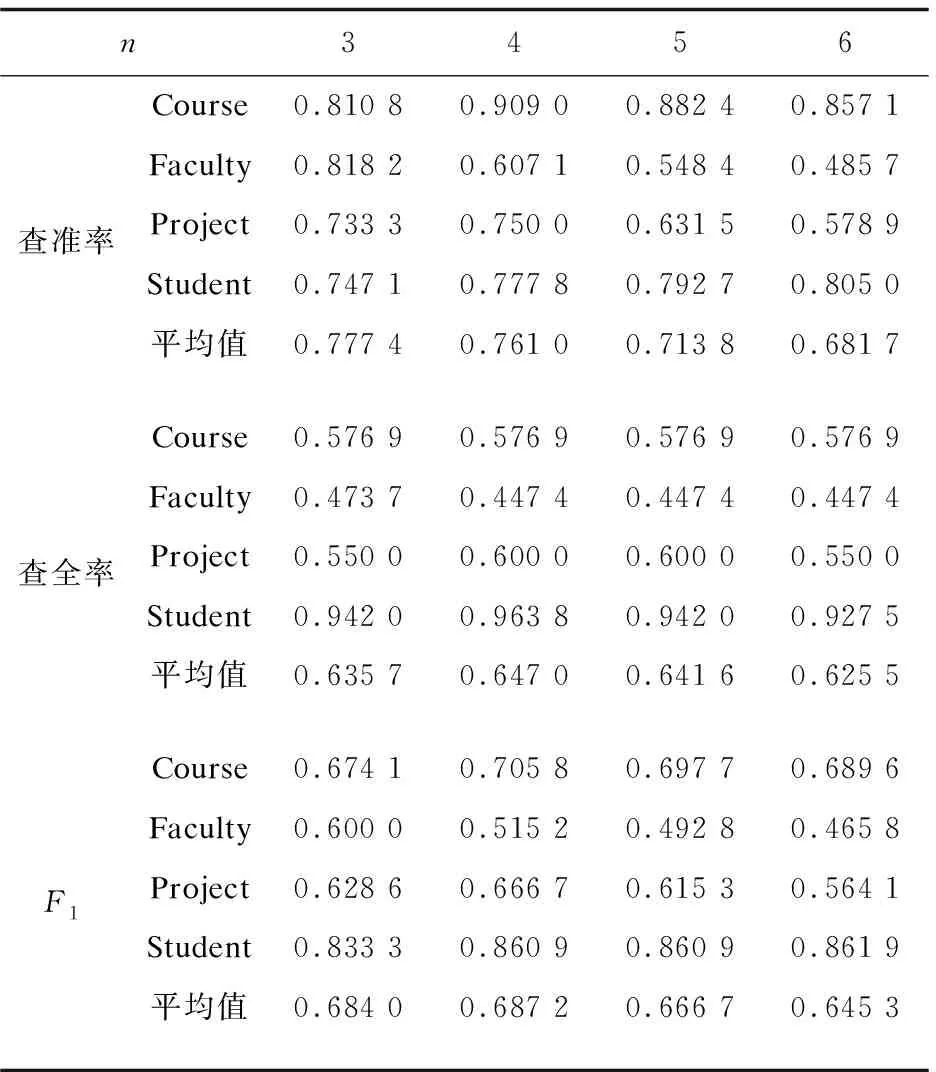
使用n-gram模型时,n太大太小都会影响分类的准确性,因此合理地选择n就显得尤为重要。根据前面的实验结果,设定weightpath=1.5,然后通过调整n的大小进行实验,最后得到每一类的查准率、查全率和F1值,如表2所示。
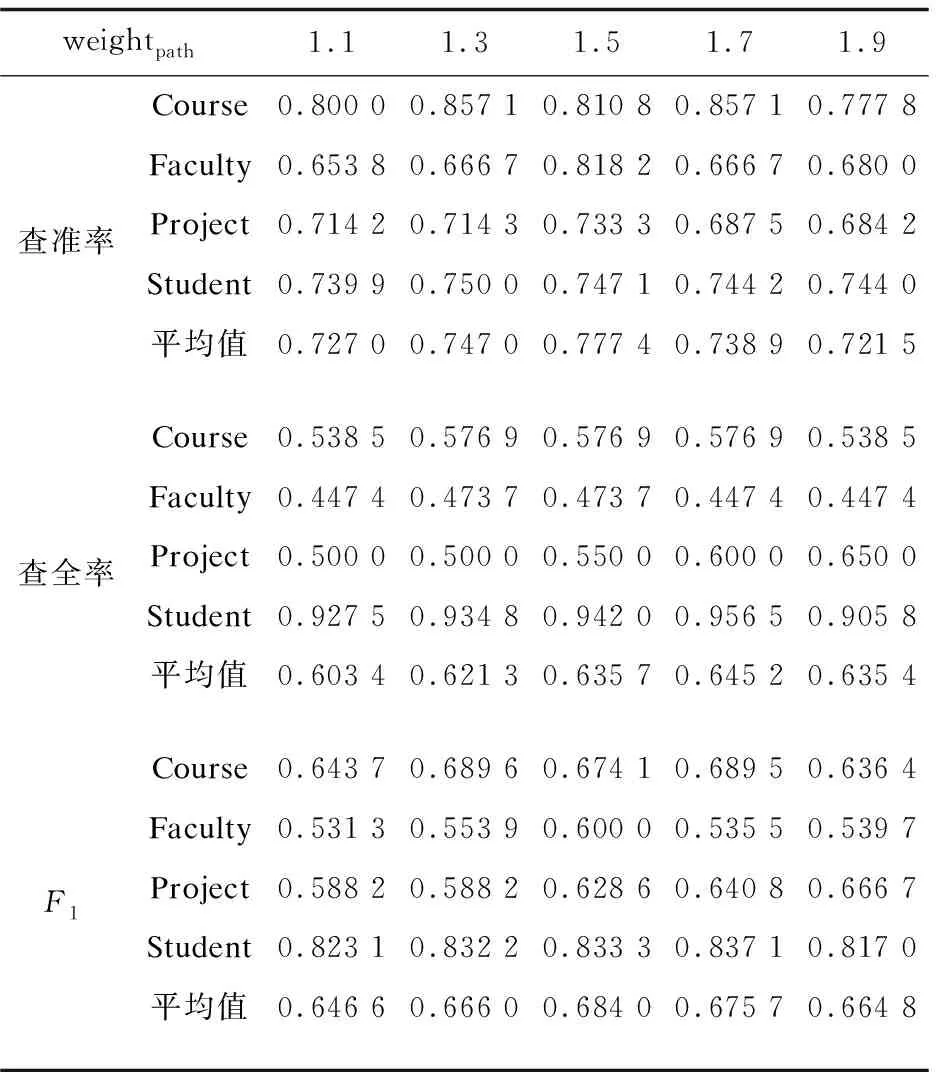
表1 在不同weightpath下得到的实验结果
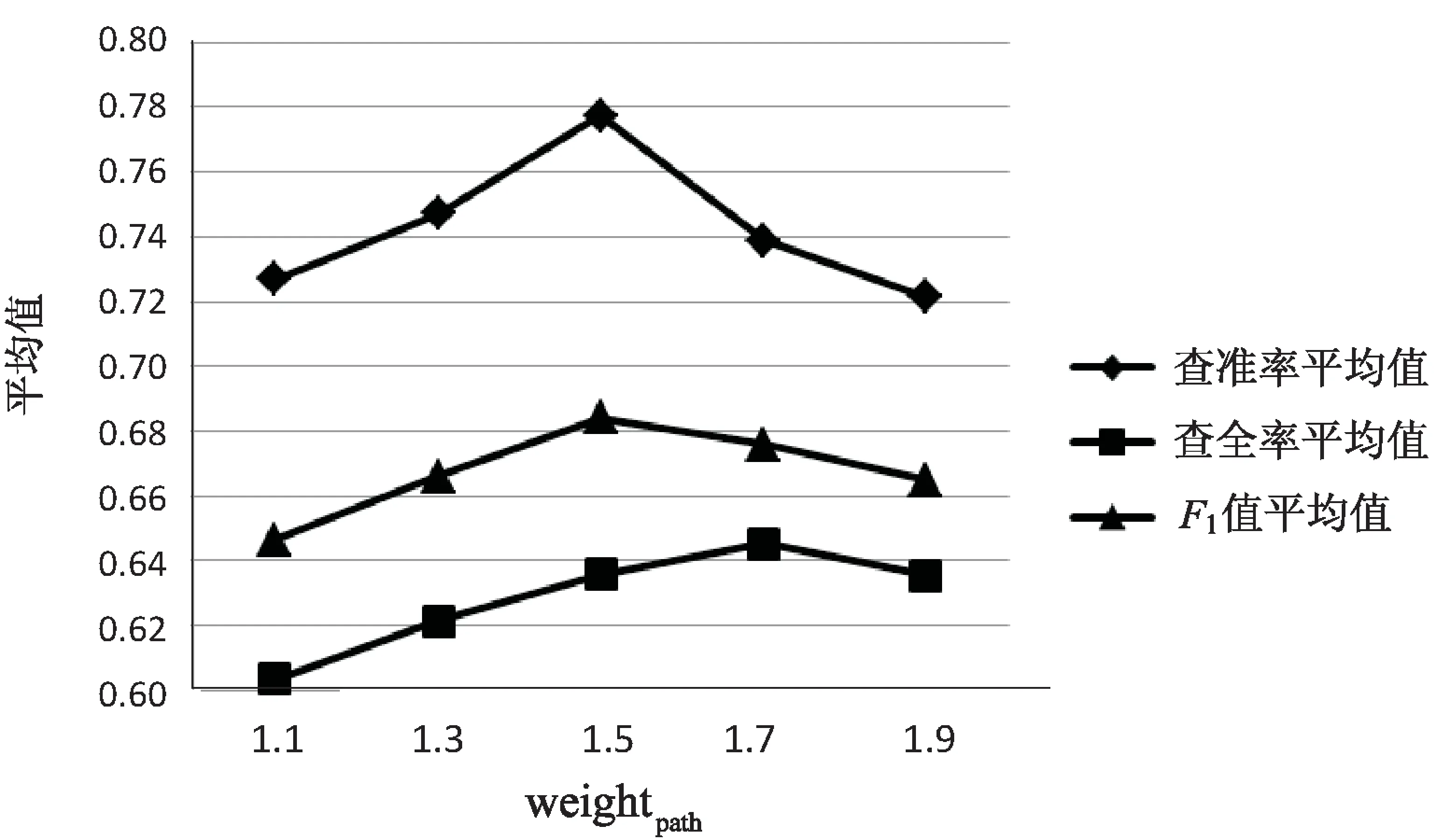
图1 在不同的weightpath下各项评价标准的平均值
n3456查准率Course0.810 80.909 00.882 40.857 1Faculty0.818 20.607 10.548 40.485 7Project0.733 30.750 00.631 50.578 9Student0.747 10.777 80.792 70.805 0平均值0.777 40.761 