激素调节的克隆选择聚类在入侵检测中的应用
2018-09-22白琳
白 琳
(西安邮电大学 计算机学院,陕西 西安 710121)
0 引 言
入侵检测作为一种实时主动的网络安全防御技术,能够为网络系统的正常运行保驾护航。从20世纪80年代首个通用入侵检测系统模型提出以来,经历了数十年的发展,众多学者对其的研究仍方兴未艾。伴随着计算机网络技术及其应用的飞速发展,面对越来越严峻的网络安全形势,对入侵检测产品的性能也提出了更多、更具体的要求:能够分析复杂、异构的大数据;能够正确检测出恶意的、非法的行为;误报率低;能够检测出未知的攻击。
1 基于聚类的入侵检测研究现状
入侵检测技术手段包括异常检测技术和误用检测技术。异常检测需要建立代表“正常行为”的模型,再以测量值对其的偏离程度判断用户行为是否“异常”。误用检测则通过按事先预定义好的异常模式以及观测到的入侵发生的情况进行模式匹配来进行检测[1]。因此,异常检测可以检测出新的攻击,所以受到的关注度更高。
现有的大多异常检测系统,其正常模型的确立都是通过对完全正常的数据集进行训练而完成的。使得检测方法依赖于带标签的训练数据,如果某些标签是错误的,“正常模型”的误差将会很大。尤其在实际网络环境中,收集和整理出带标签的网络数据工作量大、难度高,所以采用无标签的网络数据建立“正常模型”构造无监督异常检测系统才更可行。
聚类就是一种行之有效的无监督模式分类方法。可以将无标记的样本集按照某种聚类准则划分成若干个子集,将相似的样本尽量归为一类,不相似的样本归为不同类。相似度的度量依靠数据对象描述属性的取值来确定[2]。传统聚类方法,如C-均值、模糊C-均值、BIRCH等,可伸缩性较差,只能处理小规模数据,并且依赖聚类原型,容易陷入局部最优,由其构造的入侵检测系统性能不高。一些进化计算方法以其良好的优化特性用于传统算法改进,包括遗传聚类算法、免疫进化聚类[3]以及基于CSA的聚类[4]等。相应构建的入侵检测系统性能有了不同程度改善,如文献[5-6]。但是遗传进化算法易于后期发生早熟,免疫算法的疫苗提取非常依赖先验知识[7]等缺点都对聚类效果影响较大。随着智能信息处理技术的不断发展,对聚类算法的性能指标要求日益增加,除了要保证结果的有效性和可靠性,还需要具有可拓展性、可伸缩性、有效处理噪声数据或多维、异构数据的能力[1],以适应复杂网络环境下数据分析和处理的需求。
生物体的三大系统:神经系统、内分泌系统和免疫系统,彼此之间相互作用、协调、促进,形成了一个有机整体。特别地,内分泌系统中强大的激素调节能力可以有效刺激和调节另外两个系统的功能。受该生命机理启发,将激素调节机制加入抗体克隆进化过程,对抗体克隆规模进行动态调整,扩增优秀个体、抑制退化个体。构造基于激素调节的克隆聚类算法,改善聚类的精度、速度及稳定性。
2 人工内分泌系统
2.1 人工内分泌系统
生物体的内分泌系统是一个分布式的调控系统,具有良好的自适应性、自组织性和自学习性,发挥着调控机体新陈代谢和生长发育的重要作用。协同神经系统、免疫系统,维持着生物体的内稳态和内平衡。内分泌系统工作的核心就是激素调节,机体内的各个生理调节功能都要依靠激素进行。长期的生命进化过程使内分泌系统具有十分强大的功能,通过激素的反应、扩散过程进行调节,维持机体的内稳态,为生物体的正常生命活动提供保障[8]。
人工内分泌系统(artificial endocrine system,AES),指借鉴生物体内分泌系统的信息处理机理,将其应用于计算、控制、通信等领域而形成的模型或系统[9]。
在自然界,机体的内分泌系统和免疫系统之间保持着密切的双向调控联结,内分泌激素通过免疫细胞受体使其免疫功能增强或削弱;免疫系统通过细胞因子对内分泌系统发生作用[10]。因此,内分泌系统可以调节免疫功能,而免疫系统可以对其进行应答和反馈,反作用于内分泌系统。借鉴该机理,可以将激素调节作用引入人工免疫系统相关方法,在免疫基因层面对抗体工作进行调控,改进原有算法的性能。
2.2 激素调节机制
2001年,L. S. Farhy提出了激素Hill函数调节规律[11],即激素分泌的上升调节和下降调节函数。
(1)
(2)
其中,F是Hill调节函数;up表示激素刺激、down表示激素抑制;G是自变量;n(n≥1)是Hill系数,T(T>0)是阈值参数,n和T表示曲线上升或下降的斜率,对应激素刺激或是激素抑制的改变速度。
且Hill函数满足:
(3)
3 人工免疫系统
人工免疫系统(artificial immune system,AIS),是模拟生物体免疫系统的工作过程而形成的一种信息处理计算模型。其相关算法主要指克隆选择算法、人工进化免疫网络。
3.1 克隆选择学说
克隆选择学说的核心是:免疫系统中,在抗原的刺激下,免疫细胞会进行克隆、得以增殖,再通过遗传、变异等进化操作分化成记忆细胞和多样性效应细胞。与抗原亲合度较低的抗体经过进化学习后,亲合度会趋于成熟,所以,克隆选择的过程实际是面向亲合度成熟的过程。具体实现时,通过选择、交叉、变异等遗传进化算子和相应群体控制机制来操作。
3.2 克隆选择算法
克隆选择算法包含克隆增殖、免疫基因操作以及克隆选择三步。克隆选择是由亲合度函数指导的抗体群随机映射,其进化过程表示如下:
(4)
克隆的实质是在一代进化过程中,根据亲合度大小,在候选解的附近产生一个变异解群体,以此扩大搜索范围、增加抗体群多样性,防止早熟和搜索陷于局部极小值[12]。
4 基于激素调节的克隆选择聚类
4.1 目标函数
采用下列目标函数作为聚类准则:

(5)

4.2 抗体编码
设一组聚类原型P为一个抗体,将各组原型所包含的不同特征值组织在一起,再通过其各自取值范围进行量化,量化结果为k,具体将抗体按式5进行编码。
Ai(0)=
(6)
其中的各参数依据各原型pi,i∈(1,k)取值。
4.3 亲合度函数
亲合度函数构造的依据:目标函数越小,聚类效果越好,抗体-抗原亲合度越大。

(7)
其中,若f的值越大,抗体就越接近于抗原。
4.4 激素调节克隆算子
将激素调节策略引入克隆选择算法,利用Hill刺激效应使种群中抗体克隆规模得以扩增,同时利用Hill抑制原理使不良个体较多的种群克隆规模得以削减。由此,通过内分泌激素调控,个体克隆规模自适应调整到最优状态,更利于群体的进化学习,进而有效收敛。
(1)激素调节的克隆操作。

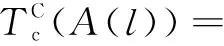
(8)
(9)
其中,Ii是元素全为1的qi维行向量。
抗体Ai的qi克隆表示为:

1,…,N
(10)
其中,Int(c)表示大于c的最小整数;Nc为与克隆规模相关的值,且大于N。
因此,对于单个抗体,qi的大小取决于f,即抗体的克隆规模完全由亲合度决定。
②激素调节。
对于第t-1代种群,其平均亲合度表示为:
(11)

种群的多样性可表示为函数:
(12)
下降规律激素调节函数可表示为:
(13)
可令
(14)
由此,就可以描述出:在当代种群中,个体亲合度与上一代的平均亲合度间的关系。在此,由函数D(t)和F(t)共同调节个体克隆规模,第t代个体的克隆规模q(t)改进为:

(15)
参数η在实际中根据经验值而定。
克隆之后,种群变为:

(16)
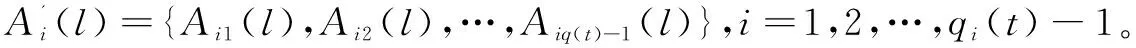
其核心为变异操作,变异仅作用于克隆后的抗体之上,这样就可以保留原始种群的有效信息。具体为:
(17)
抗体群经过激素调节的克隆选择学习后,更新为:A(l+1)=[A1(l+1),…,AN(l+1)],若A(l+1)中存在Ai(l+1)及Aj(l+1),满足f(Ai(l+1))=f(Aj(l+1))=maxf(A(l+1)),i≠j,则随机产生一个新抗体,同时以概率pi删除Ai(l+1)、Aj(l+1)其中之一。
基于激素调节的克隆聚类算法(见图1)中,抗体编码后进行如上的克隆算子操作,直到聚类原型收敛到最优解,完成聚类分析。

图1 基于激素调节的克隆聚类算法流程
5 激素调节的克隆聚类入侵检测方法
5.1 数据预处理
实验采用KDD CUP99数据集,该数据集包含了9周网络流量连接记录,其中7周的训练数据大约具有500万条数据量,2周的测试数据大约200万条数据量。连接记录具有协议类型、持续时间、标签等42个参数,分为33个连续属性、8个离散属性,第42个参数属性为标签,标记了该条记录是“正常”的,或具体为何种攻击类型。攻击类型一共有37种,被分为4大类:拒绝服务攻击、对本地超级用户的非法访问、未经授权的远程访问以及扫描与探查。
训练数据集中共有23个标签:“正常”和22种攻击类型。测试集中含有38个标签:“正常”和37种攻击类型。其中,有17种攻击未在训练集中出现,对其而言,是“未知”攻击。
对于网络连接记录的字符枚举属性,将其转变为离散数值特征值,实验中用不同的数字来代替字符枚举属性值。如:“ftp”协议用“1”代替,“http”协议用“2”代替。
实验训练集和测试集构造过程见表1。
为了验证算法对未知攻击的检测性能,构造未知攻击,指测试集相对于训练集而言,多出的攻击种类。
5.2 相异度度量标准
根据KDD CUP99数据具有混合属性的特点,采用下列相异测度函数:

(18)


表1 实验数据集
5.3 聚类分析
根据第四节中的激素调节克隆聚类算法对训练数据集进行聚类分析,得到聚类原型P。训练集被分为c类,聚类结果见表2和表3。
5.4 正常模型
上述c类子集需要区分出“正常”类或“异常”类,即为不同类贴上标签。入侵检测系统基于两个合理的假设[13-14]:
(1)同类数据在特定的尺度条件下会在特征空间中互相接近,而不同类数据会彼此远离;
(2)正常行为的数据量要远远大于异常行为的数据量。
因此,根据不同子集所包含的数据量便可区分出正常类和异常类。具体的,若某个子集的数据量与样本数据总量之比不小于ω(0<ω<1),就将其标记为“正常”,否则为“异常”。这样,就可以获得异常检测中的正常模型,进而可以实现入侵检测。

