社交媒体事件检测研究综述
2018-09-22王冰玉吴振宇沈苏彬陈佳颖
王冰玉,吴振宇,沈苏彬,陈佳颖
(1.南京邮电大学 物联网学院,江苏 南京 210000; 2.南京邮电大学 计算机学院,江苏 南京 210000)
0 引 言
互联网的日益普及,产生了各种类型的数据,包括文本数据、图像数据和视频数据等。这些数据中包含着许多隐含价值,事件检测是在数据中挖掘隐含价值的研究方向之一,利用事件检测技术向用户推荐其可能感兴趣的内容[1]。随着社交网络的兴起,人们通过社交网络分享内容、发表观点,使得社交网络成为现实世界的映射。通过分析社交媒体数据,例如Johnson N F[2]等探究了社交网络中有关ISIS的个人、组织的一些行为与现实世界所发生的极端恐怖事件之间的联系,帮助预测了现实世界中可能出现的恐怖袭击事件。由此可见,事件检测与分析有助于预测事件及其发展趋势。
目前,事件检测的研究中在以下两个方面尚有不足:第一,对于事件的定义不够明确;第二,针对不同的数据类型和实际场景有不同的事件检测方法,没有相关文献对此进行详细总结和分析。
对此,文中对事件进行了定义,指出其与话题之间的联系与区别,进一步分析了各种事件检测方法,并对未来的发展方向进行了展望。
1 事件的定义
社交媒体中的事件一般是指现实世界中发生的较重要的事情[3],数据类型以文本为主。根据事件的组成要素,童薇等[4]认为事件就是特定时间和地点发生的事情。根据事件是否发生过,事件还可以分为新事件(new event detection,NED)和已有事件。黄颖等[5]将新事件检测定义为:“检测时序新闻流中对某一话题的首次报道,即识别新话题。”
目前大部分的研究都没有对话题和事件做明确的区分,大量文章中“话题”的概念与“事件”的概念是可以互相转换的,但也有观点认为事件与话题不是同一个概念,话题的覆盖面更广[6]。还有文章认为事件发展过程中涉及话题角度不同,一个事件可能包含了许多话题[7]。
鉴于目前事件的划分方法过多,并且在事件,话题与报道的概念上分割不够清晰,因此,文中将事件(event),报道(story)和话题(topic)的概念进行严格区分,并对它们之间的关系作详细阐述。一般来说,事件由时间,地点,人物或组织以及行为四大要素组成。而报道是针对某一事件的报道,是对事件的一种描述方式。不同媒体关于同一事件的报道方式和报道内容可以不尽相同,但是它们都是围绕同一个事件进行的,都必定包含但不局限于事件的某些客观信息,如事件的时间,地点,行为主体以及动作等。话题的定义可以细分,文中将话题分为单事件话题、系列事件话题、类似事件话题三类。其中单事件话题是针对某一具体事件展开的,包括事件本身和人们对该事件的相关讨论以及事件的发酵和演变,多数情况下单事件话题等同于事件。系列事件话题是针对一系列相关事件所构成的事件链,例如奥运会的各项赛事,都是围绕着奥运会这一话题中心展开的系列事件。而类似事件话题则由无直接关系的类似事件构成。
2 文本预处理技术