00.713 80.681 7查全率Course0.576 90.576 90.576 90.576 9Faculty0.473 70.447 40.447 40.447 4Project0.550 00.600 00.600 00.550 0Student0.942 00.963 80.942 00.927 5平均值0.635 70.647 00.641 60.625 5F1Course0.674 10.705 80.697 70.689 6Faculty0.600 00.515 20.492 80.465 8Project0.628 60.666 70.615 30.564 1Student0.833 30.860 90.860 90.861 9平均值0.684 00.687 20.666 70.645 3
将在不同的n下得到的各项评价标准的平均值绘成折线图,如图2所示,可以发现当n=4时网页分类的准确性要略好于n为其他值的时候。
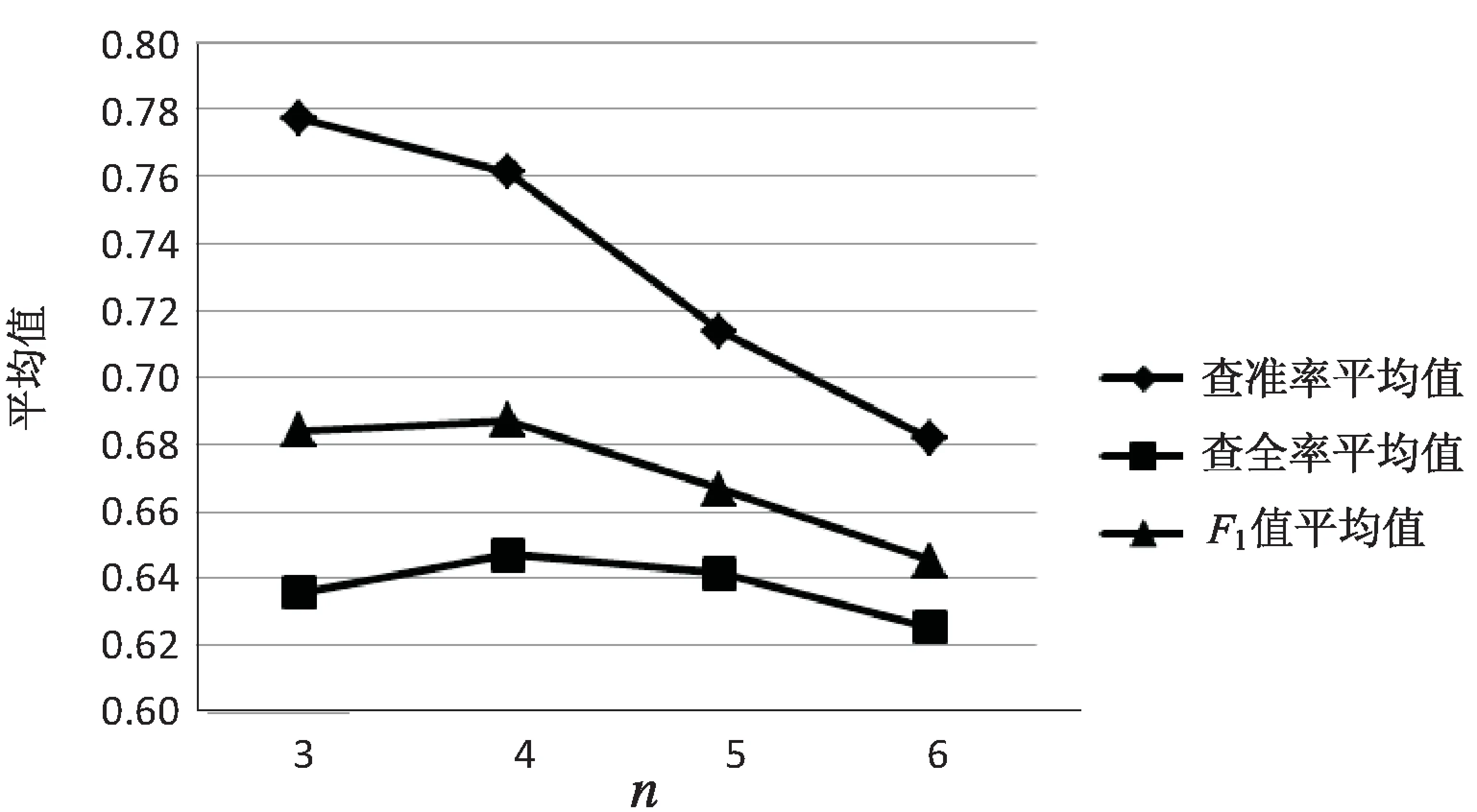