表2 类内距结果
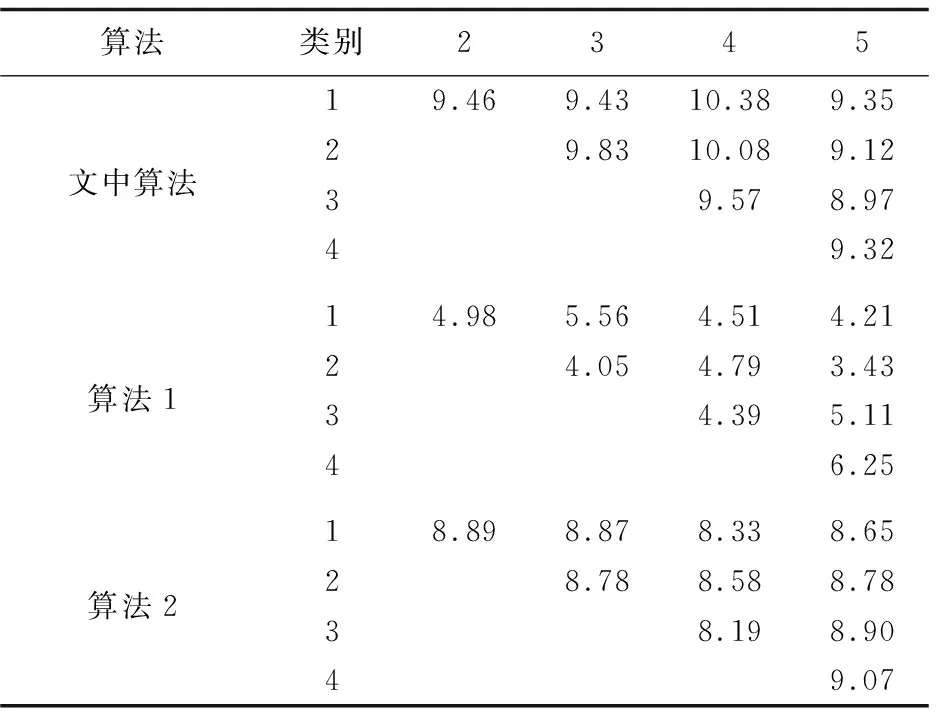
表3 类间距结果
5.5 异常检测
对测试集test1或test2,要想知道其中某个连接记录xi是否异常,即获得xi的标签,先计算xi到每个聚类原型Pj(1≤j≤c)的距离,再找出其中的最短距离d(xi,Pmin)(1≤min≤c)。在5.4小节,每个类都已获得了标签,那么第min类的标签就是xi的标签。如果d(xi,Pmin)≥μ,xi被判断为未知攻击。按照该过程完成对所有测试集数据的检测。最后计算检测率和误警率,以此来评判入侵检测系统的性能。检测率指被检测出来的异常数据占异常数据总数的百分比;误警率指正常的数据被错误的判断为异常的数目占正常数据总数的百分比。
5.6 实验结果及分析
将传统的模糊C均值算法(算法1)、没有利用激素调节克隆规模的聚类算法(算法2)作为对比算法。样本的种群规模设为50,克隆规模系数Nc=100,激素调节参数η=2.5,变异概率pm=0.2,死亡概率pi=0.4,选择最佳个体百分比15%。
三种算法的聚类结果见表2和表3。对于聚类结果,类内距越小、类间距越大,算法性能就越好[15]。
类内距的定义为:

(19)
其中,r为聚类子集个数。
类间距的定义为:
(20)
其中,n为各类所包含的数据个数。
表4给出了入侵检测结果,每种算法都经过20次独立实验,取其检测率和误警率平均值反映在表3中。其中,已知入侵指训练集中存在的22种攻击;未知入侵详见表1。
从表2和表3可以看出,基于激素调节的克隆聚类算法性能较高,更精确地反映了样本在状态空间的分布情况。在群体克隆操作时,利用内分泌激素调节特性,自适应调整个体的克隆规模,不仅可以增加进化过程中的种群多样性,同时能够更好、更多地发挥优秀个体的性能,抑制不良个体对进化学习的影响。使克隆选择的亲合度成熟过程在激素的调控下得到改善,保证聚类算法能够快速、高效地收敛至全局最优。

表4 检测结果 %
从表4可以看出,文中算法的检测效果更加理想,和传统算法相比,优势十分明显,引入了进化策略和各类进化算子,有效激发了聚类的整体寻优性。并且,算法与数据分布无关、对聚类原型无依赖性,可以自适应调整到最佳类别簇。通过构造合理的数据集,验证了文中算法对大数据集以及未知攻击的有效检测性。
6 结束语
在生物体内分泌系统和免疫系统相互作用、协同工作的生命机理启发下,将人工内分泌系统中激素的调节机制引入由克隆策略指导的聚类准则中进行数据分析。根据抗体亲合度成熟程度自适应调节个体克隆规模,以此保证在群体的进化过程中,扩增优秀个体、尽可能发挥其优势,抑制不良个体、最大程度地减少其对各代进化的影响。使得克隆算子增加自适应性、提高自学习性和稳定性,由此得到的新聚类算法具有更高的全局寻优特性和更快的收敛速度。构造了基于激素调节克隆聚类的异常检测系统,并在KDD CUP99数据集上进行了对比仿真实验,实验效果非常理想,表明检测系统可行、有效。