事件检测工作主要分为两步:文本预处理和事件检测。文本预处理主要涉及计算词元权重,以及文本相似度计算等工作。在中文文本处理时还会涉及到中文分词,中文分词是自然语言处理研究领域内仅针对中文文本的较为独立的分支,文中仅介绍词元权重计算和文本相似度计算。
2.1 词元权重
在处理文本时,常常要将其量化,表示成向量空间模型(vector space model,VSM),即用词元权重等数值构成向量空间模型的每一个分量。现在使用比较多的方法是利用词频_反文档频率(term frequency_inverse document frequency,TF_IDF)[8]提取较为重要的词元,该值的大小反映了词元的重要程度以及词元对文档的区分能力。TF_IDF的计算公式为:
wd=fw,d*log(|D|/fw,D)
(1)
即wd=TF*IDF。
其中,fw,d为词w在文档d中出现的频率;|D|为语料库的大小,即语料库中所包含的文档数目;fw,D为语料库中出现词语w的文档数目。
一篇文章中出现频繁的词往往能够代表其所要阐述的内容,然而词语所涉及的文档数目越多,说明词语能够代表某一类文档的能力越弱,无法作为区分文档的关键词使用。
许多文献对TF_IDF模型进行了改进,张阔等使用增量TF_IDF模型[9],薛晓飞等则根据词元特征对词元权重计算作了改进[10],当词元为人名、地名、时间等就增加该词元的权重。刘炜等引入本体[11]的概念,将文章中的每个句子中的词语按照‘时间’、‘地点’、‘实体’、‘活动’四个语义类进行归类,按照类别计算每个词元的重要度。
然而TF_IDF算法计算词元权重并不适用于所有情况,例如对突发事件的检测。突发词通常会在某一段时间内大量出现在很多文档中,对应着相应的突发事件,TF_IDF计算方法会使得突发词存在被忽略的风险。对于这个问题,王勇等[12]使用了词频_比例文档频率(term frequency_proportional document frequency,TF_PDF)替代了TF_IDF,用来计算突发词的权重,以弥补TF_IDF在突发词处理上的弊端。
2.2 文本相似度
相似度计算方法中最常用的是余弦相似度和Jaccard相似度,定义分别如下[13]:
(2)
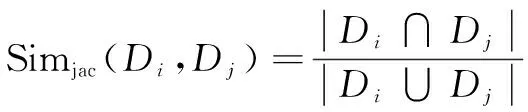
(3)
在实际应用中,周刚等[14]融合了余弦相似度、雅各比相似度和语义相似度对相似度进行综合衡量。薛晓飞等[10]综合考虑文档内容、地点、时间对文档相似度进行重定义。以上这些相似度的计算固然合理,但是实现却十分耗时。针对这样的问题,Kaleel S B等[15]利用局部敏感哈希(locality sensitive hashing,LSH)对表示文档的集合进行局部哈希映射,从而大大减少了计算量。
3 事件检测方法
根据文本数据类型将检测方法分为两类:纯文本数据事件检测方法和社交数据事件检测方法。其中纯文本数据事件检测方法分为在线事件检测和离线事件检测;社交数据事件检测方法从社交数据用户特征角度出发,分为利用用户重要度、利用用户评论转发行为和根据用户情感状态三类。