图2 在不同的n下各项评价标准的平均值
综合上述实验结果可知,当weightpath=1.5,n=4时,改进后的n-gram模型性能较优,此时网页分类的准确性要优于其他时候。所以在后续的改进前后性能对比环节,将使用这两个值作为参数进行实验。
4.2.3 改进前后网页分类准确性对比
为保证模型的可靠性,将实验数据集中的每一类都随机分为4份,然后让这4份数据的其中1份轮流充当测试集,另外3份作为训练集。设定weightpath=1.5,n=4,得到4次实验改进后的F1值,如表3所示。

表3 4次实验改进后的F1值
通过对4次实验的结果求平均值可知,改进后的F1值为66.71%,比文献[12]中得到的59.23%提升了12.63%。
4.2.4 改进前后网页分类效率对比
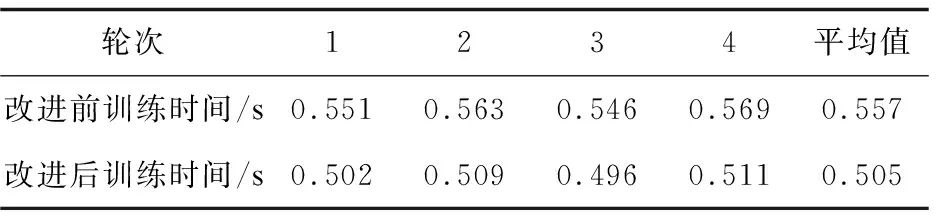
由于改进前后的差异主要体现在URL预处理和子串数量统计上,所以根据训练时间这个指标进行网页分类效率的对比。4次实验改进前后的训练时间如表4所示。
表4 4次实验改进后的F1值
轮次1234平均值改进前训练时间/s0.5510.5630.5460.5690.557改进后训练时间/s0.5020.5090.4960.5110.505
通过对4次实验的结果求平均值可知,改进后n-gram模型的平均训练时间为0.505 s,比改进前的0.557 s减少了9.34%。
上述实验证明了将改进后的n-gram模型用于网页分类的可行性,并且综合实验结果可知,改进后网页分类准确性和算法效率都有一定的提升。
5 结束语
考虑到网页URL各个字段对于网页分类的区分能力不同,在此基础上改进n-gram模型,提出基于改进的n-gram模型的URL分类算法。实验结果证明,该算法改善了分类准确性和算法效率。
在未来的研究中,将探索该模型用于中文网页URL分类的可行性。并且考虑到网页URL能够提供的信息有限,试图结合基于内容分析的网页分类技术,并采用深度学习[13-15]方法,挖掘更深层次的特征,以提升网页分类的准确性。