3.1 纯文本数据事件检测方法
3.1.1 在线事件检测
在线事件检测方法包含基于单次扫描(Single_Pass)和基于突发项等实现机制。Single_Pass关注于文档内容本身,基于突发项更加关注于若干个突然爆发的词项。
(1)基于Single_Pass的方法。
Allan J等[16]提出的Single_Pass算法是较为经典的在线事件检测算法,主要应用于新事件检测。该算法将新产生的新闻文档与已有的文档进行对比,只要新文档与过去文档的相似度均小于某一阈值α,那么说明这篇文档所描述的是一个新的事件。该算法的原理如图1所示。
目前基本的在线新事件检测(online new event detection,ONED)系统都是通过比较新有文档与已有文档的相似度来判断一个报道是否是新事件的第一篇报道,现有的ONED系统的主要缺点在于,由于网络数据量增长的速度很快,需要耗费大量的存储资源,而且随着新文档的不断涌入,内存面临着数据溢出的风险。针对现有系统的以上问题,王颖颖等[17]提出了一个改进的ONED系统架构,采用滑动窗口机制提高检测效率。
(2)基于突发项的事件检测。
突发项[18]一般指的是突发词。突发词是指在某个时间窗内被大量使用,且在之前的事件窗内很少被使用的实词[19]。也有基于情感符号的突发事件检测,张鲁民等[20-21]认为微博中情感符号的突发性代表事件的突发性。基于突发项的方法与其他方法的区别在于,前者的核心在于检测突发特征,而其他方法大多是以文本处理为核心。
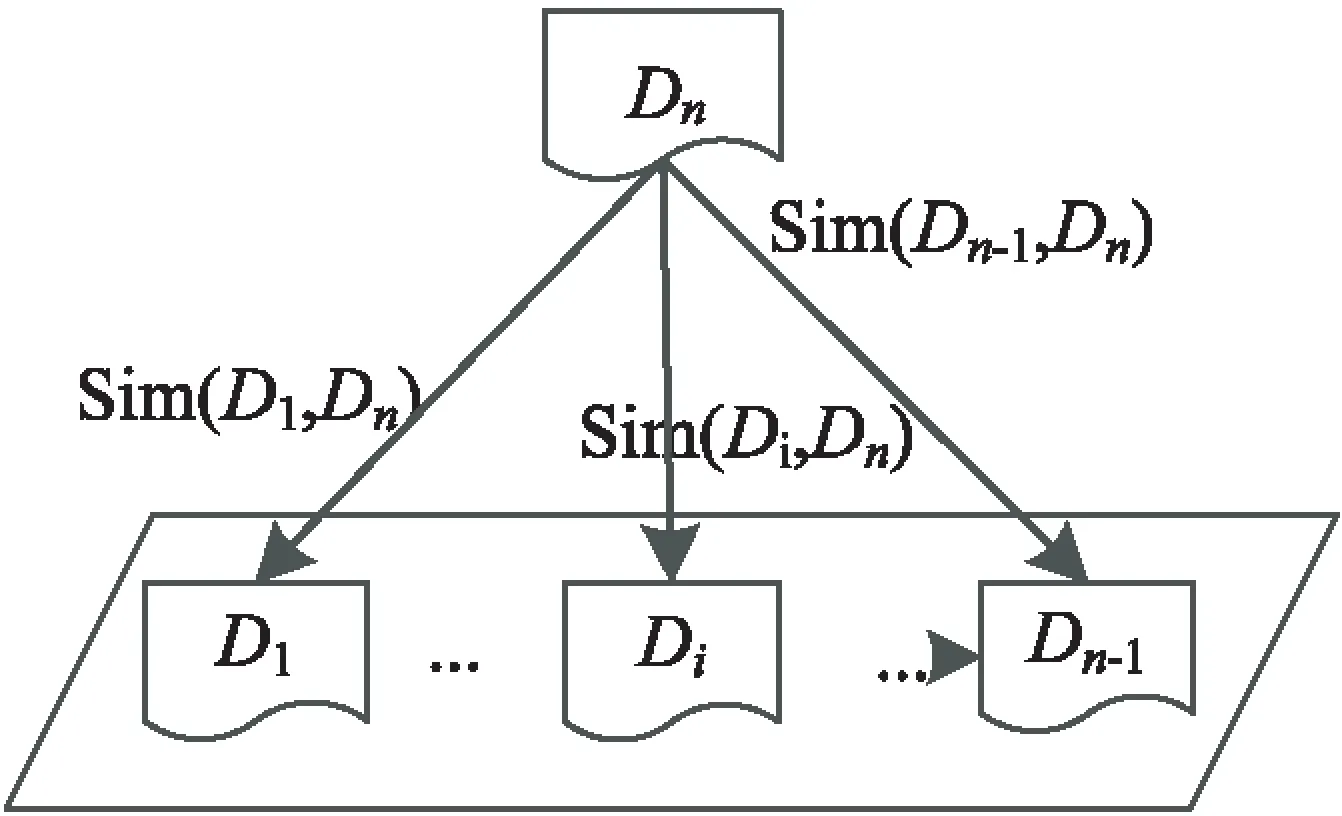
(a)新文档与已有文档分别计算相似度
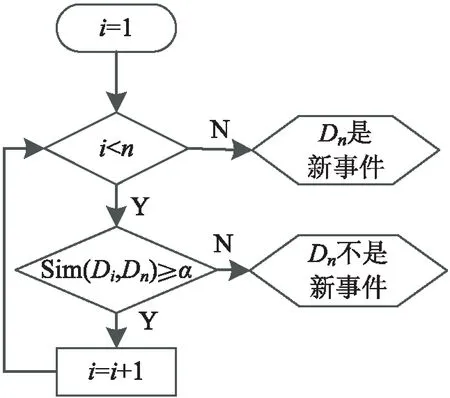
(b)判断新文档是否描述新事件
张晓霞等[22]在检测突发词频时将表征科学家科研绩效的H指数引入进来,度量包含候选突发词的文档数,将出现文档数较多的词选出作为最终用以识别突发事件的突发词。针对大量琐碎的突发项问题,Weng J等[23]提出了一种基于小波信号集群的事件检测方法(event detection with clustering of wavelet-based signals,EDCoW),为每个突发词组都建立一种信号模型,这种信号可以通过小波分析快速计算,不需要占用很大的存储空间。通过观察这些信号的相关信号自动关联性,就可以将那些细碎的不重要的词组过滤掉。
基于突发词的事件检测与时间的关系十分紧密。描述同一个突发事件的文档往往具有共时特性[24],因此时间要素是突发事件检测的重要依据。Li X等[25]将时间相关信息融合到突发事件检测模型中,充分利用了时间相关性来建模,从而进行突发事件检测。陈宏等[26]也考虑到了事件发生的时间特性,认为事件的持续时间总是在一个持续的时间段内,为了避免时间间隔比较长的相类似事件的报道文档被归为一类,在计算文档相似性时文献引入了时间衰减因子。谢思发等[27]是基于词语的爆发度来预测热点事件的,先检测出单位时间内的词频,计算每个词语爆发度,组成词语爆发度序列,然后使用时间序列聚类算法,利用Haar小波变换将高维时间序列进行降维,以时间点作为参数对热点词进行K-means聚类,不断迭代后得到由热点词聚类所产生的热点事件。
实时数据中有一些突发项是周期性出现的,对于新事件检测并无用处且造成干扰。针对周期性出现的突发项,赵洁等[28]提出一种基于突发词项频域分析的突发事件检测方法,将突发词项转换为时序信号,然后利用信号处理中的频域分析方法识别和过滤周期性出现的非突发高频词项。针对目前的博客舆情分析方法存在时间信息有歧义的虚假突发事件问题,林达真等[29]提出一种基于时间扥不特征的博客突发事件检测方法,通过波峰检测和计算事件文档与背景预料文档之间、事件相关文档和不相关文档之间的事件分布差异来判断该事件在时间特征上是否具有突发性和关联性。
3.1.2 离线事件检测
离线事件检测主要是针对已有的数据分析检测事件。离线事件检测的主流方式是聚类。聚类的主要方法有层次聚类、利用关系图的聚类、潜在狄利克雷分布聚类(latent Dirichlet allocation,LDA)[30]、词聚类等。也有从语义角度出发进行事件检测。
(1)层次聚类法。
Yang等[31]提出的层次聚类(group average clustering,GAC)是一种自底向上构造集群的聚类算法。GAC算法中的输入量是收集到的文档,而输出则是一棵集群树。集群的产生过程就是一棵自底向上的二叉树的产生过程。其中的叶子节点表示初始集群,每个集群就是一个文档。而中间层的每个节点所代表的集群都是下层中两个相似度最高的节点所代表的集群的合并。默认情况下,算法会不断进行集群点构造,直到产生出根节点为止,这样输出的集群树将囊括所有集群,并且输入的每一个文档都会有其对应的集群。如果在算法中对集群的数目已经进行了预定义,那么在集群数目达到了预定义的值之后算法将立即结束。
(2)关系图聚类法。
利用关系图的聚类方法主要是将文档之间的关系用图的形式表示出来,图中的节点之间往往表示两个顶点的某种联系。Sayyadi H等[32]提出关键字图(KeyGraph)的概念,即图中的各个节点代表的是一个个关键字,节点之间的连线表示这些术语同时出现在同一个文档中。如果出现包含了多个关键词节点的集群,那么就说明该集群隐含了某一特定事件通过计算节点之间连线的密集程度就可以得出检测事件。该方法的不足之处在于节点之间的连线都是无权重的,不能够反映关键词同时出现的频率大小。
冯戈利[33]则是提取出每个文档中的信息要素,根据这些信息要素构建出共现词网络图。在共现词网络图中实施深度优先检索方案,检测出图中的定长共现词环,通过查找环来检测出事件。
(3)LDA聚类法。
LDA的基本思想为:每篇文档的中心内容都可以由若干个潜在的主题词来概括,文档中每个有意义的词元都或多或少地与主题词有着某种关联性,LDA就是利用这种关联性来识别出文档所属的主题词的集合,根据这个集合检测出报道所对应的事件[5]。LDA模型分为文档、主题、词三层结构。LDA模型与其他聚类算法的主要区别就在于LDA的聚类结果不是确定性的分类,而是基于概率的分类,也就是分类结果呈概率分布[34]。
(4)LSH聚类法。
Vinay Setty等[35]使用LSH聚类进行事件挖掘。LSH[36-37]具有最小独立排列,能有效处理高维度的数据,结合使用可靠可扩展的近似Jaccard距离计算文档相似度,最终能够找到最相近的若干新闻报道文档。LSH聚类的优势除了能够有效处理高维数大规模数据之外,还能识别出新闻事件的规模,与其他方法相比,采用的参数很少。通常LSH会与MinHash[38-39]或者SimHash[40]结合使用。
(5)词聚类法。
词聚类法[41]需要计算词语之间的相似度。两个词语的相似度的计算方法是利用两个词语的互信息,也就是说,当两个词语越趋于描述同一个事件时,它们的上下文环境会越为相近,利用这点来计算两个词语间的相似度大小。而词聚类的思想就是:自底向上,先将特征向量空间中的每一个词语当作一类,两两词语之间计算相似度,选取相似度最高的两个归为一类。而类与类的合并,就要计算类与类之间的相似度,每次选取最大相似度的两个类进行合并,直到类集合中各元素间的最大相似度小于某一相似度阈值。
(6)基于语义和其他特征的事件检测法。
基于语义特征的事件检测方法[42]比较关注词语或者句子的语义特征。如许旭阳等[43]提出的基于句子的事件检测方法,使用二元分类器,根据句子中是否包含主体,时间,地点等关键词项将句子分为两种:包含事件元素的实例和不包含事件元素的非实例,并由此进一步进行事件检测。
基于语义特征的事件检测方法还会关注语义关联性,如赵江江等[44]将事件触发词和与其相关联的时间地点等关键词组成结构化的数据,利用这种数据模型进行事件检测。张阔等[45]则提出了基于关键词元委员会的事件检测与关系发现方法,将新闻报道文档用特征向量加时间标签的形式表示出来,计算出事件对应的词元委员会,再对每一个词元委员会集合都建立一个核心新闻簇,将含有词元量包含该词元委员会中一半以上的词元的文档归入到这个文档簇中。
3.2 社交数据事件检测方法
文中将社交网络数据单独分为一类,原因是其与传统文本在内容和形式上有极大不同。社交网络数据是一种特殊的数据类型,典型例子有微博、Twitter、Facebook等数据。其特点是[46]内容简短,口语化,情绪化,且含有用户关注度,主题词,评论转发量等信息,另外还潜在包含了时序和社交关系等,因此应当根据社交网络数据自身的特征进行事件检测,将其从传统的文本事件检测中分离出来。社交数据的事件检测方法一般会侧重于利用社交数据的各种数据特征进行事件检测,大部分方法都会结合用户相关信息,因此本节从社交数据用户特征角度出发,分类介绍社交数据的事件检测方法。
3.2.1 利用用户重要度进行事件检测
李艳等提出了术语的营养和术语的能量两个概念[47]。术语的营养值的计算涵盖了该术语的权重和用户权威性两个参数,术语的能量则表示其在微博语料库中的有效贡献。最后根据术语的能量值对术语进行排序、筛选,从而检测出热点事件。郭跇秀等则针对微博这种特殊的数据提出了用户五元组[48]的概念。用户五元组包括:用户ID、用户粉丝数、用户微博数、是否为VIP用户、用户活跃度。根据用户五元组对用户影响力进行量化后再进行事件检测。
3.2.2 利用用户评论转发行为进行事件检测
冯永等[49]认为转发数和评论数对微博重要性是极为重要的度量。因此将传统的TF_IDF方法计算权重改进为基于转发评论数的计算方式,转发评论数越高,相应的权值就越大。王勇等[12]则是针对微博这种特殊的数据提出了热度的概念,简单来说就是对一个事件被关注程度的量化。而单条微博的热度需要使用微博的转发数和评论数来衡量。而周刚等[14]提出的MB-SinglePass(microblog-SinglePass)算法是传统的Single_Pass在微博数据上的改进方法。这种方法考虑了用户之间的关系(转发评论关系,关注关系),传统的Single_Pass方法只通过相似度作为归类或新建类的准则,而MB-SinglePass则利用评论转发关系将一些帖子直接归到相应类中,并根据发帖人与最大相似度类中发帖人是否为关注或好友关系来决定相似度小于阈值的情况下是否有必要创建一个新类。
3.2.3 根据用户情感状态进行事件检测
微博与传统新闻文档除了在数据形式上相差较大以外还在内容上相差甚远。微博数据往往包含了用户的个人情感色彩,因此也有人基于此提出了微博数据的处理方法。费绍栋等[50]利用层次模型将话题聚类后,根据用户对该话题的情感态度对话题进行过滤,作者认为用户情感分为正面情绪和负面情绪两类,如果大量用户对某个话题都呈现负面情绪,那么说明该话题有很大可能性是突发事件引发的话题。唐晓波等[34]还提出了一种话题情感强度的计算方法,根据这一值对话题的情感强度进行时序回归分析。该方法能够有效挖掘话题发展过程中用户情感的变化规律,并根据规律对话题的发展变化进行持续的跟踪和探测。
最后,值得注意的是,传统新闻媒体与社交网络之间并不是相互独立的。两者之间有着相互作用和共生关系,即新闻报道为社交网络提供话题资源,而社交网络又为新闻媒体提供事件进展[51]。Hua T等[52]利用新闻报道为社交网络提供话题资源这一关系,将新闻标签转移到Twitter上以产生初始标签,然后再利用Twitter的社交特性得到带有扩展性标签的Twitter数据,利用带标签数据进行事件检测。
本节所涉及的几种事件检测类型的使用场景以及优缺点如表1所示。

表1 几种典型事件检测类型的适用场景及优缺点
4 结束语
事件检测是数据挖掘领域的一个重要分支。通过对事件的检测能够从事件中挖掘出潜在的巨大价值,基于传统的新闻报道文档的事件检测能够从庞大的数据量中检测出具体的事件以及其后续发展,而基于社交网络数据的事件检测能够进一步通过社交网络数据用户之间的关系以及用户行为进行事件检测并分析预测事件未来发展状况,对传统的新闻报道检测方法有所改进。在事件检测这一研究领域,根据用户的信息和行为来进行事件检测将是未来值得研究和探讨的方向。
